NDK入门篇:C语言基础
目录
写在前面
一、Linux内存布局原理
二、函数
2.1、函数定义
2.2、指针函数
2.3、函数指针
三、指针数组
3.1、数组
3.2、指针数组
3.3、数组指针(行指针)
四、结构体
4.1、结构体定义
4.2、内存对齐
五、共用体
六、动态库
6.1、库的概念
6.2、编译动态库
写在前面
前两天在看Android系统从开机到SystemServer进程以及服务创建这部分知识的时候,有很多C++的代码,所以就打算抽个一两天把C和C++这部分的东西稍微预习下,哈哈我都不敢说是复习,让自己能稍微看懂点。于是乎就有了本篇内容的诞生,遂将其放入了NDK专栏中,那么废话咱也不多说了,开搞!
一、Linux内存布局原理
①、内存定义
- 硬件角度:内存是计算机必不可少的一个组成部分,是与CPU沟通的桥梁,计算机中所有的程序都是运行在内存中的。
- 逻辑角度:内存是一块具备随机访问能力,支持读、写操作,用来存放程序及程序运行中产生的数据的区域。
②、内存单位
- 位(bit):是计算机中最小的数据单位,每一位的状态只能是0或1
- 字节:1Byte=8bit,是内存基本的计量单位
- KB:1KB=1024Byte,也就是1024个字节
- MB:1MB=1024KB,类似的还有GB、TB
③、内存编址
计算机中的内存按字节编址,每个地址的存储单元可以存放一个字节(8个bit)的数据,CPU通过内存地址获取指令和数据,并不关心这个地址所代表的空间具体在什么位置、怎么分布,因为硬件的设计保证一个地址对应着一个固定的空间,所以说:内存地址和地址指向的空间共同构成了一个内存单元。
④、内存地址及分配规则
- 内存地址:内存地址通常用十六进制的数据表示,指向内存中某一块区域。
- 内存地址分配规则:内存分配规则是连续的,一个挨着一个。当对象需要申请内存时,先给这个对象分配一个编码,这个编码就是内存地址
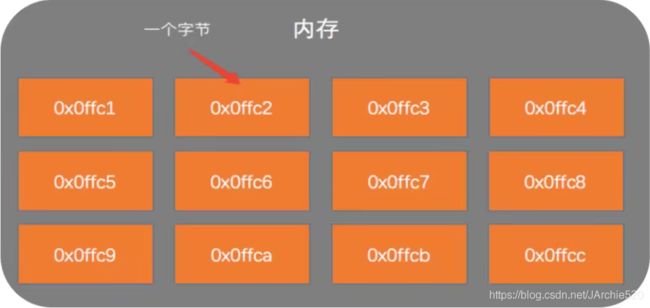
比如:上图就是一张内存地址的分布图,在每个字节中指向的都是一个对象,至于这个对象在哪里不用去管,我们需要知道的是这一系列的编码是连续性的。
⑤、内存对象
指针指向的内存区域存储的就是内存对象,内存对象可以是不同的类型,具体都有哪些类型呢?
- Int:4字节
- Short:2字节
- long:4字节
- char:1字节
- double:8字节
- long double:10字节
- 引用类型
问题: C里面long类型为什么只有4个字节?
long和int在早期16位电脑的时候int 2个字节,long 4个字节,而计算机发展到现在,一般32位和64位机器下long和int一样。而Java中的long类型是8个字节
⑥、内存组成
首先来看Android的内存组成:
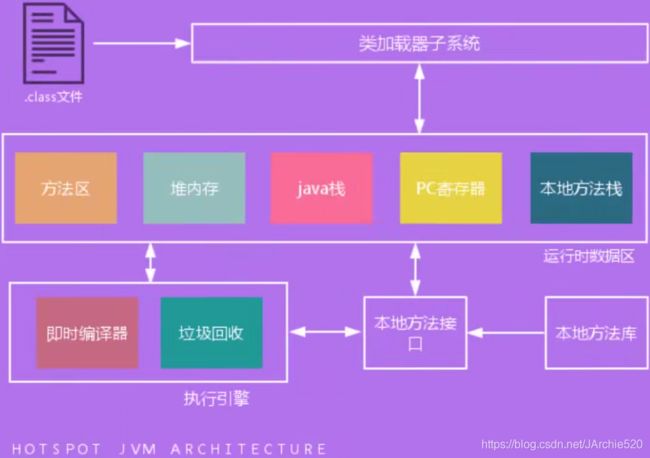
Android APP是基于虚拟机进行加载的,内存分配如上图所示,图中的内存都是在虚拟机中的,虚拟机是由C和C++进行开发的,这些内存脱离了虚拟机其实是不存在的。下面要说的C的内存分配是基于本地硬件环境的,相比于安卓内存要简单的多:

栈:栈又称堆栈,存放程序的局部变量(但不包括static声明的变量,static 意味着 在数据段中 存放变量)。除此以外,在函数被调用时,栈用来传递参数和返回值。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。储动态内存分配,需要开发人员手工分配,手工释放
堆:堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc/free等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张)/释放的内存从堆中被剔除(堆被缩减)
BSS段:通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
数据段:数据段(data segment)通常是指用来存放程序中已经初始化的全局变量的一块内存区域。数据段属于静态内存分配。
代码段:代码段就是程序中的可执行部分,直观理解代码段就是函数组成的。
二、函数
2.1、函数定义
函数和Java中的方法是一个概念,C是面向过程的,它的核心载体就是函数。
定义:函数是一组一起执行一个任务的语句。每个C程序都至少有一个函数,即主函数main(),所有简单的程序都可以定义其他额外的函数。
//返回值 函数名 参数列表
return_type function_name(parameter list){
body of the function //函数体
}举个最简单的例子:
#include
//定义函数func,返回值类型为int,入参类型为void,意为无参数
int func(void) {
printf("这是一个简单的函数"); //打印一句话
return -1; //随便给它一个返回值
}
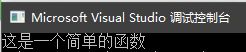
int main()
{
func(); //在main函数中进行调用
} 结果很显然,正确打印出了一句话:
注意:这里不能把func()函数定义在main()函数的下面,比如这样:
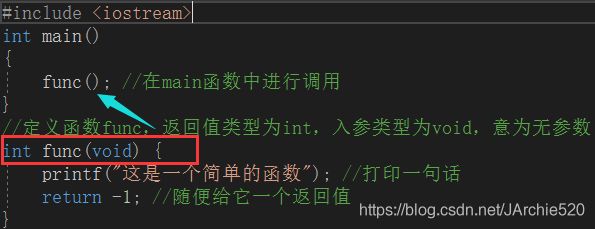
这样写编译器会报错:
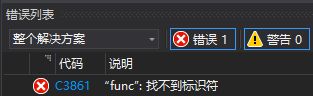
原因:在C语言中函数的执行是由上至下进行加载的,所以当它执行到main()函数的时候,它没有发现func()函数,所以会报错。这一点跟Java是不一样的,因为Java是面向对象的,它会把整个class文件加载到内存中,所以它不会有上下这种概念。C语言的这种执行方式更类似于前端的DOM解析,也是由上至下进行解析。
解决方案:针对于上面的这种情况有两种解决方案,第一种就是像上面最开始那样,把func()函数定义在main()函数的上面,第二种方式是另外定义一个头文件.h,然后在.c文件中引入:
//类似于Java中的接口,只有函数的声明,没有函数的实现
int func(void);
int func(int a, int b);#include //系统的头文件用<>引进来
#include "CTest.h" //自己的头文件用""引进来
int main()
{
func(); //在main函数中进行调用
func(1, 2);
}
//定义函数func,返回值类型为int,入参类型为void,意为无参数
int func(void) {
printf("这是一个简单的函数"); //打印一句话
return -1; //随便给它一个返回值
}
int func(int a,int b) {
printf("\n这是一个函数的重载"); //打印一句话
return -1; //随便给它一个返回值
} 这样再去执行就不会有任何的问题了:

2.2、指针函数
定义:指针函数是指带指针的函数,即本质是一个函数。函数返回类型是某一类型的指针。比如:

举个例子:
//返回值类型为int*,入参void*为无符号类型指针,相当于Java中的Object,所以这里只要是指针类型都OK
int* pointerFuc(void* param) {
printf("指针函数");
int a = 100;
int *b = &a;
return b; //这里返回值为指针类型,使用取址符获取变量a的地址
}
int main()
{
int a = 10;
pointerFuc(&a); //传递指针类型
}![]()
2.3、函数指针
指针函数是一个函数,它的返回值类型是一个指针,接下来要说的函数指针它不是一个函数,而是一个变量。
定义:函数指针是指向函数的指针变量,即本质是一个指针变量。比如:

举个例子:
CTest.h
//声明了一个变量,只不过这个变量是函数
void(*funcp)(int a); //(*func)小括号代表它的优先级,一定要写
void point_func(int a);CTest.c
int main()
{
funcp = point_func; //把函数赋值给上面定义的指针变量,赋值的过程中不会产生调用
funcp(4); //手动调用funcp(),这里才会产生调用
}
void point_func(int a) {
printf("函数指针\n");
}执行结果:
三、指针数组
3.1、数组
数组是一个数据的集合,在内存中的体现是一块连续性的内存区域,比如,我们可以声明一个int类型的数组,长度为3,然后使用一个指针*p指向数组的首地址,这样就可以通过指针来操作数组:
#include ;
int main() {
//定义int类型的数组
int arr[] = {10,20,30};
for (int i = 0; i < 3; i++){
printf("数组元素 %d\n", arr[i]);
}
int*p = arr; //将arr赋值给指针p,指向数组的第一个元素
*p = 88; //将数组第一个元素修改为10
for (int i = 0; i < 3; i++)
{
printf("修改后的数组元素 %d\n", arr[i]);
}
return 0;
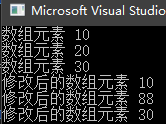
} 执行结果为:

上面的例子中指针默认是指向数组的首地址的,下面我们通过指针运算来修改数组的第二个元素,此时我们只需要修改 *p=88; 这一行代码即可,将指针加1修改为*(p+1) = 88; 这样一来,结果也就变成了下面这样:
3.2、指针数组
指针数组顾名思义数组中的每个元素都是指针,比如有一个数组arr,它的每个元素都存放了一个地址,每个地址都指向了一个变量,这样的数组我们就称之为指针数组。
下面我们就来定义一个指针数组:
#include ;
int main() {
int arr[] = {10,20,30};//定义int类型的数组
int *p[3]; //指针数组
//补充:指针优先级 () > [] > *
for (int i = 0; i < 3; i++)
{
p[i] = &arr[i]; //为指针数组中的每个元素进行赋值,&是取地址符
printf("操作后数组元素%d\n", *p[i]); //*代表指向的那个变量
}
return 0;
} 
注意:在指针数组中 int *p[3]; 这种表达式是有优先级的,定义优先级顺序为:()>[ ]>*
3.3、数组指针(行指针)
定义:int (*p)[n]
优先级高,首先说明p是一个指针,指向一个整型的一维数组,长度为n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。

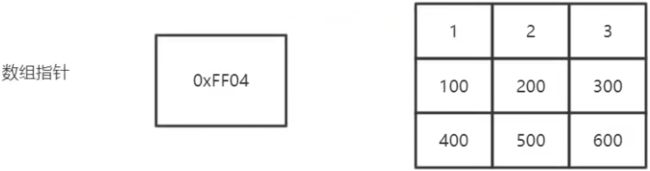
指针数组:代表的是一个数组,每个元素存放的是一个地址
数组指针:不是一个数组,只是一个变量,存放的是一个指针,它的步长发生了变化,它是指向一个二维数组的首地址,如果对当前指针进行+1操作,它会指向第二行的首地址,它和指针数组的表现形式是完全不一样的。举个例子如下:

四、结构体
4.1、结构体定义
结构体类似于Java中的Java Bean,可以将一些变量封装成一个对象,同样的在C语言中,我们可以将一些变量封装成一个结构体,下面来看结构体是如何表示的?下面介绍三种定义方式:
第一种:
#include ;
//Student相当于类名
struct Student
{
int height;
int age;
};
int main() {
struct Student stu; //声明一个struct类型的变量,类似于Java中的private Person p;
stu.height= 175; //赋值
stu.age = 18;
return 0;
} 第二种:
#include ;
//h和a表示结构变量,也就是Student类型的变量
struct Student
{
int height;
int age;
}h,a;
int main() {
h.height = 175;
h.age = 18;
return 0;
} 第三种:
#include ;
//使用typedef定义
typedef struct {
int height;
int age;
}Student;
int main() {
Student stu;
stu.height = 175;
stu.age = 18;
return 0;
} 4.2、内存对齐
在介绍这个概念之前,我们重新来定义结构体并且打印该结构体的大小是多少:
#include ;
//使用typedef定义
typedef struct {
int height;
short age;
}Student;
int main() {
Student stu;
stu.height = 175;
stu.age = 18;
printf("结构体大小%d", sizeof(stu));
return 0;
} ![]()
嗯?一个int类型,一个short类型,怎么变成8了呢?在C语言中,给对象结构体分配内存的时候,它会遵循内存对齐的规则。
定义:对齐跟数据在内存中的位置有关。如果一个变量的内存地址正好位于它长度的整数倍,它就被称作自然对齐。比如在32位cpu下,假设一个整型变量的地址为0x00000004,那么它就是自然对齐的。
当结构体需要内存过大,使用动态内存申请。结构体占用字节数和结构体内字段有关,指针占用内存就是4/8字节,因此传指针比传值效率更高。
结构体存储原则:
- 结构体变量中成员的偏移量必须是成员大小的整数倍(0被认为是任何数的整数倍)
- 结构体大小必须是所有成员大小的整数倍,也即所有成员大小的公倍数
在32位操作系统中,数据总线是32位,地址总线是32位。由于地址总线是32位,意味着寻址空间是按4递增的,数据总线32位一次可读写4byte。
接着来看这样一个结构体:

按照常理来说一共应该是占用6个字节,但实际上却是这样的:

五、共用体
共用体和结构体类似,都是表示数据类型的集合,只不过结构体内存开销更大一些。
定义:共用体是一种特殊的数据类型,允许在相同的内存位置存储不同的数据类型。可以定义一个带有多成员的共用体,但是任何时候只能有一个成员带有值。共用体提供了一种使用相同的内存位置的有效方式。举个例子如下:
union Data
{
int i;
float f;
char str[20];
}data;共用体占用的内存应足够存储共用体中最大的成员。比如在上面的案例中,在各个成员变量中,char占用的空间是最大的,所以整个Data将占用20个字节的内存空间。
下面来一起定义一个共用体:
#include ;
union MyStudent
{
int i;
float f;
};
int main() {
union MyStudent myStu;
myStu.i = 10;
myStu.f = 11;
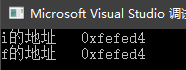
printf("i的地址 %#x\n", &myStu.i);
printf("f的地址 %#x\n", &myStu.f);
return 0;
} 执行结果为:可以看到共用体中每个成员的起始地址都是一样的,只不过在内存中分别表示的是不同的成员变量
接着来修改下代码:
#include ;
union MyStudent
{
int i;
int j;
};
int main() {
union MyStudent myStu;
myStu.i = 10;
printf("之前 %d\n", myStu.i);
myStu.j = 11;
printf("i的地址 %#x\n", &myStu.i);
printf("f的地址 %#x\n", &myStu.j);
printf("之后 %d\n", myStu.i);
printf("之后 %d\n", myStu.j);
return 0;
}
执行结果如下:

此时我们发现了一个奇怪的结果,给j赋值之后,i和j的值都变成了11,这是为什么呢?
因为:它在内存上为了节约开辟的空间大小,将之前i值的内存区域重新复用给j值,这种复用场景一般用在共用体中有很多变量的声明,最开始初始化的时候i值在代码中被使用到,但是在下面的代码中i值就不需要了,这种节约内存的性能是非常高的。
六、动态库
6.1、库的概念
在windows平台和Linux平台下都存在大量的库,Android中同样也是。库顾名思义,指的是一个容器文件,里面装的是函数,由于windows和Linux的平台不同(主要是编译器、汇编器和连接器的不同),因此二者库的二进制是不兼容的。
库的种类:库分为动态库和静态库,下图中分别是(前者为Linux平台,后者为Windows平台)不同库的表现形式:

6.2、编译动态库
如何编译一个动态库呢?看下图的流程:

下面我们来简单的实际操作一下,首先创建一个test.h头文件:

接着创建test.c文件,然后来实现上面的test()函数:
最后我们使用gcc命令行来编译生成.so文件:

补充:编译静态库使用-static,动态库使用-shared
最后再来总结一下动态库与静态库的区别:
- 静态库文件比较大,动态库比较小
- 静态库需要在编译时被链接在目标代码中,动态库在运行时才会被加载到目标代码
- 静态库类似于Android中的Module,一旦打包APK需要重新进行编译
- 动态库类似于Jar包,打包不需要重新进行编译
这里只是简单的介绍了一下动态库和静态库的基本含义,后面还会详细说,这里有个基本的了解就行了。
OK,关于C语言基础部分就先说这么多吧,咱们下一篇再见!
祝:工作顺利!