二十九、Linux安装Hive并更改Metastore依赖库
本文主要介绍如何在Linux上安装部署Hive,以及存储Hive Metastore的依赖库MySQL的安装。关注专栏《破茧成蝶——大数据篇》,查看更多相关的内容~
目录
一、安装Hive
1.1 下载安装包
1.2 Hive的安装部署
1.2.1 上传解压
1.2.2 修改配置文件
1.2.3 Hadoop集群配置
1.2.4 将Hive添加到环境变量
1.3 测试
二、Hive实例测试
2.1 启动Hive
2.2 创建表
2.3 加载本地数据
三、安装MySQL
四、将Hive Metastore配置到MySQL
4.1 拷贝驱动
4.2 修改配置文件
4.3 测试
一、安装Hive
1.1 下载安装包
首先我们需要去下载安装包,请点击这里下载对应的安装包,这里我们选择的是1.2.1版本的安装包。

1.2 Hive的安装部署
1.2.1 上传解压
1、将下载的安装包上传到master节点

2、解压到/opt/modules/目录下
tar -zxvf ./apache-hive-1.2.1-bin.tar.gz -C ../modules/
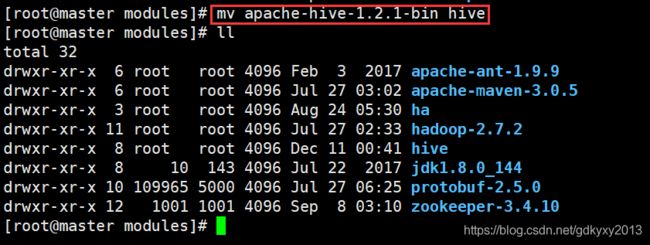
3、重命名
为了方便后续操作,我们这里对该目录重新命名一下。
1.2.2 修改配置文件
1、复制hive-env.sh.template文件
在Hive的conf目录下,复制一份hive-env.sh.template配置文件,如下:
cp hive-env.sh.template hive-env.sh
2、修改hive-env.sh文件
在hive-env.sh文件下配置Hadoop的路径已经Hive conf目录的路径。
HADOOP_HOME=/opt/modules/hadoop-2.7.2
export HIVE_CONF_DIR=/opt/modules/hive/conf
1.2.3 Hadoop集群配置
1、启动HDFS和Yarn,这里需要注意的是:Yarn的启动需要到安装ResourceManager的机器上启动,我们这里安装在了slave01上面。
start-dfs.sh
start-yarn.sh
2、在HDFS上创建/tmp和/user/hive/warehouse两个目录并修改他们的权限。
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir /tmp
hdfs dfs -chmod g+w /tmp
hdfs dfs -chmod g+w /user/hive/warehouse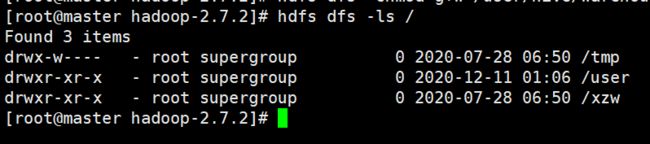
1.2.4 将Hive添加到环境变量
vim /etc/profile
##HIVE_HOME
export HIVE_HOME=/opt/modules/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile1.3 测试
输入hive进入命令行模式,可以进行简单的操作测试,语句跟SQL没什么差别。
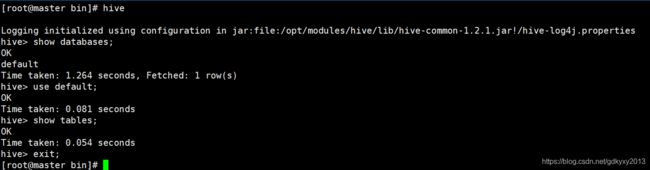
二、Hive实例测试
Hive安装完之后,我们来弄一个小例子简单的测试一下。
2.1 启动Hive
启动Hive,并新建一个数据库(xzw)。
hive
create database xzw;
2.2 创建表
这里我们创建一个people表,用来存放个人信息。people表有三个字段:id、姓名、性别,数据之间使用英文的逗号进行分割。
create table people(id int, name string, sex string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';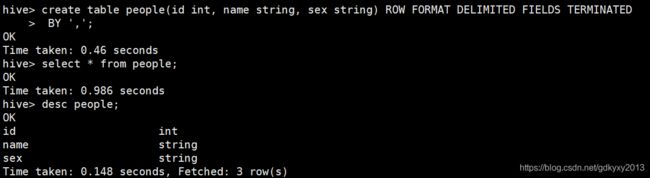
2.3 加载本地数据
1、首先需要在本地构造一部分数据。这里需要注意的是在建表的时候我们指定英文逗号为分隔符,在导数据的时候它会自动识别英文逗号作为字段的分割标志。

2、加载本地数据到Hive。
load data local inpath '/root/files/p.txt' into table people;
三、安装MySQL
一次不经意之间,我在另外一个窗口进入了Hive的命令行界面,然后就发生了下面的问题:

这是因为Metastore默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore。故有了MySQL的安装,具体安装过程可以参考《CDH6.3.1部署大数据集群》中(五、安装MySQL)的部分。这里就不再赘述了。
四、将Hive Metastore配置到MySQL
4.1 拷贝驱动
将数据库驱动拷贝的指定目录,如下图所示:

4.2 修改配置文件
1、新建hive-site.xml文件
touch hive-site.xml2、在hive-site.xml中添加如下内容
javax.jdo.option.ConnectionURL
jdbc:mysql://master:3306/metastore?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
p@ssw0rd
password to use against metastore database
4.3 测试
启动Hadoop集群,在master节点上打开多个窗口,在其中一个里面创建数据库,另外的窗口也能发现刚刚创建的数据库,证明配置成功。

这就是这篇文章的全部内容,你们在此过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了哪些问题~