“干掉”程序员饭碗后,OpenAI 又对艺术家下手了!

【CSDN 编者按】去年 OpenAI 发布了拥有 1750 亿个参数的 GPT-3,而今年 OpenAI 又发布了 GPT-3 上的重要突破:DALL·E & CLIP,或许这是 GPT-4 的热身?
整理 | 郑丽媛
出品 | CSDN(ID:CSDNnews)
AI 从上世纪 50 年代首次提出,经过几十年的发展已愈发先进。目前 AI 客服对于人工的替代率已高达 90% 以上,GPT-2 续写的权游结局,似乎比原著更好,GPT-3 更是能直接把需求变成代码,直抢程序员饭碗!
而刚步入 2021 年,继“威逼”客服、作家、程序员之后,人工智能非营利组织 OpenAI 昨日发布的 DALL·E 和 CLIP 两个模型,又让艺术家们开始头疼了。CLIP 能根据视觉类别名称自己分类图像已经让人叹服,没想到 DALL·E 居然可以用一句话就生成对应图像!
CSDN 博客专家马超(从事金融 IT 行业超十年,阿里云 MVP、华为云 MVP、华为 2020 年技术社区开发者之星)评价道:
DALL·E 带给我们震撼在于这是一种跨模态的生成模型,之前不管是 pix2pix,DeepFake 还是大谷老师修复老北京的影像,AI 还只能在图像或者文字的单模态下进行生成和模仿.
跨模态模型像 B 站的弹幕和图像的模型只能做到认知,通过弹幕理解图像的含义,通过文字直接脑补出图像来,之前闻所未闻,从这次 DALL·E 展示出的能力来看,其联想能力已经接近人类四岁的儿童,而且在未来继续扩大参数规模的情况下,还展示出 AI 的无限可能,这出不禁让我们想尽 AI 的边界到底在哪?

一句话生成对应图像的 DALL·E

DALL·E 这个名字取自艺术家萨尔瓦多·达利(Salvador Dalí)和皮克斯动画工作室(Pixar)的《机器人总动员》 (WALL·E), 是 GPT-3 的 120 亿参数版本。它将计算机视觉和自然语言处理(NLP)相结合,经过文本-图像对数据集的训练,即可通过给定的简短文本生成匹配的图像。
与 GPT-3 一样,DALL·E 也是一种 Transformer 语言模型,以包含多达1280 个 tokens (类似于每个英文字母都是26个字母中的一个 token,而在 DALL·E 中,图像使用 1024 个 tokens,文本最多使用 256 个 BPE 编码 tokens)的单个数据流同时接收文本和图像,利用最大似然法(使用概率模型,寻找能够以较高概率产生观察数据的系统发生树)训练并一个接一个地生成所有 tokens。

由文本“写着 OpenAI 的店面”DALL·E 生成的图像
为了测试 DALL·E 处理新概念的能力,OpenAI 研究人员还给了一些实际上并不存在的描述,例如“竖琴做成的蜗牛”和“鳄梨扶手椅”。意外的是,DALL·E 可以将图像中的物体进行操作和重新排列,把一些无关的概念以合理的方式进行组合并应用到现有图像上。

由文本“鳄梨扶手椅”DALL·E 生成的图像
但这种结合的成功率也需视情况而定。或许由于鳄梨的横截面本就形似高背扶手椅,果核可看做抱枕,因此 DALL·E 生成的图片并无违和感。可将文字描述换成“竖琴做成的蜗牛”,生成的图片就仅仅是将蜗牛与竖琴生硬地结合在一起。

由文本“竖琴做成的蜗牛”DALL·E 生成的图像
除此之外,经测试还发现 DALL·E 具有创建拟人化动物及物体形象,它会将某些人类的活动和衣物转移到动物和无生命的物体上,还能以合理的方式组合不同的动物。

由文本“一个穿着芭蕾舞裙遛狗的小白萝卜”DALL·E 生成的图像

由文本“一个长颈鹿做成的乌龟”DALL·E 生成的图像
但同时,DALL·E 也存在一些不足。通过研究人员控制文字描述属性观测 DALL·E 所生成的图像看来,DALL·E 对于少量的属性表述还可以较为准确地把控,可一旦描述的属性过多,或者出现容易混淆的措辞和颜色之间的关联,生成正确图片的成功率就会大幅降低。此外,DALL·E 处理描述文字的变动也不太灵活:有时用语义相同的描述替换,结果却得不到正确的图片了。

由文本“戴蓝色帽子、红色手套,穿绿色衬衫和黄色裤子的小企鹅表情符号”DALL·E 生成的图像
不过,瑕不掩瑜。通过 OpenAI 对 DALL·E 进行的全方面探测,DALL·E 还具备以下几个功能:
可以控制场景视角,将场景渲染成 3D 风格;
内部和外部结构可视化;
能推断背景细节进行图像调整;
零样本视觉推理,可根据虚拟图像得到草图;
具备地理知识,可根据文本指示生成相应地区有关图像。
除了 DALL·E ,OpenAI 还发布了一款连接文本和图像的多模态模型 CLIP (Contrastive Language–Image Pre-training) 。DALL·E 生成的图片排序正是由 CLIP 决定,它将对生成的图片进行区分,越符合文本的图片排序越前,而这又是如何实现的呢?

零样本学习的 CLIP

CLIP 能有效地从自然语言监督中学习视觉概念,只需提供识别的视觉类别名称,就可将 CLIP 应用于视觉分类基准,类似于 GPT-2 和 GPT-3 的“零样本”功能。
设计团队采用了大量可用的数据:文本和与之匹配的图像。该数据用于为 CLIP 创建代理训练任务:给定一幅图像,预测在 32768 个随机采样的文本数据集中与哪一个片段更匹配。以下是 CLIP 框架结构图:
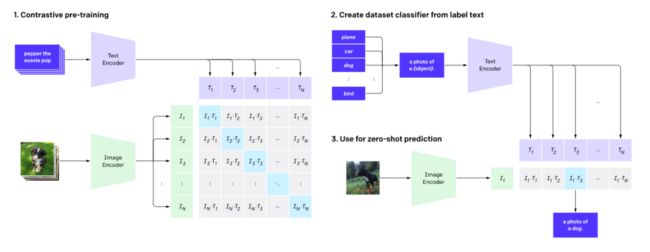
CLIP 提前训练图像编码器和文本编码器,以预测数据集中哪些图像与哪些文本相匹配;然后,利用结果将 CLIP 转换为 zero-shot 分类器;最后,将数据集的所有类别转换成文字 ,并预测文本的类别与给定图像的最佳对应关系。
CLIP 的开发主要是为了解决基于深度学习计算机视觉中的一些问题:
数据集昂贵:深度学习需要大量的数据,而视觉模型一般都是在构建成本高昂的人工标记数据集上进行训练。以 ImageNet 数据集为例,需要 25,000 多名工作人员为 22,000 个对象类别注释 1400 万张图像。但 CLIP 可以从互联网上已经公开可用的文本图像对中学习。
适用范围狭窄:还是以 ImageNet 模型为例,虽然它可以很好地预测 1000 种 ImageNet 类别,但想要执行新的任务就需要再构建一个新的数据集并对模型进行微调。而 CLIP 可适用于执行各种视觉分类任务,而无需其他训练样本。
实际应用不佳:据报道,深度学习系统在测试时,通常可以达到甚至超越人类的视觉基准,可一旦投入实际使用,其性能就大打折扣。这种仿佛是“基准绩效”与“实际绩效”之间的差异,可能是因为模型只优化了基准性能来“欺骗”大众,就像一个临时抱佛脚的学生,仅研究过去几年考试中的问题去通过考试。相反,CLIP 模型可以在基准上进行评估,而不必训练其数据,它的基准性能更接近它的实际性能。
CLIP 本身是一个高效,并且灵活通用的多模态模型,但事无完美,它也存在一些局限。虽然 CLIP 在识别常见对象方面可圈可点,但面对抽象或系统性任务(计算图像中的对象数量)或复杂的任务(计算图像中最近的汽车的距离)时,误差也较大。此外,CLIP 对于在训练数据集中未涵盖的图像概括性较差。即使 CLIP 学习了功能强大的 OCR 系统,但面对 MNIST 数据集进行评估时,准确率只有 88%,远低于数据集中 99.75% 的人类。最后,CLIP 的 zero-shot 分类器可能对文本或措辞较为敏感。

你怎么看?
OpenAI 推出的这两个模型,很快就登上了 Techmeme 的首页,也在 Hacker News 冲上第二名,引起了许多讨论。


评论1:
人类能通过少量的示例来推断和理解一些抽象概念,但 AI 看起来似乎并不行。

评论2:
我预测 2050 年时,我们的手机将有很高的“智商”,能对周围的世界有深刻的理解(不论是语言还是视觉方面)。

评论3:
我希望这是一个人人都能使用的工具!
![]()
OpenAI 联合创始人&首席科学家 Ilya Sutskever 曾在吴恩达编辑的 The Batch 周刊 2020 年终特刊里写到:“2021 年,语言模型将开始了解视觉世界。”此次新年刚过便推出的 DALL·E 和 CLIP 也印证了他的话,同时让人工智能更进一步理解人类的日常概念。对此,你有什么看法吗?欢迎评论区留言~
参考链接:
https://openai.com/blog/dall-e/
https://www.technologyreview.com/2021/01/05/1015754/avocado-armchair-future-ai-openai-deep-learning-nlp-gpt3-computer-vision-common-sense/

大洋彼岸,川普又在搞事情了。继封禁抖音海外版“Tiktok"之后,特朗普在下台倒计时的第14天亲手封禁了支付宝、QQ、微信支付、WPS 等 8 款常用的中国 App。对于美国再度封禁中国八款应用,你怎么看?点击下方 B 站小程序即可立即观看!
更多精彩推荐
☞清华毕业生最爱去华为;应届生称因拒绝加班,被申通快递辞退;PrestoSQL被迫更名 | 极客头条
☞IntelliJ IDEA、Kotlin、PyCharm 背后公司 JetBrains 遭美国调查!
☞GitHub 宣布拆“墙”,恢复伊朗开发者使用权!
☞突发!美国封禁支付宝、QQ、微信支付、WPS 等 8 款中国 App
☞如何用一句话证明你是程序员?
☞Linux之父新年首次“炮轰”:英特尔在扼杀整个ECC行业
点分享点收藏点点赞点在看