Scrapy框架爬取豆瓣高分电影爬虫
豆瓣Scrapy高分电影爬虫-仅供学习使用
今天要分享的是scrapy框架爬虫,目标网站是豆瓣的高分电影。
我们先来简单介绍下scrapy的流程。
Scrapy爬虫框架的流程图如下:
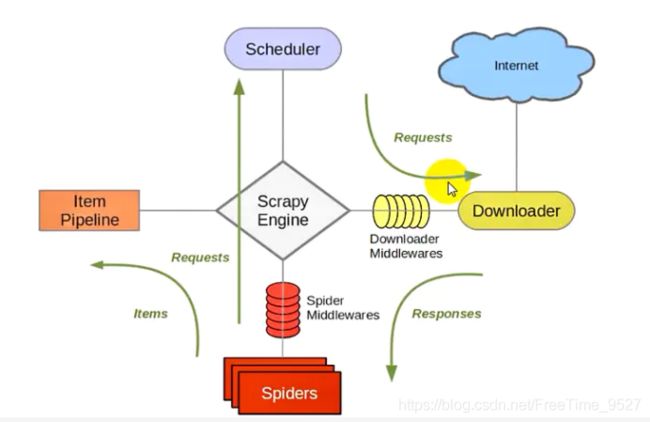
1、Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,传递信号、数据等。
Scheduler(调度器): 负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
2、Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
3、Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler。
4、Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):自定义扩展引擎和下载中间的组件。
5、Spider Middlewares(爬虫中间件):自定义扩展、操作引擎和爬虫中间通信的功能组件。
想更加深入了解scrapy的同学,请移步官网。
接下来,我们就开始进入爬虫了。
老规矩,我们先到豆瓣高分电影的页面进行抓包,分析页面。
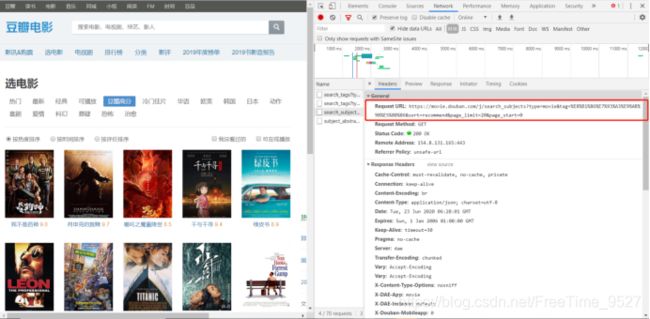
1、分析页面,找到存储数据的网页:

2、找到了存放数据的链接,我们就要分析这个链接的构成:
3、接着继续分析:
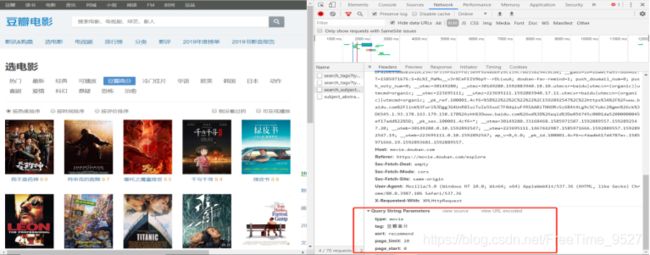
找到这里,根据我们的爬虫经验,这里的表单数据就是控制爬虫的页数的。
4.到了这里我们已经能拿到列表页的数据了,但是我们的目标是进入到详情页里面,提取详情页的数据。
我们继续分析网页:
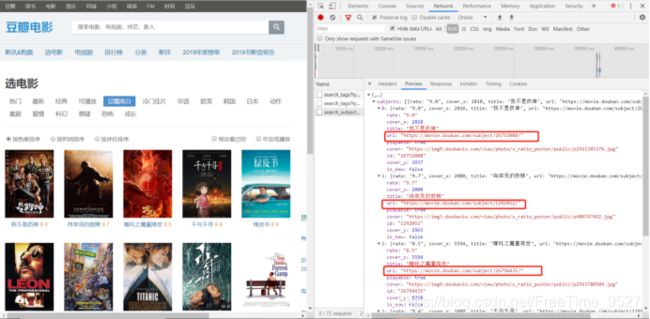
可以看到,图中的url就是进入到详情页的链接,我们只要获取到这个链接,然后再请求这个链接就能进入到详情页里面了。
5、进入详情页,分析页面构成:

6.我们可以看到我们想要的各种数据,这个就好办了,接下来我们只需要利用xpath、re进行数据提取就可以了。最后我们把提取到的数据保存在csv文件中。
爬虫页面分析到此就结束啦。接下来的时间交给代码。
db.py文件:
# -*- coding: utf-8 -*-
#author:渔戈
import scrapy
import json
import time
from scrapy import cmdline
import re
from douban.items import DoubanItem
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/']
#重写request方法
def start_requests(self):
for pn in range(0, 500, 20):
#构建表单参数
formdata = {
"type": 'movie',
"tag": "豆瓣高分",
"sort": "recommend",
"page_limit": "20",
"page_start": str(pn),
}
url = 'https://movie.douban.com/j/search_subjects'
time.sleep(2)
yield scrapy.FormRequest(url=url,formdata=formdata,callback=self.parse)
''' 获取详情页链接 '''
def parse(self, response):
contents = json.loads(response.text)['subjects']
for content in contents:
url = content['url']#获取详情页链接
# time.sleep(1)
yield scrapy.Request(url=url,callback=self.get_datas)
''' 获取数据 '''
def get_datas(self,response):
try:
# 电影名称
name = response.xpath('//div[@id="content"]/h1/span[1]/text()').get()
# 电影链接
detail_url = response.url
# 导演
director = response.xpath('//div[@id="info"]/span[1]/span[@class="attrs"]/a/text()').extract_first()
# 编剧
scriptwriter = '/'.join(response.xpath('//div[@id="info"]/span[2]/span[@class="attrs"]//a/text()').getall())
# 电影评分
movie_rating = response.xpath('//strong[@class="ll rating_num"]/text()').extract_first()
if movie_rating == None:
movie_rating = 'None'
# 主演
protagonist = '/'.join(response.xpath('//span[@class="actor"]//span[@class="attrs"]//a/text()').extract())
# 电影类型
movie_type = response.xpath(
"//div[@class='subject clearfix']/div[@id='info']/span[@property='v:genre']/text()").extract()
movie_type = '/'.join(movie_type)
# 制片地区
pro_areas = r'制片国家/地区: (.*?)
'
pro_area = re.findall(pro_areas, response.text)[0]
# 上映日期
pattern = r'.*?.*?(.*?)'
movie_pubdate = re.findall(pattern, response.text)[0]
if not movie_pubdate:
movie_pubdate = 'None'
# 片长
lengths = r'片长: (.*?).*?
'
length = re.findall(lengths, response.text)[0]
# IMBD链接
IMBD_links = r'IMDb链接: (.*?)
'
IMBD_link = re.findall(IMBD_links, response.text)[0]
IMBD_link = 'https://www.imdb.com/title/' + IMBD_link + '/'
# 电影简介
movie_summary = ''.join(response.xpath('//div[@id="link-report"]/span//text()').getall()).strip('©豆瓣').replace(
'\n', '')
wording = response.xpath('//div[@id="link-report"]/span/a/text()').get()
if wording == '(展开全部)':
movie_summary = ''.join(response.xpath('//span[@class="all hidden"]//text()').getall()).strip(
'©豆瓣').replace('\n', '')
#打印信息
print(name,detail_url,director,scriptwriter,movie_rating,protagonist,movie_type,pro_area,
movie_pubdate,length,IMBD_link,movie_summary)
item = DoubanItem(name=name,detail_url=detail_url,director=director,scriptwriter=scriptwriter,movie_rating=movie_rating,
protagonist=protagonist,movie_type=movie_type,pro_area=pro_area,movie_pubdate=movie_pubdate,
length=length,IMBD_link=IMBD_link,movie_summary=movie_summary)
yield item
except Exception as e:
print(e)
if __name__ == '__main__':
cmdline.execute('scrapy crawl db'.split())
items.py文件:
import scrapy
#author:渔戈
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
detail_url = scrapy.Field()
director = scrapy.Field()
scriptwriter = scrapy.Field()
movie_rating = scrapy.Field()
protagonist = scrapy.Field()
movie_type = scrapy.Field()
pro_area = scrapy.Field()
movie_pubdate = scrapy.Field()
length = scrapy.Field()
IMBD_link = scrapy.Field()
movie_summary = scrapy.Field()
pipelines.py文件:
import csv
#author:渔戈
class DoubanPipeline(object):
def __init__(self):
self.fp = open('豆瓣高分.csv','a',encoding='utf-8-sig',newline='')
self.writer = csv.writer(self.fp)
self.header = ['电影名称','电影链接','导演','编剧','电影评分','主演','电影类型','制片地区','上映日期','片长','IMBD链接','电影简介']
self.writer.writerow(self.header)
def open_spiser(self,spider):
print('豆瓣高分爬虫项目启动:')
def process_item(self, item, spider):
self.writer.writerow(dict(item).values())#写入数据
return item
def close_spider(self,spider):
self.fp.close()
print('豆瓣高分爬虫项目结束')
settings.py文件:
BOT_NAME = 'douban'
LOG_LEVEL = "WARNING"
SPIDER_MODULES = ['douban.spiders']
NEWSPIDER_MODULE = 'douban.spiders'
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
以上,便是scrapy豆瓣高分电影爬虫的全部代码了。
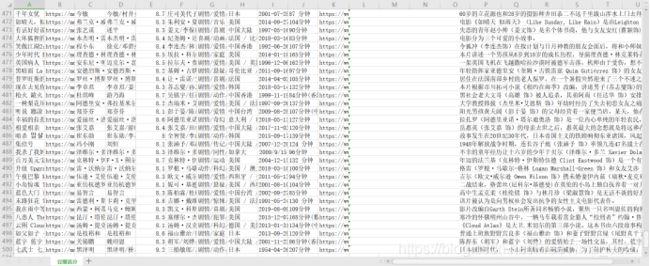
我们一共获得了 499 条豆瓣高分电影的数据,下面截图展示出部分数据

感谢各位大佬赏脸观看!鞠躬.jpg