微服务
nginx在linux下的使用以及SpringSession
nginx优势(反向代理、负载均衡)
- 作为 Web 服务器:相比 Apache,Nginx 使用更少的资源,支持更多的并发连接,体现更高的效率,能够支持高达 50,000 个并发连接数的响应。
- 作为负载均衡服务器:Nginx 既可以在内部直接支持 Rails 和 PHP,也可以支持作为 HTTP代理服务器 对外进行服务。Nginx 用 C 编写, 不论是系统资源开销还是 CPU 使用效率很优秀。
- 作为邮件代理服务器: Nginx 同时也是一个非常优秀的邮件代理服务器(最早开发这个产品的目的之一也是作为邮件代理服务器)。
- Nginx(还能够支持perl语法),Bugs非常少的服务器: Nginx 启动特别容易,并且几乎可以安装非常的简单,配置文件 非常简洁做到7*24不间断运行,即使运行数个月也不需要重新启动。你还能够在 不间断服务的情况下进行软件版本的升级。
nginx的安装
- 联网安装nginx相关的依赖( /opt 下安装 )
yum -y install zlib zlib-devel openssl openssl-devel
yum -y install patch
- 解压nginx压缩包
tar zxvf nginx-1.10.3.tar.gz
- 配置nginx编译环境( 检查是否有configure )
./configure --prefix=/usr/local/nginx --pid-path=/usr/local/nginx/nginx.pid --error-log-path=/usr/local/nginx/logs/error.log --http-log-path=/usr/local/nginx/logs/access.log --with-http_stub_status_module --with-http_ssl_module --with-http_gzip_static_module --with-http_realip_module --with-stream --http-client-body-temp-path=/usr/local/nginx/tmp/client/ --http-proxy-temp-path=/usr/local/nginx/tmp/proxy/
- 编译安装
- 在nginx目录下(/usr/local/nginx/),编译,执行 make
- 再执行 make install
- 验证nginx是否安装成功(出现版本号即安装成功)
/usr/local/nginx/sbin/nginx -V
- 配置nginx.conf(服务器集群)
- 不要忘记提前把域名和服务器IP绑定在一起。
vim /usr/local/nginx/conf/nginx.conf
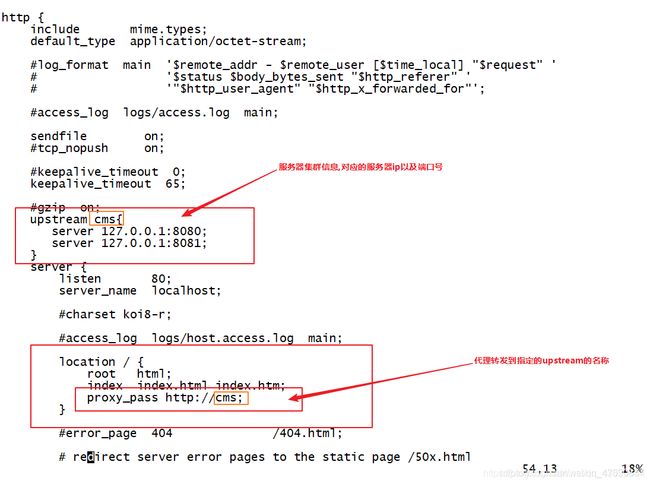
- 校验nginx配置文件
/usr/local/nginx/sbin/nginx -t
- 应该会报错缺少文件夹,创建文件夹
mkdir -p /usr/local/nginx/tmp/client
- 校验成功,启动nginx
/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
- 如果无法访问,80端口加入防火墙白名单,重启
firewall-cmd --permanent --zone=public --add-port=80/tcp
firewall-cmd --reload
/usr/local/nginx/sbin/nginx -s reload
nginx的访问分配策略
- 默认是轮询

流量限制
- 为防止用户恶意访问,可以在nginx设置限流,防止发生雪崩效应。
根据ip控制速率
limit_req_zone $binary_remote_addr zone=javasmlimit:10m rate=1r/s;
limit_req zone=javasmlimit burst=3 nodelay;
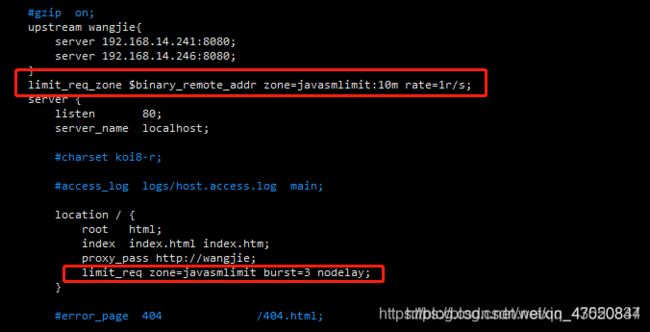
控制并发连接数
- http模块添加
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
- location模块添加
limit_conn perip 10;#单个客户端ip与服务器的连接数
limit_conn perserver 100; #限制与服务器的总连接数
# 限制传输速度(如果有N个并发连接,则是 N * limit_rate)
limit_rate 1024k;
流量限制不会提高服务器性能,但是能让服务器更加健壮。
静态文件服务器
- 修改nginx.conf
- 第一行
user root;
- 加入新的location
提前创建好文件夹,在文件夹中传入静态文件
mkdir -p /home/data
-
两种配置方式
- root配置
location /img/ { root /home/data/; }root是指定目录的上级目录,并且在指定的文件夹必须包含location指定名称的同名目录。
上面例子中,/home/data/目录下,必须有img文件夹才可以访问
请求路径:http://192.168.2.238/img/xxx.jpg
- alias配置
location /static/ { alias /home/data/; }alias是指定目录的虚拟路径,location指定的名称是代替文件目录的访问路径
上面例子中,浏览器中输入static可以代替/home/data路径
请求路径:http://192.168.2.238/static/img/xxx.jpg
location /static/ { alias /home/data/; }
跨域配置
允许全局的跨域
在server模块内,加入如下配置
# 指定允许跨域的方法,*代表所有
add_header Access-Control-Allow-Methods *;
# 预检命令的缓存,如果不缓存每次会发送两次请求
add_header Access-Control-Max-Age 3600;
# 带cookie请求需要加上这个字段,并设置为true
add_header Access-Control-Allow-Credentials true;
# 表示允许这个域跨域调用(客户端发送请求的域名和端口)
# $http_origin动态获取请求客户端请求的域 不用*的原因是带cookie的请求不支持*号
add_header Access-Control-Allow-Origin $http_origin;
# 表示请求头的字段 动态获取
add_header Access-Control-Allow-Headers
$http_access_control_request_headers;
# OPTIONS预检命令,预检命令通过时才发送请求
# 检查请求的类型是不是预检命令
if ($request_method = OPTIONS){
return 200;
}
允许指定路径跨域
在location模块内 加入如下配置
# 指定允许跨域的方法,*代表所有
add_header Access-Control-Allow-Methods *;
# 预检命令的缓存,如果不缓存每次会发送两次请求
add_header Access-Control-Max-Age 3600;
# 带cookie请求需要加上这个字段,并设置为true
add_header Access-Control-Allow-Credentials true;
# 表示允许这个域跨域调用(客户端发送请求的域名和端口)
# $http_origin动态获取请求客户端请求的域 不用*的原因是带cookie的请求不支持*号
add_header Access-Control-Allow-Origin $http_origin;
# 表示请求头的字段 动态获取
add_header Access-Control-Allow-Headers
$http_access_control_request_headers;
# OPTIONS预检命令,预检命令通过时才发送请求
# 检查请求的类型是不是预检命令
if ($request_method = OPTIONS){
return 200;
}
在代码种加入跨域配置
这里以springboot项目为例
如果使用vue等前后端分离请求,会携带Cookie等信息,但是服务器不能信任全部域名的Cookie,如果想访问,可以从客户端和服务端两种解决方案,这里说明在服务器端的设置代码。
@Configuration
public class CorsConfig {
private CorsConfiguration buildConfig() {
CorsConfiguration corsConfiguration = new CorsConfiguration();
corsConfiguration.addAllowedOrigin("*"); // 1允许任何域名使用
corsConfiguration.addAllowedHeader("*"); // 2允许任何头
corsConfiguration.addAllowedMethod("*"); // 3允许任何方法(post、get等)
corsConfiguration.setAllowCredentials(true);//支持安全证书。跨域携带cookie需要配置这个
corsConfiguration.setMaxAge(3600L);//预检请求的有效期,单位为秒。设置maxage,可以避免每次都发出预检请求
return corsConfiguration;
}
@Bean
public CorsFilter corsFilter() {
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
source.registerCorsConfiguration("/**", buildConfig()); // 4
return new CorsFilter(source);
}
}
SpringSession
- 分布式系统中,如何解决session共享问题?
- 一个浏览器在访问多个web服务器时,多个服务器之间的session对象需要共享数据。
- 使用SpringSession解决session共享问题。
- SpringSession介绍:
- SpringSession 是Spring家族中的一个子项目,Spring Session提供了用于管理用户会话信息的API和实现。
- 它把servlet容器实现的httpSession替换为spring-session,专注于解决 session管理问题,Session信息存储在Redis中,可简单快速且无缝的集成到我们的应用中;
SpringBoot+SpringSession+Redis示例
- 添加依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.springframework.sessiongroupId>
<artifactId>spring-session-data-redisartifactId>
dependency>
- 设置配置文件
spring:
redis:
host: 127.0.0.1
password: root
port: 6379
timeout: 3000
session:
store-type: redis
- 发现此时已经可以达到Session共享。
Redis高可用集群-哨兵模式
Linux下redis安装
- 解压redis的压缩包( opt文件夹下 )
tar zxvf redis-3.2.9.tar.gz
- 将redis的解压缩文件夹移到/usr/local
mv redis-3.2.9 /usr/local/
- cd到redis的源码目录
cd /usr/local/redis-3.2.9/src
- 编译redis源码
make
make test
- 修改redis.conf ( /usr/local/redis-3.2.9 文件夹下)
/xxx 查找搜索文档 n下一个
bind 绑定端口号注释 ##绑定后就只有这个IP可以访问
nrequirepass 打开注释 修改密码 ## 只修改密码就好了
- 端口号加入白名单
firewall-cmd --permanent --zone=public --add-port=6379/tcp
firewall-cmd --reload
- 启动redis服务
./redis-server ../redis.conf & (后台运行)
# 连接Redis:./redis-cli -h 127.0.0.1 -p 6379;auth:密码
# 输入指令exit退出
- 停止redis服务
ps -ef|grep redis 查看进程号
Kill -9 进程号 关闭进程号
哨兵集群模式
Redis集群
Redis实例默认就是master角色,以当前虚拟机三台redis为例,配置如下
创建Master
- 复制redis.conf 作为主库
cp redis.conf 6379.conf
- 修改主库配置
vim 6379.conf
- 按照具体的实例端口创建日志
mkdir /var/log/redis
- 相关配置
修改端口号
port=6379
修改进程id
pidfile /var/run/redis_6379.pid
注释bind 127.0.0.1,并添加密码
requirepass javasm
#bind 127.0.0.1
添加日志目录
logfile "/var/log/redis/redis-6379.log"
修改rdb文件名
dbfilename 6379.rdb
redis从库搭建
- 复制6379.conf 作为从库
cp 6379.conf 6380.conf
- 配置6380.conf 如上
参考相关配置
配置master的ip和端口号
slaveof ip地址 6379
ip使用局域网IP,不要使用127.0.0.1
配置master密码
masterauth root
- 配置6381.conf 如上
- 6380和6381加入防火墙白名单
firewall-cmd --permanent --zone=public --add-port=6380/tcp
firewall-cmd --permanent --zone=public --add-port=6381/tcp
firewall-cmd --reload
- 配置完成,启动。先启动主库,后启动从库。
哨兵集群
-
复制三份,端口号分别为:26379、26380、26381
-
需要修改:port、logfile、mymaster的IP、端口和连接密码。
-
相关配置
protected-mode no
port 26379
dir /tmp
logfile "/var/log/redis/sentinel.6379.log"
sentinel monitor mymaster 192.168.13.167 6379 2
sentinel auth-pass mymaster javasm
sentinel down-after-milliseconds mymaster 3000
sentinel failover-timeout mymaster 180000
- 注释
port 20086 #默认端口26379
dir "/tmp"
logfile "/var/log/redis/sentinel_20086.log"
daemonize yes
//格式:sentinel ;#该行的意思是:监控的master的名字叫做T1(自定义),地址为127.0.0.1:10086,行尾最后的一个2代表在sentinel集群中,多少个sentinel认为masters死了,才能真正认为该master不可用了。
sentinel monitor T1 127.0.0.1 10086 2
//sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了(subjectively down, 也简称为SDOWN)。而这个down-after-milliseconds就是用来指定这个“一定时间范围”的,单位是毫秒,默认30秒。
sentinel down-after-milliseconds T1 15000
//failover过期时间,当failover开始后,在此时间内仍然没有触发任何failover操作,当前sentinel将会认为此次failoer失败。默认180秒,即3分钟。
sentinel failover-timeout T1 120000
//在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态。
sentinel parallel-syncs T1 1
//sentinel 连接设置了密码的主和从
#sentinel auth-pass <master_name> xxxxx
//发生切换之后执行的一个自定义脚本:如发邮件、vip切换等
##sentinel notification-script <master-name> <script-path>
#sentinel client-reconfig-script <master-name> <script-path>
- 最好Redis三个配置保存一份 哨兵配置没成功会修改redis.conf到时候又要重新弄
- 将sentinel.6379.conf等三个 复制到Redis目录下(/usr/local/redis-3.2.9 文件夹下)
- 启动sentinel
在src目录下执行
./redis-server …/sentinel.6379.conf --sentinel &
./redis-server …/sentinel.6380.conf --sentinel &
./redis-server …/sentinel.6381.conf --sentinel &
- SpringBoot中配置
修改yml文件

测试
ps -ef|grep redis 查看进程

杀掉主库的进程 端口号是6379的进程
观察日志
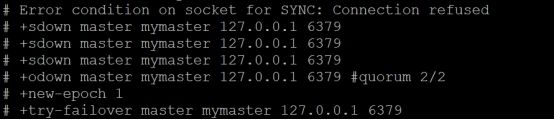
检测到主库宕机
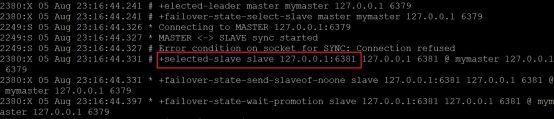
选举出了6381作为主库
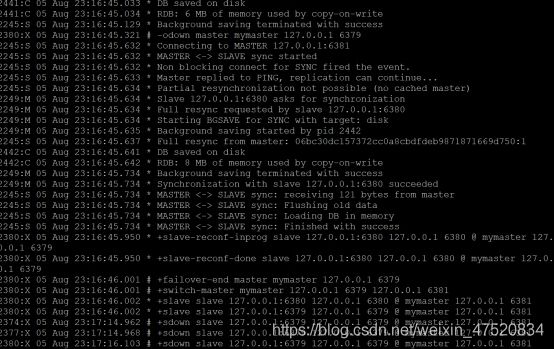
日志中可以看出,从库同步新的主库的数据,并且原来的6379变成了从库,此时的配置文件也被自动改变了。
l 进入6380客户端
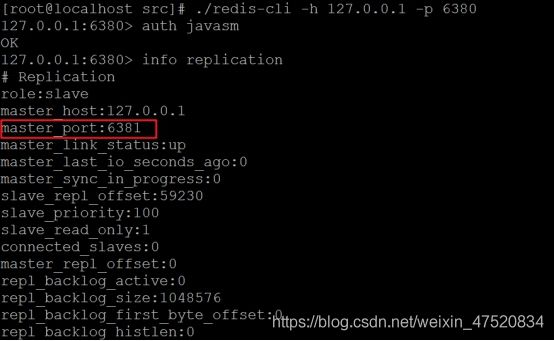
可以看见,此时的主库变成了6381
l 进入6381客户端
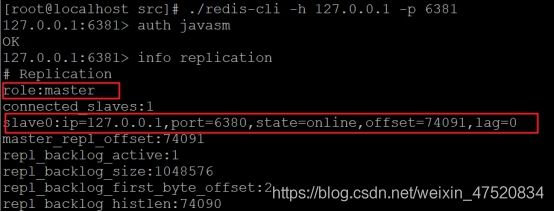
可以看见6381角色变成了主库,并且有一个从库6380
l 启动6379
如果启动报错,是同步数据时出错,修改redis.conf配置文件,masterauth属性
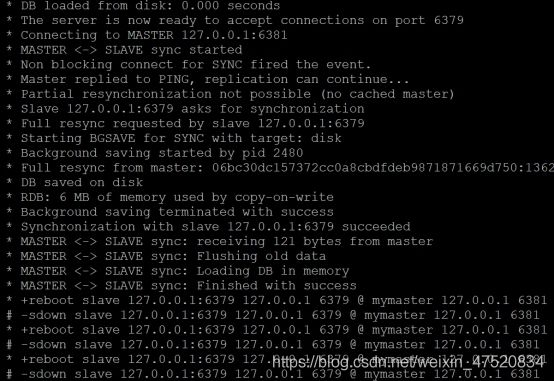
启动自动去同步数据
l 再次查看6381客户端
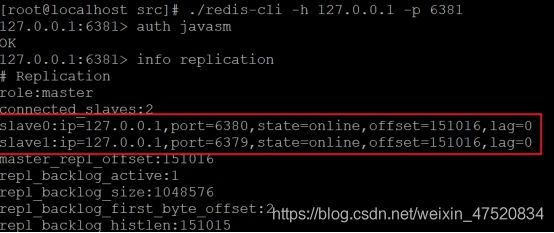
可以看见6381的从库多了一个6379
l 查看6379客户端
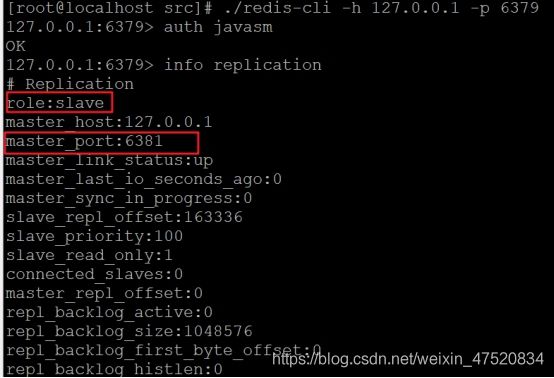
6379已经变成了从库
mycat
linux下mysql安装
/opt 目录下创建mysql文件夹
mkdir mysql
解压mysql的压缩包至mysql文件夹下
tar xvf mysql-5.7.20-1.el7.x86_64.rpm-bundle.tar -C mysql/
删除Mysql的MariaDB依赖
rpm -qa|grep mariadb [查找mariadb]
rpm -e mariadb包全名 --nodeps
mysql文件夹下依次安装mysql的rpm包(common,libs,client,server)
rpm -ivh mysql-community-common-5.7.20-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.20-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.20-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.20-1.el7.x86_64.rpm
启动mysql
service mysqld start
查找初始密码
vim /var/log/mysqld.log 或 grep password /var/log/mysqld.log
连接mysql
mysql -u root -p
修改密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Javasm123!';// 密码要求有大小写、数字、特殊字符
修改mysql访问权限
show databases; 查看库
use mysql; [进入mysql数据库]
show tables; 查看 库中有哪些表
update user set host='%' where user = 'root'; [更改用户的访问权限]
flush privileges; [刷新权限缓存]
3306加入白名单
firewall-cmd --permanent --zone=public --add-port=3306/tcp
firewall-cmd --reload
mycat安装,读写分离配置
- 从定义和分类来看,它是一个开源的分布式数据库系统,是一个实现了 MySQL 协议的Server,前端用户可以把它看作是一个数据库代理。
- 其核心功能是读写分离,分表分库,即将一个大表水平分割为 N 个小表,存储在后端 MySQL 服务器里或者其他数据库里。
- Mycat是一个Java应用,所以安装环境需要依赖JDK(1.7以上)
- 配置完成启动时,保证主从数据库都要有配置的库。
解压Mycat安装包
tar zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
将文件夹移至/usr/local/
mv mycat /usr/local/
修改server.xml(mycat/conf目录下)
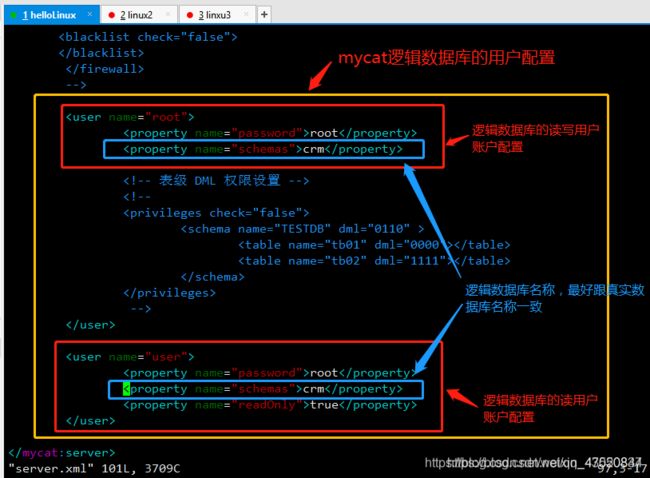
修改schema.xml
schema配置文件是用来描述逻辑数据库中的数据节点和读写库配置信息。
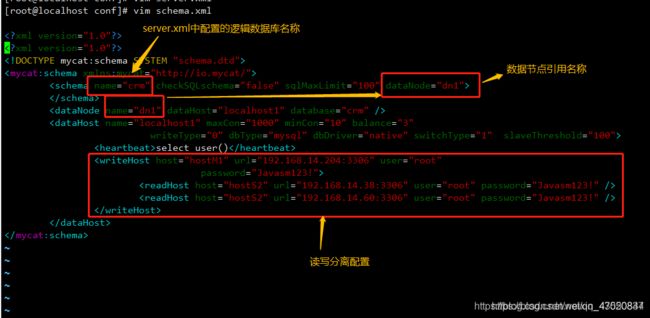
mycat端口号加入白名单
firewall-cmd --permanent --zone=public --add-port=8066/tcp
firewall-cmd --reload
12
测试mycat
bin目录下Mycat 运行命令
- ./mycat start 启动
- ./mycat stop 停止
- ./mycat restart 重新启动
查看Mycat运行日志
- tail –f mycat.log
调整日志等级
- 修改log4j2.xml的日志等级为debug
使用mysql命令登入Mycat
- mysql -u root -p -P8066 -h 127.0.0.1
1234567891011
主从同步配置
设置主库mysql的配置文件
- 编辑/etc/my.cnf
添加服务id配置 在/etc/my.cnf里面加上:
server-id=1 (保证唯一)
开启二进制日志文件(通过日志控制同步) 在/etc/my.cnf里面加上:
log-bin=/var/lib/mysql/mysql-bin
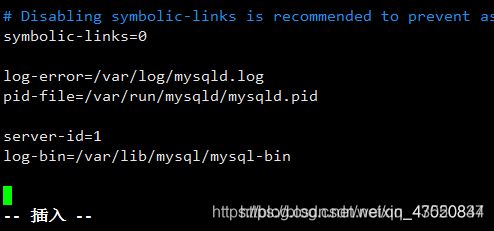
- 重启mysql
service mysqld restart
- 连接数据库
mysql -u root -p
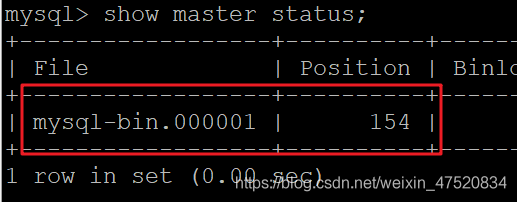
- 执行sql,复制File和Position的值,需要给slave(从库)使用
show master status;
设置从库mysql的配置文件
- 编辑/etc/my.cnf
添加服务id配置:
server-id=2(保证唯一)
- 重启mysql
- 连接数据库
- 执行指令
stop slave;
- 执行指令
change master to master_host='主库IP',
master_port=3306, master_user='主库用户名',
master_password='主库密码',
master_log_file='主库刚刚查到的File值',
master_log_pos= Position值;
- 执行指令
start slave;
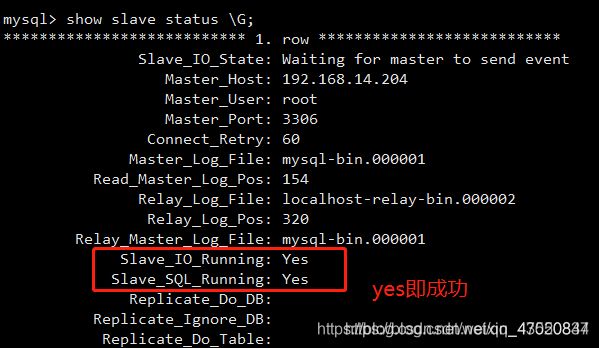
- 查看slave状态
show slave status \G;
查看Slave_IO_Running=yes Slave_SQL_Running=yes
分库分表配置
同一个数据库下的分表操作
- navcat执行查询(编写一个创建表的存储过程函数)
DELIMITER $$
USE `crm`$$
DROP PROCEDURE IF EXISTS `pro_TableCreate`$$
CREATE DEFINER=`root`@`%` PROCEDURE `pro_TableCreate`(
)
BEGIN
DECLARE i INT;
DECLARE table_name VARCHAR(20);
SET i = 0;
WHILE i<100 DO
IF i<10 THEN
SET table_name = CONCAT('pn_book_0',i);
ELSE
SET table_name = CONCAT('pn_book_',i);
END IF;
SET @csql = CONCAT(
'CREATE TABLE ',table_name,'(
`bid` bigint(20) NOT NULL AUTO_INCREMENT COMMENT "数据整合后,花生统一的图书id序列号",
`book_id` bigint(20) NOT NULL COMMENT "书籍ID",
`book_name` varchar(50) NOT NULL COMMENT "书籍名称",
`author_name` varchar(50) DEFAULT NULL COMMENT "作者名称",
`attribution` tinyint(4) DEFAULT NULL COMMENT "1.男频 2.女频 3.出版",
`ftype_id` int(11) DEFAULT NULL COMMENT "一级分类ID",
`stype_id` int(11) DEFAULT NULL COMMENT "二级分类ID",
`status` int(2) DEFAULT NULL COMMENT "书籍状态:1连载 2完本",
`is_vip` tinyint(1) DEFAULT NULL COMMENT "是否收费:0免费 1收费",
`description` varchar(1000) DEFAULT NULL COMMENT "图书简介",
`cover_url` varchar(100) DEFAULT NULL COMMENT "封面url地址",
`keyword` varchar(50) DEFAULT NULL COMMENT "图书关键字",
`word_count` varchar(20) DEFAULT NULL COMMENT "图书当前总字数",
`last_update_chapter_id` int(10) DEFAULT NULL COMMENT "最新章节ID",
`last_update_chapter_name` varchar(50) DEFAULT NULL COMMENT "最新章名",
`isRecommand` tinyint(1) NOT NULL DEFAULT "0" COMMENT "是否推荐首页:1推荐 0不推荐",
`bookPartner` bigint(20) DEFAULT "0" COMMENT "小说合作商户id",
`read_count` int(11) DEFAULT "1000" COMMENT "阅读人数",
PRIMARY KEY (`bid`),
KEY `bid` (`bid`,`book_name`)
) ENGINE=InnoDB AUTO_INCREMENT=1001058 DEFAULT CHARSET=utf8 COMMENT="创别图书表";'
);
PREPARE create_stmt FROM @csql;
EXECUTE create_stmt;
SET i = i+1;
END WHILE;
END$$
DELIMITER ;
-
执行完成后,会新增有一个函数

-
右键运行函数
-
分表完成
- 如果配有主从同步,从库中也会有新增的分表。
- 在任一从库中新增分表,主库及其他从库均不会实时新增,函数也不会生成。
需要理解mycat的几个概念。
MyCAT目前通过配置文件的方式来定义逻辑库和相关配置:
MYCAT_HOME/conf/schema.xml中定义逻辑库,表、分片节点等内容;
MYCAT_HOME/conf/rule.xml中定义分片规则;
MYCAT_HOME/conf/server.xml中定义用户以及系统相关变量,如端口等。
mycat的好处就是你可以使用他就像使用真的mysq数据库一样,jdbc该怎么连,命令行该怎么敲就怎么敲,sql语句该怎么写就怎么写,它的出现让你的业务代码持久层不用动,而背后,却能帮搭建起mysql的分表,分库,读写分离,集群分布式。
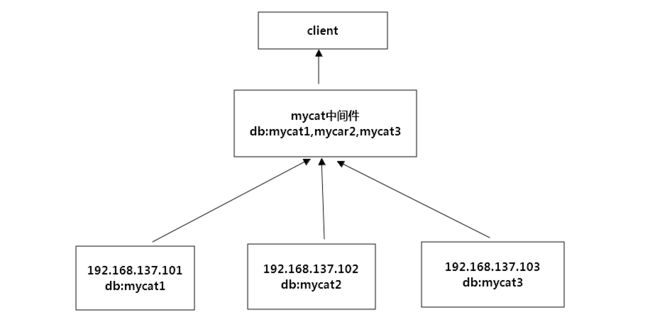
下面就简单使用mycat来帮助我们将业务数据表进行垂直切分和水平切分
垂直切分搭建
垂直切分其实就是根据业务的不同,将不同业务的表放到不同的数据库中,例如我们订单表,用户表,用户评论表,因为他们业务的不同,可以将他们分别放到三个数据库中。好,那我们就使用三个数据库,分别安装三张表,使用mysql架构如下:
数据库水平切分
除了可以按照业务将数据表分配到不同的的数据库中做成垂直切分,很多时候,用户量大的时候,例如一张用户表有上亿条数据,那么一次性查数据肯定很慢,那么我们可以这样子,将这张表按照某种规则将数据存放到不同的数据库中,例如可以按照用户省份的不同,将数据切分到广东省,北京市,上海市等数据库中。下面假如我们有一张student表,因为数据量太多,就按照id的取余规则,将数据分别存放到俩个数据库中,架构如下:
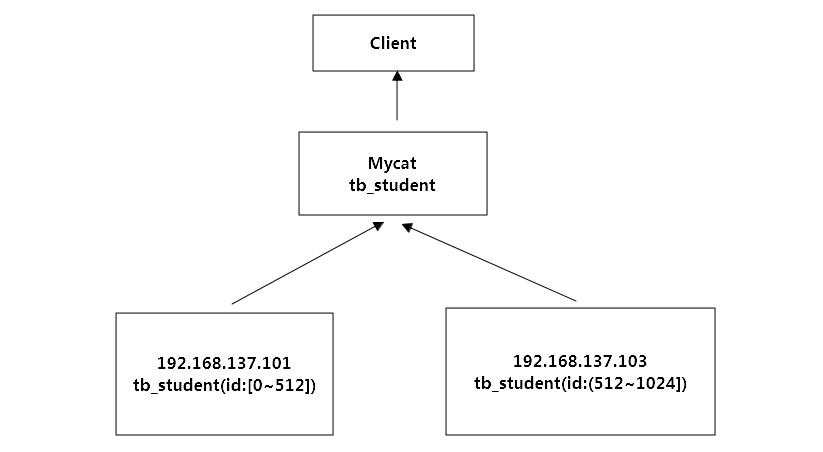
垂直切分
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="javasm" checkSQLschema="false" sqlMaxLimit="100">
<!--menu_test表 会在dn1和dn2两个库中随机访问 -->
<table name="menu_test" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<!--goods_test表 只访问dn1 -->
<table name="goods_test" primaryKey="ID" type="global" dataNode="dn1" />
</schema>
<!--database是必须真实存在的 库 上面配置的表 必须真实存在库里-->
<dataNode name="dn1" dataHost="localhost1" database="goods" />
<dataNode name="dn2" dataHost="localhost2" database="menu" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.12.173:3306" user="root"
password="Javasm123!">
</writeHost>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.12.174:3306" user="root"
password="Javasm123!">
</writeHost>
</dataHost>
</mycat:schema>
水平切分
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="javasm" checkSQLschema="false" sqlMaxLimit="100">
<table name="goods_test" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="goods-1" />
<dataNode name="dn2" dataHost="localhost1" database="goods-2" />
<dataNode name="dn3" dataHost="localhost1" database="goods-3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.12.173:3306" user="root"
password="Javasm123!">
<readHost host="hostS2" url="192.168.12.174:3306" user="root" password="Javasm123!" />
</writeHost>
</dataHost>
</mycat:schema>
solr
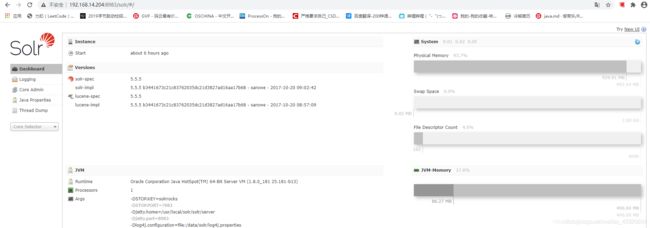
solr简介
- Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
- Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况
为什么要用全文搜索搜索引擎
之前,有同事问我,为什么要用搜索引擎?我们的所有数据在数据库里面都有,而且 Oracle、SQL Server 等数据库里也能提供查询检索或者聚类分析功能,直接通过数据库查询不就可以了吗?确实,我们大部分的查询功能都可以通过数据库查询获得,如果查询效率低下,还可以通过建数据库索引,优化SQL等方式进行提升效率,甚至通过引入缓存来加快数据的返回速度。如果数据量更大,就可以分库分表来分担查询压力。
那为什么还要全文搜索引擎呢?我们主要从以下几个原因分析:
- 数据类型
全文索引搜索支持非结构化数据的搜索,可以更好地快速搜索大量存在的任何单词或单词组的非结构化文本。
例如 Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。 - 索引的维护
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对SQL的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
什么时候使用全文搜索引擎:
- 搜索的数据对象是大量的非结构化的文本数据。
- 文件记录量达到数十万或数百万个甚至更多。
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。
linux下安装solr
解压solr
tar zxvf solr-5.5.5.tgz
创建Solr数据和安装目录
mkdir -p /data/solr /usr/local/solr
安装solr(进入 solr-5.5.5/bin/ 目录)
./install_solr_service.sh /opt/solr-5.5.5.tgz -d /data/solr -i /usr/local/solr/
Solr安装时,会自动创建一个solr用户,可以进入/etc/passwd中查看( 如果创建了可省略 )
cat /etc/passwd
如未创建用户则进行手工创建
groupadd solr
useradd -g solr solr
给Solr用户授权,防止创建core无权限的情况
chown -R solr.solr /data/solr /usr/local/solr
查看Solr状态
service solr status
Solr命令
启动 service solr start
停止 service solr stop
重新启动 service solr restart
创建一个新的core
su - solr -c "/usr/local/solr/solr/bin/solr create -c javasm(core名称) -n data_driven_schema_configs"
core相当于一个文档集,存放着文档,文档字段类型配置,索引等等信息
将solr端口加入防火墙白名单
firewall-cmd --permanent --zone=public --add-port=8983/tcp
firewall-cmd --reload
访问Solr管理界面
http://192.168.14.204:8983
solr与springboot的简单集成
- 添加依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-solrartifactId>
dependency>
- yml加入solr连接参数
spring:
data:
solr:
host: http://192.168.11.217:8983/solr
- service代码
// javasm为安装时创建的core
@Service
public class SolrServiceImpl implements SolrService {
@Resource
private SolrClient solrClient;
@Override
public String add(Integer aid, String aname) {
// TODO: 添加到数据库
if (aid != null && !StringUtils.isEmpty(aname)) {
new Thread(() -> {
// TODO: 添加到redis
// 添加到solr
SolrInputDocument sid = new SolrInputDocument();
sid.addField("aid", aid);
sid.addField("aname", aname);
try {
solrClient.add("javasm", sid);
solrClient.commit("javasm");
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}).start();
return "success";
}
return "error";
}
@Override
public SolrDocumentList query(String query) {
if (!StringUtils.isEmpty(query)) {
// 创建查询对象
SolrQuery solrQuery = new SolrQuery();
// 设置检索条件
solrQuery.setQuery(query);
try {
// 获得响应对象
QueryResponse query1 = solrClient.query("javasm", solrQuery);
// 从响应对象中获取数据
SolrDocumentList results = query1.getResults();
return results;
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
}
RocketMQ入门
什么是MQ
-
消息队列(Message Queue),是一种应用程序对应用程序的通信方法,是分布式系统的重要组件。
-
Github 上关于 RocketMQ 的介绍:
RcoketMQ 是一款低延迟、高可靠、可伸缩、易于使用的消息中间件。具有以下特性:
-
支持发布/订阅(Pub/Sub)和点对点(P2P)消息模型
-
在一个队列中可靠的先进先出(FIFO)和严格的顺序传递
-
支持拉(pull)和推(push)两种消息模式
-
单一队列百万消息的堆积能力
-
支持多种消息协议,如 JMS、MQTT 等
-
分布式高可用的部署架构,满足至少一次消息传递语义
-
提供 docker 镜像用于隔离测试和云集群部署
-
提供配置、指标和监控等功能丰富的 Dashboard
官方网站:http://rocketmq.apache.org/
阿里介绍:http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/
-
为何用消息队列
可以解决一些应用场景的高并发问题。
当不需要立即获得结果,但是并发量又需要进行控制的时候,差不多就是需要使用MQ来处理。
消息队列在实际应用中包括如下四个场景
- 解除耦合:多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败;
- 异步处理:多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间;
- 削峰填谷:广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况;
- 消息驱动的系统:系统分为消息队列、消息生产者、消息消费者,生产者负责产生消息,消费者(可能有多个)负责对消息进行处理。
linux下安装RocketMQ
- 安装jdk
- 安装maven
解压缩
tar xvf apache-maven-3.6.0-bin.tar.gz
移动文件夹到/usr/local目录下
mv apache-maven-3.6.0 /usr/local/
- 配置maven环境变量
vim /etc/profile
文件末尾追加:
export MAVEN_HOME=/usr/local/apache-maven-3.6.0
export MAVEN_HOME
export PATH=${PATH}:${MAVEN_HOME}/bin
刷新配置文件
source /etc/profile
- 修改配置文件setting.xml
<mirror>
<id>aliyunid>
<mirrorOf>centralmirrorOf>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
mirror>
- 安装Git
yum -y install git (直接上传压缩包可以不用安装git)
- 下载RockeMQ源码
git clone -b release-4.1.0-incubating https://github.com/apache/incubator-rocketmq.git
cd incubator-rocketmq
此步骤可以文件上传
解压源码
如果没有安装unzip 执行:yum -y install unzip
unzip rocketmq-all-4.3.0-source-release.zip
移动到/user/local目录下
- 编译
在rocket目录下执行
mvn -Prelease-all -DskipTests clean install -U
- 启动

到编译之后的路径下
cd distribution/target/apache-rocketmq
先修改rocket内存大小,默认虚拟机内存不足以启动
修改bin目录下文件 runbroker.sh 修改内存大小
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn125m"
修改bin目录下文件 runserver.sh 修改内存大小
JAVA_OPT="${JAVA_OPT} -server -Xms512m -Xmx512m -Xmn256m -XX:PermSize=128m -XX:MaxPermSize=320m"
关闭防火墙
systemctl stop firewalld
后台启动Name Server
nohup sh bin/mqnamesrv &
查看日志
tail -f ~/logs/rocketmqlogs/namesrv.log
ctrl+c 退出
后台启动Broker
nohup sh bin/mqbroker -n 192.168.13.145:9876 autoCreateTopicEnable=true &
查看日志
tail -f ~/logs/rocketmqlogs/broker.log
端口加入防火墙白名单
firewall-cmd --permanent --add-port=9876/tcp
firewall-cmd --reload
- 测试
> export NAMESRV_ADDR=localhost:9876
##发送消息
> sh bin/tools.sh org.apache.rocketmq.example.quickstart.Producer
##接收消息
> sh bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer
- 停止
##后启动的先停止
> sh bin/mqshutdown broker
> sh bin/mqshutdown namesrv
RocketMQ监控平台
解压
unzip rocketmq-externals-master.zip
#移动文件夹到/user/local下
>mv rocketmq-externals-master /usr/local/
#进入文件夹
>/usr/local/rocketmq-externals-master/rocketmq-console/src/main/resources
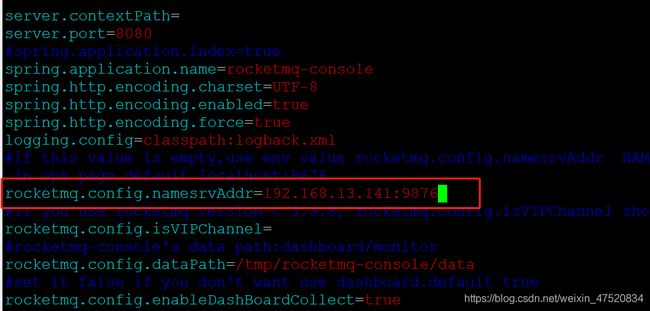
#修改配置文件
>vim application.properties
#进入文件夹
> cd /usr/local/rocketmq-externals-master/rocketmq-console/
执行编译指令
> mvn clean package -Dmaven.test.skip=true
编译成功之后会生成一个jar文件
启动指令
> java -jar target/rocketmq-console-ng-1.0.0.jar &
启动成功后,8080端口加入防火墙
请求地址:http://ip:8080/
Java调用
先关闭linux防火墙
因为使用的是虚拟机,设置内存也只有2G,所以从 Windows 上开发连接 虚拟机中的 nameServer 时要经过 Linux 系统的防火墙,而防火墙一般都会有超时的机制,在网络连接长时间不传输数据时,会关闭这个 TCP 的会话,关闭后再读写,就有可能导致异常(RemotingTooMuchRequestException: sendDefaultImpl call timeout)
> systemctl stop firewalld
创建maven项目,修改pom.xml
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
创建生产者测试类
public class Producer {
public static void main(String[] args) throws MQClientException, InterruptedException {
//声明并初始化一个producer
//需要一个producer group名字作为构造方法的参数
DefaultMQProducer producer = new DefaultMQProducer("javasm_producer");
//设置NameServer地址,此处应改为实际NameServer地址,多个地址之间用;分隔
//producer.setNamesrvAddr("192.168.13.141:9876;192.168.13.137:9876");
producer.setNamesrvAddr("192.168.13.141:9876");
//调用start()方法启动一个producer实例
producer.start();
//发送10条消息到Topic为TopicTest,tag为TagA
for (int i = 0; i < 10; i++) {
try {
Message msg = new Message("TopicTest",// topic
"TagA",// tag
("Hello Javasm RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET)// body
);
//调用producer的send()方法发送消息
//这里调用的是同步的方式,所以会有返回结果
SendResult sendResult = producer.send(msg);
//打印返回结果,可以看到消息发送的状态以及一些相关信息
System.out.println(sendResult);
} catch (Exception e) {
e.printStackTrace();
Thread.sleep(1000);
}
}
//发送完消息之后,调用shutdown()方法关闭producer
producer.shutdown();
}
}
创建消费者测试类
public class Consumer {
public static void main(String[] args) throws InterruptedException, MQClientException {
//声明并初始化一个consumer
//需要一个consumer group名字作为构造方法的参数
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("javasm_consumer");
//设置NameServer地址
//consumer.setNamesrvAddr("192.168.13.141:9876;192.168.13.137:9876");
consumer.setNamesrvAddr("192.168.13.141:9876");
//这里设置的是一个consumer的消费策略
//CONSUME_FROM_LAST_OFFSET 默认策略,从该队列最尾开始消费,即跳过历史消息
//CONSUME_FROM_FIRST_OFFSET 从队列最开始开始消费,即历史消息(还储存在broker的)全部消费一遍
//CONSUME_FROM_TIMESTAMP 从某个时间点开始消费,和setConsumeTimestamp()配合使用,默认是半个小时以前
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
//设置consumer所订阅的Topic和Tag,*代表全部的Tag
consumer.subscribe("TopicTest", "*");
//设置一个Listener,主要进行消息的逻辑处理
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.println(Thread.currentThread().getName() + " Receive New Messages: " + msgs);
for(MessageExt messageExt : msgs){
System.out.println(new String(messageExt.getBody()));
}
//返回消费状态
//CONSUME_SUCCESS 消费成功
//RECONSUME_LATER 消费失败,需要稍后重新消费
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
//调用start()方法启动consumer
consumer.start();
System.out.println("Consumer Started.");
}
}
springboot整合
- 添加依赖
<dependency>
<groupId>org.apache.rocketmqgroupId>
<artifactId>rocketmq-spring-boot-starterartifactId>
<version>2.1.0version>
dependency>
- 添加配置信息
rocketmq:
name-server: 192.168.13.120:9876
producer:
group: javasm-produncer
同步发送
同步发送字符串
- 生产者Controller调用
@RestController
public class ProducerController {
@Autowired
RocketMQTemplate rocketMQTemplate;
@GetMapping("/send")
public String sendMessage(){
//发送同步消息-字符串
//javasmTopic主题名字
rocketMQTemplate.syncSend("javasmTopic","同步发送的字符串");
return "success";
}
}
- 消费者Listener
@Component
@RocketMQMessageListener(consumerGroup = "javasmConsumerGroup",topic = "javasmTopic")
public class ConsumerListener implements RocketMQListener<String> {
@Override
public void onMessage(String s) {
System.out.println(s);
}
}
同步发送对象
- 同步发送对象-Controller
@GetMapping("/send")
public String sendMessage(){
rocketMQTemplate.syncSend("javasmTopic", new MessageModel());
return "success";
}
- 同步发送对象-Listener
@Component
@RocketMQMessageListener(consumerGroup = "javasmConsumerGroup",topic = "javasmTopic")
public class ConsumerListener implements RocketMQListener<MessageModel> {
@Override
public void onMessage(MessageModel s) {
System.out.println(s);
}
}
异步消息
@GetMapping("/send")
public String sendMessage(){
rocketMQTemplate.asyncSend("javasmTopic", "异步发送的字符串", new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
//发送成功执行
}
@Override
public void onException(Throwable throwable) {
//发送异常执行
}
});
return "success";
}
单向消息
rocketMQTemplate.sendOneWay("javasmTopic", "单向消息");
顺序消息
// hashkey相同的消息会发送到同一个queue
rocketMQTemplate.syncSendOrderly("javasmTopic", "顺序消息1","abc");
rocketMQTemplate.syncSendOrderly("javasmTopic", "顺序消息2","abc");
rocketMQTemplate.syncSendOrderly("javasmTopic", "顺序消息3","abc");
// 消费者-Listener也要修改
@RocketMQMessageListener(consumerGroup = "javasmConsumerGroup",topic = "javasmTopic",consumeMode = ConsumeMode.ORDERLY)
-
一个broker中有多个queue(单queue天然有序),producer轮询发送至多个queue,不能保证有序。需要保证顺序的消息生产进同一个queue,消费由一个线程消费一个queue。
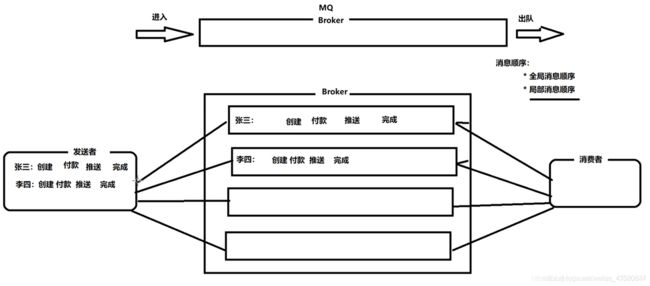
-
顺序消息生产者
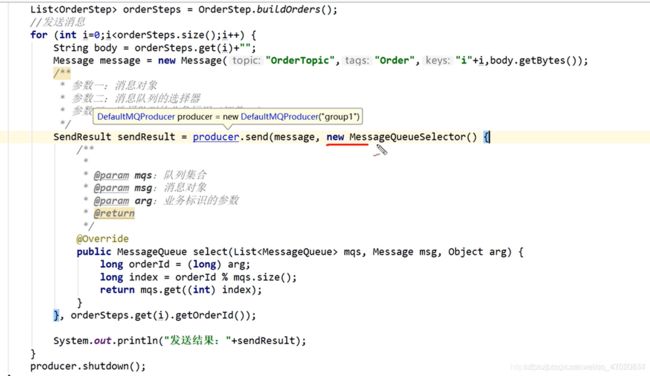
-
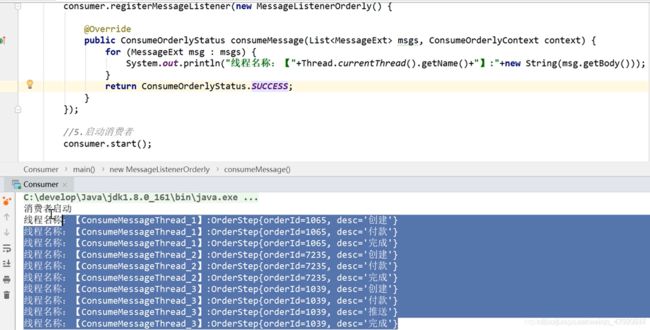
顺序消息消费者
延时消息
/**
延时消息一般使用在一定的场景中,比如我们12306买火车票
下完订单之后 30分钟如果没有支付的话 订单自动取消
此时就需要用到延时消息 我们可以在下单的时候发送一个30分钟的延时时间
等到30分钟之后 消费者自动收到通知,收到通知之后,可以查询订单状态
如果没有支付取消订单
现在RocketMq并不支持任意时间的延时,需要设置几个固定的延时等级,从1s到2h分别对应着等级1到18
*/
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
//timeout连接超时的时间
//delayLevel延时的等级
rocketMQTemplate.syncSend("javasmTopic", MessageBuilder.withPayload("延迟消息").build(), 3000, 3);
批量消息
import org.springframework.messaging.Message;
List<Message> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(MessageBuilder.withPayload("批量消息"+i).build());
}
rocketMQTemplate.syncSend("javasmTopic",list,4000);
事务消息
1:事务消息的应用场景
张三给李四转红包,怎么保证张三账户余额需要扣减,李四的账户余额需要增加,怎么保证张三账户扣钱后李四账户增加呢
2: 问题描述:
如果是单系统或者一个数据库 完全可使用本地事务解决,但是在实际当中多个微服务可能是多库多表的 甚至都不在一个工程中,此时需要使用分布式事务 比如说seata,但是RocketMQ分布式支持事务场景
3: 官网概念
事务消息共有三种状态,提交状态、回滚状态、中间状态:
TransactionStatus.CommitTransaction: 提交事务,它允许消费者消费此消息。
TransactionStatus.RollbackTransaction: 回滚事务,它代表该消息将被删除,不允许被消费。
TransactionStatus.Unknown: 中间状态,它代表需要检查消息队列来确定状态。
4:事务消息使用上的限制
4.1. 事务消息不支持延时消息和批量消息。
4.2. 为了避免单个消息被检查太多次而导致半队列消息累积,我们默认将单个消息的检查次数限制为 15 次,但是用户可以通过 Broker 配置文件的 transactionCheckMax参数来修改此限制。如果已经检查某条消息超过 N 次的话( N等于transactionCheckMax ) 则 Broker 将丢弃此消息,并在默认情况下同时打印错 误日志。用户可以通过重写 AbstractTransactionalMessageCheckListener 类来修改这个行为。
4.3.事务消息将在 Broker 配置文件中的参数 transactionTimeout 这样的特定时间长度之后被检查。当发送事务消息时,用户还可以通过设置用户属性 CHECK_IMMUNITY_TIME_IN_SECONDS 来改变这个限制,该参数优先于 transactionTimeout 参数。
4.4.事务性消息可能不止一次被检查或消费。
4.5.提交给用户的目标主题消息可能会失败,目前这依日志的记录而定。它的高可用性通过 RocketMQ 本身的高可用性机制来保证,如果希望确保事务消息不丢失、并且事务完整性得到保证,建议使用同步的双重写入机制。
4.6.事务消息的生产者 ID 不能与其他类型消息的生产者 ID 共享。与其他类型的消息不同,事务消息允许反向查询、MQ服务器能通过它们的生产者 ID 查询到消费者。
成功流程
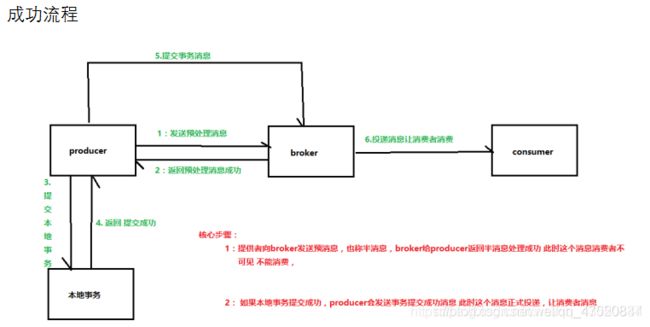
事务回滚流程
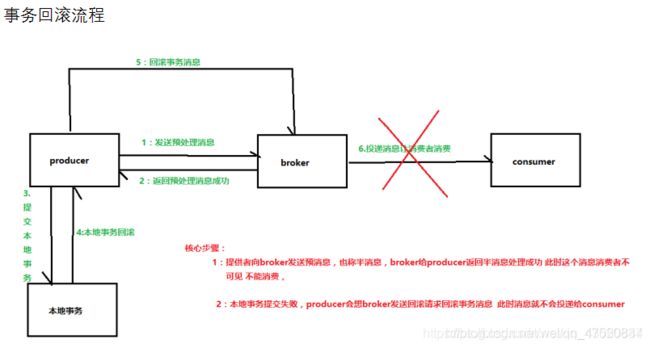
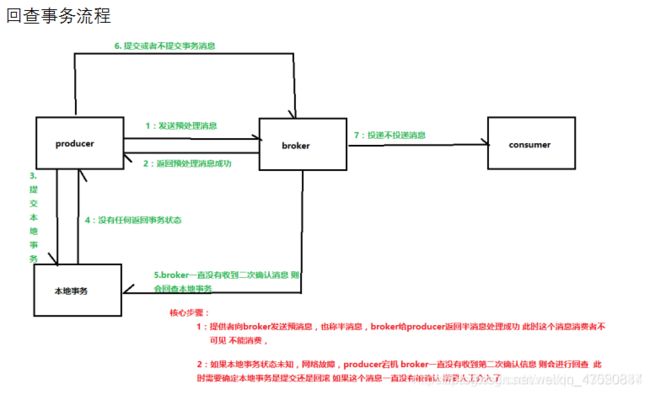
回查事务流程
- 生产者-Controller
System.out.println("张三准备给李四转钱");
String string = UUID.randomUUID().toString();
Message<String> message = MessageBuilder.withPayload("准备转钱").setHeader(RocketMQHeaders.TRANSACTION_ID,string).build();
TransactionSendResult result = rocketMQTemplate.sendMessageInTransaction("transactionMessageTopic",message,null);
- 本地事务监听器
@Component
@RocketMQTransactionListener//注解标注的类 将会监听本地事务的提交情况
public class LocalTransactionListener implements RocketMQLocalTransactionListener {
/*
* 这个方法表示执行本地事务 这个方法执行时间是向broker发送预处理消息收到回复之后 就会走这个回调函数
* 如果这个本地事务执行提交成功 消费者可以消费 如果回滚 则Broker会回滚消息 如果不返回或者返回的是UNKNOWN
* 则 默认情况下预处理消息发送一分钟后 Broker通知Producer 检查本地事务 在checkLocalTransaction返回事务提交情况
* */
private AtomicInteger atomicInteger = new AtomicInteger();
private Map<String, Integer> map = new HashMap<>();
@Override
public RocketMQLocalTransactionState executeLocalTransaction(Message message, Object o) {
String transactionId = (String) message.getHeaders().get(RocketMQHeaders.TRANSACTION_ID);
int value = atomicInteger.getAndIncrement() % 3;
map.put(transactionId, value);
if (value == 0) {
//提交成功
System.out.println("张三余额扣除成功");
System.out.println(transactionId + "提交成功");
return RocketMQLocalTransactionState.COMMIT;
}
if (value == 1) {
System.out.println("张三余额扣除失败");
System.out.println(transactionId + "事务回滚");
return RocketMQLocalTransactionState.ROLLBACK;
}
System.out.println("张三余额没啥动静");
System.out.println(transactionId + "事务无响应");
return RocketMQLocalTransactionState.UNKNOWN;
}
@Override
public RocketMQLocalTransactionState checkLocalTransaction(Message message) {
String transactionId = (String) message.getHeaders().get(RocketMQHeaders.TRANSACTION_ID);
Integer integer = map.get(transactionId);
if (integer == 2) {
System.out.println(transactionId + "回查时提交成功");
return RocketMQLocalTransactionState.COMMIT;
}
return RocketMQLocalTransactionState.ROLLBACK;
}
}
- 消费者-Listener
@Component
@RocketMQMessageListener(consumerGroup = "javasmConsumerGroup",topic = "transactionMessageTopic")
public class ConsumerListener implements RocketMQListener<String> {
@Override
public void onMessage(String s) {
System.out.println(s);
System.out.println("李四账户添加金额");
}
}
消息过滤
消息过滤: 表示消息提供者发了很多个消息,但是我只想消费其中的某一部分消息 这就是消息过滤 。
消息过滤的方式 :
- 设置Tag
- SQL表达式 (只有使用push模式的消费者才能用使用SQL92标准的sql语句)
RocketMQ集群
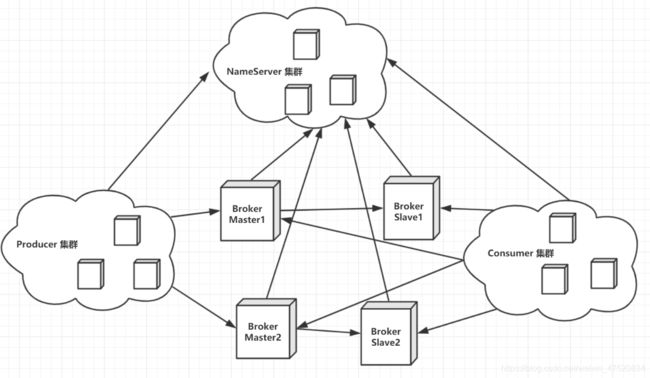
- 主从复制
RocketMQ为了提高消息消费的高可用性,避免Broker发生单点故障引起的Broker上的消息无法及时消费,同时避免单个机器硬盘损坏出现数据丢失 所以可用采用Broker的主从复制 一个Master对应一个或者多个Slave。当消息发送到Master上之后数据会同步到Slave 这个同步可以是 同步复制 也可以是异步复制
同步复制: 表示当Producer把消息给Broker的主Master之后 当Slave把数据复制成功之后 Broker才返回成功状态给Producer
异步复制:表示当Producer把消息给Broker的主Master之后,Broker直接返回Producer成功状态 不阻塞线程,使用子线程把数据复制到Slave身上
通过broker.conf文件中 brokerRole属性可以设置
- 读写分离
如果Broker不是集群的话 就一个Broker 那么读取和写入都靠它 影响性能,RocketMQ支持读写分离 master负责写消息,master和slave负责读取消息给消费者消费 那么问题来了 这样还是master又能写又能读 是不是性能还会影响呢? 其实不是 当消费者去Broker拉取消息时 默认会去master上拉去消息,此时会查看master消息堆积量,如果消息堆积量超过了物理内存的百分之40 则会在返回Consumer的消息结果中高职Consumer下次从slave上拉去消息
集群搭建参考网站:
https://www.cnblogs.com/eian/p/11478472.html
springcloud
项目的架构
单体结构

优点
开发简单
部署简单
维护简单
成本低
缺点
随着用户量增多,负载越来越高,负载均衡只能横向扩展
业务越来越复杂之后,导致框架结构越来越复杂,需求变动改动较大
随着数据增多/业务增多,可能导致war包/jar包体积越来越大。
优化
优化
横向增加服务器,让单台服务器变成多台机器的集群
垂直拆分模块,降低耦合度
数据库缓存等技术,压力也会增大,也要横向扩展
总结
适合小型创业公司
一个公司产品的最初产品,后续再重构优化
适合用户量较少的项目
一个单体架构的项目就足以支持公司的所有业务功能
例如:用户量只有十几人的xxx管理系统,xxxAPP内容管理系统,xxx政务系统
微服务框架
优点
可扩展性强
独立部署
开发比较灵活
复杂度可控
每个微服务都可以有自己的数据库
容错性高、高可用
比较适合大型企业/大型项目
缺点
故障排查困难,每次请求,都可能是一个请求链,涉及到多个微服务,每个微服务的日志可能独立存储,排查bug困难
服务监控困难
分布式的复杂性,调用其他的服务器上的服务,网络出错概率增加,延迟增高,连接超时情况增加
服务的互相依赖,导致修改接口/服务其他模块报错
运维成本增高
服务器成本增高
总结
适合成本预算充足的大型项目
适合高并发的互联网项目
适合用户体量较大的项目
不适合小型项目
微服务注册中心
认识微服务注册中心
什么是注册中心?
注册中心是微服务架构中最基础也是最重要的组件。
注册中心本质上是为了解耦微服务
注册中心主要用于提供服务的发现与注册
相当于微服务之间的通讯录,记录着所有微服务的地址
微服务之间的调用是通过注册中心来相互寻找。
为什么需要注册中心?
微服务是分布式的
微服务的数量和地址是动态变化的
所以需要引入一个额外的组件,来管理微服务
常见的注册中心
Eureka Nacos Consul Zookeeper
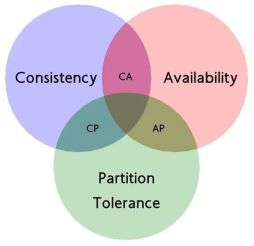
CAP理论
CAP理论是分布式系统中一个很重要的理论,它描述的是一个分布式系统最多只能满足CAP中的两个条件,不可能同时满足三个条件
C(Consistency):这里指的是强一致性。保证在一定时间内,集群中的各个节点会达到较强的一致性,同时,为了达到这一点,一般会牺牲一点响应时间。而放弃C也不意味着放弃一致性,而是放弃强一致性。允许系统内有一定的数据不一致情况的存在
A (Avalibility):可用性。意味着系统一直处于可用状态。个别节点的故障不会影响整个服务的运作
P(Partition Tolerance):分区容忍性。当系统出现网络分区等情况时,依然能对外提供服务。想到达到这一点,一般来说会把数据复制到多个分区里,来提高分区容忍性。这个一般是不会被抛弃的
对比注册中心
| Eureka | Nacos | Consul | Zookeeper | |
|---|---|---|---|---|
| CAP | AP | CP/AP | CP | CP |
| 雪崩保护 | 有 | 有 | 无 | 无 |
| 创建方式 | 内部项目 | 外部程序 | 外部程序 | 外部程序 |
| 版本状态 | 停止升级 | 版本迭代 | 版本迭代 | 版本迭代 |
| 文档 | 英文 | 中文 | 英文 | 英文 |
| SpringCloud集成 | 支持 | 支持 | 支持 | 不支持 |
| Dubbo集成 | 支持 | 不支持 | 不支持 | 支持 |
Eureka服务端
创建Eureka服务端

Eureka的服务端是在项目内部创建

<!--EurekaServer依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
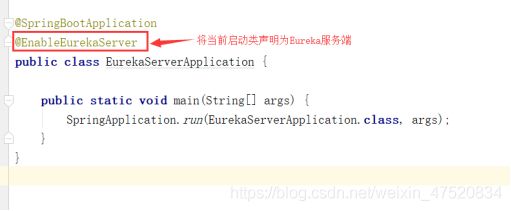
修改启动类
修改配置文件
server:
port: 8761
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8761/eureka
访问Eureka服务监控网页
访问网址:http://127.0.0.1:8761/
-
启动服务
注意:在启动的过程中会报Connection refused和Cannot execute request on any known server等错误信息,这里暂时不需要关注,这是由于Eureka的心跳机制所导致的问题,由于当前服务还没有启动成功,Eureka会在项目启动成功之前访问配置文件中配置的服务地址,所以会报出不可访问的错误。当当前服务端启动成功之后,会陆续出现心跳的日志,服务器这时候才真正注册上。
-
访问localhost:8761,出现以下页面则表示启动成功
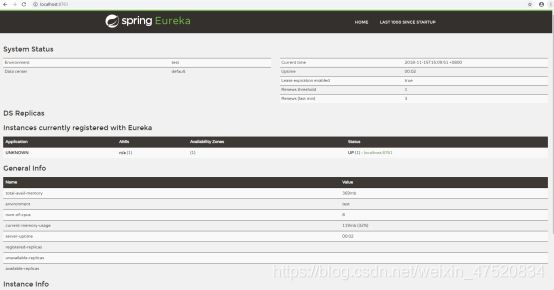
服务监控网页说明
- System Status(注册中心基本信息)
| Environment | 指定环境,默认为test,可以不改 |
|---|---|
| Data center | 数据中心 |
| Current time | 当前系统时间 |
| Uptime | 已运行时长 |
| Lease expiration enabled | 是否启用租约过期。自我保护机制关闭时,该值默认是true,自我保护机制开启之后为false |
| Renews threshold | server 期望在每分钟中收到的心跳次数 |
| Renews (last min) | 上一分钟内收到的心跳次数 |
- DS Replicas(注册中心基本信息)
| Instances currently registered with Eureka | 当前已注册到注册中心的服务 |
|---|---|
- General Info (当前服务器基本信息)
| total-avail-memory | 总共可用的内存 |
|---|---|
| environment | 环境名称,默认test |
| num-of-cpus | CPU个数 |
| current-memory-usage | 当前已经使用内存的百分比 |
| server-uptime | 服务在线时间 |
| registered-replicas | 相邻集群复制节点 |
| unavailable-replicas | 不可用的集群复制节点 |
| available-replicas | 可用的相邻集群复制节点 |
- Instance Info(当前实例基本信息)
| ipAddr | 实例ip |
|---|---|
| status | 实例状态 |
监控网页上的红字提醒
Spring Eureka 服务注册中心在三种情况下会出现红色加粗的字体提示:
1)自我保护机制开启时(enable-self-preservation: true):
EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY’RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE.
2)自我保护机制关闭时(enable-self-preservation: false):
RENEWALS ARE LESSER THAN THE THRESHOLD. THE SELF PRESERVATION MODE IS TURNED OFF.THIS MAY NOT PROTECT INSTANCE EXPIRY IN CASE OF NETWORK/OTHER PROBLEMS.
3)自我保护机制关闭了,但是一分钟内的续约数没有达到85%,可能发生了网络分区,会有如下提示
THE SELF PRESERVATION MODE IS TURNED OFF.THIS MAY NOT PROTECT INSTANCE EXPIRY IN CASE OF NETWORK/OTHER PROBLEMS.
Eureka的一些常用配置
eureka.instance.hostname
修改当前主机名称。在后续的高可用中需要用到
eureka.instance.appname
修改当前实例名称。实例名称用作在监控页面显示
eureka.client.registerWithEureka(或eureka.client.register-with-eureka)
是否注册自身到Eureka服务器。如果是单台且当前应用本身就是服务器,则可以把值设置为false
eureka.client.fetchRegistry(或eureka.client.fetch-registry)
是否从Eureka服务器获取注册信息。如果是单台且当前应用就是服务器,则可以把值设置为false
spring.application.name
声明当前应用名称,可作为监控网页的显示
创建高可用Eureka服务端
集群配置文件
假设我们有两台Eureka服务器,那么我们只需要将这两台服务器的注册中心地址填对方即可完成两两注册。为了方便测试,我们使用在同一个项目中采用多段配置的方式。配置文件如下所示
- Eureka Server 1
eureka:
instance:
appname: server
server:
#关闭自我保护
enable-self-preservation: false
#设置超时节点清理的间隔时间
eviction-interval-timer-in-ms: 10000
---
spring:
#配置别名
profiles: eurekaS1
eureka:
client:
service-url:
#注册到其他服务群,多个以逗号隔开
defaultZone: http://192.168.2.201:8762/eureka
server:
port: 8761
---
spring:
profiles: eurekaS2
eureka:
client:
service-url:
defaultZone: http://192.168.2.201:8761/eureka
server:
port: 8762
—表示多段配置,配置的应用可以在启动服务时启用(–spring.profiles.active=profiles的值。 如–spring.profiles.active=eurekaS1)。
- 在高可用环境中客户端的配置
在服务端高可用的情况下,客户端需要同时指向多台服务器,保证高可用性,避免某台节点故障之后导致不可访问的情况。
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8761/eureka,http://127.0.0.1:8762/eureka
spring:
application:
name: client
客户端
Eureka客户端
- 创建Eureka客户端
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
- 修改启动类
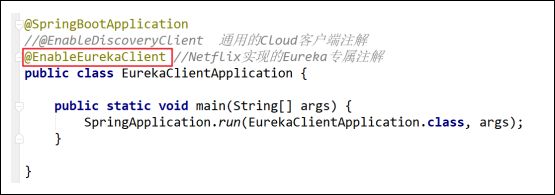
- 修改配置文件
server:
port: 8081
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8761/eureka
- 测试

在监控页面能看见两个启动的客户端,已经是测试成功了。
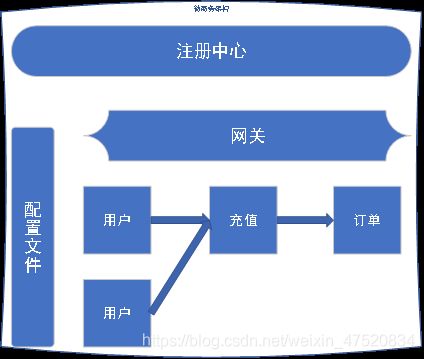
模拟服务注册与基本调用
- 创建测试项目
为了方便测试,我们可以创建一个项目包含多个module子项目来进行,具体操作如下:
- 创建一个SpringBoot项目,引入Web和Eureka Discovery,删掉项目中的src目录,将当前项目作为父项目。然后根据当前项目创建两个module子项目(SpringBoot的项目创建方式),分别是order-system和user-system。这两个项目不需要引入Web和Eureka Discovery。
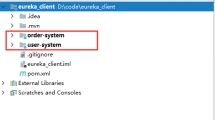
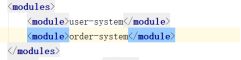
- 修改父项目的pom文件,增加modules,引入当前项目的子项目
- 分别修改两个子项目的pom文件,将子项目的parent信息指向父项目
a. groupId、artifactId和version从父项目的pom拷贝
b. 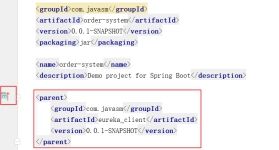
c.如果没有个性化的配置的话,properties、dependencies、dependencyManagement和build配置信息都可以删除,引用父pom文件中的配置。
- 配置完成后启动两个子项目,验证是否可以成功启动并访问。
这里启动了一个client-order作为请求端
启动一个client-user作为被请求端
下面是user端的代码
@RestController
public class UserController {
@GetMapping("/query/{uid}")
public UserModel query(@PathVariable Integer uid){
UserModel userModel = new UserModel(uid,"这是用户模块");
return userModel;
}
}
下面是order端的请求代码
@RestController
public class OrderController {
@Resource
private EurekaClient eurekaClient;
@GetMapping("/query/user/{uid}")
public UserModel get(@PathVariable Integer uid) {
Application application = eurekaClient.getApplication("client-user");
//获取实例名为client-user的客户端列表,如果启动多个实例,则返回多个。
//必须已经启动实例client-user
List<InstanceInfo> instanceList = application.getInstances();
//获得第一个客户端 TODO:非空判断
InstanceInfo instanceInfo = instanceList.get(0);
String host = instanceInfo.getHostName();//ip地址
int port = instanceInfo.getPort();//端口号
String url = "http://"+host+":"+port+"/query/"+uid;//拼接请求地址
RestTemplate restTemplate = new RestTemplate();
UserModel userModel =restTemplate.getForObject(url,UserModel.class);
return userModel;
}
}
可以在访问order页面的时候获取user的数据,就是成功了。
客户端的常见问题
当客户端关闭或掉线之后,服务端监控页面仍然还显示?
基于CAP原则,Eureka只保证了AP(高可用),也就是Eureka某个节点在不可用时,会自动将请求转发至下一个节点,并不会将当前节点下线,而是等待恢复(这是考虑到了集群环境中网络延迟、通信堵塞等因素)。所以在监控页面我们仍然还是会看到连接请求。所以Eureka的哲学是 宁可放过一个,也不错杀一千。
如何让掉线的连接过期后自动下线呢?
将Server端的自我保护机制关闭,并修改清理间隔时间
eureka.server.enable-self-preservation=false (关闭自我保护)
eureka.server.eviction-interval-timer-in-ms=30*1000(单位毫秒)
调整客户端的租约更新时间间隔和到期时间
eureka.instance.lease-renewal-interval-in-seconds=10(更新时间间隔)
eureka.instance.lease-expiration-duration-in-seconds=30(到期时间)
Consul客户端
- Consul能做什么
服务注册发现
Consul客户能够注册一个服务,比如api或mysql,其他客户可以在Consul上查询一个指定服务的提供者。Consul提供DNS和HTTP的服务发现接口。
健康检查
Consul可以灵活的使用脚本等来检测注册在其上的服务是否可用,不健康的服务Consul也能够灵活处理,比如提供服务的主机内存使用超过90%,我们可以配置让Consul不要把这样的服务提供给服务调用者。
key/value存储
这个功能和etcd有些类似,可以通过HTTP API方便地使用。
多数据中心支持
Consul支持开箱即用的多数据中心支持,这意味着用户不用建立额外的抽象层让业务扩展到各个区域
- 官网下载
官网地址:https://www.consul.io/
Spring Cloud Consul地址:https://spring.io/projects/spring-cloud-consul
启动和关闭指令
## 启动命令
consul agent -dev
##创建run.bat 放入启动命令指令 保存双击即可启动
## 关闭命令
consul leave
- 访问地址
http://127.0.0.1:8500/
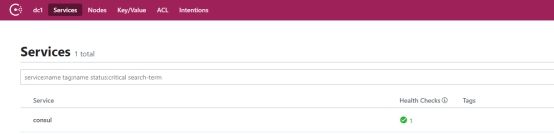
说明服务端已经启动成功
-
SpringCloudConsul
- 创建客户端项目
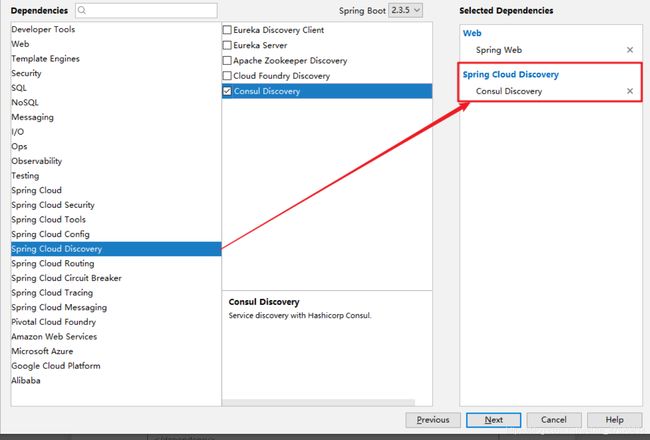
也可以在springboot项目中手动导入依赖
org.springframework.cloud
spring-cloud-starter-consul-discovery
org.springframework.boot
spring-boot-starter-actuator
- 修改配置文件
server:
port: 8088
spring:
application:
name: consul-user
cloud:
consul:
host: 127.0.0.1
port: 8500
discovery:
health-check-url: http://127.0.0.1:8500
-
修改启动类
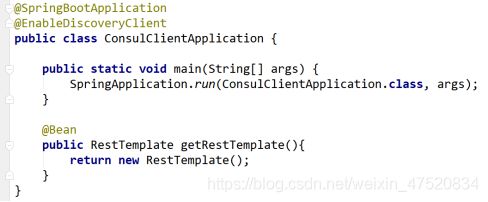
-
测试
启动客户端之后,访问consul服务端网址,服务列表,可以看见客户端接入。

这里启动了一个consul-order作为请求端
启动一个consul-user作为被请求端
下面是order端的请求代码
@RestController public class OrderController { @Autowired private DiscoveryClient discoveryClient; @Autowired RestTemplate restTemplate; @GetMapping("/query/user/{uid}") public UserModel get(@PathVariable Integer uid) { //获取实例名为consul-user的客户端列表,如果启动多个实例,则返回多个。 //必须已经启动实例consul-user List<ServiceInstance> instanceList = discoveryClient.getInstances("consul-user"); //获得第一个客户端 ServiceInstance serviceInstance = instanceList.get(0); String host = serviceInstance.getHost();//ip地址 int port = serviceInstance.getPort();//端口号 String url = "http://"+host+":"+port+"/query/"+uid;//拼接请求地址 UserModel userModel =restTemplate.getForObject(url,UserModel.class); return userModel; } }可以在访问order页面的时候获取user的数据,就是成功了。
Nacos客户端
- Nacos官网
官网地址
- 目录结构

- Nacos启动
startup -m standalone 或者 直接双击
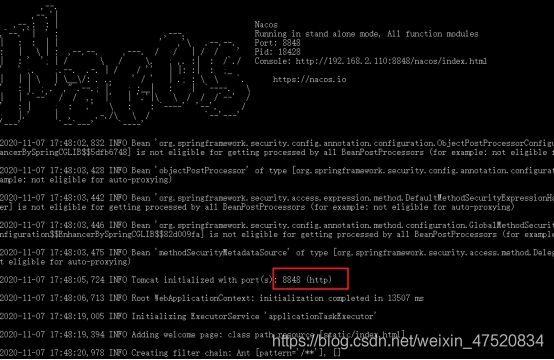
启动成功之后,可以看见nacos端口号是8848
访问本地Nacos
http://127.0.0.1:8848/nacos

- SpringCloudAlibaba+Nacos
也可以在SpringCloud项目中,直接加入依赖
com.alibaba.cloud
spring-cloud-alibaba-dependencies
2.2.1.RELEASE
pom
import
- 修改配置文件
server:
port: 8066
spring:
application:
name: nacos-order
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
#这里的server-addr 端口号如果是80也不可以省略,如果是8848可以省略,可能报错
-
修改启动类

-
测试
启动客户端之后,访问nacose服务端网址,服务列表,可以看见客户端接入。
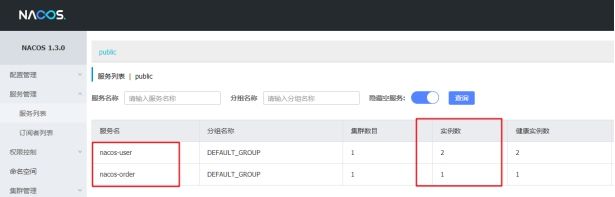
这里启动了一个nacos -order作为请求端
启动一个nacos -user作为被请求端
下面是order端的请求代码
@RestController
public class OrderController {
@Autowired
private DiscoveryClient discoveryClient;
@Autowired
RestTemplate restTemplate;
@GetMapping("/query/user/{uid}")
public UserModel get(@PathVariable Integer uid) {
//获取实例名为nacos-client-user的客户端列表,如果启动多个实例,则返回多个。
//必须已经启动实例nacos-client-user
List<ServiceInstance> instanceList = discoveryClient.getInstances("nacos-client-user");
//获得第一个客户端
ServiceInstance serviceInstance = instanceList.get(0);
String host = serviceInstance.getHost();//ip地址
int port = serviceInstance.getPort();//端口号
String url = "http://"+host+":"+port+"/query/"+uid;//拼接请求地址
UserModel userModel =restTemplate.getForObject(url,UserModel.class);
return userModel;
可以在访问order页面的时候获取user的数据,就是成功了。
Spring Cloud OpenFeign
Spring Cloud OpenFeign 基于Netflix Feign 实现的,并且实现了声明式的Web服务客户端定义方式,它使得web服务客户端更容易编写。为了更方便的与Spring 组件集成,Spring Cloud还为OpenFeign提供了SpringMVC的支持。当它配合Eureka和Ribbon可以很方便的实现客户端负载均衡。
所谓客户端负载均衡就是,客户端在启动时会拉取目前可用的服务,然后通过随机、轮询的机制在客户端对访问进行分流。
相较于我们在Eureka中的客户端调用的案例中,使用HttpClient调用方式,OpenFeign更简单明了,无论是配置还是使用起来都很方便。
OpenFeign环境要求
由于Spring Cloud OpenFeign是基于Netflix Feign实现的,所以它也与Spring Cloud Eureka一样都属于Netflix套件。版本要求也与Spring Cloud Eureka一样。
创建OpenFeign
引入OpenFeign
按照官方文档的描述,只需要在pom中引入openfeign的starter即可换成相关依赖引入。
org.springframework.cloud
spring-cloud-starter-openfeign
创建OpenFeign客户端
在SpringBoot的启动类上加入@EnableFeignClients注解即可完成OpenFeign的使用声明。
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients
public class OrderSystemApplication {
public static void main(String[] args) {
SpringApplication.run(OrderSystemApplication.class, args);
}
}
使用测试
- 被调用模块的handler
@RestController
public class UserHandler {
@GetMapping("query/{uid}")
public UserModel query(@PathVariable Integer uid){
UserModel userModel = new UserModel();
userModel.setUid(uid);
userModel.setUname();
return userModel;
}
}
- 调用模块创建一个接口
// 对应yml配置文件中被调用模块的application name,name不允许出现特殊字符
@FeignClient("userclient")
public interface UserClient {
//GetMapping("访问的全路径,不是方法上面的路径,要加上类上的路径")
//返回类型要对应 名字不需要
@GetMapping("query/{uid}")
UserModel getUserInfo(@PathVariable("uid") Integer uid);
}
- 调用模块像使用接口一样进行调用
@RestController
public class OrderHandler {
@Resource
private UserClient userClient;
//直接调用UserClient 像接口一样
@GetMapping("query/feign/{oid}/{uid}")
public OrderModel query(@PathVariable Integer oid, @PathVariable Integer uid){
UserModel userModel = userClient.getUserInfo(uid);
OrderModel orderModel = new OrderModel();
orderModel.setOid(oid);
orderModel.setUserModel(userModel);
return orderModel;
}
}
12345678910111213141516
OpenFeign的基本配置
- OpenFeign的基本配置信息在FeignClientProperties类中,所有的配置都是基于config的成员变量进行设置。具体可配置属性可参考FeignClientProperties类中的内部类FeignClientConfiguration中的成员属性。
- 超时配置建议在所有OpenFeign中进行配置。

feign:
client:
config:
default:
connectTimeout: 1000
readTimeout: 6000
##超时配置建议在所有OpenFeign中进行配置
微服务中的公共类
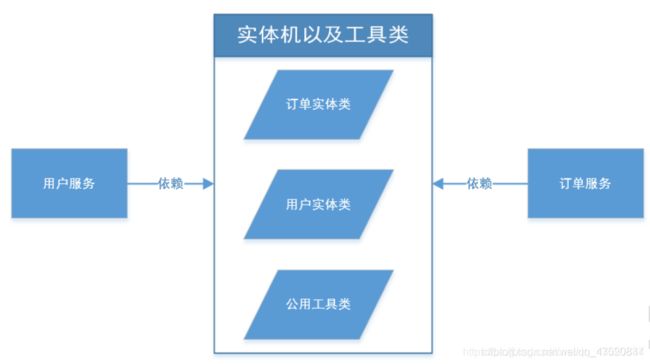
在微服务中,每一个服务都是单独存在的个体,各自治理。虽然是独立的个体,但是多多少少还会有一些对应的交集,比如实体类和各种工具类。那么在这样的情况下,我们应该怎么去设计整体架构呢?
在当前多模块的测试项目中,我们可以采取两种方案来解决问题:
1、将实体类和工具类拷贝到每个服务模块中。
2、创建一个公共模块,然后让每一个服务模块来引入当前公共模块。
上述两种方案中,很明显第二种更加便于维护及扩展。下面来介绍如何创建公共模块以及引用
创建公共模块
目录结构

common模块由于只负责管理公共类,并不需要容器和启动类,所以当前模块是使用maven创建的Java项目
pom文件配置说明
common 的pom文件
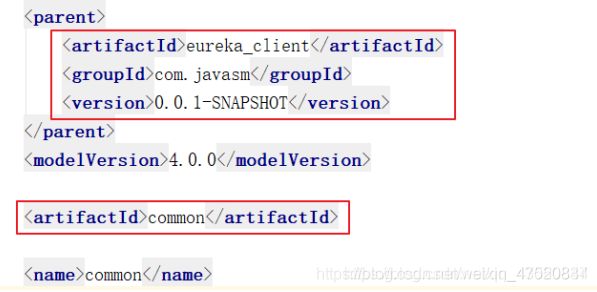
跟其他服务的pom一样,需要指向共同的父级,并指定当前的artifactId。
父级pom文件
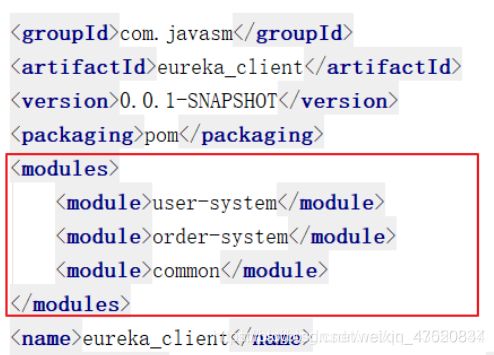
在父级pom文件中同样需要将common加入到当前项目的子模块。同时为了方便下属其他子模块的引用,需要将common加入到公共依赖中。
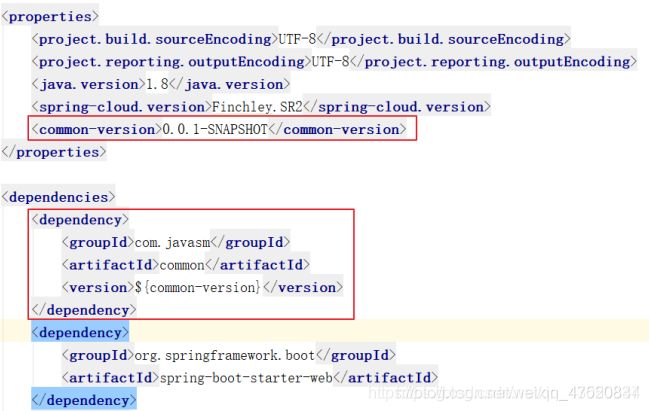
打包公共模块
配置完所有的信息之后,只需要将公共模块打包即可在其他项目中引用。目前做测试使用,只需要使用maven install 将common打包到本地即可。
Spring Cloud Ribbon
Ribbon是一个客户端负载均衡器,在Feign中实际上也默认使用了Ribbon来做负载,且该功能是默认启用的。客户端负载实际上跟Nginx类似,都是讲访问请求转发到其他服务器。它通过Eureka注册中心的Application名称来获取服务器列表,然后在调用时通过负载策略来访问具体的服务器地址。
Ribbon环境要求
OpenFeign默认集成Ribbon,不需要额外的环境要求
测试Ribbon
为了方便测试,按照之前的项目架构,我们在Order系统中使用OpenFeign调用了User系统的一个接口,这里可以将User系统启动两个实例,并让User系统中的接口返回数据不同,来测试Ribbon的负载。创建多实例的方式很简单,可以修改Controller打两个返回数据不同的Jar,在开发中这样的方式肯定会很麻烦。下面介绍IDEA中运行多个实例的方式。
创建多实例

先将User系统中原有的UserController返回值改为1,另一个实例我们将这个返回值改为2,在测试时可以很方便的甄别负载的效果。

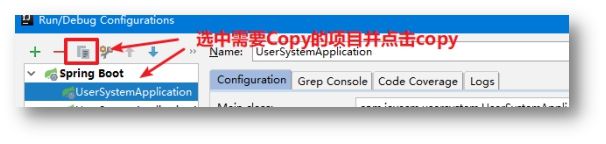
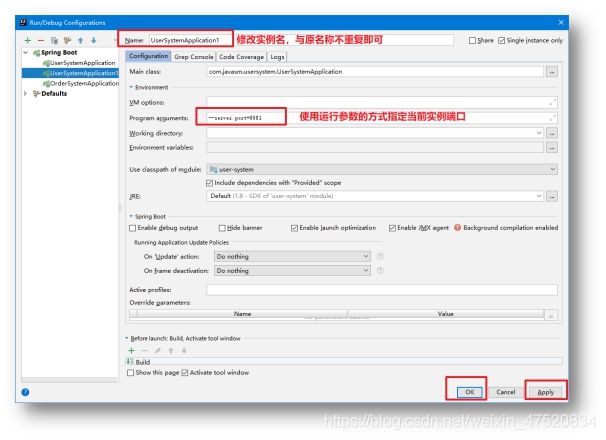
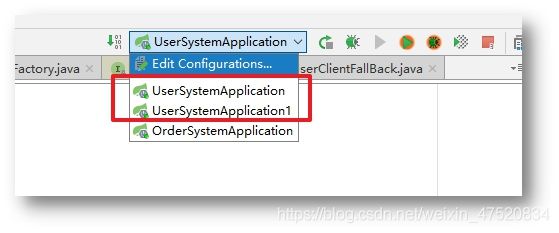
当运行实例中出现刚刚创建的实例时,就表示成功了。
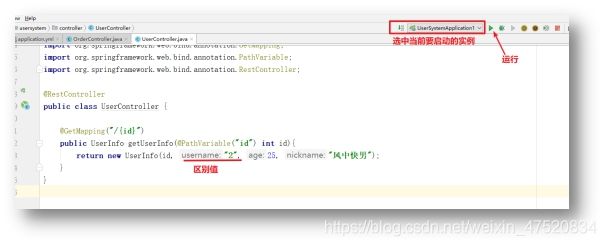
启动完毕之后就有两个用户实例,分别是8080和8081端口。分别访问这两个端口下的UserController确保两个返回值不同之后,再访问Order服务接口,查看Order服务通过Feign调用的结果。
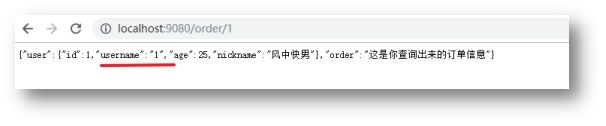
多次访问之后,会发现这个值是来回变动的,也就是说,Ribbon的负载默认采取的是轮询的机制。
修改Ribbon的负载策略
Ribbon除了默认提供的轮询策略以外,还有很多其他的负载策略供开发者选择。
| 策略类名 | 策略描述 |
|---|---|
| AvailabilityFilteringRule | 过滤掉那些因为一直连接失败的被标记为circuit tripped的后端Server,并过滤掉那些高并发的后端Server(active connections 超过配置的阈值) |
| BestAvailableRule | 选择一个最小的并发请求的Server |
| RandomRule | 随机选择一个Server |
| RetryRule | 重试查找选择一个可用的Server |
| RoundRobinRule | 轮询选择Server(默认策略) |
| WeightedResponseTimeRule | 根据响应时间分配一个weight,响应时间越长,weight越小,被选中的可能性越低。 |
| ZoneAvoidanceRule | 复合判断。判断区域是否可用,并过滤掉区域中的连接过多的Server |
配置负载策略也比较简单,只需要在yml中声明负载需要引用的类即可。
USERSERVICE:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
USERSERVICE是指在FeignClient中连接的服务名,负载策略是按照服务名单独来进行配置的
Spring Cloud Hystrix
Netflix提供了一个叫Hystrix的类库,它实现了断路器模式。在微服务架构中,通常一个微服务会调用多个其他的微服务。当某一个环节的微服务调用失败后,它将会导致上一层服务失败,服务访问越大则失败率越高,而这一连串的失败就是雪崩效益,下层失败导致上层所有服务崩溃。
断路器的作用就是,当发现某一服务调用失败后,告知调用者该接口失败,从而避免调用者服务资源消耗。而这样的处理就是我们经常会在微博以及淘宝上经常看到的繁忙页面或相关提示,这实际上就是做了服务熔断。


Hystrix环境要求
与其他netflix组件版本一致
创建Hystrix服务

官方架构图示意: 当API调用远程服务,而远程服务报错时,Hystrix将执行fallback方法来返回给api调用。
加入pom依赖
org.springframework.cloud
spring-cloud-starter-netflix-hystrix
创建Hystrix服务
启动类依赖
-
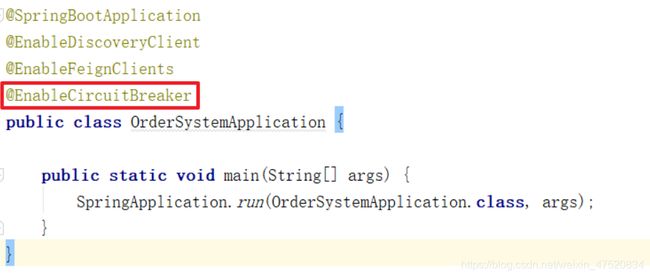
加入Hystrix注解
在order服务中直接加入**@EnableCircuitBreaker** 来启用Hystrix。
-
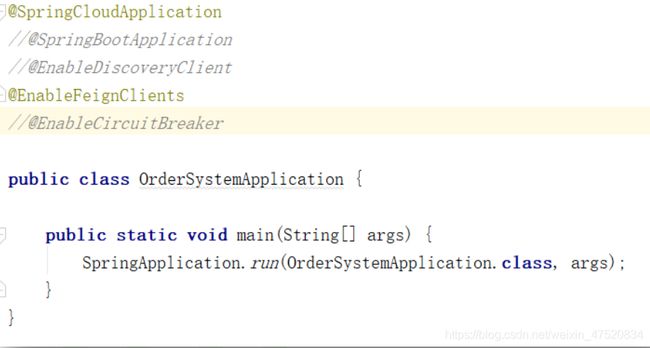
使用SpringCloudApplication
也可以直接使用**@SpringCloudApplication** 注解来代替**@SpringBootApplication**、@EnableDiscoveryClient和**@EnableCircuitBreaker**注解
修改服务调用方(Order服务)
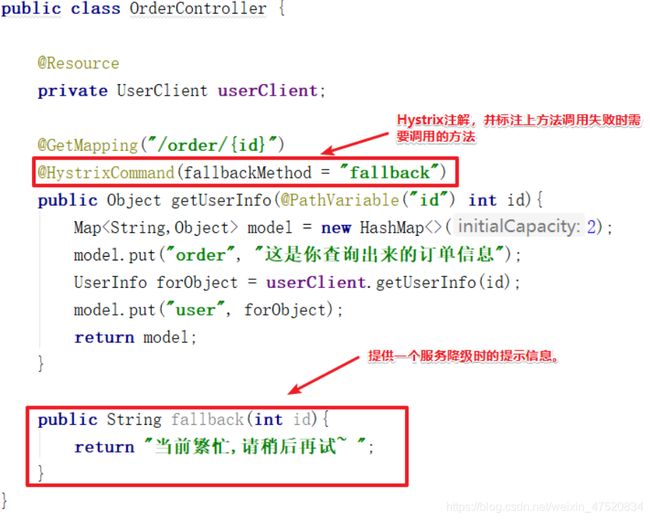
使用**@HystrixCommand**注解标记在需要熔断的方法上,使用fallbackMethod声明当接口熔断时需要调用的方法。该方法可以返回一个默认提示文案或者默认对象,且该方法的入参参数列表必须与接口方法的参数列表保持一致。
修改服务提供方(User服务)
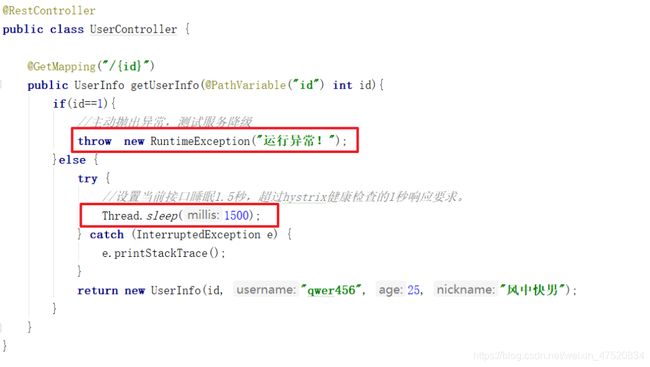
修改User服务的UserController,在对外开放的接口中加入抛出错误和模拟超时的线程睡眠。
抛出错误是为了测试服务调用方的服务降级。
线程睡眠是为了测试服务调用时的请求超时。
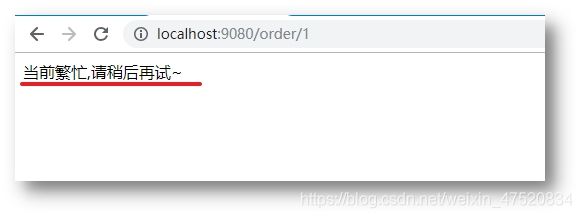
测试结果
当我们访问order服务时,无论是超时还是抛出异常,服务端都会响应在fallback中返回的对象。
配置扩展
基本示例
Hystrix的配置信息可以通过@HystrixCommand的commandProperties属性来进行配置。
具体可配属性在HystrixCommandProperties类中。
默认配置都在该类的
HystrixCommandProperties(HystrixCommandKey key, HystrixCommandProperties.Setter builder, String propertyPrefix)构造方法中完成。

属性详解
commandProperties是配置Hystrix配置的属性,该属性的值为@HystrixProperty类型的数组。@HystrixProperty中配置属性名和属性值即可完成属性配置
超时配置
Hystrix默认超时时间是1秒钟,当远程服务调用超过1秒则会判定该远程服务调用失败。

execution.isolation.thread.timeoutInMilliseconds:连接超时时间,单位毫秒,默认为1秒。
熔断机制设置
Hystrinx的熔断由三个参数的设置共同完成。
circuitBreaker.requestVolumeThreshold:默认值20,表示10秒内20个请求为一个轮回。
circuitBreaker.errorThresholdPercentage:默认值是50,表示50%的错误率。
circuitBreaker.sleepWindowInMilliseconds:默认值是5000,表示熔断后,拒绝所有请求5秒。
- 示例

配置详解
10秒内10个请求中错误率百分之60以上,则触发熔断,熔断后拒绝请求10秒钟。
注意 : Hystrix在熔断期间会对服务进行一次请求测试,如果服务能够正常访问,则会重新关闭熔断。
使用类全局配置
按照上诉配置方式,若一个类中存在多个接口需要进行熔断配置,则需要在每一个方法上加入注解和属性配置,这样非常麻烦。Hystrix也提供了类全局配置来方便开发者进行参数设置。使用**@DefaultProperties**即可完成全局声明。


当当前类中某个方法报错时,会默认按照defaultFallback属性指定的方法来执行(该方法参数列表必须为空)。
注意:@DefaultProperties 和 @HystrixCommand可以共存,后者的优先级大于前者。
Openfeign集成
Openfeign组件中默认是由集成Hystrix的,只需要在配置文件中开启即可使用Hystrix的功能。使用集成功能不需要像手动创建Hystrix服务那样繁琐,使用@DefaultProperties 和 @HystrixCommand注解,而是直接在@FeignClient上标记Hystrix的fallback,在yml中对Hystrix进行配置即可。
开启OpenFeign的Hystrix
-
OpenFeign中的Hystrix功能是默认关闭的。需要在配置文件中声明开启才可使用。
-
在yml配置文件中增加开启Hystrix的配置。
feign:
#开启feign的hystrix
hystrix:
enabled: true
配置FeignClient
FeignClient注解上有两个fallback参数,
分别是:fallback和fallbackFactory。
这两个参数的值类型都是class,class的实现的就是fallback相关的内容。
FeignClient的fallback
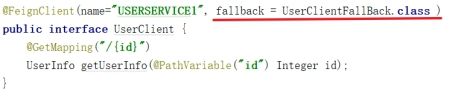
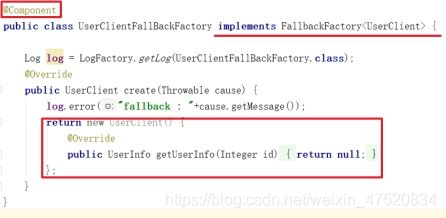
- 创建fallback类

自定义一个fallback类,这里以order系统中的userClient类为例,创建的fallback类,类名规范一般为XXXFallback,且XXXFallback类必须实现它需要接管的feignClient接口。
该类必须使用**@Component**注解将类注入到Spring容器中,否则Hystrix无法发现该类则熔断时会报错。
- 修改FeignClien
在服务调用端(Order)中修改FeignClient,加入fallback属性,并赋值定义好的fallback类。
测试user服务异常

当异常的时候,此时会发现并没有像之前创建的示例一样,出现抛出错误的情况。这是因为在OpenFeign中集成的fallback是实现client接口的,我们在fallback中当前是默认返回的**null**,而这个时候其实,hystrix已经在运行了。只是OpenFeign的hystrix是返回空或者自定义一个服务异常时协定的某个对象。
所以,在开发大型的项目,我们会提供一个公共的数据model来进行数据装载这样会更加利于后续的判断。所有的Controller都必须基于该model进行数据返回,
测试user服务超时
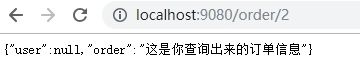
在**@HystrixCommand**中可以进行超时时间配置,在OpenFeign集成Hystrix环境中可以通过yml对超时做额外的配置。
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 4000
注意:在使用OpenFeign+Hystrix测试请求超时时,务必确保OpenFeign请求超时相关配置正确
FeignClient的fallbackFactory
- 创建fallbackFactory类
fallbackFactory类需要实现FallbackFactory接口和当前实现的具体类型,fallbackFactory的作用与fallback类似,只是前者会获取client端的报错信息。
- 修改FeignClient

Sentinle
流量防卫兵-Sentinle
了解Sentinel
- Sentinel是什么
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。
Sentinel 是面向分布式服务架构的流量控制组件,
主要以流量为切入点,从限流、流量整形、熔断降级、系统负载保护、热点防护等多个维度来帮助开发者保障微服务的稳定性。
- Sentinel特性
丰富的应用场景
Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
完备的实时监控
Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况
广泛的开源生态
Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
完善的 SPI 扩展点
Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
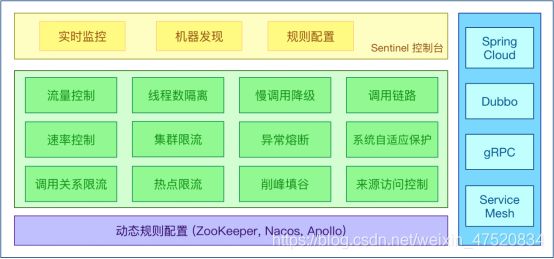
- Sentinel的基本组成
核心库(Java 客户端):不依赖任何框架/库,能够运行于 Java 7 及以上的版本的运行时环境,可以结合springcloud一起使用
控制台(Dashboard):控制台主要负责管理推送规则、监控、集群限流分配管理等
启动
就是启动jar包的指令
java -jar sentinel-dashboard-1.7.2.jar
##默认端口8080
访问控制平台
http://127.0.0.1:8080/

配置客户端
加入依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-sentinel
修改配置文件
spring:
application:
name: nacos-order
cloud:
sentinel:
transport:
port: 8719
dashboard: 127.0.0.1:8080
项目启动成功之后,请求一次页面,才能在管理页面看见对应的项目
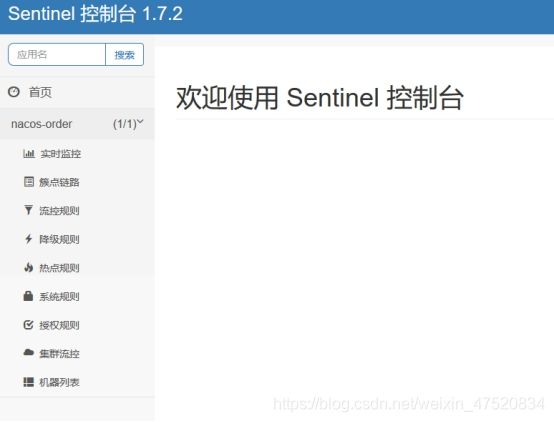
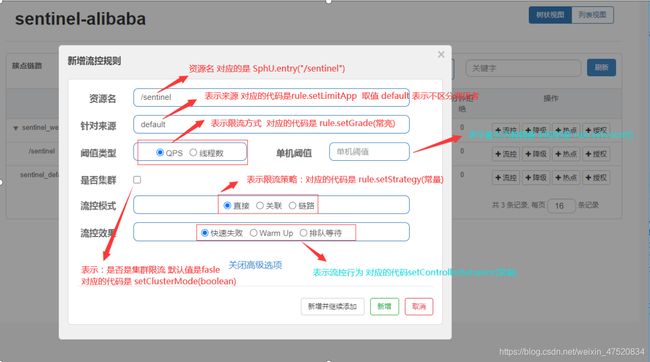
Spring Cloud Config
Spring Cloud Config的基本原理
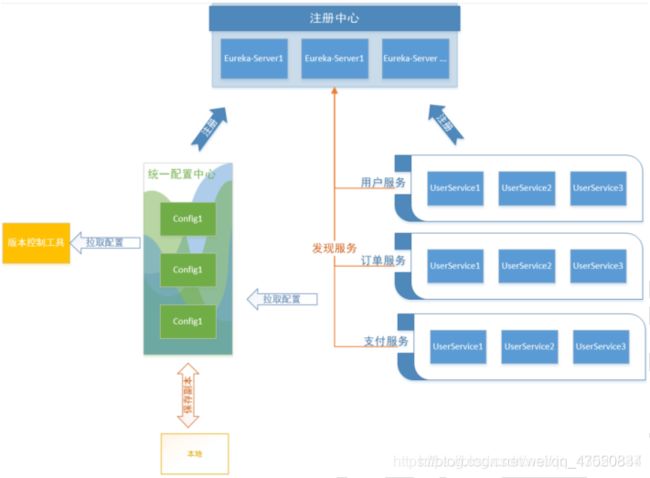
-
将所有的配置文件保存至版本管理工具
-
将配置中心的远程配置地址设置为版本控制地址,配置中心会从版本控制中拉取对应的配置文件并加载至本地。
-
将配置中心注册到Eureka完成服务注册。配置中心注册到注册中心之后,即可完成配置中心的高可用。
-
将所有的微服务配置改为链接Eureka发现配置中心,拉取指定配置中心的版本的配置文件。
-
修改微服务的配置文件为启动预加载。
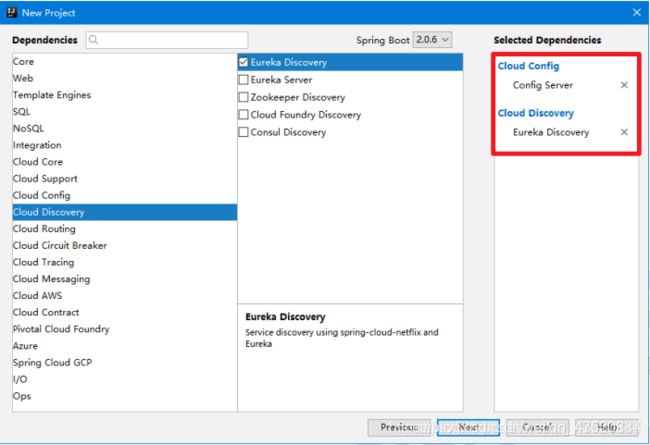
创建 Config 服务端
使用向导创建项目
加入svn依赖
由于配置中心需要连接版本控制工具,所以当前项目需要加入SVN相关的依赖支持。
org.tmatesoft.svnkit
svnkit
1.9.3
上传配置文件至版本控制工具
将其他客户端的配置文件上传至版本控制工具,这里以svn举例。
- svn文件夹说明
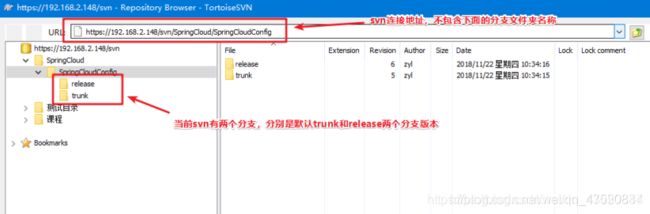
svn作为版本协同工具,拥有创建多个分支的功能,多个分支标记着多个版本环境。用于在线服务回滚。
#url可作为config连接的地址
#分支版本可在config端连接时指定,默认是trunk目录
- 分支文件夹中的文件说明

分支文件夹下存放所有的客户端的配置文件,这里存放了三个版本的文件。分别是userService.yml、userService-dev.yml(开发环境)、userService-pro.yml(生产环境)。
这三个文件又有各自不同的作用域。其中两个通过名称很好理解。
userService-dev.yml 用于开发测试环境,后缀dev可以随意自定义。
userService-pro.yml 用于正式生产环境,后缀pro 可以随意自定义。
userService.yml 用来存放不同环境的公共配置信息(可省略)。
关于这几个文件的用法,在后续配置使用中会继续分析。
给启动类加入注解
控制中心需要实现高可用,除了SpringBoot规范中的开启配置中心服务注解以外,还需要加入Eureka客户端连接的注解

修改配置文件
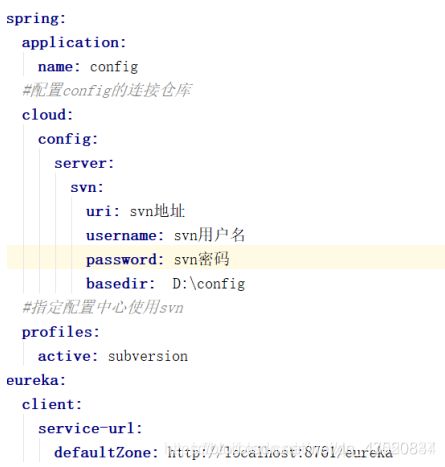
属性详解:
spring.cloud.config.server.svn 配置svn相关的属性
uri :svn地址
username : svn账户
password :svn密码
basedir :下载的配置文件本地存放路径
default-label :引用分支,默认为trunk。若需要使用其他的分支需要声明属性并指定值
spring.profiles.active = subversion 指定配置中心使用svn
访问测试
-
userService.yml(存放微服务的注册中心配置信息,不带后缀的文件,config是当做公共配置使用的,无法直接访问。)

-
userService-dev.yml(开发环境)

-
userService-pro.yml(生产环境)
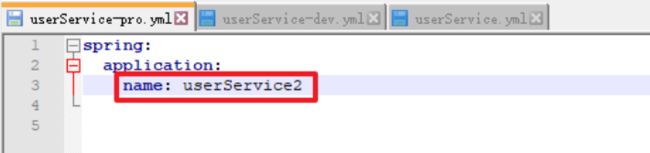
注意:这里只是为了测试才将两个文件的应用名设置为不同,在后续真正开发的过程中,一定要将所有的相同的服务设置为相同的应用名。
-
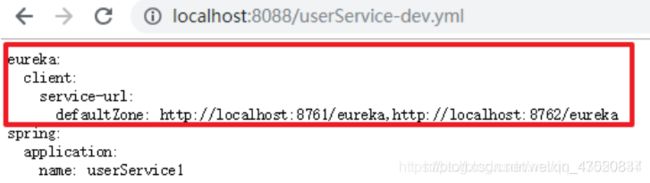
访问userService-dev.yml(访问开发环境配置文件,config会将公共配置文件同样引入进来。)
-
访问userService-pro.yml(生产环境)

服务端高可用
Config服务端高可用比较简单,只需要启动多台config服务实例即可完成集群高可用。分流操作由客户端去Eureka发现Config服务,并拉取配置时分配具体服务器。具体可以参考客户端拉取配置时,客户端打印的Fetching config from server at :配置中心地址。
具体实现在ConfigServicePropertySourceLocator.getRemoteEnvironment(…)方法中。
客户端连接 Config
引入pom依赖
在原有的Eureka依赖下,加入Spring Cloud Config相关依赖
org.springframework.cloud
spring-cloud-config-client
修改配置文件
spring:
application:
name: orderService
cloud:
config:
discovery:
service-id: eros-config
enabled: true
profile: dev
label: release
spring.application.name : 应用名(注意,在连接了配置中心的情况下,这里指配置中心的文件名)
spring.cloud.config.discovery.enabled : 开启配置中心。(true为开启,false为不开启,默认为false)
spring.cloud.config.discovery.service-id :配置中心在Eureka注册中心的名称
spring.cloud.config.profile :引用配置再配置中心的后缀。
也就是说当前配置中由spring.application.name+ spring.cloud.config.profile组成了文件名(当前示例的结果为 :userService-dev)
spring.cloud.config.label :引用配置的分支名称
修改配置文件
bootdtrap.yml
系统级配置,最先执行
application.yml
开发级配置,当系统初始化之后才会执行
- 将application.yml名称改为bootdtrap.yml
- 启动类启动
Spring Cloud Zuul
Spring Cloud Zuul 是一套边缘服务,它能实现动态路由、监控、负载和流量管理等功能。简单来说,Zuul就是服务应用端的一套负载均衡器。它是由一个核心ZuulServlet和一些列的过滤器组成
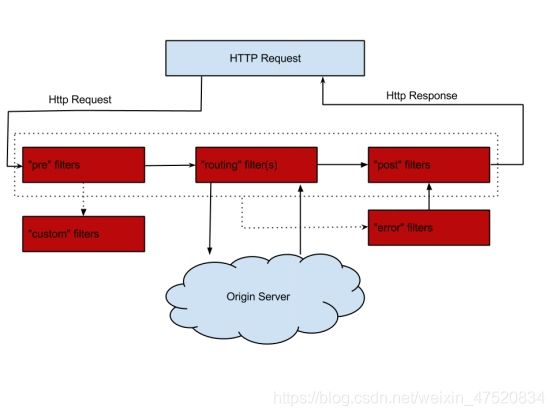
pre:前置过滤器。在请求被路由之前调用
routing: 路由过滤器。在前置调用完成之后,路由请求时被调用
error:处理请求时发生错误时被调用
post:在routing和error过滤器之后被调用
Origin Server :当前调用的服务
#Zuul统一了不同模块的接口地址 用户直接 Zuul地址+接口地址 即可调用不同模块的接口
创建Zuul服务
Spring项目向导
Pom文件

Zuul是单独的一个服务,需要重新创建一个新项目,除了加入Zuul相关依赖以外,还需要加入Config客户端和Eureka客户端依赖。
Zuul可以通过Config拉取配置文件,并注册至Eureka直接完成高可用,这个过程不需要任何配置信息。
创建Zuul服务端
@SpringBootApplication
@EnableDiscoveryClient
@EnableZuulProxy
public class ErosZuulApplication {
public static void main(String[] args) {
SpringApplication.run(ErosZuulApplication.class, args);
}
}
//Zuul服务加入@EnableZuulProxy注解即可
配置信息
eureka:
client:
service-url:
defaultZone: http://192.168.12.239:8761/eureka,http://192.168.12.239:8762/eureka
spring:
application:
name: api-geteway
cloud:
config:
discovery:
service-id: eros-config
enabled: true
profile: dev
label: release
server:
port:80
与配置中心客户端连接一样,连接配置中心,起名为api-config,同时在版本控制工具中上传对应的配置文件。配置文件可以参考Config示例创建同样的三个配置文件,并命名为api-config.yml、api-config-dev.yml、api-config-pro.yml。

在当前版本中,启动完Zuul服务直接访问zuul服务并加上需要访问的ServiceId(注册在Eureka的Application名)和请求路径即可完成转发。

从测试结果中可以看到,通过zuul服务地址+服务实例+接口地址 就可以完成请求转发的功能。整个过程如下图所示:
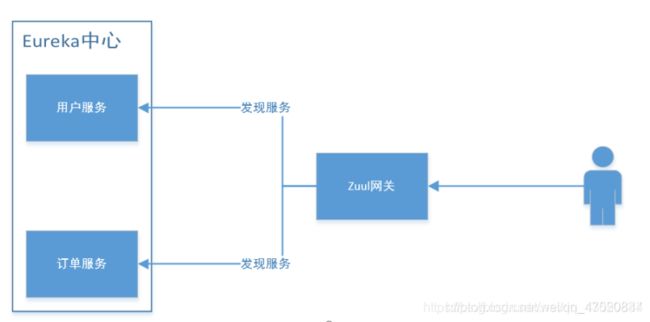
当用户访问网关时,Zuul网关会将Eureka上所有可用服务列表拉取下来,根据用户访问路径先匹配应用ID,然后将请求路径转发给对应的应用服务
Zuul服务的一些常用配置
配置路径转发的几种方式
Zuul启动后可以通过Zuul服务地址+实例名称和请求路径,对注册中心的服务进行访问,Zuul也提供自定义映射的功能,通过本方式可以间接的隐藏服务实例名称。当然原始的实例名称仍然可以访问
- 通过指定serviceId的方式自定义路径(完整版)
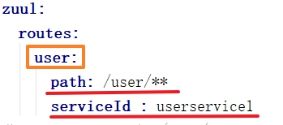
user可以随便制定,只为区别节点,并没有实际意义
path 需要映射的路径
serviceId 映射路径需要访问的实例名称
- 通过指定serviceId的方式自定义路径(简写版)

通过实例名:映射路径 可以简洁的声明实例名和映射路径
- 通过指定url的方式自定义路径
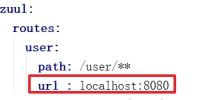
path 请求路径与上述其他定义一致,
url 请求路径需要转发的连接
通配符详解
| 通配符 | 说明 | 通配符示例 | 通配符示例说明 |
|---|---|---|---|
| ? | 匹配任意单个字符 | /user/? | 可以匹配/user/后面拼接的任意一个字符的路径。如:/user/a |
| * | 匹配任意数量的字符 | /user/* | 可以匹配/user/后面拼接的任意多个字符的路径。如:/user/123 |
| ** | 匹配任意数量的字符,支持多级目录 | /user/** | 可以匹配/user/后面拼接的任意多级目录路径。如:/user/photo/123 |
禁用服务
- 禁用所有默认映射的服务

为了防止用户直接通过服务ID访问接口,可以通过zuul.ignored-services通配符来禁用直接通过Eureka注册中心的服务名访问。如果需要单独限制,可以使用数组的方式声明对应的服务ID。如下图

连接及超时配置
Zuul的连接数,超时等常见配置在ZuulProperties的内部类Host类中。超时配置有两种情况:
- 当zuul使用了服务注册中心时,会有ribbon组件负责连接。开发者需要设置ribbon.ReadTimeout 和ribbon.SocketTimeout两项配置属性
- 当使用了zuul节点和url映射时,需要配置
zuul.host.connect-timeout-millis和zuul.host.socket-timeout-milli属性
-
连接超时配置

-
Ribbon超时设置

自定义过滤器

在Zuul的架构图中可以看到,zuul中由四层核心过滤器,分别是pre(前置)、routing(路由)、post(后置)和error(异常)过滤器。开发者一般可以通过前置过滤器完成用户权限校验,后置过滤器完成响应结果过滤等功能。主要的过滤器一共有10个,但是对应的过滤器都有自己的执行前置条件,所以,并不会因为过滤器过多而影响到性能。
内置过滤器基本介绍(了解)
| Filter名称 | Filter 的作用 |
|---|---|
| Pre 前置过滤器 | |
| ServletDetectionFilter | 判定当前请求是通过SpringMVC还是ZuulServlet来执行的 |
| Servlet30WrapperFilter | 将request对象进行二次包装 |
| FormBodyWrapperFilter | 文件上传时,对文件对象封装的过滤器 |
| DebugFilter | 调试过滤器,激活调试日志 |
| PreDecorationFilter | 查找路由 |
| Routing过滤器 | |
| RibbonRoutingFilter | 对通过serviceId路由访问的请求进行负载访问 |
| SimpleHostRoutingFilter | 对通过url路由访问的请求进行直接访问 |
| SendForwardFilter | 对请求上下文中的forward.do参数进行处理请求 |
| Post过滤器 | |
| SendErrorFilter | 在上下文中出现错误时处理 |
| SendResponseFilter | 使用当前上下文中的参数对访问端进行响应 |
自定义过滤器简介
@Component
public class SimpleFilter extends ZuulFilter {
@Override
public String filterType() {
//定义当前过滤器类型。具体过滤器类型详见org.springframework.cloud.netflix.zuul.filters.support.FilterConstants
return FilterConstants.PRE_TYPE;
}
@Override
public int filterOrder() {
//当前过滤器的顺序,值越小越靠前
return FilterConstants.PRE_DECORATION_FILTER_ORDER - 1;
}
@Override
public boolean shouldFilter() {
//true/false表示是否执行run方法
return true;
}
@Override
public Object run() throws ZuulException {
//过滤器的具体业务
return null;
}
}
自定义的Filter需要继承ZuulFilter父类,并添加@Component注解
ZuulFilter中定义了四个方法需要重写。
1.filterType方法 : 返回当前过滤器类型。包含有pre、routing、post、error类型过滤器。具体可以参考FilterConstants类中的*_type常量定义
2..filterOrder : 返回当前过滤器的运行顺序,值越小,运行优先级越高。值定义在FilterConstants类中的_order常量。前置过滤器官方demo给的建议是运行在PreDecorationFilter过滤器之前。后置过滤器官方demo给的建议是运行在SendResponseFilter之前
3.shouldFilter : 返回当前过滤器是否要执行run方法。无特殊情况时,一般返回true即可。
4.run:过滤器的主要逻辑业务方法。该方法可直接返回null即可。不需要返回其他值。
1.1.1.2. 自定义pre前置过滤器
@Component
public class SessionFilter extends ZuulFilter {
@Override
public String filterType() {
//定义当前过滤器类型。具体过滤器类型详见org.springframework.cloud.netflix.zuul.filters.support.FilterConstants
return FilterConstants.PRE_TYPE;
}
@Override
public int filterOrder() {
//当前过滤器的顺序,值越小越靠前
return FilterConstants.PRE_DECORATION_FILTER_ORDER -1;
}
@Override
public boolean shouldFilter() {
//true/false表示是否执行run方法
return true;
}
@Override
public Object run() throws ZuulException {
//zuul内置RequestContext对象,可获取当前请求的上下文
RequestContext requestContext = RequestContext.getCurrentContext();
HttpServletRequest request = requestContext.getRequest();
String uid = request.getParameter("uid");
if(StringUtils.isEmpty(uid)){
//终止后续过滤器的执行
requestContext.setSendZuulResponse(false);
//设置响应码
requestContext.setResponseStatusCode(HttpStatus.SC_BAD_REQUEST);
requestContext.getResponse().setContentType("text/html;charset=utf-8");
requestContext.setResponseBody("无权限访问~");
}else{
//redis中查找用户id对应的token是否存在,判定当前用户是否有权限。
}
return null;
}
}
# filterType() 返回值定义为**FilterConstants.****PRE_TYPE**类型,将当前过滤器定义为前置过滤器
# filterOrder()返回值按照官方的建议,filterOrder取值为 FilterConstants.PRE_DECORATION_FILTER_ORDER -1
# run() 主要负责过滤器的主业务逻辑
RequestContext 是Zuul内置的对象,通过该对象可以获取当前请求的Request和Response对象。
requestContext.setSendZuulResponse(false); 当设置为false时将会中断后续的过滤器执行
requestContext.setResponseStatusCode(HttpStatus.SC_BAD_REQUEST); 当设置了SendZuulResponse为false时,需要设置当前响应的状态码
requestContext.setResponseBody("error context"); 设置当前错误信息的响应文本
1.1.1.3. 自定义其他类型过滤器
除了创建pre前置过滤器以外,还可以按照FilterConstants类中的 *_type常量定义filterType方法的返回值来定义具体过滤器类型。同时定义filterOrder的返回值来定义过滤器执行顺序。