当强化学习遇上循环神经网络:从System 1到System 2 Deep Learning
点击蓝字 • 关注我们
AI TIME欢迎每一位AI爱好者的加入!
在复杂多变的环境中,如何去学习具有高度适应性和认知性的策略,是认知科学和人工智能的核心问题。本报告会介绍讲者最近在强化学习(RL)中利用循环神经网络(RNN)来实现更具有认知性(cognitive),更高效的控制策略的两篇工作:
(1)讲者会介绍用于部分可观测环境(POMDP)中强化学习的一种变分循环神经网络(variational RNN)模型。此模型可以通过预测环境中的状态转变,将环境中的不可观测信息编码在RNN的internal states中。并提出了一种相应的算法,可以高效地实现在部分可观测环境中的强化学习。
(2)提出一种新颖的,多层级的循环神经网络(multiple-levels RNN)模型,用于通过端对端(end-to-end)的无模型强化学习(model-free RL)来解决分层控制(hierarchical control)的任务。通过实验我们可以观察到,在一个具有挑战性的控制任务中,此RNN会在强化学习中逐步自组织出动作层次结构(self-organization of action hierarchy)。该层次结构在高层的RNN中对应子目标(sub-goal)的抽象表示,而在低层的RNN中对应底层动作控制。另外这个自组织的动作层次结构可以帮助智能体,在由已经学习过的子目标重新组成的新任务中更快地进行重新学习 。

韩东起:本科毕业于中国科学技术大学物理系,现为Cognitive Neurorobotics Research Unit, Okinawa Institute of Science and Technology (OIST) 的PhD Candidate,导师为 Jun Tani和 Kenji Doya。他的主要研究兴趣是所有和神经网络有关系的课题,包括人工神经网络的应用(主要是深度强化学习),生物神经回路的建模(脉冲神经网络)以及利用人工神经网络模型研究认知神经科学。

一、背景知识
图灵奖得主Yoshua Bengio在NeurIPS 2019带来了一场题为《From System 1 Deep Learning To System 2 Deep Learing》的报告。
Yoshua的第一个观点,是指人的认知系统包含两个子系统(这是认知理论中大家共识的观点):
①System 1直觉系统,主要负责快速、无意识、非语言的认知,这是目前深度学习主要做的事情;
②System 2是逻辑分析系统,是有意识的、带逻辑、规划、推理以及可以语言表达的系统,这是未来深度学习需要着重考虑的;

强化学习(Reinforcement Learning):
强化学习是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题,强化学习的常见模型是马尔可夫决策过程。近些年来热门的深度强化学习(deep RL),其实就是用神经网络作函数近似的强化学习。
1、马尔可夫决策过程(Markov Decision Processes, MDPs)
MDPs 简单说就是一个智能体(Agent)采取行动(Action)从而改变自己的状态(State)获得奖励(Reward)与环境(Environment)发生交互的循环过程。
MDP 的策略完全取决于当前状态(Only present matters),这也是它马尔可夫性质的体现。
其可以简单表示为:
![]()
强化学习算法按照策略更新方式的不同,可以分为基于价值的(value-based) 和基于策略的(policy-based) 两类方法。有一种算法合并了Value-based和 Policy-based 两类强化学习算法,就是Actor-Critic方法。
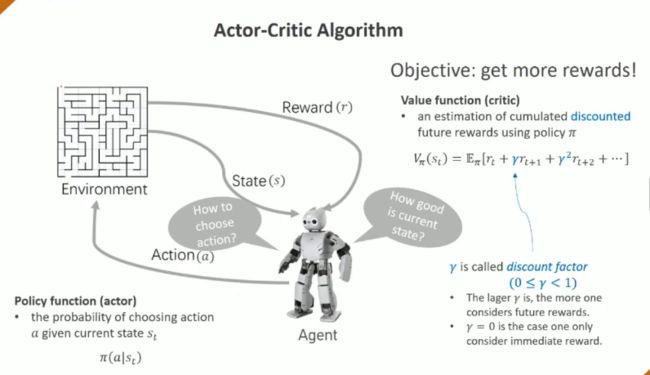
2、Actor-Critic Algorithm
构造一个agent,既能直接输出策略policy function,又能通过 价值函数value function 来实时评价当前策略的好坏。所以我们需要两个输出,一个负责生成策略的 Actor 和一个负责评价策略的 Critic,而且两者都还在不断更新,这种互补式的训练方式有时会比单独的策略网络或者值函数网络更有效。
3、RL&RNN
① RL(Reinforcement Learning)
强化学习算法是在探索环境的过程中学习在特定的情境下选择哪种行动可以得到最大的回报。
特点:
1、习惯性的系统:agents是具有明确的目标的,所有的 agents 都能感知自己的环境,并根据目标来指导自己的行为(做能获得更多rewards的事情)
2、通过算法设计来更高效地实现;
3、无意识的系统:输入观测量,输出指导行为;
4、自我探索:不需要大量data,弱监督任务也可以自我学习;
② RNN(Recurrent Neural Networks)
循环神经网络是一种能有效的处理序列数据的神经网络结构。它可以描述动态时间行为,因为和前馈神经网络(feedforward neural network,FNN)接受较特定结构的输入不同,RNN将状态在自身网络中循环传递,因此可以接受更广泛的时间序列结构输入。[Ref 1]
特点:
1、前后文相关:处理序列data;
2、信号在神经网络里传播的路径长;
3、元学习(meta-learning)的功能[Ref 2];
4、有包含信息的hidden state,不是单纯的输入输出工具;
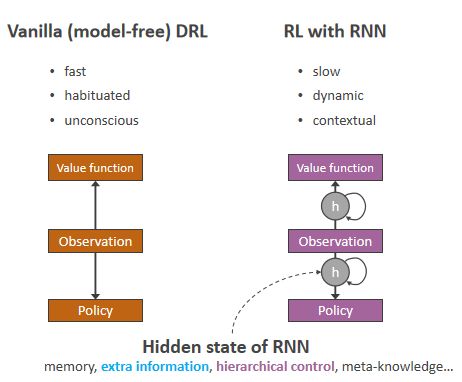
Deep RL:输入是观测量,输出是价值函数和观测函数
RL with RNN:RNN 比前馈神经网络多了一个承载前后文信息的 hidden state,扮演一个“心灵”的角色。
hidden state:可以通过一些方法可以让它表示丰富的信息,比如历史信息,阶层式的控制的子目标/抽象动作、关于当前任务集的meta-knowledge。
二、用变分循环神经网络来解决部分可观测的控制任务
论文链接:https://openreview.net/forum?id=r1lL4a4tDB
1、简介
在部分可观测环境中,深度强化学习经常会达不到令人满意的性能。这是因为我们需要同时解决两个问题:如何从原始观测中提取信息来解决任务,以及如何改进策略。在本研究中,我们提出了一种求解部分可观测任务的强化学习算法。
我们的方法包括两个部分:用于建模环境的变分RNN模型(VRM),和一个以环境中可观测信息以及VRM的隐藏状态为输入的的强化学习控制器。
该算法在两种部分可观测的机器人控制任务中进行了测试——坐标或速度不可观测的任务和需要长期记忆的任务。我们的实验表明,在不能以简单的方式从原始观测中推断环境中隐藏信息的任务中,与其他算法相比,该算法达到了更好的样本效率和/或学习了更优的策略。
2、motivation
●在解决需要考虑历史观测量的时候,直接把RNN作为函数近似器(function approximator)很可能会导致训练不稳定,因为本身RNN就相比FNN难训练,而且RL函数的target依赖于本身函数的近似(“bootstrap”)。
●而如果用一个RNN去做自监督学习(输入:当前观测:输出:未来观测) ,可以让RNN更容易地去理解环境的状态转换。
●这时RNN的hidden state可以看作环境中的隐变量的一种表示。再用其来作为RL的附加输入可以显著提升学习效率。
3、实验

横坐标:和环境接触的步数 纵坐标:平均的performance
第一列是控制任务示意图;
第二列完全可观测(包括机器人的坐标&速度和各关节的角度&角速度);
第三列部分可观测(只包括机器人的速度和各关节的角速度);
第四列部分可观测(不包括机器人的速度和各关节的角速度);
我们注意到,在需要用较长序列的原始观测来推断环境信息的任务中(比如第三列,需要用速度/角速度推断坐标/角度),我们的算法比其他算法具有明显的优势。这和我们的motivation相符合。
三、基于递归神经网络和强化学习的动作层级自组织
论文链接:https://doi.org/10.1016/j.neunet.2020.06.002
1、引言:关于动作层级
在一个复杂的强化学习问题中,一个任务可以包含若干个并列的子目标,每个子目标又可以通过执行一系列更详细的动作(抽象动作/动作组)来达成。
比如在资源的调度分配问题中,资源的调度分配策略随着环境的观测值(若干待分配资源的个体,资源配置策略不同,获得的收益不同),希望通过调整资源配置策略,获得最大的全局收益。
这时动作包含以下几部分(几个层次)
(1)给哪些个体配置资源(直接给全部个体配置资源的收益不一定高于只给部分个体配置)
(2)给每个个体配置多少资源
(3)具体给每个个体配置哪些资源(资源之间也有差异,同一资源配置给不同个体收益不同)
又比如如图所示的泡茶问题, 可以分成几个步骤,每个步骤都需要控制手脚去做对应的事情。而人类是很擅长自主地去把一个任务分成不同层级的,而且是在学习过程中可以自发地去理解、发现任务的动作层级。
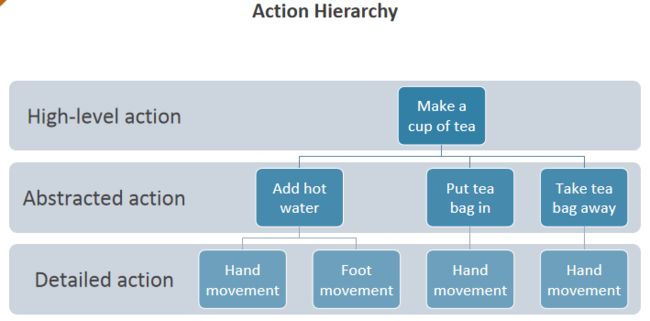
思考:既然人类这么擅长自主地把任务按照子目标分层级,那AI如何达到类似的学习能力呢?
不妨来看看人脑有什么特点:
●神经科学家在大脑皮层区域发现了一个时间尺度的上升层次,被认为是处理更高级的认知功能的区域对应更慢的时间尺度。[Ref 3]
●此外,大脑皮层的神经元具有高度随机的神经活动。
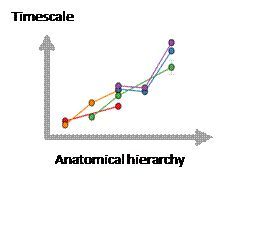
基于以上三点,我们将使用一个具有随机性的、多时间尺度的循环神经网络(RNN)作为我们的模型。
2、ReMASTER框架(Recurrent Multi-level Actor-critic with STochastic Experience Replay)
其中RNN模型称为Multiple Timescales Stochastic RNN (MTSRNN),由两层组成:
① 低层:慢时间尺度(hidden state随时间变化慢),输出相对短期的价值函数,低层接收观测量,输出策略。
② 高层:快时间尺度(hidden state随时间变化快),输出相对长期的价值函数,高层和低层相连。
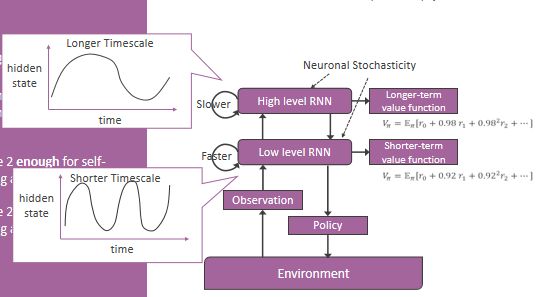
两个关键要素:
① 内禀的时间尺度层次性:体现在RNN的hidden state的变化速率上和价值函数的估计上面。
② 在RNN的hidden state更新中的noise:随机性。
大致算法流程如下:

3、顺序目标达成任务(Sequential target-reaching Task)
此任务中,一个两轮机器小车agent需要依次到达红-绿-蓝3个目标点,从而获得奖励。难点没有外部信号指示当前目标给agent,而是需要agent通过行动历史去判断当前目标。这可以认为是一个现实世界中更复杂的序列任务的抽象,包括将整个任务分解成子任务和以特定的顺序执行每个子任务。
两个行动层次:
① 学会通过传感器的输入来控制双轮到达特定目标(较低层次)。
② 学会利用历史观察的记忆来识别要达到的目标(子目标)(更高层次)。
观测量是到每个目标的距离和角度等传感器数据。

4、实验结果
在使用ReMASTER进行足量训练后,agent可以成功地学会完成顺序目标达成任务。但是agent是否理解了这个任务中的动作层级呢?我们来看看下面的结果
① Agent行为分析
下面的三列图展示了同一个agent在不同的三次任务中的行为:
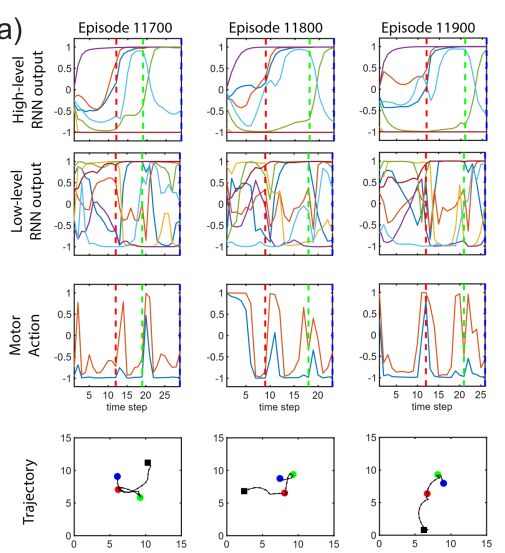
第一行和第二行显示高层和低层的RNN output,其中垂直虚线表示agent到达目标。为了清晰起见,我们只绘制了每层的前7个神经元,不同的颜色表示不同的神经元。X轴是时间,y轴是RNN output(可以理解为神经元激活程度)。
第三行是轮子的动作,即两个车轮的速度。
第四行是机器人的行动轨迹,其中黑色方块表示其起始位置,彩色圆点是3个目标位置,可以看到agent在目标位置都不一样的情况下都能很好地完成任务。
我们可以看到,在这三次任务中,高层的RNN output显示出了相似的行为,即使在这三次任务中轮子的动作完全不一样。这个结果一定程度上表明了高层的RNN可以表示高层的子目标,而这是在强化学习后自组织起来的。
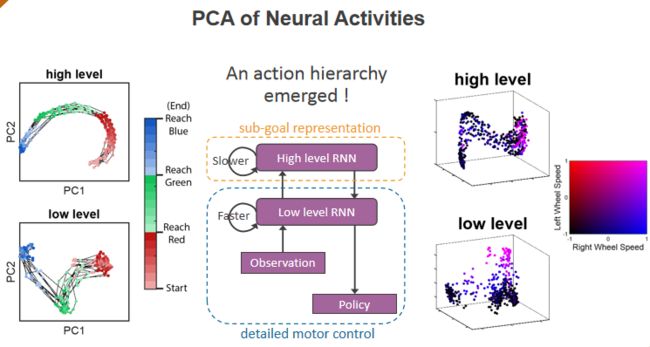
② PCA主成分分析
我们可以用更具有统计学可信度的证据来展示agent在强化学习中发展起来的动作层级。通过PCA主成分分析高层和低层的hidden state,可以明显的观测到agent的行动分层。
High level:表现出序列化一致性,对应于子目标;
Low level:对应具体的动作控制。
③ 连续再学习任务
在这个任务中,agent需要再学习适应改变了的目标顺序,连续的再学习任务由3个不同的阶段组成。
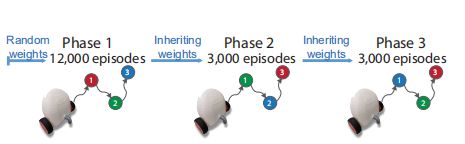
●第1阶段对应于原来的 红-绿-蓝 顺序目标达成任务。
●第2阶段将子目标重新排序,agent需要按 绿-蓝-红 的新顺序来完成。
●第3阶段又变了顺序,变成 蓝-绿-红。
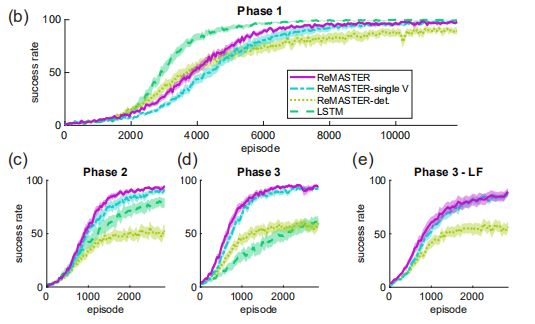
注:ReMASTER-single V 是高层RNN不输出较长期价值函数的ReMASTER;ReMASTER-det. 是RNN中没有随机噪声的ReMASTER;LSTM是用单层LSTM来替换双层RNN的ReMASTER。
由于我们先前的分析表明,底层的RNN已经学习了如何去完成各个子目标。那么,让agent再去学习第2,3阶段的任务,应该会更为快速。因为agent不需要再重新学习底层的控制,而只需要将高层的子目标重组(re-composition)。实验结果也表明,相对于其他的baselines,ReMASTER在再学习的阶段(上图中c和d)能做得更快更好。
另外一个有趣的结果是,我们可以让agent在第2阶段后将底层RNN的权重都冻结,只让高层RNN再学习。如上图e所示,agent依然可以在第3阶段较快地适应新的目标顺序。
④ 显式地去运用已经学会的子目标
我们看到用ReMASTER的agent可以学习完成顺序目标达成任务,而且在RNN中自主地形成了动作层级——高层RNN可以表示子目标。如果我们希望它仅完成一个子目标,例如达到蓝色目标,该怎么办?
其实这很容易做到!我们只要固定高层RNN的hidden state(比如固定到agent在RL时前往蓝色目标过程中高层RNN的hidden state),而让低层的RNN照常运算,就可以了!下图展示了一个学习好了的agent在固定了高层hidden state后的运动轨迹。每行的图中使用了同样的高层hidden state,而每列的图中目标位置保持一致。黑色方块依然是agent的初始位置,而彩色圆点对应了目标位置。
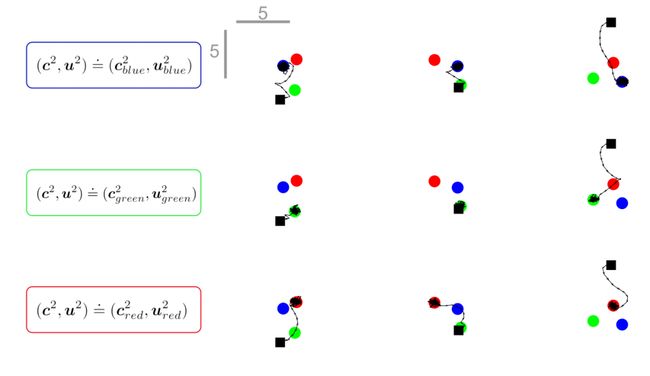
5、总结
①在此研究中,我们仔细研究了在“顺序目标达成任务”中,如何通过端对端的强化学习和RNN来自主发展出一个可解释的动作层级。
②我们提出了ReMASTER算法框架,它具有两个受神经生物学启发的特征。一个是RNN里内禀的时间尺度层级,另一个是网络中的随机性。
③实验结果表明,ReMASTER的agent在强化学习后可以成功解决顺序目标达成任务,并且一个可解释的动作层级在双层网络中自发组织起来。此动作层级可以帮助agent在再学习由已掌握子目标重新排序组成的新任务时学得更快。
作者寄语
●神经网络本身就是很神奇的东西,Hierarchical RL其实也不一定需要精心设计的算法,而靠RNN里内禀的时间尺度层级和随机性(噪声)就能做到。
●机器学习的路走了这么远,我们有时候可以回过头来看一下神经科学/脑科学的研究能给我们一些什么启发。毕竟只人类来说,在地球这么复杂多变的环境下,是数以亿计的人口经过数万代的进化得到的结果,必然有其优越性。如果要模拟这么大规模的演化计算的话,现在计算机能达到的算力还差得远。
参考文献
[Ref 1] Recurrent neural network, Wikipedia, https://en.wikipedia.org/wiki/Recurrent_neural_network
[Ref 2] Wang J X, Kurth-Nelson Z, Tirumala D, et al. Learning to reinforcement learn[J]. arXiv preprint arXiv:1611.05763, 2016.
[Ref 3] Murray J D, Bernacchia A, Freedman D J, et al. A hierarchy of intrinsic timescales across primate cortex[J]. Nature neuroscience, 2014, 17(12): 1661-1663.
e m t
往期精彩
AI i

整理:唐家欣
审稿:韩东起
排版:岳白雪
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(直播回放:https://b23.tv/9xQMXZ)
(点击“阅读原文”下载本次报告ppt)