云原生技术公开课学习笔记:应用编排与管理:Job和DaemonSet、应用配置管理
五、应用编排与管理:Job和DaemonSet
1、Job
1)、需求来源


2)、用例解读
1)Job语法

上图是Job最简单的一个yaml格式,这里主要新引入了一个kind叫Job,这个Job其实就是job-controller里面的一种类型。 然后metadata里面的name来指定这个Job的名称,下面spec.template里面其实就是pod的spec
这里面的内容都是一样的,唯一多了两个点:
- 第一个是restartPolicy,在Job里面可以设置Never、OnFailure、Always这三种重试策略。在希望Job需要重新运行的时候,可以用Never;希望在失败的时候再运行,再重试可以用OnFailure;或者不论什么情况下都重新运行时Alway
- 另外,Job在运行的时候不可能去无限的重试,所以需要一个参数来控制重试的次数。这个backoffLimit就是来保证一个Job到底能重试多少次
所以在Job里面,主要重点关注的一个是restartPolicy重启策略和backoffLimit重试次数限制
2)Job状态

Job创建完成之后,就可以通过kubectl get jobs这个命令,来查看当前job的运行状态。得到的值里面,基本就有Job的名称、当前完成了多少个Pod,进行多长时间
- AGE的含义是指这个Pod从当前时间算起,减去它当时创建的时间。这个时长主要用来告诉你Pod的历史、Pod距今创建了多长时间
- DURATION主要来看Job里面的实际业务到底运行了多长时间,当性能调优的时候,这个参数会非常的有用
- COMPLETIONS主要来看任务里面这个Pod一共有几个,然后它其中完成了多少个状态,会在这个字段里面做显示
3)查看Pod

Job最后的执行单元还是Pod。刚才创建的Job会创建出来一个叫pi的一个Pod,这个任务就是来计算这个圆周率,Pod的名称会以${job-name}-${random-suffix}
它比普通的Pod多了一个叫ownerReferences,这个声明了此pod是归哪个上一层controller来管理。可以看到这里的ownerReferences是归batch/v1,也就是上一个Job来管理的。这里就声明了它的controller是谁,然后可以通过pod返查到它的控制器是谁,同时也能根据Job来查一下它下属有哪些Pod
4)并行运行Job

有时候有些需求:希望Job运行的时候可以最大化的并行,并行出n个Pod去快速地执行。同时,由于我们的节点数有限制,可能也不希望同时并行的Pod数过多,有那么一个管道的概念,我们可以希望最大的并行度是多少,Job控制器都可以帮我们来做到
这里主要看两个参数:一个是completions,一个是parallelism
- 首先第一个参数是用来指定本Pod队列执行次数,可以把它认为是这个Job指定的可以运行的总次数。比如这里设置成8,即这个任务一共会被执行8次
- 第二个参数代表这个并行执行的个数。所谓并行执行的次数,其实就是一个管道或者缓冲器中缓冲队列的大小,把它设置成2,也就是说这个Job一定要执行8次,每次并行2个Pod,这样的话,一共会执行4个批次
5)查看并行Job运行
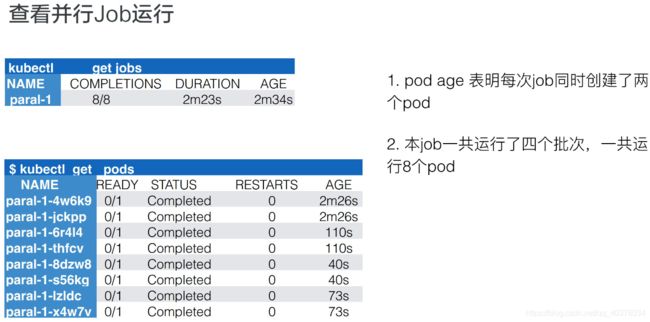
上图就是当这个Job整体运行完毕之后可以看到的效果,首先看到job的名字,然后看到它一共创建出来了8个pod,执行了2分23秒,这是创建的时间
接着来看真正的pods,pods总共出来了8个pod,每个pod的状态都是完成的,然后来看一下它的AGE,就是时间。从下往上看,可以看到分别有73s、40s、110s和2m26s。每一组都有两个pod时间是相同的,即:时间段是40s的时候是最后一个创建、2m26s是第一个创建的。也就是说,总是两个pod同时创建出来,并行完毕、消失,然后再创建、再运行、再完毕
6)CronJob语法

CronJob(定时任务)和Job相比会多几个不同的字段:
-
schedule:schedule这个字段主要是设置时间格式,它的时间格式和Linux的crontime是一样的
-
**startingDeadlineSeconds:**每次运行Job的时候,它最长可以等多长时间,有时这个Job可能运行很长时间也不会启动。所以这时,如果超过较长时间的话,CronJob就会停止这个Job
-
concurrencyPolicy:就是说是否允许并行运行。所谓的并行运行就是,比如说我每分钟执行一次,但是这个Job可能运行的时间特别长,假如两分钟才能运行成功,也就是第二个Job要到时间需要去运行的时候,上一个Job还没完成。如果这个policy设置为true的话,那么不管你前面的Job是否运行完成,每分钟都会去执行;如果是false,它就会等上一个Job运行完成之后才会运行下一个
-
**JobsHistoryLimit:**这个就是每一次CronJob运行完之后,它都会遗留上一个Job的运行历史、查看时间。当然这个额不能是无限的,所以需要设置一下历史存留数,一般可以设置默认10个或100个都可以
3)、操作演示
1)Job的创建及运行验证
job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl","-Mbignum=bpi","-wle","print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
hanxiantaodeMBP:yamls hanxiantao$ kubectl create -f job.yaml
job.batch/pi created
hanxiantaodeMBP:yamls hanxiantao$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
pi 1/1 2m1s 2m26s
hanxiantaodeMBP:yamls hanxiantao$ kubectl get pods
NAME READY STATUS RESTARTS AGE
pi-hltwn 0/1 Completed 0 2m34s
hanxiantaodeMBP:yamls hanxiantao$ kubectl logs pi-hltwn
3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989380952572010654858632788659361533818279682303019520353018529689957736225994138912497217752834791315155748572424541506959508295331168617278558890750983817546374649393192550604009277016711390098488240128583616035637076601047101819429555961989467678374494482553797747268471040475346462080466842590694912933136770289891521047521620569660240580381501935112533824300355876402474964732639141992726042699227967823547816360093417216412199245863150302861829745557067498385054945885869269956909272107975093029553211653449872027559602364806654991198818347977535663698074265425278625518184175746728909777727938000816470600161452491921732172147723501414419735685481613611573525521334757418494684385233239073941433345477624168625189835694855620992192221842725502542568876717904946016534668049886272327917860857843838279679766814541009538837863609506800642251252051173929848960841284886269456042419652850222106611863067442786220391949450471237137869609563643719172874677646575739624138908658326459958133904780275901
2)并行Job的创建及运行验证
job1.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: paral-1
spec:
completions: 8
parallelism: 2
template:
spec:
containers:
- name: param
image: ubuntu
command: ["/bin/bash"]
args: ["-c","sleep 30;date"]
restartPolicy: OnFailure
hanxiantaodeMBP:yamls hanxiantao$ kubectl create -f job1.yaml
job.batch/paral-1 created
hanxiantaodeMBP:yamls hanxiantao$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
paral-1 0/8 10s 10s
hanxiantaodeMBP:yamls hanxiantao$ kubectl get pods
NAME READY STATUS RESTARTS AGE
paral-1-9gs52 1/1 Running 0 22s
paral-1-vjc5v 1/1 Running 0 22s
hanxiantaodeMBP:yamls hanxiantao$ kubectl get pods
NAME READY STATUS RESTARTS AGE
paral-1-7t6qf 0/1 Completed 0 102s
paral-1-9gs52 0/1 Completed 0 2m31s
paral-1-fps7x 0/1 Completed 0 107s
paral-1-hflsd 0/1 Completed 0 39s
paral-1-qfnk9 0/1 Completed 0 37s
paral-1-t5dqw 0/1 Completed 0 70s
paral-1-vjc5v 0/1 Completed 0 2m31s
paral-1-vqh7d 0/1 Completed 0 73s
3)Cronjob的创建及运行验证
cron.yaml:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date;echo Hello from ther Kubernetes Cluster
restartPolicy: OnFailure
startingDeadlineSeconds: 10
concurrencyPolicy: Allow
successfulJobsHistoryLimit: 3
hanxiantaodeMBP:yamls hanxiantao$ kubectl create -f cron.yaml
cronjob.batch/hello created
hanxiantaodeMBP:yamls hanxiantao$ kubectl get jobs
No resources found in default namespace.
hanxiantaodeMBP:yamls hanxiantao$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
hello-1609464960 1/1 4s 5s
hanxiantaodeMBP:yamls hanxiantao$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
hello-1609464960 1/1 4s 66s
hello-1609465020 1/1 3s 6s
由于这个CronJob是每分钟执行一次,所以一开始使用kubectl get jobs查看Job信息可能看不到,需要稍微等一下
4)、架构设计

Job Controller其实还是主要去创建相对应的pod,然后Job Controller会去跟踪Job的状态,及时地根据我们提交的一些配置重试或者继续创建。每个pod会有它对应的label,来跟踪它所属的Job Controller,并且还去配置并行的创建,并行或者串行地去创建pod
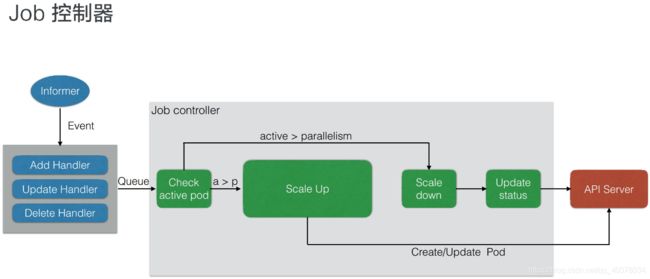
上图是一个Job控制器的主要流程。所有的job都是一个controller,它会watch这个API Server,每次提交一个Job的yaml都会经过api-server传到etcd里面去,然后Job Controller会注册几个Handler,每当有添加、更新、删除等操作的时候,它会通过一个内存级的消息队列,发到controller里面
通过Job Controller检查当前是否有运行的pod,如果没有的话,通过Scale up把这个pod创建出来;如果有的话,或者如果大于这个数,对它进行Scale down,如果这时pod发生了变化,需要及时Update它的状态
同时要去检查它是否是并行的job,或者是串行的job,根据设置的配置并行度、串行度,及时地把pod的数量给创建出来。最后,它会把job的整个的状态更新到API Server里面去,这样我们就能看到呈现出来的最终效果了
2、DaemonSet
1)、需求来源


2)、用例解读
1)DaemonSet语法

首先是kind:DaemonSet。DaemonSet的语法和Deployment有相同的部分,例如它会有matchLabel,通过matchLabel去管理对应所属的pod,这个pod.label也要和这个DaemonSet.controller.label相匹配,它才能去根据label.selector去找到对应的管理Pod。下面spec.container里面的东西都是一致的
这里用fluentd来做例子。DaemonSet最常用的点在于以下几点内容:
-
首先是存储,GlusterFS或者Ceph之类的东西,需要每台节点上都运行一个类似于Agent的东西,DaemonSet就能很好地满足这个诉求
-
另外,对于日志收集,比如说logstash或者fluentd,这些都是同样的需求,需要每台节点都运行一个Agent,这样的话,可以很容易搜集到它的状态,把各个节点里面的信息及时地汇报到上面
-
还有一个就是,需要每个节点去运行一些监控的事情,也需要每个节点去运行同样的事情,比如说Promethues这些东西,也需要DaemonSet的支持
2)查看DaemonSet状态

创建完DaemonSet之后,可以使用kubectl get DaemonSet(DaemonSet缩写为ds)。可以看到DaemonSet返回值和deployment特别像,即它当前一共有正在运行的几个,然后我们需要几个,READY了几个。当然这里面,READY都是只有Pod,所以它最后创建出来所有的都是pod
这里有几个参数,分别是:需要的pod个数、当前已经创建的pod个数、就绪的个数,以及所有可用的、通过健康检查的pod;还有NODE SELECTOR。NODE SELECTOR是节点选择标签,有时候我们可能希望只有部分节点去运行这个pod而不是所有的节点,所以有些节点上被打了标的话,DaemonSet就只运行在这些节点上
3)更新DaemonSet

其实DaemonSet和deployment特别像,它也有两种更新策略:一个是RollingUpdate,另一个是OnDelete
-
RollingUpdate就是会一个一个的更新。先更新第一个pod,然后老的pod被移除,通过健康检查之后再去建第二个pod,这样对于业务上来说会比较平滑地升级,不会中断
-
OnDelete其实也是一个很好的更新策略,就是模板更新之后,pod不会有任何变化,需要我们手动控制。我们去删除某一个节点对应的pod,它就会重建,不删除的话它就不会重建,这样的话对于一些我们需要手动控制的特殊需求也会有特别好的作用
3)、操作演示
1)DaemonSet的编排
daemonSet.yaml:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
containers:
- name: fluentd-elasticsearch
image: fluent/fluentd:v1.4-1
hanxiantaodeMBP:yamls hanxiantao$ kubectl create -f daemonSet.yaml
daemonset.apps/fluentd-elasticsearch created
hanxiantaodeMBP:yamls hanxiantao$ kubectl get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd-elasticsearch 1 1 1 1 1 35s
hanxiantaodeMBP:yamls hanxiantao$ kubectl get pods
NAME READY STATUS RESTARTS AGE
fluentd-elasticsearch-h9jb9 1/1 Running 0 2m17s
2)DaemonSet的更新
hanxiantaodeMBP:yamls hanxiantao$ kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=fluent/fluentd:v1.4
daemonset.apps/fluentd-elasticsearch image updated
hanxiantaodeMBP:yamls hanxiantao$ kubectl rollout status ds/fluentd-elasticsearch
daemon set "fluentd-elasticsearch" successfully rolled out
4)、架构设计

DaemonSet还是一个controller,它最后真正的业务单元也是Pod,DaemonSet其实和Job controller特别相似,它也是通过controller去watch API Server的状态,然后及时地添加pod。唯一不同的是,它会监控节点的状态,节点新加入或者消失的时候会在节点上创建对应的pod,然后同时根据你配置的label去选择对应的节点
DaemonSet的控制器,DaemonSet其实和Job controller做的差不多:两者都需要根据watch这个API Server的状态。现在DaemonSet和Job controller唯一的不同点在于,DaemonsetSet Controller需要去watch node的状态,但其实这个node的状态还是通过API Server传递到etcd上
当有node状态节点发生变化时,它会通过一个内存消息队列发进来,然后DaemonSet controller会去watch这个状态,看一下各个节点上是都有对应的Pod,如果没有的话就去创建。当然它会去做一个对比,如果有的话,它会比较一下版本,然后加上刚才提到的是否去做RollingUpdate?如果没有的话就会重新创建,Ondelete删除pod的时候也会去做check它做一遍检查,是否去更新,或者去创建对应的pod
当然最后的时候,如果全部更新完了之后,它会把整个DaemonSet的状态去更新到API Server上,完成最后全部的更新
六、应用配置管理
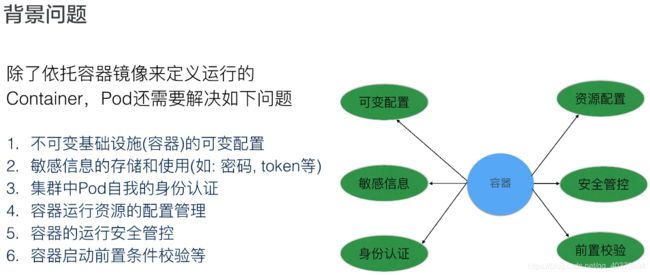
1、需求来源

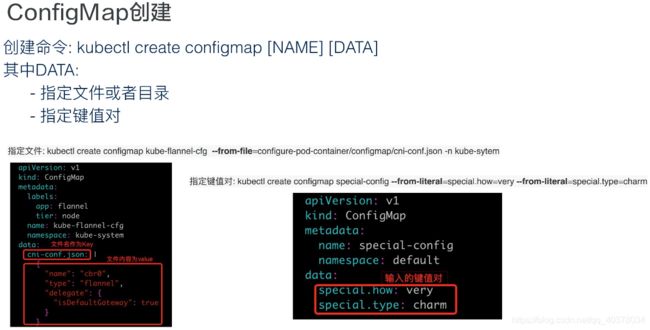
2、ConfigMap



3、Secret





4、ServiceAccount


5、Resource


6、SecurityContext

7、InitContainer

课程地址:https://edu.aliyun.com/roadmap/cloudnative?spm=5176.11399608.aliyun-edu-index-014.4.dc2c4679O3eIId#suit