《英文取名》未来五年名字使用人数预测 --- Python实现ARIMA模型
一、ARIMA知识介绍
时间序列提供了预测未来价值的机会。 基于以前的价值观,可以使用时间序列来预测经济,天气和能力规划的趋势,其中仅举几例。 时间序列数据的具体属性意味着通常需要专门的统计方法。
我们将首先介绍和讨论自相关,平稳性和季节性的概念,并继续应用最常用的时间序列预测方法之一,称为ARIMA。
用于建模和预测时间序列未来点的Python中的一种方法被称为SARIMAX ,其代表具有eXogenous回归的季节性自动反馈集成移动平均值 。 在这里,我们将主要关注ARIMA组件,该组件用于适应时间序列数据,以更好地了解和预测时间序列中的未来点。
时间序列预测——ARIMA(差分自回归移动平均模型):
ARIMA(p,d,q)中,AR是"自回归",p为自回归项数;I为差分,d为使之成为平稳序列所做的差分次数(阶数);MA为"滑动平均",q为滑动平均项数,。ACF自相关系数能决定q的取值,PACF偏自相关系数能够决定q的取值。ARIMA原理:将非平稳时间序列转化为平稳时间序列然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。
①自回归模型(AR)
- 描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测。
- 自回归模型必须满足平稳性的要求。
- 必须具有自相关性,自相关系数小于0.5则不适用。
- p阶自回归过程的公式定义:
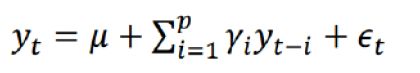

PACF,偏自相关函数(决定p值),剔除了中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的干扰之后x(t-k)对x(t)影响的相关程度。
②移动平均模型(MA)
- 移动平均模型关注的是自回归模型中的误差项的累加,移动平均法能有效地消除预测中的随机波动。
- q阶自回归过程的公式定义:

ACF,自相关函数(决定q值)反映了同一序列在不同时序的取值之间的相关性。x(t)同时还会受到中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的影响而这k-1个随机变量又都和x(t-k)具有相关关系,所 以自相关系数p(k)里实际掺杂了其他变量对x(t)与x(t-k)的影响。
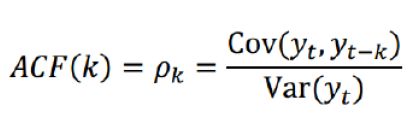
ARIMA(p,d,q)阶数确定:
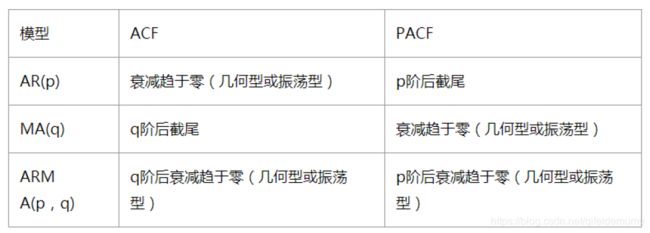
(图示: ACF和PACF图)
③平稳性要求
平稳性就是要求经由样本时间序列所得到的拟合曲线在未来的一段期间内仍能顺着现有的形态“惯性”地延续下去,平稳性要求序列的均值和方差不发生明显变化。
具体分为严平稳与弱平稳:
严平稳:严平稳表示的分布不随时间的改变而改变,期望和相关系数保持不变。
如:白噪声(正态),无论怎么取,都是期望为0,方差为1
弱平稳:期望与相关系数(依赖性)不变
未来某时刻的t的值Xt就要依赖于它的过去信息,所以需要依赖性
因为实际生活中我们拿到的数据基本都是弱平稳数据,为了保证ARIMA模型的要求,我们需要对数据进行差分,以求数据变的平稳。
④模型评估:
AIC:赤池信息准则(AkaikeInformation Criterion,AIC)
![]()
BIC:贝叶斯信息准则(Bayesian Information Criterion,BIC)
![]()
⑤模型残差检验
- ARIMA模型的残差是否是平均值为0且方差为常数的正态分布
- QQ图:线性即正态分布
二、ARIMA预测实践步骤
①所用的所有Python数据包
python版本为3.7,pandas,numpy,statsmodels.api,matplotlib,warnings,itertools,几个实现统计功能的常用python包。
# 编码 UTF-8 #
'''''=================================================
@Project -> File :英文取名(ARIMA模型预测) -> MY_ARIMA
@IDE :PyCharm
@Author :吴泽胜
@Date :2020/5/23 20:32
=================================================='''
import warnings
import itertools
import os
import gc
# 使用 matplotlib 的 scatter 方法绘制散点图
import matplotlib.pyplot as plt
# Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
import pandas as pd
# 提供高性能的矩阵运算
import numpy as np
# 自相关函数的库 ACF 和 PACF
import statsmodels.api as sm
# matplotlib绘图
import matplotlib
import matplotlib.dates as mdate
from pylab import rcParams
from statsmodels.graphics.gofplots import qqplot
from statsmodels.tsa.arima_model import ARIMA
from sklearn.metrics import mean_squared_error
②数据准备与预处理
# 创建导入数据对象
df = pd.read_csv("../Data/Babyname-1880-2018.csv") # 相对路径Babyname-1880-2018
# 数据年份
Year_Number = []
# 预测年份
Forecast_Year_Number = ['2019', '2020', '2021', '2022', '2023', '2024']
# 年份人数排序
# 男 Male Rank
Rank_Array_M = []
# 女 Female Rank
Rank_Array_F = []
# 过滤每年的男女人数
df_M = df[df["Gender"] != 'F']
df_F = df[df["Gender"] != 'M']
# 写入 1979-2018年 四十年
for item in range(1880, 2019):
Year_Number.append(str(item))
# 写入排序 M
for item in Year_Number:
my_df = df_M[item].rank(ascending=0, method='first')
Rank_Array_M.append(my_df)
# 写入排序 F
for item in Year_Number:
my_df = df_F[item].rank(ascending=0, method='first')
Rank_Array_F.append(my_df)
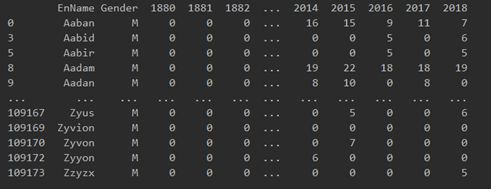
1.导入英文名学习包Babyname-1880-2018.csv:

2.通过“Gender”过滤每年男女的男女人数:
女性:

男性:
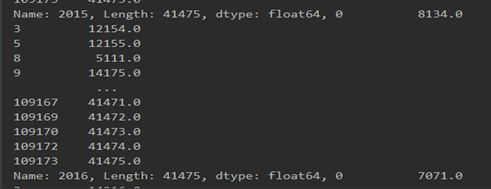
3.通过Rank函数,将男性,女性每年人数进行排序:
女性:

男性:
③数据重采样
# 遍历每一条数据
for row_index, row in df.iterrows():
# 异常处理
try:
# 打印运行位置
Process_Information(row_index)
# 记录性别
Gender = row[1:2][0]
# 选择性别排名 三元运算
Rank_Array = Rank_Array_M if Gender == 'M' else Rank_Array_F
# 将DataFrame数据转为list
train_data = np.array(row).tolist()
# 传值 单条1880-2018年所有数据
train_data_all = train_data
train_data_all = pd.Series(train_data_all[2:])
# 将list数据转为Series 取1979年
train_data = pd.Series(train_data[101:])
# ARIMA学习所用的数据是单精度型数据
train_data = train_data.astype('float32')
# x轴年份 1880-2018
train_data.index = pd.Index(sm.tsa.datetools.dates_from_range(start='1979', end='2018', length=0))
# 设置面板大小
train_data.plot(figsize=(16, 6))
# 改变图标题字体,标题设置
plt.title(str(row[0:1]), fontdict={'weight': 'normal', 'size': 20})
# 对于测试ARIMA方法调用
Forecast_Array_Number = MY_ARIMA(train_data)
# 打印预测 2019年 - 2024年 的预测值
print(Forecast_Array_Number)
# 将处理好的数据,写入设计好的文档(txt)
Write_Data(train_data_all, Forecast_Array_Number, str(row[0:1][0]), Rank_Array, row_index, Gender)
except:
# 打印错误的名字
print("%s 运行错误:" % str(row[0:1][0]))
# 错误信息写入 将处理好的数据,写入设计好的文档(txt)
Error_Write_Data(train_data_all, Forecast_Array_Number, str(row[0:1][0]), Rank_Array, row_index, Gender)
pass
# 释放内存
gc.collect()
continue
1.过滤每一条数据,从1979 – 2018 年作为机器学习数据
④将原始数据可视化
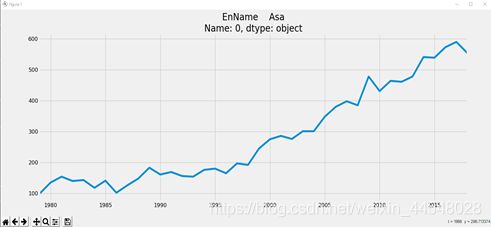
⑤查看一阶差分图
def MY_ARIMA(train_data):
# 拆分法,检验序数据的稳定性
# 一阶差分图 t 与 t-1 时刻的差值
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(111)
# .diff(1) 差分间隔为1个单位 例如 2001年 - 2000年 的数据
diff1 = train_data.diff(1)
diff1.plot(ax=ax1)
将序列平稳(差分法确定d)。

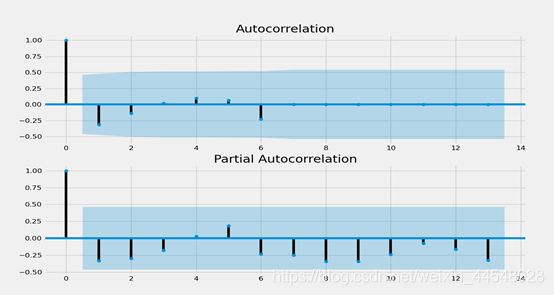
⑥p和q阶数确定:ACF与PACF
# 做acf和pacf图 自相关函数acf的Pk的取值范围[-1,1] 偏自相关函数pacf
dta1 = train_data.diff(1)
# 差分的数据记得使用dropna方法去掉空值,否则acf和pacf图很可能出不来
dta2 = dta1.dropna()
# 显示 acf 和 pacf 图
fig = plt.figure(figsize=(12, 8))
# 此处为20 acf图,lags为滞后阶数
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(dta2, ax=ax1)
# pacf 图片
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(dta2, ax=ax2)
plt.show()
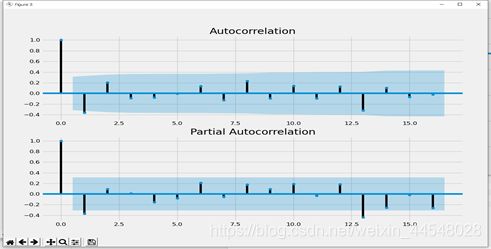
(图示:ACF图 和 PACF图)
⑦ARIMA(p,d,q)/SARIMA(p,d,q,s)呈现季节性用这个模型
# 寻找最优解pdq组合搭配
# evaluate combinations of p, d and q values for an ARIMA model
def evaluate_models(dataset, p_values, d_values, q_values):
dataset = dataset.astype('float32')
best_score, best_cfg = float("inf"), None
for p in p_values:
for d in d_values:
for q in q_values:
order = (p, d, q)
try:
mse = evaluate_arima_model(dataset, order)
if mse < best_score:
best_score, best_cfg = mse, order
print('ARIMA%s MSE=%.3f' % (order, mse))
except:
continue
print('Best ARIMA%s MSE=%.3f' % (best_cfg, best_score))
# 返回最优解 p,d,q
return best_cfg
# evaluate an ARIMA model for a given order (p,d,q)
def evaluate_arima_model(X, arima_order):
# prepare training dataset
train_size = int(len(X) * 0.66)
train, test = X[0:train_size], X[train_size:]
history = [x for x in train]
# make predictions
predictions = list()
for t in range(len(test)):
model = ARIMA(history, order=arima_order)
model_fit = model.fit(disp=0)
yhat = model_fit.forecast()[0]
predictions.append(yhat)
history.append(test[t])
# calculate out of sample error
error = mean_squared_error(test, predictions)
return error
def MY_ARIMA(train_data):
# 暴力测试pdq的最佳搭配值,此方法不是最优解,但是也是一种办法。
# evaluate parameters
p_values = d_values = q_values = range(0, 2)
# 忽略警告
warnings.filterwarnings("ignore")
# 调用 evaluate_models 方法,获取最优p,d,q值
# 均方根
best_cfg = evaluate_models(train_data.values, p_values, d_values, q_values)
# 预测模型
arma_mod20 = sm.tsa.statespace.SARIMAX(train_data,
order=(best_cfg[0], best_cfg[1], best_cfg[2]),
seasonal_order=(1, 1, 0, 12),
enforce_stationarity=False,
enforce_invertibility=False
).fit()
arma_mod20.plot_diagnostics(figsize=(16, 8))
print(arma_mod20.summary().tables[1])
print(arma_mod20.aic, arma_mod20.bic, arma_mod20.hqic)
1.通过取MSE的最小值,确定pdq的最佳搭配
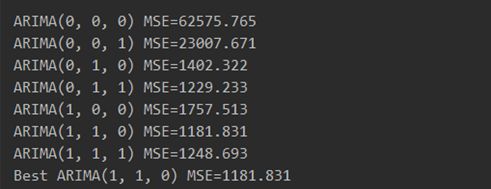
2. 详细输出,arma_mod20.summary()可以输出全部的模型计算参数表
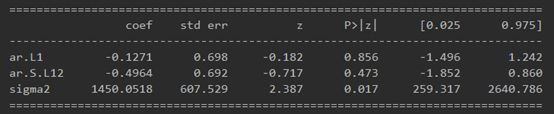
由SARIMAX的输出产生的SARIMAX返回大量的信息,但是我们将注意力集中在系数表上。 coef列显示每个特征的重量(即重要性)以及每个特征如何影响时间序列。 P>|z| 列通知我们每个特征重量的意义。 这里,每个重量的p值都低于或接近0.05 ,所以在我们的模型中保留所有权重是合理的。
⑧模型诊断
在 fit 季节性ARIMA模型(以及任何其他模型)的情况下,运行模型诊断是非常重要的,以确保没有违反模型的假设。 plot_diagnostics对象允许我们快速生成模型诊断并调查任何异常行为。
arma_mod20.plot_diagnostics(figsize=(15, 12))
plt.show()

主要关切是确保我们的模型的残差是不相关的,并且平均分布为零。 如果季节性ARIMA模型不能满足这些特性,这是一个很好的迹象,可以进一步改善。
残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。“残差”蕴含了有关模型基本假设的重要信息。如果回归模型正确的话, 可以将残差看作误差的观测值。 它应符合模型的假设条件,且具有误差的一些性质。利用残差所提供的信息,来考察模型假设的合理性及数据的可靠性称为残差分析。
在这种情况下,我们的模型诊断表明,模型残差正常分布如下:
在右上图中,我们看到红色KDE线与N(0,1)行(其中N(0,1) )是正态分布的标准符号,平均值0 ,标准偏差为1 ) 。 这是残留物正常分布的良好指示。
左下角的q-q图显示,残差(蓝点)的有序分布遵循采用N(0, 1)的标准正态分布采样的线性趋势。 同样,这是残留物正常分布的强烈指示。
随着时间的推移(左上图)的残差不会显示任何明显的季节性,似乎是白噪声。 这通过右下角的自相关(即相关图)来证实,这表明时间序列残差与其本身的滞后值具有低相关性。
这些观察结果使我得出结论,模型选择了令人满意,可以了解时间序列数据和预测未来价值。
虽然有一个令人满意的结果,的季节性ARIMA模型的一些参数可以改变,以改善模型拟合。 例如,我网格搜索只考虑了一组受限制的参数组合,所以如果在拓宽网格搜索,可能会找到更好的模型。
⑨验证预测
# 对模型进行验证
pred = arma_mod20.get_prediction(start=pd.to_datetime('2013-12-31'), dynamic=False) #预测值
pred_ci = pred.conf_int() #置信区间
预测年份的置信区间:
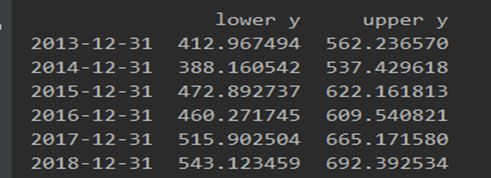
实际年份的确定值:

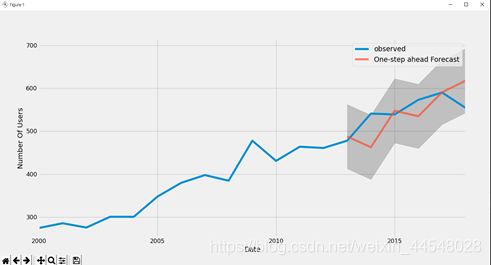
可以看出,实际年份的确定值,均在预测年份的置信区间。进一步证明此ARIMA模型的选择是真实有效的。
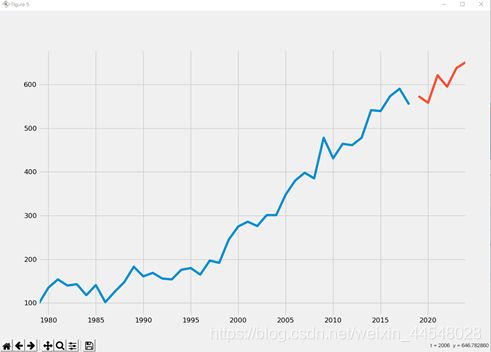
⑩生成和可视化预测
根据项目需求,预测 2019-2024年的预测值
# arma_mod20 = sm.tsa.ARIMA(train_data, order=(2,0,0)).fit()
# 输出 AIC:赤池信息准则 BIC:贝叶斯信息准则
print(arma_mod20.aic, arma_mod20.bic, arma_mod20.hqic)
# 预测 2019-2024 包区间的使用人数
predict_sunspots = arma_mod20.predict('2019', '2024', dynamic=True)
# 预测模型并作图
fig, ax = plt.subplots(figsize=(12, 8))
ax = train_data.loc['1979':].plot(ax=ax)
predict_sunspots.plot(ax=ax)
plt.show()

⑪将预测值与原数据导入到项目指定文件
'''''
写入文件函数
train_data: 1880-2018数据
Forecast_Array_Number: 预测后五年的数据
Name: 该组数据的名字
Rank_Array: 该组数据每年的排名
row_index: 该组数据坐在 CSV 的序号(行数)
'''
def Write_Data(train_data, Forecast_Array_Number, Name, Rank_Array, row_index, Gender):
train_data = train_data.astype('int32')
First_Name = Name[0]
Impot_File_Txt_Path = '../Data/Result_Data_File/' + First_Name + '/'
Impot_File_Txt_Name = Name + '.txt'
file_path = Impot_File_Txt_Path + Impot_File_Txt_Name
# 创建目录
if os.path.exists(Impot_File_Txt_Path):
pass
else:
os.mkdir(Impot_File_Txt_Path)
# 创建文件
if os.path.exists(file_path):
print("文件: " + file_path + " 已经存在")
File_Txt_Data = []
with open(file_path, mode='r', encoding='utf-8') as File_Txt:
File_Txt_Data = File_Txt.readlines()
# F
if (Gender == 'F'):
# 先前数据导入txt文件
for index in range(1, 140):
item = File_Txt_Data[index].split(',')
item[1] = str(train_data[index-1])
item[3] = str(Rank_Array[index - 1][row_index].astype('int32'))
str_ = ""
for item_ in item:
str_ = str_ + item_ + ','
File_Txt_Data[index] = str_[0:-1]
# 预测数据导入txt文件
i = 0
for index in range(140, 146):
item = File_Txt_Data[index].split(',')
print(Forecast_Array_Number[i])
item[1] = str(Forecast_Array_Number[i])[0:-2]
str_ = ""
for item_ in item:
str_ = str_ + str(item_) + ','
File_Txt_Data[index] = str_[0:-1]
i = i + 1
# M
else:
# 先前数据导入txt文件
for index in range(1, 140):
item = File_Txt_Data[index].split(',')
item[2] = str(train_data[index-1])
item[4] = str(Rank_Array[index - 1][row_index].astype('int32'))
str_ = ""
for item_ in item:
str_ = str_ + item_ + ','
File_Txt_Data[index] = str_[0:-1] + '\n'
# 预测数据导入txt文件
i = 0
for index in range(140, 146):
item = File_Txt_Data[index].split(',')
print(Forecast_Array_Number[i])
item[2] = str(Forecast_Array_Number[i])[0:-2]
str_ = ""
for item_ in item:
str_ = str_ + str(item_) + ','
File_Txt_Data[index] = str_[0:-1]
i = i + 1
with open(file_path, mode='w', encoding='utf-8') as File_Txt:
for item_ in File_Txt_Data:
File_Txt.write(item_)
# 没有同名文件
else:
print("成功创建文件: " + file_path)
with open(file_path, mode='w', encoding='utf-8') as File_Txt:
# 创建写入对象
File_Txt.write('BirthYear, F, M, Frank, Mrank' + '\n')
# 男性 M
if (Gender == 'M'):
# 先前数据导入txt文件
for item_data_index in range(len(train_data)):
item_data = train_data[item_data_index]
File_Txt.write(
str(Year_Number[item_data_index]) + ',' + '0' + ',' + str(item_data) + ',' + '0' + ',' + str(
Rank_Array[item_data_index][row_index].astype('int32')) + '\n')
# 预测数据导入txt文件
for item_data_index in range(len(Forecast_Array_Number)):
File_Txt.write(
str(Forecast_Year_Number[item_data_index]) + ',' + '0' + ',' + str(
Forecast_Array_Number[item_data_index])[0:-2] + ',' + '0' + ',' + '0' + '\n')
# 女性 F
else:
# 先前数据导入txt文件
for item_data_index in range(len(train_data)):
item_data = train_data[item_data_index]
File_Txt.write(str(Year_Number[item_data_index]) + ',' + str(item_data) + ',' + '0' + ',' + str(
Rank_Array[item_data_index][row_index].astype('int32')) + ',0\n')
# 预测数据导入txt文件
for item_data_index in range(len(Forecast_Array_Number)):
File_Txt.write(
str(Forecast_Year_Number[item_data_index]) + ',' + str(Forecast_Array_Number[item_data_index])[
0:-2] + ',' + '0' + ',' + '0' + ',' + '0' + '\n')
File_Txt.close()
def Error_Write_Data(train_data, Forecast_Array_Number, Name, Rank_Array, row_index, Gender):
train_data = train_data.astype('int32')
First_Name = Name[0]
Impot_File_Txt_Path = '../Data/Result_Data_File/' + First_Name + '/'
Impot_File_Txt_Name = Name + '.txt'
file_path = Impot_File_Txt_Path + Impot_File_Txt_Name
# 创建目录
if os.path.exists(Impot_File_Txt_Path):
pass
else:
os.mkdir(Impot_File_Txt_Path)
# 创建文件
if os.path.exists(file_path):
print("文件: " + file_path + " 已经存在")
File_Txt_Data = []
with open(file_path, mode='r', encoding='utf-8') as File_Txt:
File_Txt_Data = File_Txt.readlines()
# F
if (Gender == 'F'):
# 先前数据导入txt文件
for index in range(1, 139):
item = File_Txt_Data[index].split(',')
item[1] = str(train_data[index])
item[3] = str(Rank_Array[index][row_index].astype('int32'))
str_ = ""
for item_ in item:
str_ = str_ + item_ + ','
File_Txt_Data[index] = str_[0:-1]
# 预测数据导入txt文件
i = 0
for index in range(139, 145):
item = File_Txt_Data[index].split(',')
item[1] = '0'
str_ = ""
for item_ in item:
str_ = str_ + str(item_) + ','
File_Txt_Data[index] = str_[0:-1]
i = i + 1
# M
else:
# 先前数据导入txt文件
for index in range(1, 139):
item = File_Txt_Data[index].split(',')
item[2] = str(train_data[index])
item[4] = str(Rank_Array[index][row_index].astype('int32'))
str_ = ""
for item_ in item:
str_ = str_ + item_ + ','
File_Txt_Data[index] = str_[0:-1] + '\n'
# 预测数据导入txt文件
i = 0
for index in range(139, 145):
item = File_Txt_Data[index].split(',')
item[2] = '0'
str_ = ""
for item_ in item:
str_ = str_ + str(item_) + ','
File_Txt_Data[index] = str_[0:-1]
i = i + 1
with open(file_path, mode='w', encoding='utf-8') as File_Txt:
for item_ in File_Txt_Data:
File_Txt.write(item_)
# 没有同名文件
else:
print("成功创建文件: " + file_path)
with open(file_path, mode='w', encoding='utf-8') as File_Txt:
# 创建写入对象
File_Txt.write('BirthYear, F, M, Frank, Mrank' + '\n')
# 男性 M
if (Gender == 'M'):
# 先前数据导入txt文件
for item_data_index in range(len(train_data)):
item_data = train_data[item_data_index]
File_Txt.write(
str(Year_Number[item_data_index]) + ',' + '0' + ',' + str(item_data) + ',' + '0' + ',' + str(
Rank_Array[item_data_index][row_index].astype('int32')) + '\n')
# 预测数据导入txt文件
for item_data_index in range(len(Forecast_Array_Number)):
File_Txt.write(
str(Forecast_Year_Number[
item_data_index]) + ',' + '0' + ',' + '0' + ',' + '0' + ',' + '0' + '\n')
# 女性 F
else:
# 先前数据导入txt文件
for item_data_index in range(len(train_data)):
item_data = train_data[item_data_index]
File_Txt.write(str(Year_Number[item_data_index]) + ',' + str(item_data) + ',' + '0' + ',' + str(
Rank_Array[item_data_index][row_index].astype('int32')) + ',0\n')
# 预测数据导入txt文件
for item_data_index in range(len(Forecast_Array_Number)):
File_Txt.write(str(
Forecast_Year_Number[item_data_index]) + ',' + '0' + ',' + '0' + ',' + '0' + ',' + '0' + '\n')
File_Txt.close()
三、项目所有代码实现
# 编码 UTF-8 #
'''''=================================================
@Project -> File :英文取名(ARIMA模型预测) -> MY_ARIMA
@IDE :PyCharm
@Author :吴泽胜
@Date :2020/5/23 20:32
=================================================='''
import warnings
import itertools
import os
import gc
# 使用 matplotlib 的 scatter 方法绘制散点图
import matplotlib.pyplot as plt
# Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
import pandas as pd
# 提供高性能的矩阵运算
import numpy as np
# 自相关函数的库 ACF 和 PACF
import statsmodels.api as sm
# matplotlib绘图
import matplotlib
import matplotlib.dates as mdate
from pylab import rcParams
from statsmodels.graphics.gofplots import qqplot
from statsmodels.tsa.arima_model import ARIMA
from sklearn.metrics import mean_squared_error
warnings.filterwarnings("ignore") # 忽略警告
plt.style.use('fivethirtyeight') # 定义matplotlib风格 。
# 设置matplotlib对象自定义图形的各种默认属性
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
'''''
自回归移动平均模型(ARIMA)
该python文件核心函数
'''
def MY_ARIMA(train_data):
# 拆分法,检验序数据的稳定性
# 一阶差分图 t 与 t-1 时刻的差值
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(111)
# .diff(1) 差分间隔为1个单位 例如 2001年 - 2000年 的数据
diff1 = train_data.diff(1)
diff1.plot(ax=ax1)
# 做acf和pacf图 自相关函数acf的Pk的取值范围[-1,1] 偏自相关函数pacf
dta1 = train_data.diff(1)
# 差分的数据记得使用dropna方法去掉空值,否则acf和pacf图很可能出不来
dta2 = dta1.dropna()
# 显示 acf 和 pacf 图
fig = plt.figure(figsize=(12, 8))
# 此处为20 acf图,lags为滞后阶数
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(dta2, ax=ax1)
# pacf 图片
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(dta2, ax=ax2)
# 暴力测试pdq的最佳搭配值,此方法不是最优解,但是也是一种办法。
# evaluate parameters
p_values = d_values = q_values = range(0, 2)
# 忽略警告
warnings.filterwarnings("ignore")
# 调用 evaluate_models 方法,获取最优p,d,q值
# 均方根
best_cfg = evaluate_models(train_data.values, p_values, d_values, q_values)
# 预测模型
arma_mod20 = sm.tsa.statespace.SARIMAX(train_data,
order=(best_cfg[0], best_cfg[1], best_cfg[2]),
seasonal_order=(1, 1, 0, 12),
enforce_stationarity=False,
enforce_invertibility=False
).fit()
arma_mod20.plot_diagnostics(figsize=(16, 8))
print(arma_mod20.summary().tables[1])
# 对模型进行检验
# pred = arma_mod20.get_prediction(start=pd.to_datetime('2013-12-31'), dynamic=False) #预测值
# pred_ci = pred.conf_int() #置信区间
# # print(pred_ci)
# ax = train_data['2000':].plot(label='observed')
# pred.predicted_mean.plot(ax=ax, label='One-step ahead Forecast', alpha=.7, figsize=(14, 7))
#
# ax.fill_between(pred_ci.index,
# pred_ci.iloc[:, 0],
# pred_ci.iloc[:, 1], color='k', alpha=.2)
#
# ax.set_xlabel('Date')
# ax.set_ylabel('Number Of Users')
# plt.legend()
# plt.show()
# arma_mod20 = sm.tsa.ARIMA(train_data, order=(2,0,0)).fit()
# 输出 AIC:赤池信息准则 BIC:贝叶斯信息准则
print(arma_mod20.aic, arma_mod20.bic, arma_mod20.hqic)
# 预测 2019-2024 包区间的使用人数
predict_sunspots = arma_mod20.predict('2019', '2024', dynamic=True)
# 预测模型并作图
fig, ax = plt.subplots(figsize=(12, 8))
ax = train_data.loc['1979':].plot(ax=ax)
predict_sunspots.plot(ax=ax)
plt.show()
# 返回预测数据
# 返回的数据进行过滤
for item_data_index in range(len(predict_sunspots)):
if predict_sunspots[item_data_index] > 0:
predict_sunspots[item_data_index] = int(round(predict_sunspots[item_data_index], 0))
predict_sunspots[item_data_index] = str(predict_sunspots[item_data_index])[0:-2]
else:
predict_sunspots[item_data_index] = '0'
return predict_sunspots
# 寻找最优解pdq组合搭配
# evaluate combinations of p, d and q values for an ARIMA model
def evaluate_models(dataset, p_values, d_values, q_values):
dataset = dataset.astype('float32')
best_score, best_cfg = float("inf"), None
for p in p_values:
for d in d_values:
for q in q_values:
order = (p, d, q)
try:
mse = evaluate_arima_model(dataset, order)
if mse < best_score:
best_score, best_cfg = mse, order
print('ARIMA%s MSE=%.3f' % (order, mse))
except:
continue
print('Best ARIMA%s MSE=%.3f' % (best_cfg, best_score))
# 返回最优解 p,d,q
return best_cfg
# evaluate an ARIMA model for a given order (p,d,q)
def evaluate_arima_model(X, arima_order):
# prepare training dataset
train_size = int(len(X) * 0.66)
train, test = X[0:train_size], X[train_size:]
history = [x for x in train]
# make predictions
predictions = list()
for t in range(len(test)):
model = ARIMA(history, order=arima_order)
model_fit = model.fit(disp=0)
yhat = model_fit.forecast()[0]
predictions.append(yhat)
history.append(test[t])
# calculate out of sample error
error = mean_squared_error(test, predictions)
return error
'''''
写入文件函数
train_data: 1880-2018数据
Forecast_Array_Number: 预测后五年的数据
Name: 该组数据的名字
Rank_Array: 该组数据每年的排名
row_index: 该组数据坐在 CSV 的序号(行数)
'''
def Write_Data(train_data, Forecast_Array_Number, Name, Rank_Array, row_index, Gender):
train_data = train_data.astype('int32')
First_Name = Name[0]
Impot_File_Txt_Path = '../Data/Result_Data_File/' + First_Name + '/'
Impot_File_Txt_Name = Name + '.txt'
file_path = Impot_File_Txt_Path + Impot_File_Txt_Name
# 创建目录
if os.path.exists(Impot_File_Txt_Path):
pass
else:
os.mkdir(Impot_File_Txt_Path)
# 创建文件
if os.path.exists(file_path):
print("文件: " + file_path + " 已经存在")
File_Txt_Data = []
with open(file_path, mode='r', encoding='utf-8') as File_Txt:
File_Txt_Data = File_Txt.readlines()
# F
if (Gender == 'F'):
# 先前数据导入txt文件
for index in range(1, 140):
item = File_Txt_Data[index].split(',')
item[1] = str(train_data[index-1])
item[3] = str(Rank_Array[index - 1][row_index].astype('int32'))
str_ = ""
for item_ in item:
str_ = str_ + item_ + ','
File_Txt_Data[index] = str_[0:-1]
# 预测数据导入txt文件
i = 0
for index in range(140, 146):
item = File_Txt_Data[index].split(',')
print(Forecast_Array_Number[i])
item[1] = str(Forecast_Array_Number[i])[0:-2]
str_ = ""
for item_ in item:
str_ = str_ + str(item_) + ','
File_Txt_Data[index] = str_[0:-1]
i = i + 1
# M
else:
# 先前数据导入txt文件
for index in range(1, 140):
item = File_Txt_Data[index].split(',')
item[2] = str(train_data[index-1])
item[4] = str(Rank_Array[index - 1][row_index].astype('int32'))
str_ = ""
for item_ in item:
str_ = str_ + item_ + ','
File_Txt_Data[index] = str_[0:-1] + '\n'
# 预测数据导入txt文件
i = 0
for index in range(140, 146):
item = File_Txt_Data[index].split(',')
print(Forecast_Array_Number[i])
item[2] = str(Forecast_Array_Number[i])[0:-2]
str_ = ""
for item_ in item:
str_ = str_ + str(item_) + ','
File_Txt_Data[index] = str_[0:-1]
i = i + 1
with open(file_path, mode='w', encoding='utf-8') as File_Txt:
for item_ in File_Txt_Data:
File_Txt.write(item_)
# 没有同名文件
else:
print("成功创建文件: " + file_path)
with open(file_path, mode='w', encoding='utf-8') as File_Txt:
# 创建写入对象
File_Txt.write('BirthYear, F, M, Frank, Mrank' + '\n')
# 男性 M
if (Gender == 'M'):
# 先前数据导入txt文件
for item_data_index in range(len(train_data)):
item_data = train_data[item_data_index]
File_Txt.write(
str(Year_Number[item_data_index]) + ',' + '0' + ',' + str(item_data) + ',' + '0' + ',' + str(
Rank_Array[item_data_index][row_index].astype('int32')) + '\n')
# 预测数据导入txt文件
for item_data_index in range(len(Forecast_Array_Number)):
File_Txt.write(
str(Forecast_Year_Number[item_data_index]) + ',' + '0' + ',' + str(
Forecast_Array_Number[item_data_index])[0:-2] + ',' + '0' + ',' + '0' + '\n')
# 女性 F
else:
# 先前数据导入txt文件
for item_data_index in range(len(train_data)):
item_data = train_data[item_data_index]
File_Txt.write(str(Year_Number[item_data_index]) + ',' + str(item_data) + ',' + '0' + ',' + str(
Rank_Array[item_data_index][row_index].astype('int32')) + ',0\n')
# 预测数据导入txt文件
for item_data_index in range(len(Forecast_Array_Number)):
File_Txt.write(
str(Forecast_Year_Number[item_data_index]) + ',' + str(Forecast_Array_Number[item_data_index])[
0:-2] + ',' + '0' + ',' + '0' + ',' + '0' + '\n')
File_Txt.close()
def Error_Write_Data(train_data, Forecast_Array_Number, Name, Rank_Array, row_index, Gender):
train_data = train_data.astype('int32')
First_Name = Name[0]
Impot_File_Txt_Path = '../Data/Result_Data_File/' + First_Name + '/'
Impot_File_Txt_Name = Name + '.txt'
file_path = Impot_File_Txt_Path + Impot_File_Txt_Name
# 创建目录
if os.path.exists(Impot_File_Txt_Path):
pass
else:
os.mkdir(Impot_File_Txt_Path)
# 创建文件
if os.path.exists(file_path):
print("文件: " + file_path + " 已经存在")
File_Txt_Data = []
with open(file_path, mode='r', encoding='utf-8') as File_Txt:
File_Txt_Data = File_Txt.readlines()
# F
if (Gender == 'F'):
# 先前数据导入txt文件
for index in range(1, 139):
item = File_Txt_Data[index].split(',')
item[1] = str(train_data[index])
item[3] = str(Rank_Array[index][row_index].astype('int32'))
str_ = ""
for item_ in item:
str_ = str_ + item_ + ','
File_Txt_Data[index] = str_[0:-1]
# 预测数据导入txt文件
i = 0
for index in range(139, 145):
item = File_Txt_Data[index].split(',')
item[1] = '0'
str_ = ""
for item_ in item:
str_ = str_ + str(item_) + ','
File_Txt_Data[index] = str_[0:-1]
i = i + 1
# M
else:
# 先前数据导入txt文件
for index in range(1, 139):
item = File_Txt_Data[index].split(',')
item[2] = str(train_data[index])
item[4] = str(Rank_Array[index][row_index].astype('int32'))
str_ = ""
for item_ in item:
str_ = str_ + item_ + ','
File_Txt_Data[index] = str_[0:-1] + '\n'
# 预测数据导入txt文件
i = 0
for index in range(139, 145):
item = File_Txt_Data[index].split(',')
item[2] = '0'
str_ = ""
for item_ in item:
str_ = str_ + str(item_) + ','
File_Txt_Data[index] = str_[0:-1]
i = i + 1
with open(file_path, mode='w', encoding='utf-8') as File_Txt:
for item_ in File_Txt_Data:
File_Txt.write(item_)
# 没有同名文件
else:
print("成功创建文件: " + file_path)
with open(file_path, mode='w', encoding='utf-8') as File_Txt:
# 创建写入对象
File_Txt.write('BirthYear, F, M, Frank, Mrank' + '\n')
# 男性 M
if (Gender == 'M'):
# 先前数据导入txt文件
for item_data_index in range(len(train_data)):
item_data = train_data[item_data_index]
File_Txt.write(
str(Year_Number[item_data_index]) + ',' + '0' + ',' + str(item_data) + ',' + '0' + ',' + str(
Rank_Array[item_data_index][row_index].astype('int32')) + '\n')
# 预测数据导入txt文件
for item_data_index in range(len(Forecast_Array_Number)):
File_Txt.write(
str(Forecast_Year_Number[
item_data_index]) + ',' + '0' + ',' + '0' + ',' + '0' + ',' + '0' + '\n')
# 女性 F
else:
# 先前数据导入txt文件
for item_data_index in range(len(train_data)):
item_data = train_data[item_data_index]
File_Txt.write(str(Year_Number[item_data_index]) + ',' + str(item_data) + ',' + '0' + ',' + str(
Rank_Array[item_data_index][row_index].astype('int32')) + ',0\n')
# 预测数据导入txt文件
for item_data_index in range(len(Forecast_Array_Number)):
File_Txt.write(str(
Forecast_Year_Number[item_data_index]) + ',' + '0' + ',' + '0' + ',' + '0' + ',' + '0' + '\n')
File_Txt.close()
def Process_Information(row_index):
print(' ****************************************')
print()
print(" 运行第 %d 组数据中..." % (row_index + 1))
print()
print(' ****************************************')
'''''
程序入口,在df流中,遍历获取每组数据
数据准备与预处理
'''
# 创建导入数据对象
df = pd.read_csv("../Data/Test.csv") # 相对路径Babyname-1880-2018
# 数据年份
Year_Number = []
# 预测年份
Forecast_Year_Number = ['2019', '2020', '2021', '2022', '2023', '2024']
# 年份人数排序
# 男 Male Rank
Rank_Array_M = []
# 女 Female Rank
Rank_Array_F = []
# 过滤每年的男女人数
df_M = df[df["Gender"] != 'F']
df_F = df[df["Gender"] != 'M']
# 写入 1979-2018年 四十年
for item in range(1880, 2019):
Year_Number.append(str(item))
# 写入排序 M
for item in Year_Number:
my_df = df_M[item].rank(ascending=0, method='first')
Rank_Array_M.append(my_df)
# 写入排序 F
for item in Year_Number:
my_df = df_F[item].rank(ascending=0, method='first')
Rank_Array_F.append(my_df)
# 遍历每一条数据
for row_index, row in df.iterrows():
# 异常处理
try:
# 打印运行位置
Process_Information(row_index)
# 记录性别
Gender = row[1:2][0]
# 选择性别排名 三元运算
Rank_Array = Rank_Array_M if Gender == 'M' else Rank_Array_F
# 将DataFrame数据转为list
train_data = np.array(row).tolist()
# 传值 单条1880-2018年所有数据
train_data_all = train_data
train_data_all = pd.Series(train_data_all[2:])
# 将list数据转为Series 取1979年
train_data = pd.Series(train_data[101:])
# ARIMA学习所用的数据是单精度型数据
train_data = train_data.astype('float32')
# x轴年份 1880-2018
train_data.index = pd.Index(sm.tsa.datetools.dates_from_range(start='1979', end='2018', length=0))
# 设置面板大小
train_data.plot(figsize=(16, 6))
# 改变图标题字体,标题设置
plt.title(str(row[0:1]), fontdict={'weight': 'normal', 'size': 20})
# 对于测试ARIMA方法调用
Forecast_Array_Number = MY_ARIMA(train_data)
# 打印预测 2019年 - 2024年 的预测值
print(Forecast_Array_Number)
# 将处理好的数据,写入设计好的文档(txt)
Write_Data(train_data_all, Forecast_Array_Number, str(row[0:1][0]), Rank_Array, row_index, Gender)
except:
# 打印错误的名字
print("%s 运行错误:" % str(row[0:1][0]))
# 错误信息写入 将处理好的数据,写入设计好的文档(txt)
Error_Write_Data(train_data_all, Forecast_Array_Number, str(row[0:1][0]), Rank_Array, row_index, Gender)
pass
# 释放内存
gc.collect()
continue
'''''
Tit = 总迭代次数
Tnf = 功能评估总数
Tnint = 在Cauchy搜索期间探索的段总数
Skip = 跳过的 BFGS 更新数
Nact = 最终广义Cauchy点的有效界数
Projg = 最终投影坡度的范数
F = 最终功能值
'''