基于PyTorch的GRU网络实现股票价格预测
参考:https://www.7forz.com/3319/
根据Tushare的数据,用LSTM的变体GRU试着做一个股票价格预测,参考了上述博客的代码,大多数参数经过了调整。
1. 用新晨科技(300542)的640天的收盘数据训练
2. 在沪深A股代码中随机抽取50条用于测试
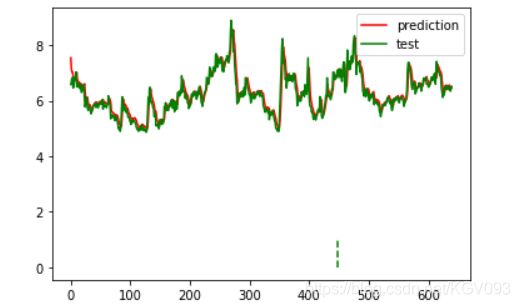
3. 查看50条里面loss最大的一支股票,画出其数据与预测曲线(有明显误差但趋势大致相同)
预测的结果比预期好很多,留个坑--Midterm考完回来研究解释......
2020.10.27 更一波:
似乎把训练次数降到800可以比较好地防止过拟合?
代码:
# -*- coding: utf-8 -*-
"""main.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1W2_OxJ3JcWnvnG8wugwms-ETq0pRYX_v
"""
import numpy as np
import pandas as pd
pip install tushare
import tushare as ts
data = ts.get_k_data('300542')['close'].values
print(data.shape)
import matplotlib.pyplot as plt
data = data.astype('float32')
mx = np.max(data)
mn = np.min(data)
data = (data - mn) / (mx - mn)
input_len = 1
def generate_dataset(data, days_for_train):
dataset_x, dataset_y = [], []
for i in range(len(data) - days_for_train):
cur_x = data[i:(i + days_for_train)]
cur_y = data[i + days_for_train]
dataset_x.append(cur_x)
dataset_y.append(cur_y)
return np.array(dataset_x), np.array(dataset_y)
import torch
import torch.nn as nn
import torch.optim as optim
print(torch.cuda.is_available())
print(torch.cuda.device_count())
print(torch.cuda.get_device_name(0))
dataset_x, dataset_y = generate_dataset(data, input_len)
train_len = int(len(dataset_x) * 0.7)
train_x, train_y = dataset_x[:train_len], dataset_y[:train_len]
train_x, train_y = torch.from_numpy(train_x), torch.from_numpy(train_y)
train_x = train_x.reshape(-1, 1, input_len)
train_y = train_y.reshape(-1, 1, 1)
class Regression(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers):
super().__init__()
self.gru = nn.GRU(input_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, output_size)
#self.dropout = nn.Dropout(p=0.1)
def forward(self, _x):
x, _ = self.gru(_x)
s, b, h = x.shape
x = x.reshape(s * b, h)
x = self.fc(x)
x = x.reshape(s, b, 1)
#x = self.dropout(x)
return x
loss_function = nn.MSELoss()
epochs = 1000
model = Regression(input_len, hidden_size=10, output_size=1, num_layers=1)
opt = optim.SGD(model.parameters(), lr=0.2)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
train_x = train_x.to(device)
train_y = train_y.to(device)
model.train()
for epoch in range(epochs):
opt.zero_grad()
out = model.forward(train_x)
loss = loss_function(out, train_y)
loss.backward()
opt.step()
if (epoch + 1) % 100 == 0:
print("Epoch", epoch+1)
print("Loss:", loss.item())
model = model.eval()
dataset_x = dataset_x.reshape(-1, 1, input_len)
dataset_x = torch.from_numpy(dataset_x).to(device)
pred = model.forward(dataset_x)
pred = pred.reshape(len(dataset_x))
pred = torch.cat((torch.zeros(input_len), pred.cpu()))
pred = pred.detach().numpy()
assert len(pred) == len(data)
plt.plot(pred, 'r', label='prediction')
plt.plot(data, 'b', label='data')
plt.plot((train_len, train_len), (0, 1), 'g--')
plt.legend()
plt.show()
data *= (mx - mn)
data += mn
pred *= (mx - mn)
pred += mn
plt.plot(pred, 'r', label='prediction')
plt.plot(data, 'b', label='data')
plt.plot((train_len, train_len), (0, 1), 'g--')
plt.legend()
plt.show()
print("Predicted price of 2020.10.26:", pred[-1])
from google.colab import drive
drive.mount('/content/drive')
import os
import random
file = open("/content/drive/My Drive/Deep Learning/LSTM - Stock Price Prediction/ALL.txt", "r")
tot_list = []
for line in file.readlines():
tot_list.append(line.rstrip('\n'))
random.shuffle(tot_list)
test_list = random.sample(tot_list, 50)
max_loss = 0
max_index = None
i = 0
for i in range(len(test_list)):
cur = test_list[i]
test = ts.get_k_data(code=cur)['close'].values
test = test.astype('float32')
mx = np.max(test)
mn = np.min(test)
test = (test - mn) / (mx - mn)
testset_x, testset_y = generate_dataset(test, input_len)
test_len = int(len(testset_x) * 0.7)
test_x, test_y = testset_x[:test_len], testset_y[:test_len]
test_x, test_y = torch.from_numpy(test_x), torch.from_numpy(test_y)
test_x = test_x.reshape(-1, 1, input_len)
test_y = test_y.reshape(-1, 1, 1)
testset_x = testset_x.reshape(-1, 1, input_len)
testset_x = torch.from_numpy(testset_x).to(device)
pred = model.forward(testset_x)
pred = pred.reshape(len(testset_x))
pred = torch.cat((torch.zeros(input_len), pred.cpu()))
pred = pred.detach().numpy()
assert len(pred) == len(test)
test = torch.from_numpy(test[1:])
pred = torch.from_numpy(pred[1:])
loss = loss_function(test, pred)
print("No.", i, "Code -", cur)
print("Loss:", loss.item())
if max_loss < loss.item():
max_loss = loss.item()
max_index = i
test = ts.get_k_data(code=test_list[max_index])['close'].values
print("Test code:", test_list[max_index])
test = test.astype('float32')
mn = np.min(test)
test = (test - mn) / (mx - mn)
testset_x, testset_y = generate_dataset(test, input_len)
test_len = int(len(testset_x) * 0.7)
test_x, test_y = testset_x[:test_len], testset_y[:test_len]
test_x, test_y = torch.from_numpy(test_x), torch.from_numpy(test_y)
test_x = test_x.reshape(-1, 1, input_len)
test_y = test_y.reshape(-1, 1, 1)
testset_x = testset_x.reshape(-1, 1, input_len)
testset_x = torch.from_numpy(testset_x).to(device)
pred = model.forward(testset_x)
pred = pred.reshape(len(testset_x))
pred = torch.cat((torch.zeros(input_len), pred.cpu()))
pred = pred.detach().numpy()
assert len(pred) == len(test)
test = torch.from_numpy(test[1:])
pred = torch.from_numpy(pred[1:])
loss = loss_function(test, pred)
print("Test loss:", loss)
test *= (mx - mn)
test += mn
pred *= (mx - mn)
pred += mn
plt.plot(pred, 'r', label='prediction')
plt.plot(test, 'g', label='test')
plt.plot((test_len, test_len), (0, 1), 'g--')
plt.legend()
plt.show()训练集--新晨科技(300542):

测试集--维克技术(600152):
10000次:

800次: