《自拍教程69》Python 批量重命名音频文件,AV专家必备!
本篇主要学习如何Python自定义模块并调用该模块,并重点介绍Python正则表达式的强大的文本处理能力。
案例故事: 任何一款终端产品只要涉及音频输出,就肯定涉及音频的解码,
作为一名专业的AV (Audio & Video)测试人员,我们需要一堆的规范化标准的的音频测试文件,
但是发现音频资源名字命名的很随意比如:青藏高原.wma,
以上命名不能看出音频文件的具体编码规格,
测试经理要求我进行批量重命名工作,模板如下,
音频编码格式_音频采样率_声道数_比特率_容器.容器, 例如:
WMA_44.1KHz_stereo_192Kbps_wma.wma
音频编解码基本知识
将声音存储为音频文件的时候,需要经过以下几个步骤:
- 需要录制(采样)成音频原始数据;
- 通过一定的编码压缩技术将音频原始数据尽可能地压缩成最小;
- 通过音频容器以独立文件的形式存储音频;
主要涉及以下技术参数:
| 音频参数 | 参数释义 | 举例 |
|---|---|---|
| 音频编码格式 (压缩技术) |
即将音频数据压缩的一类技术, 不同的编码格式, 其压缩率与压缩效果不一样。 主要分成2类: 有损压缩(会导致失真,压缩率高) 无损压缩(尽量保真,压缩率低) |
有损压缩: Mpeg1 Level3(即我们常说的Mp3); WMA;LCACC; LTPAAC; HE-AAC, HE-AACV2; AMR-WB, AMN-NB; Vorbis;MiDi; 无损压缩: Flac;PCM;APE |
| 音频采样率 (单位:Khz) |
将声音记录成数据文件的时候, 需要对声音进行采样, 每秒钟对声音信号的采样次数即采样率。 采样率越高,越能还原现场音质。 |
比如44.1Khz代表每秒采样44100次 8Khz, 11.025Khz, 22.5Khz, 32Khz, 44.1Khz, 48Khz,96Khz |
| 音频位深度 (单位:bit) |
每次采样,采集数据量的大小 | 8bit, 16bit |
| 音频声道数 (单位:channel) |
一般有双声道即2个声道, 录音的时候肯定是需要2个麦克风同时录制的, 即同时采集了2个音频流。 5声道,则需要有5个麦克风同时录制 |
单声道:1 channel, Mono 双声道:2 channels, Stereo 5声道:5 channels |
| 音频比特率 (单位:Kbps) |
每秒钟的音频流的数据量, 其大小是直接取决于: 音频编码格式(压缩率), 采样率,位深度,声道数乘积 |
48Kbps, 96Kbps, 128Kbps,256Kbps |
| 音频容器 | 文件后缀,将音频流封装的一种文件格式 | .mp3; .wma; .aac; .3gp; .mp4; .flac ; .ape;.pcm; .raw; .mid; .ogg; .wav; .mkv; .m4a |
我们碰到的任何音频文件,都是数据的集合,
一般数据越大,其音频播放质量越好。
准备阶段
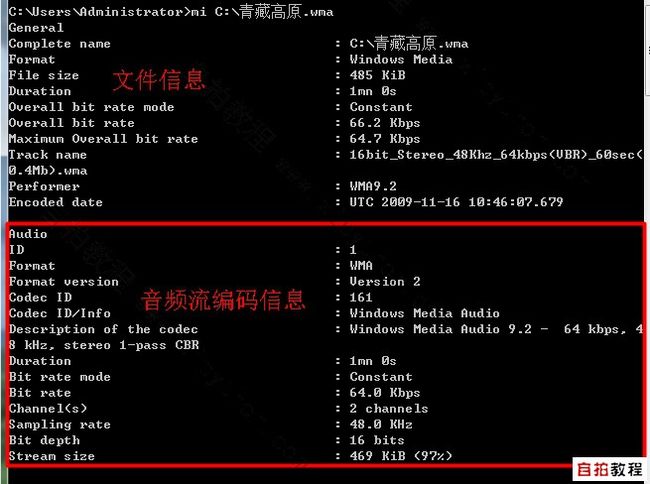
- 确保mediainfo.exe 命令行工具已经加入环境变量,查看其具体功能方法。
- 以下是某个音频文件的mediainfo信息, 都是文本,Python处理起来肯定很简单的。
- 如果要进行批量重命名音频,我们还是用输入输出文件架构,如下:
+---Input_Audio #批量放入待命名的音频
| 1.mp3
| 青藏高原.wma
|
+---Output_Video #批量输出已命名的音频
| Mpeg3L1_44.1KHz_stereo_128Kbps_mp3.mp3
| WMA_44.1Khz_stereo_96Kbps_wma.wma
|
\audio_info.py # 获取音频文件info信息的模块,
\rename_audio.py #调用audio_info.py并实现重名,可双击运行
定义audio_info.py模块
由于涉及较复杂的代码,建议直接用面向对象类的编程方式实现:
# coding=utf-8
import os
import re
import subprocess
class AudioInfoGetter():
'''获取音频文件的codec, sample_rate, channels, bitrate'''
def __init__(self, audio_file):
'''判断文件是否存在,如果存在获取其mediainfo信息'''
if os.path.exists(audio_file):
self.audio_file = audio_file
p_obj = subprocess.Popen('mediainfo "%s"' % self.audio_file, shell=True, stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
self.info = p_obj.stdout.read().decode("utf-8") # 解决非英文字符的编码问题
else:
raise FileNotFoundError("Not this File!") # 如果多媒体文件路径不存在,必须中断
def get_audio_codec(self):
'''获取音频的编码格式,比如Mepg3L1就是我们常说的Mp3, 还有AAC系列,AMR系列,Flac等等'''
try:
audio_codec = re.findall(r"Format\s+:\s(.*)", self.info)[-1] # 取第最后一个Format字段
audio_codec = audio_codec.strip() # 去除前后的空格
if (audio_codec == "MPEG Audio"):
audio_codec = self.__format_mpeg_audio()
elif (audio_codec == "AMR"):
audio_codec = self.__format_amr_audio()
elif (audio_codec == "AAC"):
audio_codec = self.__format_aac_audio()
elif ("PCM" in audio_codec):
audio_codec = "PCM"
else:
pass
except:
audio_codec = "undef" # 防止程序因为异常而中断
return audio_codec
def get_audio_channel(self):
'''获取声道数,如果是双声道是stereo, 如果是单声道是mono,还存在5声道的情况'''
try:
audio_channel = re.findall(r"Channel\(s\)\s+:\s(.*)\schannel.*", self.info)[-1]
audio_channel = audio_channel.strip() # 过滤掉前后空格
if audio_channel == "2":
audio_channel = "stereo"
elif audio_channel == "1":
audio_channel = "mono"
elif audio_channel == "5":
audio_channel = "5-channels"
else:
audio_channel = "undef" # 设置为undef,表示特殊异常规格,建议人工验证并考虑手动重命名
except:
audio_channel = "undef" # 防止程序因为异常而中断
return audio_channel
def get_audio_sample_rate(self):
'''获取音频采样率,比如常见的48Khz, 44.1Khz等'''
try:
audio_sample_rate = re.findall(r"Sampling rate\s+:\s(.*)", self.info)[-1].strip()
audio_sample_rate = audio_sample_rate.replace(" ", "") # 去1 536 这个数字里的空格
if "K" not in audio_sample_rate:
audio_sample_rate = audio_sample_rate.replace("Hz", "") # 先去掉“Hz"
audio_sample_rate = str(int(int(audio_sample_rate) / 1000))
audio_sample_rate = audio_sample_rate + "Khz" # 再添上KHz的单位
elif audio_sample_rate.endswith(".0Khz"):
audio_sample_rate = audio_sample_rate.replace(".0", "")
elif "/" in audio_sample_rate: # 偶尔会有多个采样率的情况 48.0 Khz / 44.1 KHz 这种
audio_sample_rate = "undef" # # 设置为undef,表示特殊异常规格,建议人工验证并考虑手动重命名
else:
pass
except:
audio_sample_rate = "undef" # 防止程序因为异常而中断
return audio_sample_rate
def get_audio_bitrate(self):
'''获取音频比特率,比如96Kbps, 128Kbps'''
try:
audio_bitrate = re.findall(r"Bit rate\s+:\s(.*)", self.info)[-1].strip()
audio_bitrate = audio_bitrate.replace(" ", "") # 去掉1 536 这个数字里的空格
if "K" not in audio_bitrate:
audio_bitrate = audio_bitrate.replace("bps", "") # 先去掉“bps"
audio_bitrate = str(int(audio_bitrate) / 1000)
audio_bitrate = audio_bitrate + "Kbps" # 再添上KHz的单位
except:
audio_bitrate = "undef" # 防止程序因为异常而中断
return audio_bitrate
def get_audio_container(self):
'''获取音频容器,即文件后缀名'''
_, audio_container = os.path.splitext(self.audio_file)
if not audio_container:
raise NameError("This file no extension")
audio_container = audio_container.replace(".", "")
return audio_container
def __format_mpeg_audio(self):
'''如果是Mpeg Auido的音频格式(常见的比如Mp3(Mpeg1 Level3)),进行格式化'''
try:
mpeg_audio_version = re.findall(r"Format version\s+:\sVersion\s(.*)", self.info)[-1].strip()
mpeg_audio_profile = re.findall(r"Format profile\s+:\sLayer\s(.*)", self.info)[-1].strip()
mpeg_audio_profile = "Mpeg%sL%s" % (mpeg_audio_version, mpeg_audio_profile)
except:
mpeg_audio_profile = "undef"
return mpeg_audio_profile
def __format_amr_audio(self):
'''如果是amr的音频格式(常见的比如amr-nb amr-wb),进行格式化'''
try:
amr_profile = re.findall(r"Format profile\s+:\s(.*)", self.info)[-1].strip()
if amr_profile == "Wide band":
amr_profile = "AMR-WB"
elif amr_profile == "Narrow band":
amr_profile = "AMR-NB"
else:
amr_profile = "undef" # 设置为undef,表示特殊异常规格,建议人工验证并考虑手动重命名
except:
amr_profile = "undef"
return amr_profile
def __format_aac_audio(self):
'''如果是acc的音频格式(常见的比如AAC-LC, AAC-LTP, HE-AAC, HE-AACV2),进行格式化'''
try:
amr_profile = re.findall(r"Format profile\s+:\s(.*)", self.info)[-1].strip()
if amr_profile == "LC":
aac_profile = "AAC-LC"
elif amr_profile == "LTP":
aac_profile = "AAC-LTP"
elif amr_profile.startswith("HE-AACv2"):
aac_profile = "HE-AACV2"
elif amr_profile.startswith("HE-AAC"):
aac_profile = "HE-AAC"
else:
aac_profile = "undef" # 设置为undef,表示特殊异常规格,建议人工验证并考虑手动重命名
except:
aac_profile = "undef"
return aac_profile
if __name__ == '__main__':
# 以下代码块,只是用来测试本模块的,一般不建议直接在这里大面积调用本模块'''
a_obj = AudioInfoGetter("C:\\好听的歌曲.wma")
audio_codec = a_obj.get_audio_codec()
print(audio_codec)
调用audio_info.py模块并实现批量重命名
# coding=utf-8
import os
import audio_info
from shutil import copyfile
curdir = os.getcwd()
# 输入文件夹,放入待重命名的音频
input_audio_path = os.path.join(curdir, "Input_Audio")
filelist = os.listdir(input_audio_path) #获取文件列表
# 输出文件夹,已命名的视频存放在这里
output_audio_path = os.path.join(curdir, "Output_Audio")
# 如果没有Output_Audio这个文件夹,则创建这个文件夹
if not os.path.exists(output_audio_path):
os.mkdir(output_audio_path)
if filelist: # 如果文件列表不为空
for i in filelist: # 变量文件列表
audio_file = os.path.join(input_audio_path, i)
a_obj = audio_info.AudioInfoGetter(audio_file)
audio_codec = a_obj.get_audio_codec()
audio_sample_rate = a_obj.get_audio_sample_rate()
audio_channel = a_obj.get_audio_channel()
audio_bitrate = a_obj.get_audio_bitrate()
audio_container = a_obj.get_audio_container()
new_audio_name = audio_codec + "_" + audio_sample_rate + "_" + audio_channel + "_" \
+ audio_bitrate + "_" + audio_container + "." + audio_container
print(new_audio_name)
new_audio_file = os.path.join(output_audio_path, new_audio_name)
copyfile(audio_file, new_audio_file) # 复制文件
else:
print("It's a Empty folder, please input the audio files which need to be renamed firstly!!!")
os.system("pause")
本案例练手素材下载
包含:mediainfo.exe(更建议丢到某个环境变量里去),
各种编码格式的音频文件,audio_info.py模块,rename_audio.py批处理脚本
调转自拍教程官网下载
运行效果如下:

以上可以看出,输入输出文件架构的好处,
我只需要将不同名字不同字符的,待重命名的音频文件整理好,
丢到Input_Audio文件夹下,运行程序脚本后查看Output_Audio输出文件,
就可以测试脚本的运行是否正常,健壮性(容错)是否符合要求,
从而对这个程序脚本实现了“灰盒测试”。
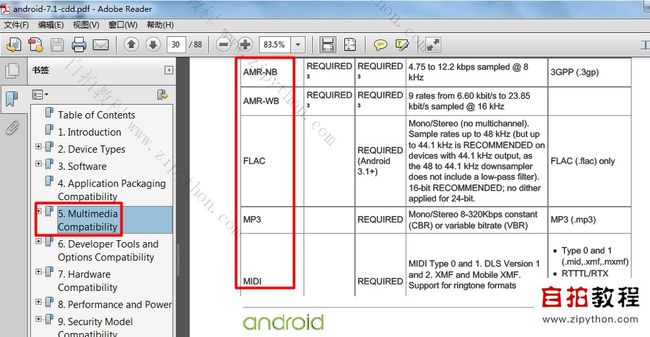
小提示: 比如Android手机,Google推出了CDD(Compatibiltiy Definition Document兼容性定义文档),
其第5部分,涉及了很多音频编解码格式的规定:
这就是Android最主要的音频多媒体编解码测试需求。
更多更好的原创文章,请访问官方网站:www.zipython.com
自拍教程(自动化测试Python教程,武散人编著)
原文链接:https://www.zipython.com/#/detail?id=2c26d313cea54e8ab9ab3ecb612b986c
也可关注“武散人”微信订阅号,随时接受文章推送。