eBPF 是一个用于访问 Linux 内核服务和硬件的新技术,由于其灵活性和高性能等特点,被迅速用于网络、出错、跟踪以及防火墙等多场景。目前国内已有少数企业开始尝试将 eBPF 引入生产实践,又拍云也是其中一个。专为技术开发者提供知识分享的 Open Talk 公开课邀请了又拍云开发工程师周晨约直播分享 eBPF 的学习经验与开发心得,并对其分享内容进行整理,下拉至文末点击阅读原文可回看原视频。

大家好,今天分享的主题是《eBPF 探索之旅》,围绕三部分展开:
- eBPF 是什么
- eBPF 能做什么
- 如何编写 eBPF 程序
认识 eBPF
eBPF 是什么,从字面上来看是扩展伯克利包处理器,那伯克利包处理器是什么呢?

在此之前先来了解一个性能优秀的常用抓包工具:tcpdump
tcpdump

图中展示了两个常用指令
指令一:指定 IP 和端口,可以抓到 IP 为 220.173.103.227,端口为 80 的包
指令二:加上 grep,可以过滤出带有 route 字段的数据
那么 tcpdump 又是如何做到通过用户提供的规则处理网络上收到的包,再 copy 给用户的呢?如果放在用户层,就需要在系统里所有 socket 读写的时候做一层处理,把规则放上去,这样做难度太大。而 tcpdump 是基于 libpcap 库实现的,libpcap 能做到在驱动将包交给内核网络时,把包取过来,通过用户传给 libpcap 的规则将需要的网络包 copy 一份给用户,再把包传给内核网络栈,而之所以 libpcap 能做到这点全靠 BPF。
BPF
BPF 是基于寄存器虚拟机实现的,支持 jit,比基于栈实现的性能高很多。它能载入用户态代码并且在内核环境下运行,内核提供 BPF 相关的接口,用户可以将代码编译成字节码,通过 BPF 接口加载到 BPF 虚拟机中,当然用户代码跑在内核环境中是有风险的,如有处理不当,可能会导致内核崩溃。因此在用户代码跑在内核环境之前,内核会先做一层严格的检验,确保没问题才会被成功加载到内核环境中。
eBPF:BPF 的扩展
回到 eBPF,它作为一个 BPF 的扩展,都扩展了些什么呢?
- 首先在功能上,不仅仅局限于网络,它能够借助 kprobe 获取内核函数运行信息,这样调试内核就不需要 gdb 或者加入内核探点重新编译内核。
- 可以借助 uprobe 获取用户函数的运行信息,kprobe 和 uprobe 不仅能获取函数运营信息,还可以获取代码执行到了哪一行时的寄存器以及栈信息,其原理可以理解为在某个指令打断点,当 cpu 执行到这个断点的时候,cpu 会保存当前的寄存器信息,然后单步执行断点持载的 handler,也是想要在内核中执行的逻辑,执行完成后 cpu 会回到这个断点的位置,恢复寄存器的状态,然后继续运行下去。
- 支持 tracepoint,即在写代码中加入 trace 点,获取执行到这点时的信息。
- 可以嵌入到 perf_event 中。我们熟知的 XDP 以及 tc 都是基于 eBPF 实现的,并且在性能上有着不俗的表现。
eBPF 的功能
- 系统性能监控/分析工具:能够实现性能监控工具、分析工具等常用的系统分析工具,比如 sysstate 工具集,里面提供了 vmstate,pidstat 等多种工具,一些常用的 top、netstat(netstat 可被 SS 替换掉),uptime、iostat 等这些工具多数都是从 /proc、/sys、/dev 中获取的会对系统产生一定的开销,不适合频繁的调用。比如在使用 top 的时候通过 cpu 排序可以看到 top cpu 占用也是挺高的,使用 eBPF 可以在开销相对小的情况下获取系统信息,定时将 eBPF 采集的数据 copy 到用户态,然后将其发送到分析监控平台。
- 用户程序活体分析:做用户程序活体分析,比如 openresty 中 lua 火焰图绘制,程序内存使用监控,cdn 服务异常请求分析,程序运行状态的查看,这些操作都可以在程序无感的情况下做到,可以有效提供服务质量。
- 防御攻击:比如 DDoS 攻击,DDoS 攻击主要是在第七层、第三层以及第四层。第七层的攻击如 http 攻击,需要应用服务这边处理。第四层攻击,如 tcp syn 可以通过 iptable 拒绝异常的 ip,当然前提是能发现以及难点是如何区分正常流量和攻击流量,简单的防攻击会导致一些误伤,另外 tcp syn 也可以通过内核参数保护应用服务。第 3 层攻击,如 icmp。对于攻击一般会通过一些特殊的途径去发现攻击,而攻击的防御则可以通过 XDP 直接在网络包未到网络栈之前就处理掉,性能非常的优秀。
- 流控:可以控制网络传输速率,比如 tc。
- 替换 iptable:在 k8s 中 iptable 的规则往往会相当庞大,而 iptable 规则越多,性能也越差,使用 eBP 就可以解决,关于这方面有很多开源的实践可以参考。
- 服务调优:如下图所示,在 cdn 服务中难免会出现一些指标突刺的情况,这种突刺拉高整体的指标,对于这种突刺时常会因为找不到切入点而无从下手,eBPF 存在这种潜力能帮助分析解决该问题,当 eBPF 发现网络抖动,会主动采集当时应用的运行状态。

eBPF 程序实践
编写 eBPF 程序的内核最低也要是 3.15,此版本刚好可以支持 eBPF ,但这时 eBPF 支持的特性比较少,不建议使用,最好是 4.8 以上的内核,内核越新 eBPF 支持的功能就越成熟。另外像 kprobe、uprobe、traceport 相关的参数要开起来,否则只能用 BPF的某些特性,而无法使用eBPF 的特性,相当于是空壳。通过路径 /lib/modules/uname-r/source/.config 或者在 /boot/ 下查找对应版本的内核 config 来查看系统是否开启了所需的参数。
编写 eBPF 程序的对环境也有一定的要求。eBPF 代码需要编译成 llvm 的字节码,才能够在 eBPF 及虚拟机中运行,因此需要安装 llvm 以及 clang,安装好之后可以通过 llc 来查看是否支持 BPF。

eBPF 代码示例
内核、环境都准备好后就可以开始编写工作了。如果是不借助任何工具直接手写一个 eBPF 程序会非常的困难,因为内核提供的文档对如何编写 eBPF 程序的说明是比较缺乏的。当然内核也有提供工具,在内核包中的 bpftool 工具。推荐是使用工具 bcc,它能够降低写 BPF 程序的难度,提供了python、lua 的前端。以 python 为例,只需要写好需要载入 eBPF 的 C代码,再通过 bcc 提供的 BPF 类就可以将代码载入到 eBPF 虚拟机中,执行 python 程序,代码就可以运行起来了。

图中是 bcc 工具的使用例子,代码非常简单,导入一下 BPF,进行 BPF 初始化。
- text 是要执行的代码,里面是一个函数
- kprobe__schedule 内容是调用 bpf_trace_printk(“hello world\n”);return 0
- kprobe__schedule 的含义是用 kprobe的 特性在内核调用 schedule 函数的时候调用 bpf_trace_printk,打出 hello world
- bpf_trace_printk 会把这些输出到 /sys/kernel/debug/tracing/trace_pipe 里,后面的 trace_print 就可以把数据打印出来
下面是通过 kprobe 监控机器 tcp(ipv4)的连接状态变化。首先需要知道 tcp 状态变化时内核会调用哪些函数。除了 time-wait 状态之外,其他状态基本上是通过 tcp_set_state 设置的。在 time-wait 阶段的时候,内核会创建一个新的结构体去存 time-wait 的 socket,内核考虑到内存的开销问题,之前的 socket 会释放掉。先不考虑 time-wait。

接下来看看具体的代码,上图中是载入到 eBPF 的 C 代码。
- 最上面的 BPF_HASH 表示创建一个 BPF 提供的 HASH 表;last 是 HASH 表的名称;struct sock* 是指 key 的大小,这里表示指针大小;uint64_t 是 value 的大小,为 64 位;最后的 10240 表示 map 最多能够放多少个元素。
- 往下是一个结构体 bcc_tcp_state,可以看到后面有一个 BPF_PERF_OUTPUT,它是利用到了 perf ring buffer 的一个特性。
- 再下面是函数 get_tcp_state_change,该函数会在内核调用 tcp_set_state 的时候调用。
通过内核的几个参数,内核的结构体 socket,以及这个函数传进来的一些 state,可以获取当时 tcp 连接的状态转化情况,上图函数的第一个参数 ctx 实际上是寄存器,后面是要介入函数的两个参数。这里会把一些 tcp 的状态存起来,使用 perf_submit 将这些状态更新到 perf ring buffer 中,就可以在用户态把 perf ring buffer 东西给读出来,这就是 tcp 的一些状态变化。
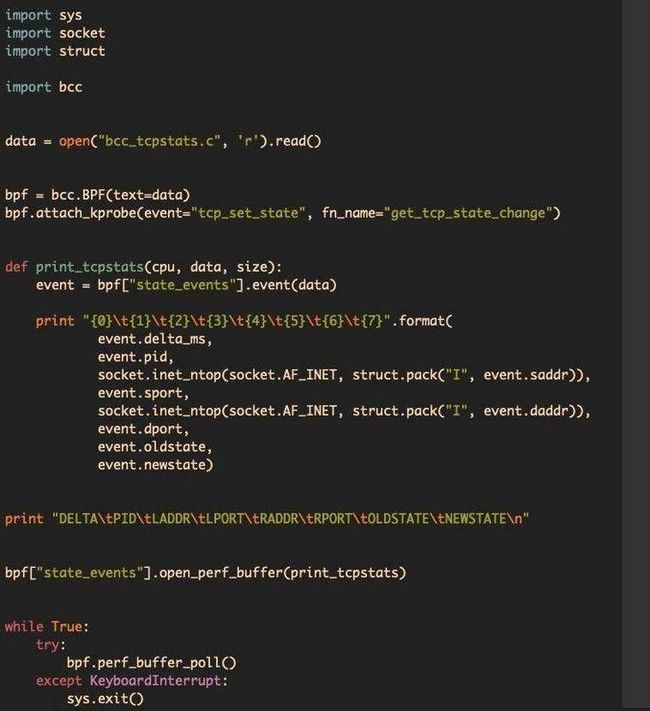
上图是 python 代码。
- 首先把 C 代码读进来,通过调用 bpf 初始化,将代码编译成 eBPF 字节码,载入到 eBPF 虚拟机中运行。
- 下面是 attach_kprobe,就是在内核调用 tcp,event 是指内核在调用 tcp_set_state 的时候,fn_name 是指内核在调用 tcp_set_state 时会执行 get_tcp_state_change 函数,就是前面 C 代码中的函数。
- 打开 perf ring buffer,即后面调用的 bpf[“state_events”].open_perf_buffer,里面的参数是一个 Callback 函数,在ring buffer 有数据的时候就会调用一次 print_state,也就是说在 C 代码中调用 perf_sumbit 时候就可以调用一次 print_tcpstats 函数,并会输出存入的数据。
- 最下面调用了 perf_buffer_poll的功能,只会在 ring buffer 有消息时被唤醒,再调用 Callback 函数,这样就不会无谓地浪费 CPU。
利用 uprobe 查看应用服务信息

上图是通过 uprobe 查看 nginx 请求分布的情况。首先要看 nginx 创建请求的位置,是在 ngx_http_create_request,和之前一样写一个要嵌入 eBPF 虚拟机的 C 代码,还是创建一个 HASH 表,名称是 req_distr,key 是 32 位大小,value 是 64 位,核心函数是 check_ngx_http_create_request,在 nginx 调用该函数时,会执行这个钩子函数,函数内部调用的是 count_req。把 PID 和 PID 上创建的请求次数对应起来,当 PID 调用过 ngx_http_create_request 时,请求计数就会 +1。如此也就可以看到整个请求在各个 work 上的分布情况。
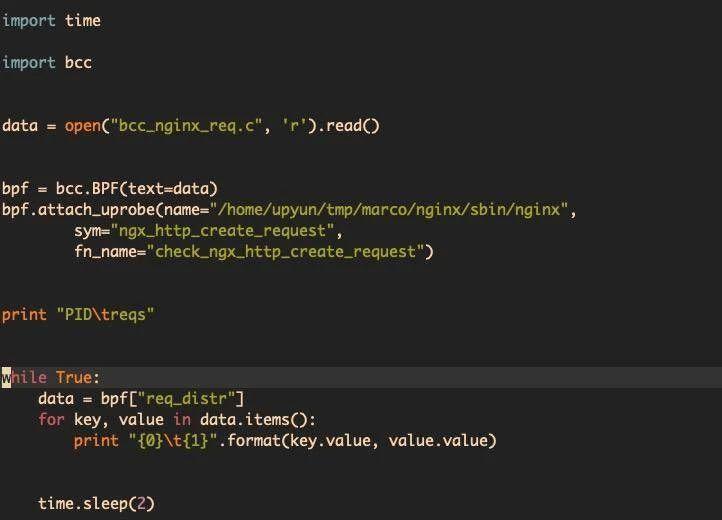
图中是 python 代码,同样把 C 代码读进来,并调用 bbf 把代码编译成 llvm 字节码,载入到 eBPF 虚拟机中,再调用 attach_uprobe。name 是指 nginx 的一个二进制文件,sym 是指要在哪个函数中打个断点,上图是 ngx_http_create_request 函数。fn_name 是在 ngx_http_create_request 函数执行的时候需要调用的函数。另外需要注意二进制文件必须要把编译符号开放出来,比如编译的时加个 -g,否则会找不到这个函数。最下面是简单地获取 HASH 表,去输出 HASH 表的 key 和 value,这样就能看到 pid 对应的 request 数量,pid 也就会对应着 worker,如此就能够查看到运行 nginx 的请求分布情况。
查看运行中的 eBPF 程序与 map
可以通过内核包中 bpftool 提供的 bpftool 工具查看,它的目录是在 /lib/modules/uname-r/tools/bpf/bpftool 中,需要自己编译一下,在 /lib/modules/uname-r/tools 下执行 make-C/bpf/bpftool 就可以了。

上图是 bpftool 工具查看 map(前面 BPF_HASH 创建的)情况的效果,-p 参数,能够展示得好看一些。prog 参数可以把在虚拟机中跑的程序给展示出来。这样就能看到到底运行了那些 eBPF 程序以及申请的 map。
eBPF 在又拍云的发展
- 完善 cdn 系统监控体系
- 强化 cdn 业务链路 traceing,提高服务水平,提供更多的性能分析的途径
- 解决 cdn 服务中遇到的某些难以解决的问题 注:目前通过 systemtap 可以解决
- 将 XDP 引入又拍云边缘机器,给予防范 DDoS 攻击提供帮助
- 替换 tcpdump 工具,加快抓包效率,减少抓包时对系统性能的影响