Python爬虫基础(爬取豆瓣电影Top250数据并存入MySQL关系型数据库)
文章目录
- 爬虫的基本原理
- requests.get() 发送请求
- XPath 解析HTML文档
- MySQL 数据库
- 爬取豆瓣电影Top250数据并存入MySQL数据库
爬虫的基本原理
我们用浏览器打开一个网页,一般是通过HTTP协议(超文本传输协议)或者HTTPS协议(可以理解为HTTP的安全版)对服务器的一个资源进行请求,返还得到一份HTML文档,然后浏览器对这份HTML文档进行渲染,这样就形成了我们所看到的网页。而爬虫就是模拟浏览器发送了一个请求,从而获得了这份HTML文档,最后从文档中抽取出我们所需要的内容即可。
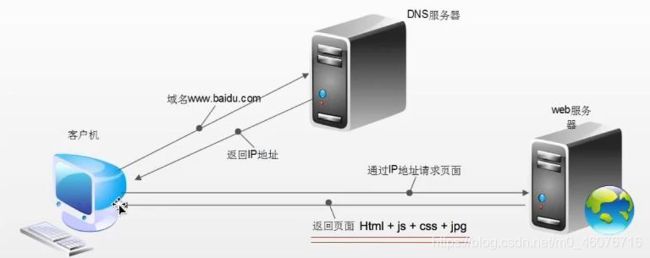
浏览器发送HTTP请求的示意图如下:客户端通过HTTP协议对DNS服务器发送请求,返还得到一个IP地址,然后通过IP地址请求web服务器,返还得到HTML文档。
requests.get() 发送请求
请求头
请求头是用来说明服务器要使用的附加信息,比较重要的信息有 Cookie、Referer、User-Agent 等。一般请求头可以用 User-Agent ,在做爬虫时加上此信息,可以伪装为浏览器;如果不加,有可能会被识别出为爬虫而获取不到数据。
请求头怎么找
以豆瓣电影Top250为例(https://movie.douban.com/top250)
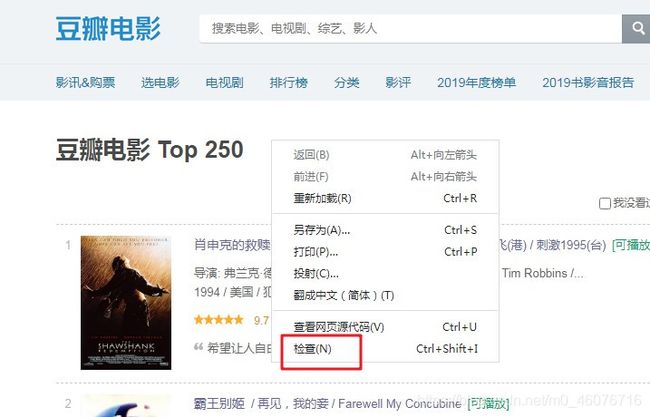
- 先打开这个网址,在空白处右键鼠标,点击【检查】(如果没有检查的话,建议换用谷歌浏览器打开)
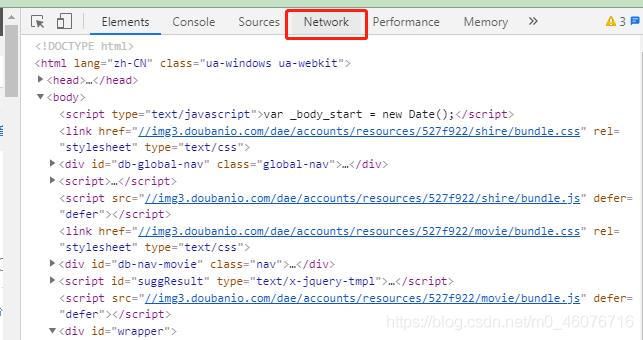
- 右边弹出来的框里面,选择【Network】点击
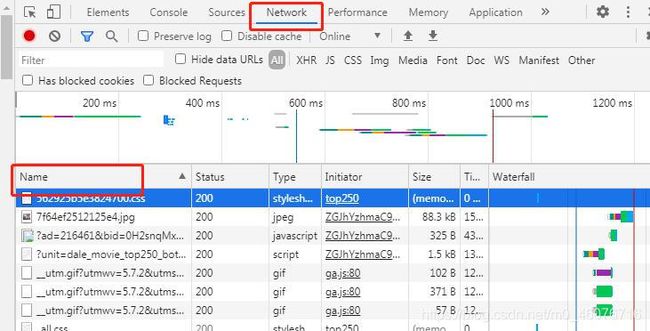
- 可以看到下面有【Name】,如果没有,那么刷新一下网页(别关闭这个窗口哟)就有了
- 再鼠标左击随便一条【Name】下的属性,又会弹出一个框(下图绿色框起来的部分)
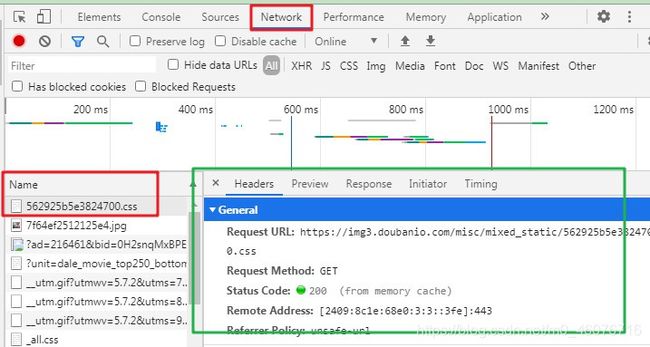
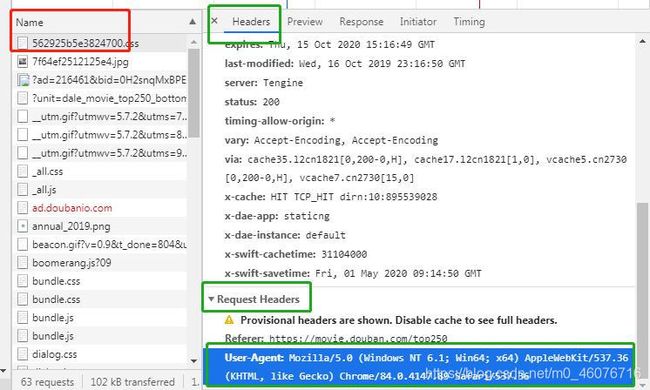
- 下拉这一部分的内容,可以看到下面有个Request Headers,把User-Agenty那一部分的内容复制下来,这个就是我们要找的 请求头
import requests
url = 'https://movie.douban.com/top250'
# 这里要把拿到的请求头改成字典的格式,建议用单引号或者三引号,因为有的时候可能内部包含有双引号
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'}
# 向目标网站发送请求
response = requests.get(url=url, headers=headers)
# 打印响应状态码(一般我们只要记住200代表成功,400代表错误,其他的遇到再查就行了)
print(response.status_code)
# 响应的内容以文本形式得到(得到的是str类型,这个就是我们需要的文档,然后把它转成html就可以通过xpath解析了)
print(response.text)
# 响应的内容以字节流形式得到
# 比方说我们需要爬取网站的图片时,可以通过xpath解析获取到图片的url, 然后通过该方法转换为字节流,再通过open(mode='wb')写入本地
print(response.content)
""" 下面这几个作为了解,本文不怎么用 """
# print(response.url) # 打印 请求url
# print(response.headers) # 打印 头信息
# print(response.cookies) # 打印 cookie信息
XPath 解析HTML文档
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言。我们这里就是利用 XPath 语言在上一步请求到的HTML文档中查找我们需要的数据。
XPath 语法(这里列举的不用记,需要的时候可以查询,后面会讲到如何直接找到 xpath 路径,不需要自己写)
| 表达式 | 描述 |
|---|---|
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| 路径表达式 | 描述 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点 |
| /bookstore | 选取根元素 bookstore |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置 |
| //@lang | 选取名为 lang 的所有属性 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素 |
| /bookstore/book[position() < 3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00 |
| /bookstore/book[price>35.00]//title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00 |
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型的节点 |
| 路径表达式 | 描述 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素 |
| //* | 选取文档中的所有元素 |
| //title[@*] | 选取所有带有属性的 title 元素 |
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素 |
| //title | //price | 选取文档中的所有 title 和 price 元素 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素 |
小案例:如何爬取下图中的【豆瓣电影 Top 250】
上一步操作我们知道了如何请求数据,现在我们需要对数据进行解析,从中找到【豆瓣电影 Top 250】对应的这部分数据,那么要用到 xpath,如果自己按照上面的语法写很麻烦,那么怎样快速找到这部分数据对应的 xpath 呢?
流程如下:
- 选中我们需要找的内容,鼠标右键 - 点击【检查】
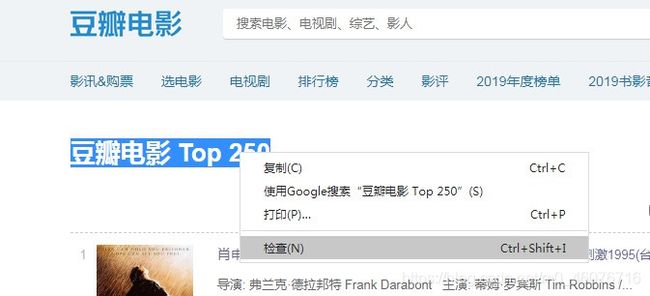
- 自动帮我们找到了想要的内容,然后再对准内容右键【Copy】 - 【Copy XPath】,就得到了我们所需要的,再把复制的XPath粘贴到代码中去

import requests
from lxml import etree
url = 'https://movie.douban.com/top250'
# 这里要把拿到的请求头改成字典的格式,建议用单引号或者三引号,因为有的时候可能内部包含有双引号
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'}
# 向目标网站发送请求
response = requests.get(url=url, headers=headers)
print(response.status_code) # 响应状态码为200,说明获取成功
# 把str解析成html文档, 返回根目录, 即元素
html = etree.HTML(response.text)
# 把复制得到xpath粘贴到这里,后面加 /text() 是读取文本信息
result = html.xpath('//*[@id="content"]/h1/text()')
print(result) # 返回列表
print(result[0]) # 取列表中的元素
输出:
200
['豆瓣电影 Top 250']
豆瓣电影 Top 250
MySQL 数据库
MySQL 是最流行的关系型数据库管理系统,很多公司都是用数据库存放数据的,所以了解一些基本的数据库知识显得非常有必要。最后的案例当中,我们会把我们写的爬虫爬取到的数据存放到 MySQL 数据库当中去。
安装 MySQL
MySQL下载地址,请点击我

如果不会安装的话:
Windows版本请参照这个链接方法,请点击我
Navicat Premium 使用中可能会遇到的问题
Navicat premium 是一款数据库管理工具,可以使您在管理数据库的时候更加方便,一般来说我们用 Python 来操作数据库,用 Navicat Premium 来查看数据库,大家可以自己去安装一个 Navicat Premium,安装好之后打开的界面是这样的:
连接数据库操作:点击左上角【连接】- 【MySQL】,输入您安装MySQL时得密码,我的密码是 54110,再点【连接测试】
如果报像这样的错
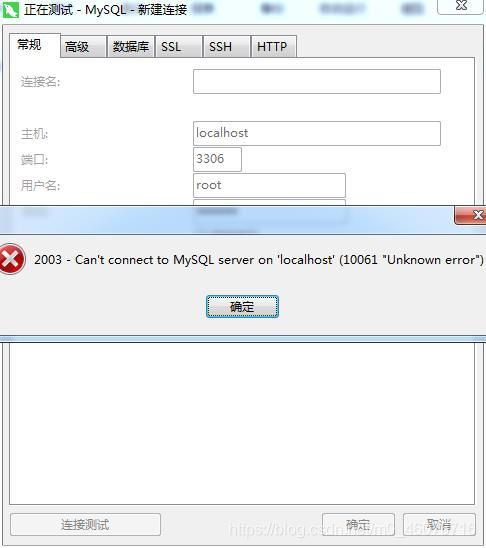
只需要到计算机管理里面启动MySQL的服务就可以了

其他的问题解决方案如下:
2059 - authentication plugin…错误请点击我
Connection with same connection name already exists in the project错误请点击我
连接上之后,就可以通过右键新建数据库等操作了,当然也可以通过Python创建数据库等其他操作,对Navicat操作我们不做介绍。可以看到这里我新建了一个名为 crawler_film 的数据库,然后在这个数据库中新建了一个名为top250的表,表中保存了我爬取的 豆瓣电影Top250 的电影名,导演,拍摄时间,拍摄地,电影类型,评分,评论人数,电影宣传图片的url等信息,这也是最后我们要做的一个案例。
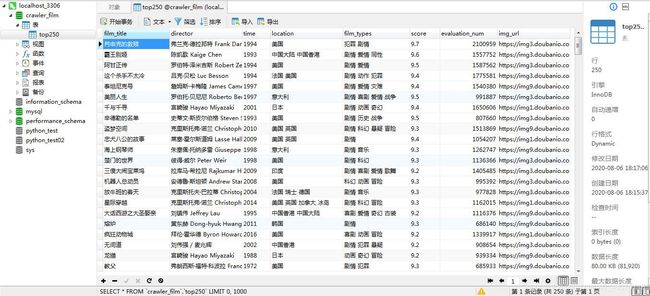
对于下面代码中用到的Python操作MySQL数据库的语法不太清楚的,可以参考:
主要是对MySQL数据库增删改查的Python操作,请点击我
爬取豆瓣电影Top250数据并存入MySQL数据库
模块一:
import pymysql
# 储存配置信息
class MyConfig:
def __init__(self):
self.host = 'localhost' # 数据库服务器地址或(也可以是 '127.0.0.1')
self.user = 'root' # 数据库用户名
self.password = '54110' # 数据库密码
self.port = 3306 # 端口号
self.db = 'crawler_film' # 数据库名
# 创建数据库方法(也可以去Nacicat手动创建)
def create_database(self):
# 声明一个MySQL连接对象
db = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port)
cursor = db.cursor() # 获得MySQL的操作游标
# 创建数据库(数据库名叫作crawler_film,默认编码为UTF-8)
cursor.execute("create database crawler_film default character set utf8")
db.close() # 关闭连接
if __name__ == '__main__':
config = MyConfig()
config.create_database() # 创建数据库
模块二:
import requests
from lxml import etree
import os
import pymysql
from Config import MyConfig
class GetDoubanTop250:
def __init__(self):
self.config = MyConfig() # 实例化配置对象, 再用实例对象调用属性
self.db = pymysql.connect(host=self.config.host, user=self.config.user, password=self.config.password,
port=self.config.port, db=self.config.db)
def get_data(self, url, headers):
response = requests.get(url, headers=headers) # 请求目标网站
# print(response.status_code) # 打印状态码(200为获取成功)
html = etree.HTML(response.text) # 把str解析成html文档, 返回根目录, 即元素
page25 = html.xpath('// *[ @ id = "content"] / div / div[1] / ol / li') # 得到每页的25个电影Element组成的列表,每个Element可供继续往下查找
# 当网址超过最后一页时, html还是可以获取到, page25就为空列表[], for循环之下都不会运行, film_title=""被返回, break死循环
film_title = ""
for element in page25: # 遍历每个电影的Element
film_title = element.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0] # 获取电影名
director = element.xpath('./div/div[2]/div[2]/p[1]/text()')[0].split("\xa0")[0].split("导演:")[1].strip() # 获取导演
time = element.xpath('./div/div[2]/div[2]/p[1]/text()[2]')[0].split("\xa0")[0].strip() # 获取拍摄时间
location = element.xpath('./div/div[2]/div[2]/p[1]/text()[2]')[0].split("\xa0")[2].strip() # 获取拍摄地
film_types = element.xpath('./div/div[2]/div[2]/p[1]/text()[2]')[0].split("\xa0")[4].strip() # 获取电影类型
score = element.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0] # 获取评分
evaluation_num = int(element.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0].replace("人评价","")) # 获取评论人数
img_url = element.xpath('./div/div[1]/a/img/@src')[0] # 获取电影宣传图片的url
r = requests.get(img_url)
with open("E:/电影宣传图片/{}.jpg".format(film_title), mode="wb") as file:
file.write(r.content) # 保存电影宣传图片
self.save_data(film_title,director,time,location,film_types,score,evaluation_num,img_url)
return film_title
def save_data(self, *args):
cursor = self.db.cursor()
create_table_sql = """ create table if not exists top250(
film_title varchar(100) comment "电影名",
director varchar(100) comment "导演",
time varchar(100) comment "电影时间",
location varchar(100) comment "电影拍摄地",
film_types varchar(100) comment "电影类型",
score varchar(50) comment "电影评分",
evaluation_num int comment "评价人数",
img_url varchar(500) comment "宣传图片url")"""
insert_sql = """insert into top250(
film_title,director,time,location,film_types,score,evaluation_num,img_url)
values(%s,%s,%s,%s,%s,%s,%s,%s)"""
cursor.execute(create_table_sql) # 执行创建表的SQL语句即可, 不需要调用commit()
# 对于数据插入、更新、删除操作,都需要调用commit()才能生效, 只需要改一下SQL语句就可以了
# 注意:这里的SQL语句最好用占位符的方法,然后把值写到execute方法中来, 否则容易'神仙'报错
cursor.execute(insert_sql, (args[0],args[1],args[2],args[3],args[4],args[5],args[6],args[7]))
self.db.commit()
if __name__ == '__main__':
if not os.path.exists("E:/电影宣传图片"):
os.makedirs("E:/电影宣传图片")
page = 0
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"}
gdt = GetDoubanTop250()
while True:
url = "https://movie.douban.com/top250?start={}&filter=".format(page) # 每页网址规律:start={}每页+25
film_title = gdt.get_data(url, headers)
if film_title == "":
gdt.db.close() # 关闭MySQL连接
break
page += 25