在近期的GDG开发者大会广州站上,个推高级技术总监董霖以“异构数据的SQL一站式解决方案”为主题,深入分享了个推在SQL领域多年的实战经验。本文将从三方面阐述统一SQL:
一、为什么要统一SQL
二、如何统一SQL
三、个推统一SQL实践
(以下根据演讲内容整理)
01
为什么要统一SQL
数据作业是多兵种合作的战场
公司内部围绕数据开展的工作,需要数据分析师、数据研发工程师、运维工程师、甚至产品运营人员共同完成,沟通和协作的效率成为关键性因素。
数据存储引擎眼花缭乱
随着大数据行业的发展,数据存储引擎目前处于百花齐放的阶段,新兴技术层出不穷:如关系型数据库,包括MySQL、Oracle、SQL Server以及蚂蚁推出的OceanBase等;NoSQL方案,包括Redis、Aerospike、MongoDB等;基于Hadoop体系的方案,包括Hive、HBase等;以及目前比较火热的NewSQL方向,包括Greenplum、TiDB、Doris、ClickHouse等。
各式各样的存储引擎让不少参与数据作业的人感到茫然,不知道该选择什么样的方式。开发者要花非常多的成本不停地尝试各种方案,以应对市场需求。开发者需要准确了解数据存在哪里、字段格式怎样、数据表间的关系怎样、数据如何操作等信息,技术人员和业务人员还需要花很多时间掌握各种存储引擎的性能和特性。
多样的数据存储方案
引擎选择类型多、学习成本高
除了存储引擎,计算引擎的选择也给大家带来困扰。Spark和Flink各有千秋,也各自在快速发展和相互学习融合。另外机器学习引擎也有很多方案,比如Tensorflow、PyTorch以及计算引擎中携带的机器学习算法库,但这些方案的学习成本比较高,常常令开发者感到纠结,难以抉择。
工作语言不统一
存储引擎和计算引擎具有繁多的方案,会给协同工作带来较大的语言障碍。对于分析师来说,日常大量使用的主要是SQL,但是有些时候也会使用Python、Shell脚本等方式完成数据处理。数据建模人员主要依赖Python,而数据研发人员则主要使用Java和Scala来开发实时任务。产品运营人员甚至会使用Excel来完成一些简单的分析任务。当然,大多数时候他们还是将需求表达给数据分析师,由分析师来协助完成。
语言障碍也在一定程度上限制了协作的效率,在资源调配上也缺乏灵活性。比如基于Spark或Flink的实时任务目前只能由数据研发同学完成,这很容易造成工作积压。
“统一SQL”天时地利人和
如果我们仔细思考,其实会发现数据处理本质上是数仓的加工处理,而各类数据作业都可抽象为数仓的ETL过程,即数据的提取(extract)、转换(transform)和加载(load)。目前来看,SQL是描述数据处理流程最优的DSL(Domain Specific Language),是事实标准。
在目前大环境下推行统一SQL的解决方案是大势所趋,具备天时地利人和的基本条件:
• 天时:数据体量增长,计算、人力、沟通成本增加,为企业不能承受之重;
• 地利:主流关系型数据库、MPP数据库、计算引擎、ES、甚至NoSQL方案已经或者计划支持SQL语法;
• 人和:SQL语言易于上手,核心功能只有9个动词;分析师、建模师、数据研发甚至产品运营等非技术人员都可以快速掌握SQL这门语言。
我们认为可以通过统一SQL的方式去完成二八原则的转换,即从目前把80%的时间花在20%的常规数据作业上 ,转变成用20%的时间就可以完成80%的常规数据作业。这样我们就可以有更多的时间去解决更复杂的工作,去思考数据的价值。
02
如何统一SQL
要想实现SQL的统一,我们认为需满足四大核心需求:元数据打通、跨数据源、支持离线和实时计算、支持机器学习。
先以一个典型的离线计算场景为例,我们希望通过简单的SQL即可达成目标,即用Hive数据与MySQL数据相融合,然后回写到HBase。
`
update hbase.biz.user_balances as a
set a.balance = ret.balance
from
(
select b.uid, c.balance
from hive.warehouse.users as b
inner join mysql.biz.balances as c
on b.uid = c.uid
) as retwhere a.uid = ret.uid`
类似的,如果是一个典型的实时计算场景,我们也希望能通过一个简单的SQL来完成Kafka数据流与MySQL的融合再回写到Redis这样的需求,例如:
`
update redis.dashboard.brands as a
set a.cnt = ret.cnt
from
(
select c.brand, count(distinct b.uid) as cnt
from kafka.app.visit_logs as b
inner join mysql.warehouse.users as c
on b.uid = c.uid
group by c.brand
) as retwhere a.brand = ret.brand`
为寻找到合适的解决方案,我们首先调研了独立的开源方案。我们关注到奇虎360开源的Quicksql,这个方案大体上是先将SQL解析成AST(抽象语法树),然后将执行计划下推到具体的执行引擎。QuickSQL支持比较多的数据源,包括Hive、MySQL、ES、MongoDB等,遗憾的是这一方案不支持实时任务,是针对离线场景的解决方案。
该方案的Apache Calcite极具借鉴意义。Apache Calcite是一个基于SQL的动态数据管理框架,首先它把SQL的语法解析成AST,进行语法校验,接着基于RBO和CBO的查询进行优化,最后通过JDBC等引擎连接外部数据源。此外,Calcite支持元数据对接,开发者可以通过Calcite提供的框架,输入表名、行数、分布、排序等优化所需的元数据信息。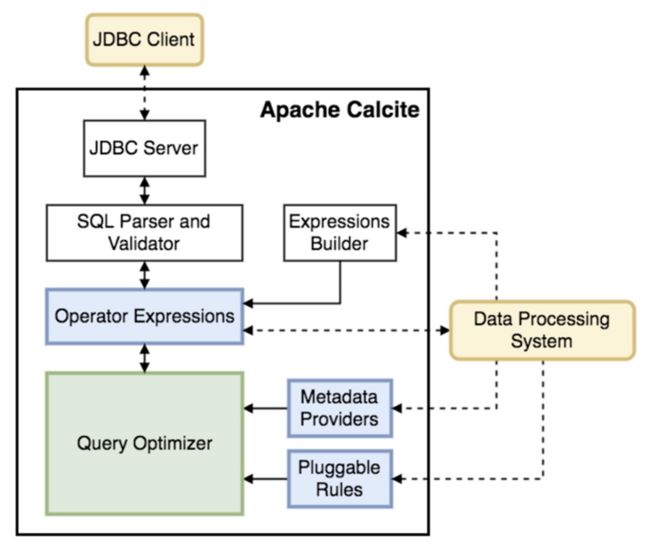
接下来,我们调研了目前主流的实时计算引擎,想看其是否可以提供比较完备的SQL支持。首先评估的是Spark SQL。它通过antlr解析器把SQL语法解析成AST,接着进行查询优化,最后把指令拆解成RDD任务。
这个方案可以支持离线和实时,但是在公司内部使用会遇到几个问题:一个是如果要扩展支持更多的数据,需要修改Spark SQL的Connector部分,这需要修改Spark环境,对于一个大规模的Spark集群来说,更新升级底层环境会带来比较大的风险;另外底层环境的更新对于私有化部署的场景也是比较难以接受的。
此外需要通过USING这样的个性化DDL语法去连接外部数据源,这一定程度破坏了SQL的标准性。但综合而言,Spark SQL确实为我们提供了非常好的解决方案和思路。
然后,我们评估的是Flink SQL。它是阿里为Flink提供的非常有价值的组件,整体流程跟Spark的方案十分类似,通过Calcite解析SQL语法,进行查询优化后下推执行计划,同时也支持非常多的数据源。相对来说Flink SQL比Spark SQL支持性更好,但是也仍然存在和Spark SQL类似的问题,包括元数据打通、底层引擎迁移成本、采用自定义的WITH关键字来声明数据源的访问等。
由于这些DDL语法不是标准的SQL语法,一方面会带来一些学习的成本,另外一方面会带来兼容性问题,导致同样的SQL无法同时运行于Spark和Flink平台。
最后,我们还调研了机器学习的SQL支持方式。我们寻找到一个叫MLSQL的开源方案,它通过类似于train、predict这样的关键词就可以快速完成模型训练和预测的工作,也支持跨数据源查询。但MLSQL更侧重于从前到后完整的流程整合,在大规模数据体量下暂时还缺乏成熟的应用案例,对于我们的使用场景还需要进行不少的定制化开发。不过总体而言,它的语法扩展方式对我们有极强的借鉴意义。
`
load json./tmp/train as trainData;
train trainData as RandomForest./tmp/rf where keepVersion="true" and fitParam.0.featuresCol="content" and fitParam.0.labelCol="label" and fitParam.0.maxDepth="4" and fitParam.0.checkpointInterval="100" and fitParam.0.numTrees="4" ;
predict testData as RandomForest./tmp/rf;`
*来源:MLSQL官方文档
根据上述调研我们进行了总结整理,希望统一SQL的技术架构是这样的:
1、兼容两种计算引擎(Spark/Flink),不对计算引擎进行修改;
2、可灵活扩展数据源;
3、对SQL优化过程自主可控,逻辑上与引擎解耦,物理上可以与引擎绑定;
4、扩展支持机器学习语法。
03
个推统一SQL实践
为了方便不同的角色、不同岗位的人员参与到数据治理工作中,个推开发了一套数据中台系统,在公司内部叫作每日治数平台。每日治数平台由数据仓库、模型平台、数据资产治理平台、数据集成平台、数据开发平台五个模块组成,帮助企业解决数据治理痛点、降低数据使用门槛、提升数据运用价值。
通过数据资产治理平台,我们可以录入数据资产、管理数据间的血缘关系以及对数据质量进行监控。通过数据集成平台,我们可以与数据源进行对接,完成数据的结构化工作。通过数据开发平台,我们可以完成数仓的建设和维护工作。其中统一SQL引擎——GQL便是个推数据开发平台的基础。
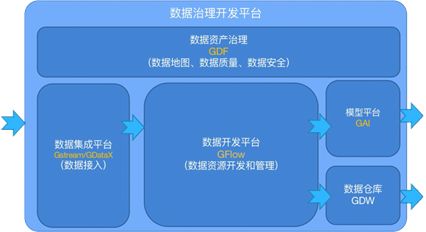
GQL的结构跟前文提及的Spark SQL、Flink SQL非常像,都是通过解析层把SQL拆解成语法树结构,然后结合数据的元信息完成查询优化的工作,最后再把这些执行任务派发给相应的计算引擎或者存储引擎。
在元数据方面,我们将数据治理平台的信息与SQL解析层对接,消除DDL的差异,无需再通过WITH、USING这样的关键字定义临时表的形式声明要访问的数据,提高了SQL的标准性。
在开发环境方面,我们基于Database Navigator插件拓展了GQL的支持。开发者可以在IntelliJ IDEA上编写和调试GQL,并直接查看查询结果。
在数据源方面,我们目前支持五大类的数据源,包括JDBC/ODBC接口、文件系统、Hadoop体系、KV型数据以及kafka。未来,我们希望 API的数据接口也可以通过GQL的方式进行接入。
在机器学习方面,GQL主要做了两块功能支持。在特征工程方面,包括异常值、缺失值的处理,特征组合、特征自动化筛选等相对机械的工作,都可以通过GQL来完成。在模型方面,GQL支持常用的有监督学习模型(如逻辑回归、随机森林、XGBoost等)以及无监督聚类模型。
SQL作为一种DSL,语法虽然简单,但并不通用。有些任务不适合用SQL来描述和完成,如迭代和加解密算法等,这就需要通过UDF(User Define Function)扩展,让SQL代码具有更丰富的能力。GQL对UDF也做了扩展支持,可以通过Java、Python等方式增加UDF。
04
总结
我们认为SQL是目前最适合人与数据打交道的语言,没有之一。元数据打通、跨数据源、离线和实时支持、机器学习支持是统一SQL所需的四大核心功能。Flink SQL基本能满足我们的需求,如果底层计算引擎就是Flink,毫无疑问,使用它可以解决绝大部分的问题。但是如果希望保持更大的灵活性以及扩展性,那么有必要考虑将SQL作为独立的一层技术栈进行发展。结合个推自身实践,以GQL作为每日治数平台的统一SQL引擎,我们分享了所采用的技术方案以及实现的功能,希望能给大家有所启发。
