当Top-k遇到深度学习
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
top-k操作(即从分数集合中找到k个最大或最小元素)是一个重要的机器学习模型组件,被广泛用于信息检索和数据挖掘中。但是,如果top-k操作是通过算法方式(例如使用冒泡算法)计算的,则无法使用现在流行的梯度下降算法以端到端的方式训练所得模型。这是因为这些计算方式通常涉及交换索引,无法用来计算其梯度。换句话说,从输入数据到该元素是否属于前k个集合的指标向量的对应映射是不连续的。
为了解决这个问题,我们提出了一个平滑的近似操作,即SOFT top-k运算符。具体来说,我们的SOFT top-k运算符将top-k运算的输出近似为最优传输问题的解。然后,我们基于最优传输问题的KKT条件快速地估算SOFT运算符的梯度。我们将提出的算子应用于k nearest neighbors分类和beam search算法,并通过实验展示了性能的提高。

谢雨佳:本科毕业于中国科学技术大学少年班学院,现为佐治亚理工学院CSE系第五年博士生,导师为查宏远教授和赵拓教授。她的研究方向主要为最优传输理论和端到端学习。

一、动机:如何将Top K 嵌入到深度学习框架中?
k nearest neighbors (kNN) classifier 是一个非常常见且实用的分类方法。具体来说,假设有很多已知label的template data,以及一个未知label的query data,我们可以将未知的query data与其他image相比,得到比较相似的k个图片,将其称为k nearest neighbors,并将这些 neighbors的label作为该未知data的label。对于image data,一个自然的做法是使用特征抽取网络(feature extraction)将这些image投影到一个embedding space里,并在这个embedding space中做kNN以得到对未知data的预测。然后我们最小化损失函数来更新特征抽取网络中的参数。但是,该模型框架的缺点在于:由于需要进行的top-k操作不可微,因此不能通过梯度下降法或者随机梯度下降法实现参数优化。
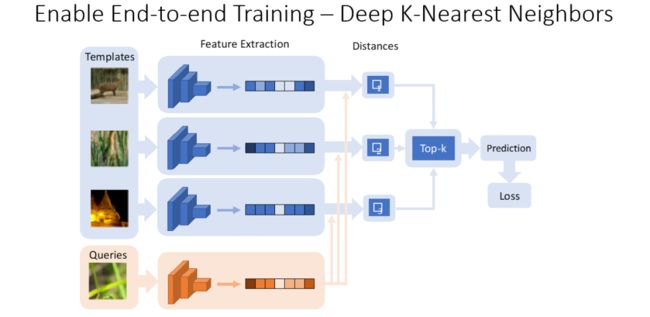
图1 深度k近邻网络结构示意图
为什么top-k 不可微?考虑一个top-k算法,比如,bubble,heap或者quick sort partition这些算法,实则是不断置换输入变量(input scores)的索引(indices),这个置换索引的操作是不可微的。从另一个角度出发,输入为“4 1 2 3 0 1 2”,然后得到排名第一的元素,若用一个identical director表示的话为“1 0 0 0 0 0 0”,当输入变为“5 3 1 0 2 2 1”时,输出不变。这说明,top k 操作本质上是一个分段常数映射(piecewise constant function),其梯度要么为0,要么不存在。这也进一步解释了,为什么该模型框架不能通过梯度下降法或者随机梯度下降法实现参数优化。基于此,讲者旨在设计一种能实现可微的top k operator。

图2 研究top-k 的深度学习网络的目标
二、如何使Top-K问题可微?
首先,将实现可微的top-k operator问题看作是一个最优运输问题,即把一个分布的mass运输到另一个分布上,并使运输成本最小。比如,有两个分布和,以及成本矩阵,那么问题就转化成如图中所示的优化问题,就代表了最终的运输计划。

图3 最优运输问题
回到top-k的问题上,假设现在有六个输入值,希望求取top-2的元素。对此,我们可以构造这样一个最优运输问题,其中是输入值的经验分布(在这六个值上,每个值上分布1/6的mass),是参数为k/N的伯努利分布。也就是说,在0上放置2/3的mass,在1上放置1/3的mass。根据最优运输的规则,最优运输方案 (Optimal Transport Plan, OT plan)就是将较大的两个数运输到1的位置,将较小的四个数运输到0的位置。基于此,可得到最优运输方案的matrix,其第二行就是所求的指示向量(indicate vector),若向量元素为1则表示该数为top k elements,为0时则不是。
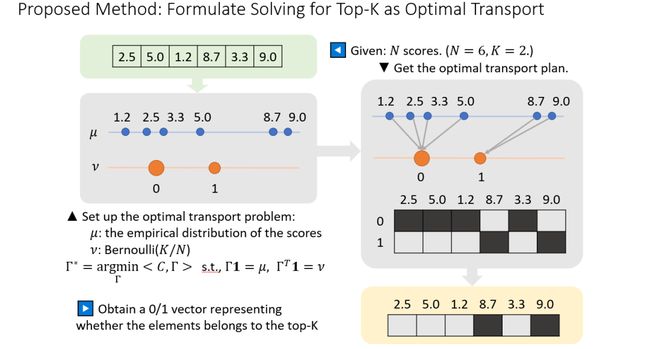
图4 将top-k问题视作最优运输问题
其次,怎样让top-k问题可微?讲者提出在上述的最优运输方案的基础上增加一项正则熵(entropy regularization)。主要是因为,最优运输问题是一个线性规划的问题,则其最优解几乎一定在可行域的顶点上,也就是说当输入(X)发生变化的时候,最优解会从可行域的一个顶点跳跃到另一个顶点上,这个过程是不可微的。增加了正则熵之后,得到最优解将是可行域的内点,当X发生变化时,也是平滑变化,这就可以使从X→的映射实现可微。

图5 top k 问题可微——增加正则熵
在很多应用中,不仅需要知道哪些元素是top-k,并且还需得知 top-k中k个元素的排序。因此,讲者做了如图6所示的修改,分布不再是伯努利分布,而是在0的位置上依旧分布2/3的mass,然后在1和2上分别分布1/6的mass。由此得到OT plan的matrices,并表示出哪一个得分最大,哪一个得分第二大。
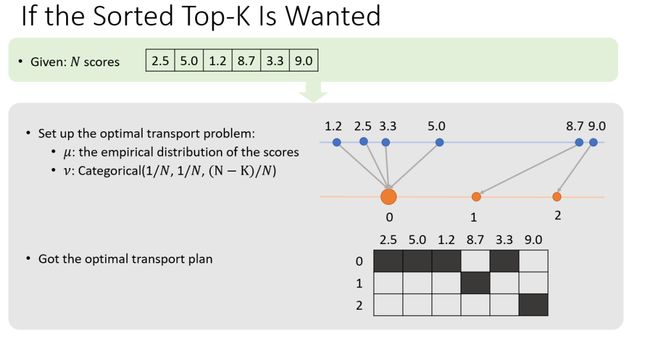
图6 top k 中k个元素的排序
具体地说,如何求解带有正则熵的OT plan问题?讲者介绍了一种专门求解带有正则熵的OT plan问题的算法——Sinkhorn 算法,该算法可循环迭代且线性收敛,同时算法的迭代次数与N无关,这说明算法的时间复杂度是O(N)。另外,为了将top-k嵌入到深度学习框架中,并使其可微,就不仅需要求出top-k 的元素是什么,还需要知道如何求解top-k 的梯度。一般来说,求导就是进行误差向后传播(back propagation),可直接使用自动微分法。但由于Sinkhorn 算法是一个迭代算法,因此在forward pass中,需要将迭代的中间变量都存到内存中,这不仅对内存的负担很大,而且求梯度的过程也会比较慢。因此,这里直接使用梯度的闭式解来求解,即在forward pass中求得top-k之后,通过简单的矩阵操作可得到梯度。
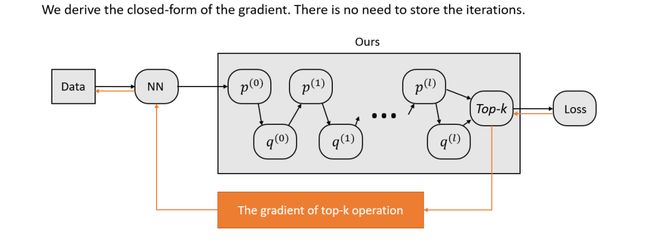
图7 梯度的 closed-form图解
由于是一个优化问题的最优解,因此与X的关系被KKT条件约束,由图8的推导,可得到top-k operator的闭式解。

图8 top k operator的梯度求解
但是,增加正则熵后得到的最优解并不是准确的top-k operator(由于正则项引入了bias),那么该如何量化这个bias?讲者通过对比增加了正则熵的与没有加正则熵的,证明该差别受限于下述表示,且当系数越来越大时,得到的解会越来越平滑。

图9 top k operator的梯度求解
三、实验验证
1)图像分类实验研究
通过与baselines对比可知,该方法可以有效提高分类精度。相比于文章中采用的基于kNN的端到端训练,作者着重强调了两个baselines,即kNN+pretrained CNN以及CE+CNN,前者使用两阶段训练:先用交叉熵来训练一个神经网络来作为特征提取器,将image编码到embedding space中,然后在embedding space中做kNN以得到一个预测;后者是直接结合交叉熵与CNN实现分类,结果如图10所示。
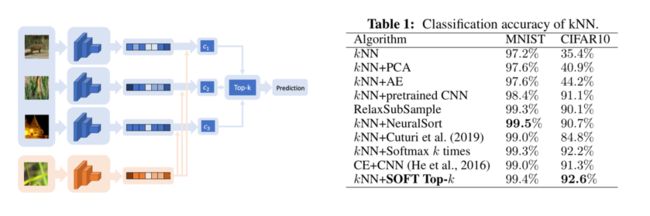
图10 图像分类结果对比
2)自然语言生成实验研究
在生成句子时(inference stage),需要模型一个字一个字生成(beam search),即从起始词开始,模型会选择前k个likelihood较大的词作为候选词,循环反复,最终选择likelihood最大的句子作为output。但在训练阶段,是利用ground truth sequence来训练模型,但问题是模型没有利用自己生成的词来进行训练,因此开始时模型生成的词如果有一点误差,在后续inference 阶段误差会被很快放大。

图11 Beam search training 算法
如果能够将beam search嵌入到training阶段,模型的training阶段和inference阶段就是完全一致的,这个问题就可以迎刃而解。然而由于beam search的每一步都需保留前k个likelihood最大的词,这是典型的top-k 操作,如何能将beam search嵌入到training阶段?
采用讲者提出的可微top-k operator实现beam search,即在每一步有Nk个选择以及vector of likelihood,将vector of likelihood放到sorted top-k operator中取top-k得到matrixes,将这个matrixes与所有词的embedding matrix相乘得到下一步的input,循环进行以得到一个likelihood最大的sequence,与ground truth sequence进行比较,实现training。
在WMT14的数据集上的实验,证明了加入beam search training的模型实现了不小的提高。

图12 嵌入top-k 的beam search training 网络和
基于beam search的实验验证
相关资料
文章下载二维码
Full paper: Differentiable Top-k with optimal transport, NeurIPS 2020

参考文献
Cuturi M . Sinkhorn Distances: Lightspeed Computation of Optimal Transportation Distances. NIPS, 2013.
https://dl.acm.org/doi/10.5555/2999792.2999868
Cuturi, M., Teboul, O. and Vert, J.-P.:Differentiable ranking and sorting using optimal transport. NIPS,2019.
e m t
往期精彩
AI i

整理:刘美珍
审稿:谢雨佳
排版:岳白雪
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(直播回放:https://b23.tv/qmP3rC)
(点击“阅读原文”下载本次报告ppt)