ElasticSearch分片是什么?投票机制是怎样的?脑裂问题如何解决?
ElasticSearch
- 一、ElasticSearch相关概念
-
- 一.ElasticSearch相关概念
-
-
- 1.1.ElasticSearch介绍
-
- 1.1.2.ES的特点
- 1.1.3.ES和lucene的区别
- 1.2.ES的相关概念
-
- 1.2.1.Near Realtime(NRT)
- 1.2.2.Index:索引库
- 1.2.3.Type:类型
- 1.2.4.Document&field
- 1.2.5.Cluster:集群
- 1.2.6.Node:节点
- 1.2.7.shard(分片)
- 1.2.8.replica(复制品)
- 1.2.9.集群原理图
-
- 二.ElasticSearch的安装
-
-
- 2.1.ElasticSearch安装
-
- 2.1.1.下载
- 2.1.2.安装
- 2.1.3.测试
- 2.2.可视化工具安装
-
- 2.2.1.Kibana5安装
-
- 1.下载
- 2.配置
- 3.启动Kibana5
- 4.默认访问地址
- 2.2.2.elasticsearch-header
-
- 1.下载
- 2.安装
- 3.运行
- 4.配置跨域
- 2.3.分词器安装
-
- 2.3.1.什么是分词
- 2.3.2.什么是分词器
- 2.3.3.安装IK分词器
-
- 三.RestFull风格
-
-
- 3.1.基本定义
-
- 3.1.1.什么是Restfull
- 3.1.2.Restful的好处
- 3.1.3.Restfull的特点
- 3.2.案例
-
- 3.2.1获取员工
- 3.2.2.添加一个员工
- 3.2.3.修改员工
- 3.2.4.删除员工
-
- 四.ElasticSearch基础
-
-
- 4.1.索引库CRUD
-
- 4.1.1增加索引库
- 4.1.2查询索引库
- 4.1.3.删除索引库
- 4.1.4.修改索引库
- 4.2.文档的CRUD
-
- 4.2.1.文档概念
- 4.2.2.添加文档
- 4.2.3.获取文档
- 4.2.4.修改文档
- 4.2.5.删除文档
-
- 五.文档的查询
-
-
- 5.1.常用查询
-
- 5.1.1.查询所有
- 5.1.2.查询指定索引库
- 5.1.3.查询指定类型
- 5.1.4.查询指定文档
- 5.1.5.批量获取
-
- a.不同索引库查询
- b.同索引库同类型 - 推荐
- 5.1.6.分页查询
- 5.1.6.字符串查询
-
- 六.DSL查询与DSL过滤
-
-
- 6.1.基本概念
-
- 6.1.1.基本概念
- 6.1.2.查询与过滤的区别
- 6.2.综合案例
-
- 6.2.1.语法介绍
- 6.2.2综合案例
-
- 七.文档的映射
-
-
- 7.1.基本概念
-
- 7.1.1.什么是文档映射
- 7.1.2.默认的字段类型
-
- a.基本字段类型
- b.复杂字段类型
- c.默认映射
- 7.1.3.映射规则
- 7.2.添加映射
-
- 7.2.1.创建新的索引库
- 7.2.2.单类型创建映射
- 7.2.3.多类型创建映射
- 7.3.数组/对象映射
-
- 7.3.1.对象映射
- 7.3.2.数组映射
- 7.3.3.对象数组
- 7.4.全局映射
-
- 7.4.1.默认方式:_default_
- 7.4.2.动态模板
- 7.5.最佳实践
-
- 1.建索引库
- 2.全局映射
- 3.自定义映射
- 4.Java-API做CRUD
-
- 八.ElasticSearch集群
-
-
- 8.1.集群相关概念
-
- 8.1.1.为什么要集群
- 8.1.2.ES节点类型
- 8.2.ES的集群理解
-
- 8.2.1.shard&replica机制
- 8.2.2.图解Shard分配
-
- a.单node环境下创建index
- b.两个node环境下创建index
- c.扩容极限,提升容错
- 8.2.3.容错机制-Master选举
- 8.3.集群搭建
-
- 8.3.1.环境准备
- 8.3.2.配置说明
- 8.3.3.修改ES配置
- 8.4连接集群
-
- 8.4.1.修改kibana配置
- 8.4.2.集群查看命令
-
- 九.JavaApi操作ES
-
-
- 9.1.集成ES
-
- 9.1.1.导入依赖
- 9.1.2.连接ES
- 9.2.文档CRUD
-
- 9.2.1.添加文档
- 9.2.2.获取文档
- 9.2.3.更新文档
- 9.2.4.删除文档
- 9.2.5.批量操作
- 9.3.查询-重要
-
- 十.总结
-
-
- 一.作业
- 二.重点
- 三.面试题
-
- 1.ES查询为什么这么快?
- 2.ES怎么搭建集群
- 3.你对ES的理解
- 4.ES和Lucene的区别
- 5.说一下你对ES的分片机制
-
本文所需资源文件
一、ElasticSearch相关概念
一.ElasticSearch相关概念
1.1.ElasticSearch介绍
ES是一个分布式的全文搜索引擎,为了解决原生Lucene使用的不足,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,ES的索引库管理支持依然是基于Apache Lucene™的开源搜索引擎。
ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐Lucene
的复杂性,从而让全文搜索变得简单。
1.1.2.ES的特点
- 分布式全文搜索引擎
- 能在分布式项目/集群中使用
- 本身支持集群扩展
- 处理PB级结构化或非结构化数据
- 简单的 RESTful API通信方式
- 支持各种语言的客户端
- 基于Lucene封装,使操作简单
1.1.3.ES和lucene的区别
Lucene:
- 只支持Java
- 非分布式的,索引目录只能在本地
- 使用非常复杂
- 小项目使用
1.2.ES的相关概念
1.2.1.Near Realtime(NRT)
近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
1.2.2.Index:索引库
包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
1.2.3.Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
1.2.4.Document&field
文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
| ES | MySql |
|---|---|
| 索引库(index) | 数据库 |
| 文档类型(type) | 表 |
| 文档(document) | 记录(一行数据) |
| 字段(field) | 列 |
1.2.5.Cluster:集群
包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
1.2.6.Node:节点
集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为"elasticsearch"的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
1.2.7.shard(分片)
单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
1.2.8.replica(复制品)
任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
1.2.9.集群原理图
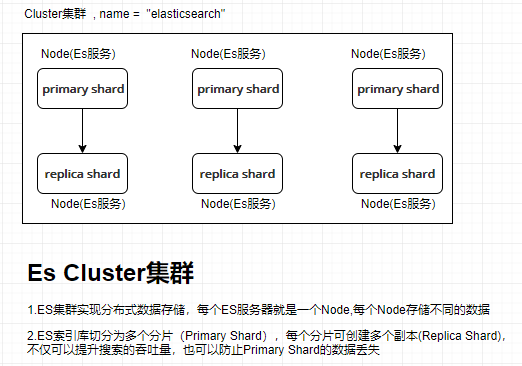
二.ElasticSearch的安装
2.1.ElasticSearch安装
2.1.1.下载
https://www.elastic.co/downloads/elasticsearch
2.1.2.安装
解压即可
2.1.3.测试
访问:http://localhost:9200
2.2.可视化工具安装
2.2.1.Kibana5安装
1.下载
https://www.elastic.co/downloads/kibana
2.配置
解压并编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
3.启动Kibana5
bin\kibana.bat
4.默认访问地址
http://localhost:5601
2.2.2.elasticsearch-header
1.下载
https://github.com/mobz/elasticsearch-head/releases
2.安装
npm install
3.运行
npm run start
4.配置跨域
修改 elasticsearch/config/elasticsearch.yml
- http.cors.enabled: true
- http.cors.allow-origin: “*”
2.3.分词器安装
2.3.1.什么是分词
2.3.2.什么是分词器
2.3.3.安装IK分词器
ES默认对英文文本的分词器支持较好,但和lucene一样,如果需要对中文进行全文检索,那么需要使用中文分词器,同lucene一样,在使用中文全文检索前,需要集成IK分词器。
-
下载IK分词器
ES的IK分词器插件源码地址:https://github.com/medcl/elasticsearch-analysis-ik
-
解压elasticsearch-analysis-ik-5.2.2.zip文件
并将其内容放置于ES根目录/plugins/ik
-
IK分词器配置
-
IK分词测试
POST _analyze { "analyzer":"ik_smart", "text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首" }IK分词器指定:ik_smart ; ik_max_word
三.RestFull风格
3.1.基本定义
3.1.1.什么是Restfull
Restful是一种面向资源的架构风格,可以简单理解为:使用URL定位资源(名称),用HTTP动(GET,POST,DELETE,PUT)描述操作。
描述id为1的用户:/user/1
获取id为1的用户:GET /user/1
3.1.2.Restful的好处
- 透明性,暴露资源存在。
- 充分利用 HTTP 协议本身语义。(GET POST DELETE PUT)
- 无状态,这点非常重要。在调用一个接口(访问、操作资源)的时候,可以不用考虑上下文,不用考虑当前状态,极大的降低了复杂度。
3.1.3.Restfull的特点
- 资源(URL)使用名词表示
- 使用http动词来描述操作
3.2.案例
3.2.1获取员工
获取id为10的员工
GET /employee/10
获取所有员工
GET /employees
3.2.2.添加一个员工
PUT /employee/save
{
"username":"zs"
}
3.2.3.修改员工
POST /employee/update
{
"id":1,
"username":"zs"
}
3.2.4.删除员工
DELETE /employee/1
四.ElasticSearch基础
# 分词器
POST _analyze
{
"analyzer":"ik_smart",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
#添加数据:索引库 crm ,文档类型 employee , 文档id 1
PUT _index/_type/_id
PUT crm/employee/1
{
"id":1,
"username":"zs"
}
POST crm/employee
{
"id":2,
"username":"ls"
}
#获取
GET crm/employee/1?pretty
GET crm/employee/AW6H9xjf0NTWp10n23Ze
GET _search
#删除
DELETE crm/employee/AW6H9xjf0NTWp10n23Ze
DELETE _all
#全量修改
PUT crm/employee/1
{
"username":"zszs"
}
#局部修改
POST crm/employee/1/_update
{
"doc":{
"username":"ls"
}
}
4.1.索引库CRUD
4.1.1增加索引库
PUT shopping
{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
}
}
4.1.2查询索引库
GET _cat/indices?v
查看指定索引库
GET _cat/indices/aigou

4.1.3.删除索引库
DELETE 名字
4.1.4.修改索引库
删除再添加
4.2.文档的CRUD
4.2.1.文档概念
| ES | Mysql |
|---|---|
| _index(索引库) | 数据库 |
| _type(文档类型) | 表 |
| _document(文档对象) | 一行数据 |
| _id(文档ID) | 主键ID |
其他
| _source | (文档原始数据-就是保存在ES中的真实数据) |
|---|---|
| _all | (所有字段的连接字符串) |
| metadata | (文档元数据-出去文档真实数据意外的其他数据) |
4.2.2.添加文档
语法
PUT 索引库/文档类型/文档id
{
文档原始数据
}
案例:
PUT crm/user/11
{
"id":11,
"username":"zs"
}
解释:添加id为11的用户 , 索引库为 crm,类型为 User
注意:如果不指定文档的id,ES会自动生成文档id
4.2.3.获取文档
a.获取指定文档
GET 索引库/类型/文档ID
b.指定返回的列
GET /itsource/employee/123?_source=fullName,email
4.2.4.修改文档
a.整体修改
PUT {index}/{type}/{id}
{
修改后的内容
}
ps: 文档修改过程:1.删除旧文档,2.添加新文档
b.局部修改
POST itsource/employee/123/_update
{
"doc":{
"email" : "[email protected]",
"salary": 1000
}
}
ps:文档修改过程: 1.检索旧文档 , 2.修改文档 ,3.删除就文档 , 4.添加新文档
4.2.5.删除文档
DELETE {index}/{type}/{id}
五.文档的查询
5.1.常用查询
5.1.1.查询所有
GET _search
5.1.2.查询指定索引库
GET crm/_search
5.1.3.查询指定类型
GET crm/user/_search
5.1.4.查询指定文档
GET crm/user/11
5.1.5.批量获取
批量查询很重要,对相比单个查询来说,批量查询性能更高。
a.不同索引库查询
GET _mget
{
"docs" : [
{
"_index" : "itsource",
"_type" : "blog",
"_id" : 2
},
{
"_index" : "itsource",
"_type" : "employee",
"_id" : 1,
"_source": "email,age"
}
]
}
b.同索引库同类型 - 推荐
GET itsource/blog/_mget
{
"ids" : [ "2", "1" ]
}
5.1.6.分页查询
- size: 每页条数
- form:从多少条数据开始查
5.1.6.字符串查询
条件查询+分页+排序
GET crm/user/_search?q=age:17&size=2&from=2&sort=id:desc&_source=id,username
字符串查询(query string)其实就是在url后面以字符串的方式拼接各种查询条件,这种方式不推荐,因为条件过多,拼接起来比较麻烦
六.DSL查询与DSL过滤
6.1.基本概念
6.1.1.基本概念
DSL过滤语句和DSL查询语句非常相似,但是它们的使用目的却不同:DSL过滤查询文档的方式更像是对于我的条件"有"或者"没有"(等于 ;不等于),而DSL查询语句则像是"有多像"(模糊查询)。
6.1.2.查询与过滤的区别
DSL过滤和DSL查询在性能上的区别:
- 过滤结果可以缓存并应用到后续请求。-> 精确过滤后的结果拿去模糊查询性能高
- 查询语句同时匹配文档,计算相关性,所以更耗时,且不缓存。
- 过滤语句可有效地配合查询语句完成文档过滤。
总结:需要模糊查询的使用DSL查询 ,需要精确查询的使用DSL过滤,在开发中组合使用(组合查询) -> 关键字查询使用DSL查询,其他的都是用DSL过滤。
6.2.综合案例
6.2.1.语法介绍
GET crm/user/_search
{
"query": {
"bool": {
"must": [
{"match": {"description": "search" }}
],
"filter": {
"term": {"tags": "lucene"}
}
}
},
"from": 20,
"size": 10,
"_source": ["fullName", "age", "email"],
"sort": [{"join_date": "desc"},{"age": "asc"}]
}
解释:
query : 查询
bool : 组合查询 , 包含了 DSL查询和DSL过滤
must : 必须匹配 :与(must) 或(should) 非(must_not)
match:分词匹配查询,会对查询条件分词 , multi_match :多字段匹配
filter: 过滤条件
term:词元查询,不会对查询条件分词
from,size :分页
_source :查询结果中需要哪些列
sort:排序
6.2.2综合案例
组合搜索bool可以组合多个查询条件为一个查询对象,名称(name)中有 “娃娃” 的商品 ,价格(minPrice)在 10000- 20000之间,品牌id为 14,按照销量(saleCount)倒排序,查询第 1 页,每页10 条 ,查询结果中只需要 :id,name,minPrice,brandId
GET aigou/product/_search
{
"query":{
"bool": {
"must": [{
"match": {
"name": "春季"
}
}],
"filter": [
{
"range":{ //范围查询
"minPrice":{
"gte":10000,
"lte":20000
}
}
},
{
"term": { //词元查询
"brandId": 14
}
}
]
}
},
"from": 1,
"size": 10,
"_source": ["id", "name", "minPrice","brandId"],
"sort": [{
"saleCount": "desc"
}]
}
ps:其他查询方式
- term:单词/词元查询
- match : 分词查询(模糊匹配)
- multi_match :多字段匹配
- range:范围查询
- exists :存在
- missing : 不存在
- prefix:前缀匹配
- wildcard:通配符匹配 ,使用*代表0~N个,使用?代表1个。
七.文档的映射
7.1.基本概念
7.1.1.什么是文档映射
ES的文档映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型。
- Mysql建表过程:创建数据库 -> 创建表(指定字段类型) -> crud数据
- ES创建索引过程:创建索引库 -> 文档类型映射 -> crud文档
- 映射与分词 : 为了方便字段的检索,我么会对某些存储在ES中的字段进行分词,但是有些字段类型可以分词,有些字段类型不可以分词,所以对于字段的类型需要我们自己去指定。
7.1.2.默认的字段类型
查看索引类型的映射配置:GET {indexName}/_mapping/{typeName}
a.基本字段类型
-
字符串
text(分词), keyword(不分词) ,StringField(不分词文本),TextFiled(要分词文本) ,text默认为全文文本,keyword默认为非全文文本
-
数字(long,integer,short,double,float)
-
日期date
-
逻辑boolean
b.复杂字段类型
- 对象类型:object
- 数组类型:array
- 地理位置:geo_point,geo_shape
c.默认映射
ES在没有配置Mapping的情况下新增文档,ES会尝试对字段类型进行猜测,并动态生成字段和类型的映射关系。
| JSON type | Field type |
|---|---|
| Boolean: true or false | “boolean” |
| Whole number: 123 | “long” |
| Floating point: 123.45 | “double” |
| String, valid date:“2014-09-15” | “date” |
| String: “foo bar” | “string” |
7.1.3.映射规则
字段映射的常用属性配置列表 - 即给某个字段执行类的时候可以指定以下属性
| 属性名 | 解释 |
|---|---|
| type | 字段的类型:基本数据类型,integer,long,date,boolean,keyword,text… |
| enable | 是否启用:默认为true。 false:不能索引、不能搜索过滤。 |
| boost | 权重提升倍数:用于查询时加权计算最终的得分,比如标题中搜索到的内容比简介中搜索到的内容跟重要,那么可以提升 |
| index | 索引模式:analyzed (索引并分词,text默认模式), not_analyzed (索引不分词,keyword默认模式),no(不索引) |
| analyzer | 索引分词器:索引创建时使用的分词器,如ik_smart,ik_max_word,standard |
| search_analyzer | 搜索分词器:搜索该字段的值时,传入的查询内容的分词器。 |
| fields | 多字段索引:当对该字段需要使用多种索引模式时使用。如:城市搜索New York"city": |
"city":{
"type": "text",
"analyzer": "ik_smart",
"fields": {
"raw": {
"type": "keyword"
}
}
}
解释:相当于给 city取了一个别名 city.raw,city的类型为text , city.raw的类型为 keyword
搜索 city分词 ; 搜索city.raw 不分词那么以后搜索过滤和排序就可以使用city.raw字段名
7.2.添加映射
注意:如果索引库已经有数据了,就不能再添加映射了
7.2.1.创建新的索引库
put aigou
7.2.2.单类型创建映射
put aigou/goods/_mapping
{
"goods": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}
解释:给aigou索引库中的是goods类型创建映射 ,id指定为long类型 , name指定为text类型(要分词),analyzer分词使用ik,查询分词器也使用ik
7.2.3.多类型创建映射
PUT aigou
{
"mappings": {
"user": {
"properties": {
"id": {
"type": "integer"
},
"info": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
},
"dept": {
"properties": {
"id": {
"type": "integer"
},
....更多字段映射配置
}
}
}
}
解释:同时给user和dept创建文档映射
7.3.数组/对象映射
基本类型字段映射非常简单,直接配置对应的类型即可,但是数组和对象如何指定类型呢?
7.3.1.对象映射
{
"id" : 1,
"girl" : {
"name" : "王小花",
"age" : 22
}
}
文档映射
{
"properties": {
"id": {"type": "long"},
"girl": {
"properties":{
"name": {"type": "keyword"},
"age": {"type": "integer"}
}
}
}
}
7.3.2.数组映射
{
"id" : 1,
"hobby" : ["王小花","林志玲"]
}
文档映射
{
"properties": {
"id": {"type": "long"},
"hobby": {"type": "keyword"}
}
}
解释:数组的映射只需要映射一个元素即可,因为数组中的元素类型是一样的。
7.3.3.对象数组
{
"id" : 1,
"girl":[{"name":"林志玲","age":32},{"name":"赵丽颖","age":22}]
}
文档映射
"properties": {
"id": {
"type": "long"
},
"girl": {
"properties": {
"age": { "type": "long" },
"name": { "type": "text" }
}
}
}
7.4.全局映射
索引库中多个类型(表)的字段是有相同的映射,如所有的ID都可以指定为integer类型,基于这种思想,我们可以做全局映射,让所有的文档都使用全局文档映射。全局映射可以通过动态模板和默认设置两种方式实现。
7.4.1.默认方式:default
索引下所有的类型映射配置会继承_default_的配置,如:
PUT {indexName}
{
"mappings": {
"_default_": {
"_all": {
"enabled": false
}
},
"user": {},
"dept": {
"_all": {
"enabled": true
}
}
}
关闭默认的 _all ,dept自定义开启 all
7.4.2.动态模板
dynamic_templates
PUT _template/global_template //创建名为global_template的模板
{
"template": "*", //匹配所有索引库
"settings": { "number_of_shards": 1 }, //匹配到的索引库只创建1个主分片
"mappings": {
"_default_": {
"_all": {
"enabled": false //关闭所有类型的_all字段
},
"dynamic_templates": [
{
"string_as_text": {
"match_mapping_type": "string",//匹配类型string
"match": "*_text", //匹配字段名字以_text结尾
"mapping": {
"type": "text",//将类型为string的字段映射为text类型
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
{
"string_as_keyword": {
"match_mapping_type": "string",//匹配类型string
"mapping": {
"type": "keyword"//将类型为string的字段映射为keyword类型
}
}
}
]
}
}}
PS : 映射方式优先级 (低 -> 高):默认 -> 全局 -> 自定义
7.5.最佳实践
1.建索引库
2.全局映射
3.自定义映射
4.Java-API做CRUD
八.ElasticSearch集群
8.1.集群相关概念
8.1.1.为什么要集群
- 单节点故障
- 支持高并发
- 海量数据存储
8.1.2.ES节点类型
默认情况下,elasticsearch集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。在生产环境下,如果不修改elasticsearch节点的角色信息,在高数据量,高并发的场景下集群容易出现脑裂等问题。这些功能是由两个属性控制的。node.master 和 node.data 默认情况下这两个属性的值都是true。
| 配置 | 值 | 解释 |
|---|---|---|
| node.master | true | 是否是主节点 |
| node.data | true | 是否存储数据 |
-
主节点master
node.master=true,代表该节点有成为主资格,主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。一般会把主节点和数据节点分开,node.master=true , node.data=false
-
数据节点data
node.data=true,数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等,数据节点对CPU,IO,内存要求较高,优化节点的时候需要做状态监控,资源不够时要做节点扩充。配置:mode.master=false,mode.data=true
-
负载均衡节点client
当主节点和数据节点配置都设置为false的时候,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器。配置:mode.master=false,mode.data=false
最佳实践
在一个生产集群中我们可以对这些节点的职责进行划分,建议集群中设置3台以上的节点作为master节点,这些节点只负责成为主节点,维护整个集群的状态。再根据数据量设置一批data节点,这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大,所以在集群中建议再设置一批client节点(node.master: false node.data: false),这些节点只负责处理用户请求,实现请求转发,负载均衡等功能。
8.2.ES的集群理解
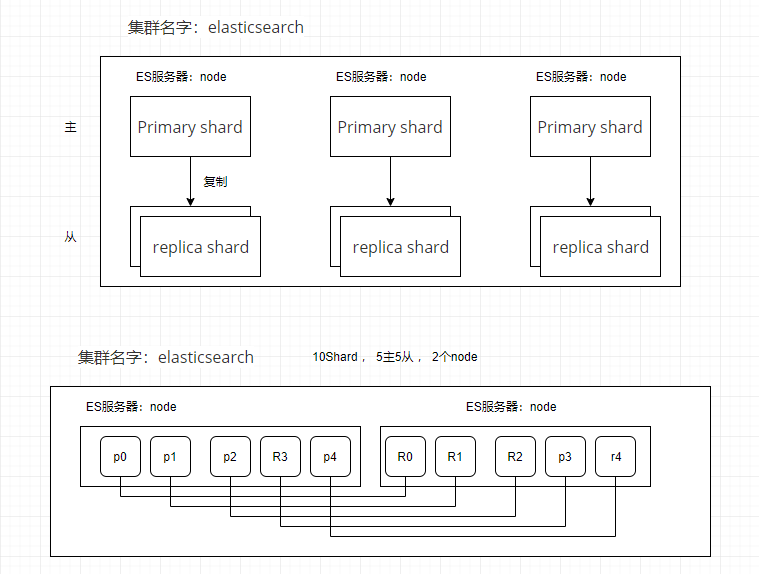
8.2.1.shard&replica机制
-
index包含多个shard,一个shard是最小工作单元,存储部分数据,完整的建立索引和处理索引的能力
-
primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
-
增减节点时,shard会自动在nodes中负载均衡
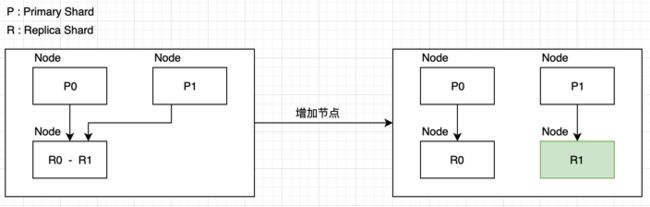
-
primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
-
replica shard是primary shard的副本,负责容错,以及承担读请求负载 - 读写分离
-
primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
-
primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
8.2.2.图解Shard分配
a.单node环境下创建index
单node环境下,创建一个index,有3个primary shard,3个replica shard
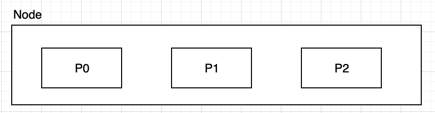
- 这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
- 集群status是yellow
- 集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
b.两个node环境下创建index
2个node环境下,创建一个index, 3个primary shard,3个replica shard
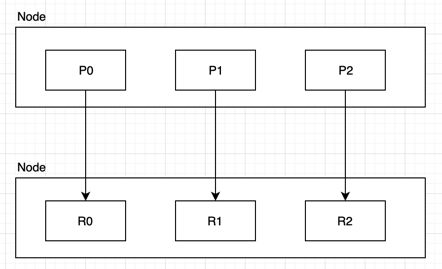
c.扩容极限,提升容错
如何让性能达到更优?
- 每个Node更少的Shard,每个Shard资源跟充沛,性能更高
- 扩容极限:6个shard(3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好
- 超出扩容极限,动态修改replica数量,9个shard(3primary,6 replica),扩容到9台机器,比3台机器时,拥有3倍的读吞吐量
8.2.3.容错机制-Master选举
-
master node宕机,自动进行master选举, - Red
当某个PrimaryShard (主分片)宕机,这个PrimaryShard的某个ReplicShard(备分片)会通过选举成为PrimaryShard。
-
Replica容错:将replica提升为新的primary shard,- yellow
新的主分片选举成功后,那么保证了主分片的完整性,但是少了一个备分片,所以状态变成了黄色
-
重启宕机节点:会生成新的ReplicShard,如果宕机前有数据,会像恢复之前的数据,然后从PrimaryShard中拷贝新的数据,这样做的好处是:1.恢复性能好 , 2.可以避免数据同步延迟造成的数据丢失问题(在宕机的一瞬间,有些数据还没同步到ReplicShard,可能会导致数据丢失)
8.3.集群搭建
8.3.1.环境准备
真实环境
| NodeName | Web端口,客户端端口 |
|---|---|
| node-1 | 172.168.1.1:9200 172.168.1.1:9300 |
| node-2 | 172.168.1.2:9200 172.168.1.2:9300 |
| node-3 | 172.168.1.3:9200 172.168.1.3:9300 |
模拟环境
| NodeName | Web端口,客户端端口 |
|---|---|
| node-1 | 127.0.0.1:9201 127.0.0.1:9301 |
| node-2 | 127.0.0.1:9202 127.0.0.1:9302 |
| node-3 | 127.0.0.1:9203 127.0.0.1:9303 |
注意:需要准备三个ES(拷贝),然后删除data目录 , 如果电脑内存不够,可以把jvm.properties中的内存设置改小
8.3.2.配置说明
- cluster.name
集群名,自定义集群名,默认为elasticsearch,建议修改,因为低版本多播模式下同一网段下相同集群名会自动加入同一集群,如生产环境这样易造成数据运维紊乱。
- node.name
节点名,同一集群下要求每个节点的节点名不一致,起到区分节点和辨认节点作用
- node.master
是否为主节点,选项为true或false,当为true时在集群启动时该节点为主节点,在宕机或任务挂掉之后会选举新的主节点,恢复后该节点依然为主节点
- node.data
是否处理数据,选项为true或false。负责数据的相关操作
- path.data
默认数据路径,可用逗号分隔多个路径
- path.logs
默认日志路径
- bootstrap.mlockall
内存锁,选项为true或false,用来确保用户在es-jvm中设置的ES_HEAP_SIZE参数内存可以使用一半以上而又不溢出
- network.host
对外暴露的host,0.0.0.0时暴露给外网
- http.port
对外访问的端口号,默认为9200,所以外界访问该节点一般为http://ip:9200/
- transport.tcp.port
集群间通信的端口号,默认为9300
- discovery.zen.ping.unicast.hosts
集群的ip集合,可指定端口,默认为9300,如 ["192.168.1.101","192.168.1.102"]
- discovery.zen.minimum_master_nodes
最少的主节点个数,为了防止脑裂,最好设置为(总结点数/2 + 1)个
- discovery.zen.ping_timeout
主节点选举超时时间设置
- gateway.recover_after_nodes
值为n,网关控制在n个节点启动之后才恢复整个集群
- node.max_local_storage_nodes
值为n,一个系统中最多启用节点个数为n
- action.destructive_requires_name
选项为true或false,删除indices是否需要现实名字
8.3.3.修改ES配置
- Node1-配置
# 统一的集群名
cluster.name: my-ealsticsearch
# 当前节点名
node.name: node-1
# 对外暴露端口使外网访问
network.host: 127.0.0.1
# 对外暴露端口
http.port: 9201
#集群间通讯端口号
transport.tcp.port: 9301
#集群的ip集合,可指定端口,默认为9300
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
- Node2-配置
# 统一的集群名
cluster.name: my-ealsticsearch
# 当前节点名
node.name: node-2
# 对外暴露端口使外网访问
network.host: 127.0.0.1
# 对外暴露端口
http.port: 9202
#集群间通讯端口号
transport.tcp.port: 9302
#集群的ip集合,可指定端口,默认为9300
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
- Node3-配置
# 统一的集群名
cluster.name: my-ealsticsearch
# 当前节点名
node.name: node-3
# 对外暴露端口使外网访问
network.host: 127.0.0.1
# 对外暴露端口
http.port: 9203
#集群间通讯端口号
transport.tcp.port: 9303
#集群的ip集合,可指定端口,默认为9300
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
分别启动三个ES节点 , 访问:http://127.0.0.1:9201/
8.4连接集群
8.4.1.修改kibana配置
elasticsearch.url: "http://localhost:9201"
连接其中一个节点自然能连接上整个集群 , 然后启动Kibana
8.4.2.集群查看命令
创建索引
PUT shopping
{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
}
}
-
GET _cat/nodes?v :查看Node
-
GET _cat/indices?v : 查看索引库
九.JavaApi操作ES
9.1.集成ES
9.1.1.导入依赖
org.elasticsearch.client
transport
5.2.2
org.apache.logging.log4j
log4j-api
2.7
org.apache.logging.log4j
log4j-core
2.7
9.1.2.连接ES
编写工具
public class ESClientUtil {
public static TransportClient getClient(){
Settings settings = Settings.builder()
.put("cluster.name","my-ealsticsearch")
.put("client.transport.sniff", true).build();
TransportClient client = null;
try {
client = new PreBuiltTransportClient(settings)
.addTransportAddress(
new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9303));
} catch (UnknownHostException e) {
e.printStackTrace();
}
return client;
}
}
9.2.文档CRUD
9.2.1.添加文档
@Test
public void testAdd() {
//获取客户端对象
TransportClient client = ESClientUtil.getClient();
//创建索引
IndexRequestBuilder indexRequestBuilder = client.prepareIndex("shopping", "user", "1");
Map data = new HashMap<>();
data.put("id",1);
data.put("username","zs");
data.put("age",11);
//获取结果
IndexResponse indexResponse = indexRequestBuilder.setSource(data).get();
System.out.println(indexResponse);
client.close();
}
9.2.2.获取文档
GetResponse response = client.prepareGet("crm", "vip", "1").get();
9.2.3.更新文档
@Test
public void testUpdate(){
//获取客户端对象
TransportClient client = ESClientUtil.getClient();
//修改索引
UpdateRequestBuilder updateRequestBuilder = client.prepareUpdate("shopping", "user", "1");
Map data = new HashMap<>();
data.put("id",1);
data.put("username","zs");
data.put("age",11);
//获取结果设置修改内容
UpdateResponse updateResponse = updateRequestBuilder.setDoc(data).get();
System.out.println(updateResponse);
client.close();
}
9.2.4.删除文档
@Test
public void testDelete(){
//获取客户端对象
TransportClient client = ESClientUtil.getClient();
DeleteRequestBuilder deleteRequestBuilder = client.prepareDelete("shopping", "user", "1");
DeleteResponse deleteResponse = deleteRequestBuilder.get();
System.out.println(deleteResponse);
client.close();
}
9.2.5.批量操作
@Test
public void testBuilkAdd(){
//获取客户端对象
TransportClient client = ESClientUtil.getClient();
BulkRequestBuilder bulkRequestBuilder = client.prepareBulk();
Map data1 = new HashMap<>();
data1.put("id",11);
data1.put("username","zs");
data1.put("age",11);
bulkRequestBuilder.add(client.prepareIndex("shopping", "user", "11").setSource(data1));
Map data2 = new HashMap<>();
data2.put("id",22);
data2.put("username","zs");
data2.put("age",11);
bulkRequestBuilder.add(client.prepareIndex("shopping", "user", "11").setSource(data2));
BulkResponse bulkItemResponses = bulkRequestBuilder.get();
Iterator iterator = bulkItemResponses.iterator();
while(iterator.hasNext()){
BulkItemResponse next = iterator.next();
System.out.println(next.getResponse());
}
client.close();
}
9.3.查询-重要
@Test
public void testSearch(){
//获取客户端对象
TransportClient client = ESClientUtil.getClient();
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("shopping");
searchRequestBuilder.setTypes("user");
searchRequestBuilder.setFrom(0);
searchRequestBuilder.setSize(10);
searchRequestBuilder.addSort("age", SortOrder.ASC);
//查询条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
List must = boolQueryBuilder.must();
must.add(QueryBuilders.matchQuery("username" , "zs"));
List filter = boolQueryBuilder.filter();
filter.add(QueryBuilders.rangeQuery("age").lte(20).gte(10));
filter.add(QueryBuilders.termQuery("id",11));
searchRequestBuilder.setQuery(boolQueryBuilder);
SearchResponse searchResponse = searchRequestBuilder.get();
SearchHits hits = searchResponse.getHits();
System.out.println("条数:"+hits.getTotalHits());
for (SearchHit hit : hits.getHits()) {
System.out.println(hit.getSource());
}
client.close();
}
十.总结
一.作业
- 文档的crud
- 索引库的curd
- DSL查询与过滤 - 手敲
- 简单的文档映射 - 手敲
- 集群的理解和搭建
- Java操作ES - 手敲
拓展
- 完成ES 批量操作 和 ES的查询
- 完成SpringBoot的HelloWorld程序
效果:通过浏览器访问,页面显示一个字符串 “hello world”
@RequestMapping("hello")
@ReponseBody
public String hello(){
return "hello world";
}
二.重点
- 文档的crud
- 字符串查询 - 能看懂就行
- 文档映射- 能看懂就行
- DSL查询与过滤
- 集群概念和搭建
- Java操作ES