2020-12-31
ElasticSearch之将网页上爬取的数据传到elasticsearch中。
我们一般会将数据保存到elasticsearch中来实现搜索。
项目源码: github地址
1.从网页爬取数据
网页解析数据一般会用Jsoup包。首先引进来吧。
接下来,我会从彼岸图网这个网站爬取一些图片,(仅测试娱乐,无商业用途)并将信息保存到elasticsearch上。
开始吧。
新建一个springboot项目。引入jsoup包。以及会用到的json解析包。
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.10.2version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.58version>
dependency>
创建一个类,
HtmlParseUtil.java:

复制如下代码:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.URL;
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
//你要解析那个网址
String url = "http://pic.netbian.com/e/search/result/?searchid=16";
//解析网页返回document对象
Document document = Jsoup.parse(new URL(url),30000);
// Element element = document.getElementById("J_goodsList");
// System.out.println(element);
Elements elements = document.getElementsByClass("slist");
// System.out.println(elements);
//获取所有的li元素
Elements elements1 = elements.first().getElementsByTag("li");
for (Element el : elements1){
String img = el.getElementsByTag("img").eq(0).attr("src");
String name = el.getElementsByTag("b").eq(0).text();
System.out.println("-------------------------------------------------------------");
System.out.println(img);
System.out.println(name);
}
}
}
代码讲解。
1.你要搜索的网址,后面那个?searchid=16就是你搜索的东西,你可以改成其他的。
//你要解析那个网址
String url = "http://pic.netbian.com/e/search/result/?searchid=16";
2.解析网页。
得到的这个document 对象,就是网页中的dom元素对象,你可以按照js那样操作它。
//解析网页返回document对象
Document document = Jsoup.parse(new URL(url),30000);
3.根据id或者class来操作
注意,这里的slist是怎么来的。你打开彼岸图网,搜索“美女”(搜索的东西自定义),然后f12,
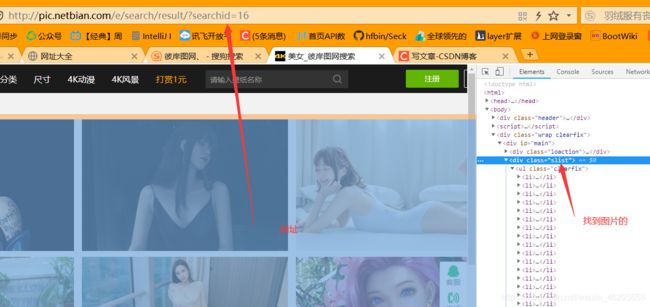
Elements elements = document.getElementsByClass("slist");
注意,保证你的电脑有网。运行测试一下,检查控制台输出的东西。
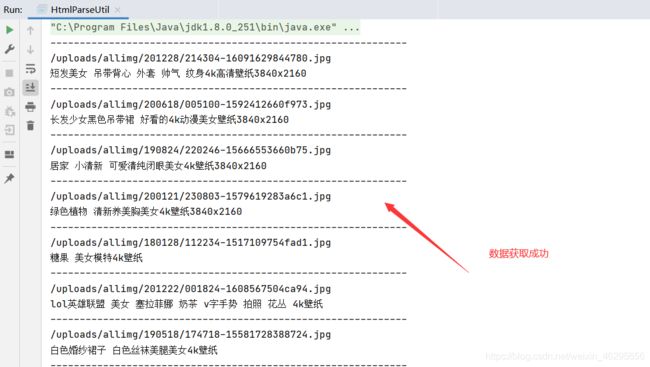
成功之后,把这个方法封装成一个工具类。以便调用。
import com.example.boot_es.pojo.Tupian;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
@Component
public class HtmlParseUtil {
public static void main(String[] args) throws Exception {
new HtmlParseUtil().parseHtml("12");
}
public List<Tupian> parseHtml(String keywords) throws Exception {
//你要解析那个网址
String url = "http://pic.netbian.com/e/search/result/?searchid="+keywords;
//解析网页返回document对象
Document document = Jsoup.parse(new URL(url), 30000);
// Element element = document.getElementById("J_goodsList");
// System.out.println(element);
Elements elements = document.getElementsByClass("slist");
// System.out.println(elements);
//获取所有的li元素
Elements elements1 = elements.first().getElementsByTag("li");
ArrayList<Tupian> allimage = new ArrayList<>();
for (Element el : elements1) {
String img = el.getElementsByTag("img").eq(0).attr("src");
String name = el.getElementsByTag("b").eq(0).text();
System.out.println("-------------------------------------------------------------");
System.out.println(img);
System.out.println(name);
Tupian tupian = new Tupian();
tupian.setImg(img);
tupian.setName(name);
allimage.add(tupian);
}
return allimage;
}
}
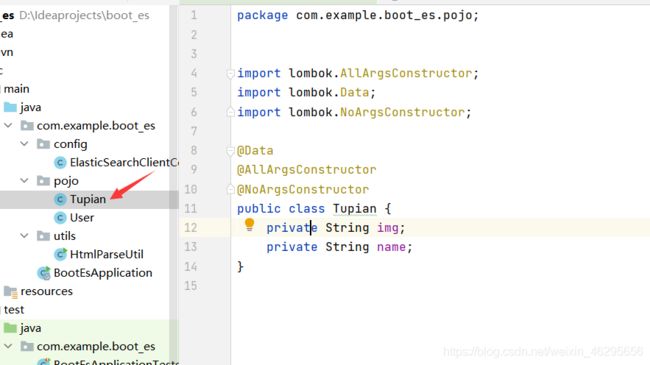
Tupian.java:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Tupian {
private String img;
private String name;
}
2.保存到ElasticSearch中。
数据获取成功之后。就要保存到elasticsearch中了。
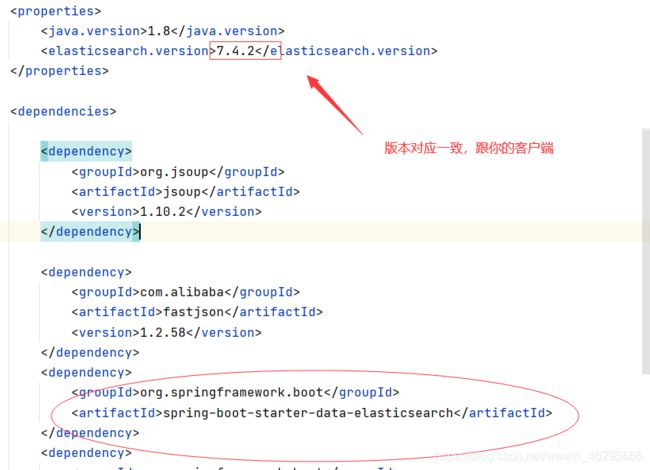
首先整合elastic search
自己添加pom依赖。注意版本,跟你下载的要一致。
ElasticSearchClientConfig.java
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1",9200,"http")));
return client;
}
}
TupianService.java
import com.alibaba.fastjson.JSON;
import com.example.boot_es.pojo.Tupian;
import com.example.boot_es.utils.HtmlParseUtil;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@Service
public class TupianService {
private final static String INDEX_NAME ="biantu_index";
@Autowired
private RestHighLevelClient restHighLevelClient;
//1解析数据放入到elasticsearch
public Boolean parseTupian(String keywords) throws Exception {
List<Tupian> alldata = new HtmlParseUtil().parseHtml(keywords);
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("1m");
for (int i = 0; i < alldata.size(); i++) {
bulkRequest.add(
new IndexRequest("biantu_index")
.source(JSON.toJSONString(alldata.get(i)), XContentType.JSON));
}
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulkResponse.hasFailures();
}
//2.获取这写数据实现搜索功能。
public List<Map<String, Object>> searchPage(String keyword, int pageNo, int pageSize) throws IOException {
if (pageNo <= 1) {
pageNo = 1;
}
//条件搜索。
SearchRequest searchRequest = new SearchRequest(INDEX_NAME);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//结果解析
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
list.add(documentFields.getSourceAsMap());
}
return list;
}
}
TupianController.java
import com.example.boot_es.pojo.Tupian;
import com.example.boot_es.service.TupianService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.List;
import java.util.Map;
@RestController
public class TupianController {
@Autowired
private TupianService tupianService;
@GetMapping("/parse/{keyword}")
public Boolean parse(@PathVariable("keyword") String keyword) throws Exception{
return tupianService.parseTupian(keyword);
}
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String,Object>> search(
@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize
) throws IOException {
return tupianService.searchPage(keyword,pageNo,pageSize);
}
这里写了两个方法,一个方法是把解析出来的数据放入到elasticsearch中;第二个方法是通过关键字来搜索elasticsearch中的数据并渲染到网页上。
3.测试
1.先来测试第一个,把数据放入到elastic search中。
浏览器输入: http://localhost:8080/parse/14
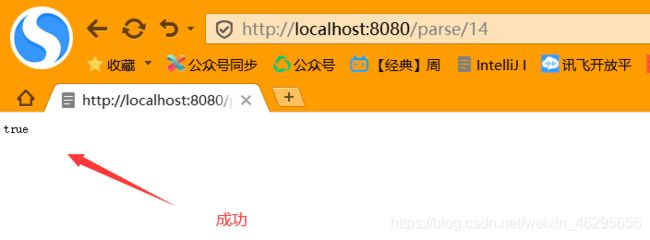
如果返回的是 true,则表示保存成功。
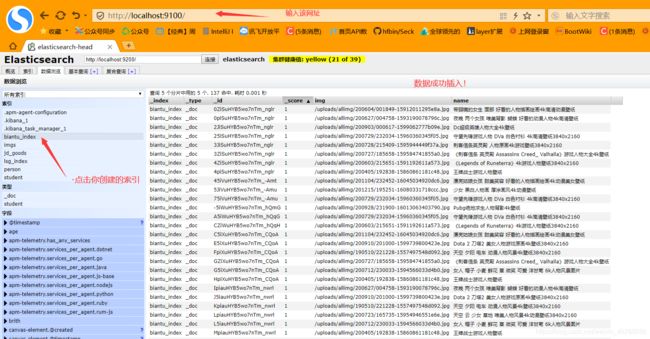
返回elasticsearch查看结果:成功插入进来!
接下来测试第二个方法。
通过关键字搜索,输入网址:localhost:8080/search/4k/1/10 。 表示的意思是。查询name中包含4k的数据,并且显示前10条。成功!

接下来就可以通过Vue来绑定这些数据渲染到网页上了。
下一篇博客地址: 将数据渲染到网页上