猿人学题库十六题——js加密_表情包+sojson6.0——满天坑
猿人学题库十六题——js加密_表情包+sojson6.0
1. 首先 进入 浏览器的开发者工具,
进去后首先还是 无线debug ,找到 debugg 对应的行数,右击选择 never pause here ,刷新 就不会再此处 停下了

进去后找逻辑请求的规律参数,多请求几次,发现 只要 safe 参数在变化,下一步我们就分析 这个参数
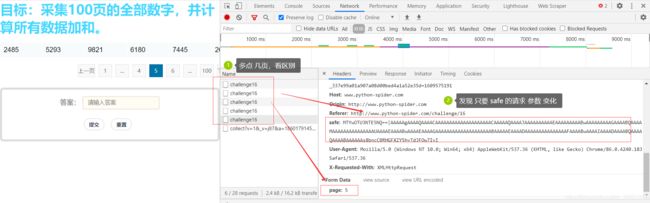
2. 解析请求参数
safe 参数分析,找到 JS 的地方 ,

在 进去 JS 代码后,发现 在 ajax请求之前 执行了 一段颜文字代码,
颜文字后有 request.setRequestHeader("safe", token); 这么一段代码应该都看的懂吧,就是把 token 赋值给 safe ,后面就是找taken的过程

我们把 颜文字 复制到,控制台console 打印,把函数体 打印出来就可以 查看了
这里前面的博客也有说到过这些 什么乱七八糟看不懂的颜文字或还有 【】 这种的代码的函数体,一般一个 自执行函数,
既然是自执行函数 最后肯定是有 () 的,这是自执行的规律,把最后的括号去掉,就可以查看函数体

这里就是 获取 token的地方,结果了一长串的 JS方法 window.btoa(a)+('|')+binb2b64(hex_sha1(window.btoa(core_sha1(a)))) + b64_sha1(a));

进一步分析 token ,我们还要 找到 那一长串的 JS 方法的 地方,这里我们直接 全局搜索找吧,

点进去 后可以 看到 下面这里 main.js 代码 ,这里只想 定义方法的地方,
window.btoa(a)+('|')+binb2b64(hex_sha1(window.btoa(core_sha1(a)))) + b64_sha1(a)); 这里才是 得到 token的,我们只需要把 对应的方法抠出来,
不想扣的就直接 把 全部 复制出来,出错了再分析

这里 window.btoa 方法是 自带的方法 ,我们需要自己改写,base64 方法,补充base64 方法
把 base64 方法,复制过来,调用encode 编码改写得到 相同的结果,

这里 记录一下坑:
1. 首先 main.js 那里 不能格式化代码,格式化代码后就会出错,应该是代码中对格式化做个反优化,格式化后代码出错了
2. 保持 js 文件,读取的时候不用用 encoding='utf-8' 读取,也会出问题,应该是编码什么问题
这里 通过JS获取token有几种方法:补充python执行JS
1. 使用 execjs 库来调用 ,python执行 JS的库,可以得到,这种很多依赖的东西会遇到很麻烦
2. 使用 node 环境来执行 js 代码,可以在过程中忽略很多麻烦 (os.popen('node main.js'))
3. require('express'); 可以使用 node的express 做一个接口,来获取参数
(大批量抓的时候,os读取资源,比网络http协议,很耗资源啊,所有大量的时候可以使用推荐使用 express )
分析完后 ,之后都是撸代码就好了。
3. 撸代码
import execjs
import os
import requests
print(execjs.get().name)
pipeline = os.popen('node ./js颜文字/11.js')
print(pipeline.read())
with open('./js颜文字/11.js') as f:
Str_code = f.read()
js = execjs.compile(Str_code)
cookies = {
'_ga': 'GA1.2.760325869.1609250258',
'Hm_lvt_337e99a01a907a08d00bed4a1a52e35d': '1609245724,1609245874,1609247115,1609554124',
'no-alert': 'true',
'_gid': 'GA1.2.1884060414.1609554148',
'sessionid': 'fzgdwngfh1mv2dhz49vyzcmfwjf17xuo',
'Hm_lpvt_337e99a01a907a08d00bed4a1a52e35d': '1609554512',
}
headers = {
'Proxy-Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36',
'safe': 'MTYwOTU1NDU3NA==|AAAAAAAAAAgAAAABAAAAAAAAAAAAAAACAAAABwAAAAcAAAAJAAAAAAAAAAQAAAAHAAAAAAAAAAUAAAAGAAAAAwAAAAUAAAAJAAAAAgAAAAMAAAAAAAAAAQAAAAAAAAAFAAAABAAAAAAAAAAFAAAACQAAAAEAAAAAAAAAAQAAAAIAAAAGAAAAAAAAAAMAAAAGAAAAAAAAAAUAAAAHAAAABQ6lelG1ssNQqsHIhrrJ0Qbgq2xoM',
'Origin': 'http://www.python-spider.com',
'Referer': 'http://www.python-spider.com/challenge/16',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
def get_token():
result = js.call('get_token')
print(result)
return result
def Get_Date(i,headers):
data = {
'page': i
}
response = requests.post('http://www.python-spider.com/api/challenge16', headers=headers, cookies=cookies, data=data, verify=False)
# print(response.json())
return response.json()
Count = 0
for i in range(1,101):
toekn = get_token()
headers['safe'] = toekn
data = Get_Date(i,headers)
for data in data['data']:
Count += int(data['value'])
print(Count)
# 4883828 答案答案没毛病 ,完工 OK !!!,

总结 :
这个和 十四题 的 【】的JS 有点像,这个是 颜文字,一样的处理方式,这题的main.js 没有去分析了,正常是根据 token的函数扣JS,这里直接复制 没有问题,就直接用了。
[分享] 猿人学·爬虫逆向高阶课 https://j.youzan.com/2fCUDs ,可以私信交流学习
