新闻文本分类-Task5
Task05:基于深度学习的文本分类
本章主要探索两个深度学习模型在文本分类上面的原理和应用。一个是CNN模型的应用TextCNN,另一个是RNN模型的应用TextRNN。
TextCNN
textCNN模型的原理图如下
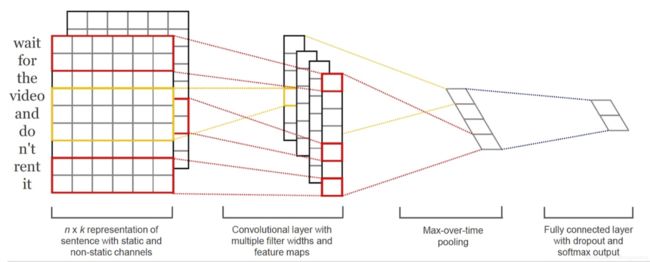
每个词通过向量来表示,模型的上游可以通过word2vec等方法学习得到每个单词的词向量表示,在进行卷积操作,此时的卷积和以往的图片卷积不同,是通过n*d,d表示词向量的维度,卷积的列如果小于d,会导致卷积提取的是词内部部分信息,这样没有意义。所以通过n*d的卷积核来进行的,可以使得word作为最小的粒度进行抽象,是一种n-gram特征抽取的方法。
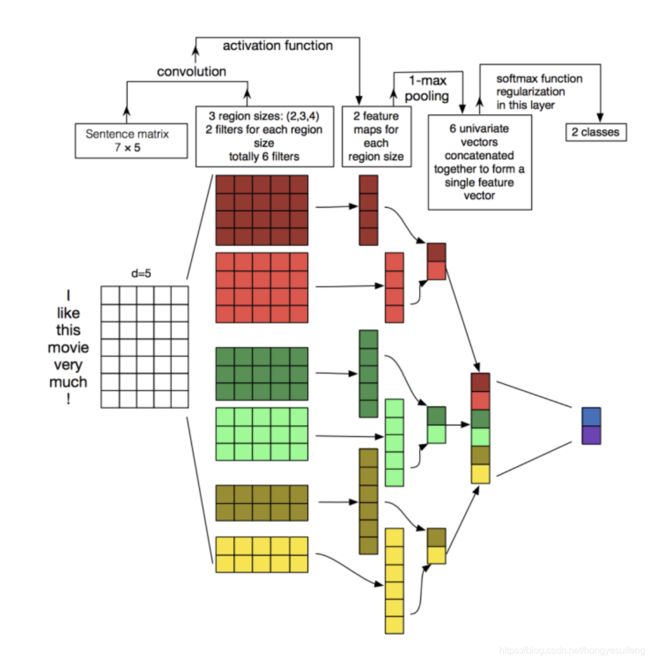
这里有6个卷积核,尺寸为2×5, 3×5, 4×5,每个尺寸各2个。
A分别与以上卷积核进行卷积操作,再用激活函数激活。每个卷积核都得到了特征向量(feature maps)。
使用1-max pooling提取出每个feature map的最大值,然后在级联得到最终的特征表达。
将特征输入至softmax layer进行分类, 可以进行正则化操作。
TextRNN
textRNN模型的原理图如下
该结构为TextRNN的经典结构:
embedding—>BiLSTM—>concat final output/average all output—>softmax
一般取前向/反向LSTM在最后一个时间步长上隐藏状态,然后进行拼接,在经过一个softmax层(输出层使用softmax激活函数)进行一个多分类;或者取前向/反向LSTM在每一个时间步长上的隐藏状态,对每一个时间步长上的两个隐藏状态进行拼接,然后对所有时间步长上拼接后的隐藏状态取均值,再经过一个softmax层(输出层使用softmax激活函数)进行一个多分类(2分类的话使用sigmoid激活函数)。
TextCNN进行文本分类
#常用包导入
import sys
import torch
import pandas as pd
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
from collections import Counter
from sklearn.utils import shuffle
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import classification_report
#数据读取
train = pd.read_csv(sys.argv[1],sep='|',names=["id","md5","path","label"])
test = pd.read_csv(sys.argv[2],sep='|',names=["id","md5","path","label"])
#cpu,gpu选择
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据处理,字典构建
train = shuffle(train)
word2idx = {
}
sentences = list(train['path'].apply(lambda x:" ".join(x.split("\\"))))
labels = list(train['label'])
test_sentences = list(test['path'].apply(lambda x:" ".join(x.split("\\"))))
test_labels = list(test['label'])
# TextCNN Parameter
embedding_size = 300
sequence_length = max([len(each.split()) for each in sentences]) # every sentences contains sequence_length(=3) words
num_classes = 2 # 0 or 1
batch_size = 128
# 词典量级过大,根据词频来筛选部分词语计入词典,其他新词,非常见词语通过“UNK”表示
word_list = " ".join(sentences).split()
c = Counter(word_list)
word_list_common = list(Counter(el for el in c.elements() if c[el]>1))
word_list_common.append("UNK")
vocab = list(set(word_list_common))
word2idx = {
w: i for i, w in enumerate(vocab)}
vocab_size = len(vocab)
def make_data(sentences, labels):
inputs = []
for sen in sentences:
tmp_list = []
for each_word in sen.split():
try:
tmp_list.append(word2idx[each_word])
except:
tmp_list.append(word2idx['UNK'])
inputs.append(tmp_list)
#inputs.append([word2idx[n] for n in sen.split()])
targets = []
for out in labels:
targets.append(out) # To using Torch Softmax Loss function
pad_token = 0
padded_X = np.ones((len(inputs), sequence_length)) * pad_token
for i, x_len in enumerate([len(each) for each in inputs]):
sequence = inputs[i]
padded_X[i, 0:x_len] = sequence[:x_len]
inputs, targets = torch.LongTensor(padded_X), torch.LongTensor(labels)
return inputs, targets
# 数据构建
input_batch, target_batch = make_data(sentences,labels)
input_batch_test, target_batch_test = make_data(test_sentences,test_labels)
dataset = Data.TensorDataset(input_batch, target_batch)
loader = Data.DataLoader(dataset, batch_size, True)
# 模型构建
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN, self).__init__()
self.W = nn.Embedding(vocab_size, embedding_size)
output_channel = 1
self.conv2 = nn.Conv2d(1, 1, (2, embedding_size))
self.conv3 = nn.Conv2d(1, 1, (3, embedding_size))
self.conv4 = nn.Conv2d(1, 1, (4, embedding_size))
# fc
#self.fc = nn.Linear(3 * output_channel, num_classes)
self.Max2_pool = nn.MaxPool2d((sequence_length-2+1, 1))
self.Max3_pool = nn.MaxPool2d((sequence_length-3+1, 1))
self.Max4_pool = nn.MaxPool2d((sequence_length-4+1, 1))
#self.fc = nn.Linear(7 * output_channel, num_classes)
self.linear1 = nn.Linear(3, 2)
def forward(self, x):
#'''
#X: [batch_size, sequence_length]
#'''
#batch_size = X.shape[0]
#embedding_X1 = self.W(X) # [batch_size, sequence_length, embedding_size]
#embedding_X = embedding_X.unsqueeze(1) # add channel(=1) [batch, channel(=1), sequence_length, embedding_size]
#conved = self.conv(embedding_X) # [batch_size, output_channel, 1, 1]
#flatten = conved.view(batch_size, -1) # [batch_size, output_channel*1*1]
#output = self.fc(flatten)
#return output
batch = x.shape[0]
# Convolution
x = self.W(x)
x = x.unsqueeze(1)
x1 = F.relu(self.conv2(x))
x2 = F.relu(self.conv3(x))
x3 = F.relu(self.conv4(x))
# Pooling
x1 = self.Max2_pool(x1)
x2 = self.Max3_pool(x2)
x3 = self.Max4_pool(x3)
# capture and concatenate the features
x = torch.cat((x1, x2, x3), -1)
x = x.view(batch, 1, -1)
# project the features to the labels
x = self.linear1(x)
x = x.view(-1, 2)
return x
model = TextCNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Training
for epoch in range(5):
for i,(batch_x, batch_y) in enumerate(loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (i + 1) % 100 == 0:
# print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
print('Epoch:', '%03d' % (epoch + 1), "data_batch:",i, 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# test eval
## Test
## Predict
model = model.eval()
predict = model(input_batch_test).data.max(1, keepdim=True)[1]
print("this is the precision:")
print(precision_score(test_labels,predict))
print("this is the recall:")
print(recall_score(test_labels,predict))
print(classification_report(test_labels,predict))
TextRNN未完待续。。
import sys
import torch
import pandas as pd
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
from collections import Counter
from sklearn.utils import shuffle
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import classification_report
train = pd.read_csv(sys.argv[1],sep='|',names=["id","md5","path","label"])
test = pd.read_csv(sys.argv[2],sep='|',names=["id","md5","path","label"])
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 3 words sentences (=sequence_length is 3)
train = shuffle(train)
word2idx = {
}
sentences = list(train['path'].apply(lambda x:" ".join(x.split("\\"))))
labels = list(train['label'])
test_sentences = list(test['path'].apply(lambda x:" ".join(x.split("\\"))))
test_labels = list(test['label'])
# TextRNN Parameter
embedding_size = 300
sequence_length = max([len(each.split()) for each in sentences]) # every sentences contains sequence_length(=3) words
num_classes = 2 # 0 or 1
batch_size = 128
word_list = " ".join(sentences).split()
c = Counter(word_list)
word_list_common = list(Counter(el for el in c.elements() if c[el]>1))
word_list_common.append("UNK")
vocab = list(set(word_list_common))
word2idx = {
w: i for i, w in enumerate(vocab)}
vocab_size = len(vocab)
def make_data(sentences, labels):
inputs = []
for sen in sentences:
tmp_list = []
for each_word in sen.split():
try:
tmp_list.append(word2idx[each_word])
except:
tmp_list.append(word2idx['UNK'])
inputs.append(tmp_list)
#inputs.append([word2idx[n] for n in sen.split()])
targets = []
for out in labels:
targets.append(out) # To using Torch Softmax Loss function
pad_token = 0
padded_X = np.ones((len(inputs), sequence_length)) * pad_token
for i, x_len in enumerate([len(each) for each in inputs]):
sequence = inputs[i]
padded_X[i, 0:x_len] = sequence[:x_len]
inputs, targets = torch.LongTensor(padded_X), torch.LongTensor(labels)
return inputs, targets
input_batch, target_batch = make_data(sentences,labels)
input_batch_test, target_batch_test = make_data(test_sentences,test_labels)
dataset = Data.TensorDataset(input_batch, target_batch)
loader = Data.DataLoader(dataset, batch_size, True)
class TextRNN(nn.Module):
def __init__(self):
super(TextRNN, self).__init__()
self.W = nn.Embedding(vocab_size, embedding_size)
self.lstm = nn.LSTM(300, 128, 2,bidirectional=True, batch_first=True)
# fc
self.fc = nn.Linear(128 * 2, 2)
def forward(self, X):
'''
X: [batch_size, sequence_length]
'''
batch_size = X.shape[0]
out = self.W(X) # [batch_size, sequence_length, embedding_size]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :])
return out
model = TextRNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Training
for epoch in range(2):
for i,(batch_x, batch_y) in enumerate(loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (i + 1) % 100 == 0:
#print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
print('Epoch:', '%03d' % (epoch + 1), "data_batch:",i, 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# test eval
## Test
## Predict
model = model.eval()
predict = model(input_batch_test).data.max(1, keepdim=True)[1]
print("this is the precision:")
print(precision_score(test_labels,predict))
print("this is the recall:")
print(recall_score(test_labels,predict))
print(classification_report(test_labels,predict))