【腾讯开发者大会】天刀手游开发历程(笔记)
前言
最近腾讯游戏学院发布了一些游戏行业内大佬们的分享视频,观看这些视频,我们可以了解到行业内最新的一些技术知识等,以便提升自己的水平。之前也看到天刀手游是基于Unity制作的,同时自己也作为一名天刀游戏的玩家,碰见看见有关天刀手游的技术分享,因此必然要学习学习,了解大佬们的核心先进技术。
链接:https://www.bilibili.com/video/BV1EZ4y137db?p=6
本文目前基本仅仅只是对视频的内容的抄录,因为视频大部分提到的知识都没有接触过(唉!),无法跟进一步的拓展来说。以后有时间一定好好研究一番,同时若后续项目需要,也可以以此作为一个研究方向的参考。
手游研发的三要素
画质,帧率,功耗(pc可以不考虑),三者协调。例如当我们的帧率达到一个预估值后,我们可以再努力提升画质。当画质提升后,必然会造成帧率的下降以及功耗的提升,因此我们需要再优化帧率以及功耗。通过这种方式来达到三者平衡以及不断的拔高。

利用各种技术栈来优化
在游戏开发中,我们往往需要各种优化来提升性能,这点是非常非常重要的。视频中的大部分内容介绍的也就是如果通过各种技术栈,来获得更好的优化效果。

天刀手游主要用到了如下几个技术点来进行优化:
- 对多线程渲染引擎,进行优化,把大部分可以并行的工作,比如动画、布料,放到其他的线程去运行。
- 使用ISPC,来自动生成NeonSIMD的代码,这部分代码可以更好地提升CPU的执行效率。
- 在GPU和CPU的遮挡剔除中,使用不同粒度的遮挡剔除算法,首先启用了Vulkan API,通过它来对GPU的内存进行更好的粒度上的管理。
- 实现了GPU Driven的渲染管线,用compute来辅助优化各项其他的渲染技术。
- 在画面上使用了PBR的材质,使用了真实的物理单位的lighting,获得更好的HDR的画面效果。
在开发过程中,经历了多线程的优化,发现了在做手机平台上的一个优化甜区。即手机的多核要比我们在端游时代开发的时候更早的进入了多核时代。现在很多安卓手机都是4+4的多核架构(像更早时候在主机平台上看到的,如xbox360,ps3),在这些架构下,都是以能让开发者更多的使用这些辅助的计算单元,来提升计算效率。因此有两个大方向:
- 尽可能剥离主线程上的计算,通过dispatch到小核上,dispatch到其他线程上,来提升它的计算效率。
- 把计算转入GPU Compute。
做优化时,团队要有一个非常好的基础,这个基础来源于我们在于从多线程开始,意识到整个计算体系,应该不同的去往compute方向,或者往其他线程方向去使用。通过减少主线程的开销成本,来去提升整个游戏的性能效率。
多线程的框架改动
对Unity进行了多线程的框架改动,把渲染线程和提交线程从主线程中剥离出来。因为在手游的开发环境里,一个主线程的持续工作会带来手机芯片的功率提升,这会带来更多的发热。
Vulkan API
官网:https://www.khronos.org/vulkan/
相关文献:https://vkguide.dev/
Vulkan是数字图形技术产业诞生的一个全新图形接口项目,它类似于OpenGL和Direct3D,并且在某些领域上要优于这两者。Vulkan针对高性能的实时3D应用,如跨平台的各类3D游戏和交互软件,并提供更好的性能和更低的CPU占用率,而且在多核CPU协同负载运行更加优秀。
天刀手游也引入了Vulkan API,它相对于OpenGLES来说的话,有着更好的,更轻量级的调用。进过他们的测试,可以做到在提交线程上获得30%的CPU的效率提升。
同时Vulkan API是更加自由的开发方式,可以在其中进行各种各样的优化。例如对一些比较重的Vulkan API操作,像Descriptor Set的绑定,Layout的绑定,都可以采用一些Cache的方式来去做。Vulkan API的灵活性可以使得开发时获得更好的解法。
GPU Compute
GPU Compute即Compute Shader,在它的帮助下,程序员可直接将GPU作为并行处理器加以利用,GPU将不仅具有3D渲染能力,也具有其他的运算能力。在前面的Vulkan以及后面的GPU Driven的相关文献中,都有所介绍。
视频中的解读如下:
- 它首先是一个现代渲染框架的一个基石,除了GPU进行光栅化处理的部分之外,compute能够完成大量的GPU的渲染流程上的操作,包括计算光照,计算材质等等。另外值得注意的是,compute的渲染语言,其实是完全能和GPU本身的硬件对应起来,例如Local Data Storage机制,例如ThreadGroup和Thread利用率的概念,这两个都能很好的在compute语言上表现出来。
- 使用compute能够发挥Vulkan更大的潜力,因为我们可以使用Vulkan对GPU的同步行为做出非常好的控制。而compute作为一个独立的单元,我们可以把compute的计算很好的和GPU的其他计算并行起来,例如compute可以和一个带宽优先的(像shadow pass)进行并行。另外compute是一个单独的Queue,我们可以对比vs和ps的整套pipeline来说,它是一个非常简化的单元,非常容易到处去摆放的。
- 采用compute的话,可以给GPU Driven和Bindless打开更广阔的优化空间。我们甚至可以使用Async compute的方式来更进一步的并行compute和GPU的单元。
- 对天刀手游而言,打开compute的关键突破点就是GPU Driven的地形系统。

GPU Driven
参考文献:https://www.raywenderlich.com/books/metal-by-tutorials/v2.0/chapters/15-gpu-driven-rendering#toc-chapter-018-anchor-001
https://zhuanlan.zhihu.com/p/37084925
天刀手游同时也引入了GPU Driven的技术,通过它可以把大部分CPU上的工作转移到GPU上去运行。不仅提升了GPU的效率,也减少了从GPU到CPU之间的各种传递的带宽。这项技术可以运用在地形上,以及草和植被上,同时在家园里也运用了这些效果。
何为GPU Driven Pipeline?
首先是GPU掌握实际的渲染控制,可以提供更细致的渲染力度。例如我们在做渲染剔除的时候,CPU只能控制在object level,使用Object Bounding来去做剔除。我们在GPU这个层面上,可以做到更进一步的控制,我们可以在Mesh cluster级别上,通过切分Mesh来获得更好的力度控制。
另外一个好处是,它不需要GPU和CPU之间的数据来回传递,在理想情况下,GPU Driven甚至可以使用一个drawcall来绘制完整个场景。当然了,这个需要compute shader的支持以及indirect drawing相关api的提供。在Vulkan1.0的情况下都可以拿到相关的支持。

行业发展
在最近几年里,GPU Driven其实是一个相对来说比较热门的研发方向。以下是历年来的一些参考文献:
- siggraph15
ubisoft:主要是讲《刺客信条:大革命》的开发。 - gdc16
EA frostbite:EA的寒霜引擎(Frostbite Engine)也提到了GPU Driven的pipeline。 - gdc18
ubisoft - gdc19
ubisoft
但是在手机的领域上,目前还没有一些技术能够真正在在线的产品中体现出来。

天刀手游中的运用
首先介绍下CPU地形常用的算法,在天刀手游上个版本里的地形算法是CPU端的Geometry Clipmap算法,它采用的裁剪剔除方式是视锥的裁剪剔除方式。对比GPU Driven来说的话,它少了depth剔除。并且它的计算LOD的方式是根据距离计算的,而GPU Driven可以根据距离和地形块的复杂度来计算。送入clipmap方式的顶点处,因为有两个pass,其中一个要通过Virtual Texture来使用,这样的话它是需要21万*2的顶点数。而GPU Driven情况下,因为获得比较好的剔除效果,它只需要8万6的顶点数。
此外,在GPU Driven情况下在iphone8p上可以获得2.9ms的时间开销,这比通过CPU的方式下,节省了近四分之一的成本。而在CPU端获得的收益更大,我们提交线程和渲染线程,每个都可以获得5ms以上的收益。
下图即是两者的对比:

使用流程
它主要包含GPU Driven和Virtual Texture两个算法,它们的实现有着互相的交叉。出于简化,视频只介绍一下GPU Driven相关流程上的一些算法。
- 首先是一个深度的mips生成,这部分算法是在compute里面实现的。
- 其次我们在compute里面实现GPU遮挡剔除,使用上一步制作的深度缓冲buffer。GPU的遮挡剔除主要是通过计算你送入的patche的尺寸,看它处在哪一级的深度缓冲上,然后来对比这一级深度缓冲的深度和你的深度,来决定是否被depth剔除掉。
- 通过这个流程我们可以获得可视的patches数目,然后根据这些可视的patches数目,仍然通过compute用来做indirect的Arguments的buffer来生成出来。
- 将这些准备好的indirect buffer给绘制出去。

Hiz Buffer(Hierarchical Z-Buffer)Occlusion Culling 优化
有一个非常重要的优化,也是在compute上可以达成的。该优化主要是利用compute里面的一个Thread shared memory的方式来做。这个优化它减少了对于CPU和GPU之间的多次的dispatch,减少了binding memory pingpong操作。它能应用的范围主要在于对你的buffer做filter,例如我们经常在渲染管线中提到的bloom,高斯模糊以及自动曝光等,这些对于区域进行filter的操作都可以获得优化。
应用
首先会做第一次的dispatch,这个dispatch会产生16*16的线程组,每组128条线程。我们这128条线程读入深度放入mips里。
第二步通过同步的方式,再把上一级的mips相邻的四个点取出来,合并选择最深的单位,写到第二级的mips里,然后以此类推,完成四级的写出。
在第二个dispatch里,用同样的方法,dispatch一个线程组,128条线程。同样的把后面的32*16的mips写入完成。

LOD优化
在Farcry的实现里面,它主要采用的是CPU四叉树的方式来组织LOD的patches。根据距离更新四叉树上的节点,然后根据相机的距离选择这些节点,送入GPU进行indirect buffer和GPU Culling。
对于天刀手游来说,我们把这些patch信息先通过offline的方式bake出来,我们在每个相机发生位置变化的时候,会去更新这些bake出来的信息。根据这些信息,我们会去对改变的patch做过滤,然后生成新的indirect buffer。

应用
第一步,读到了所有的patches的属性。
第二步,根据视锥裁剪,获得视锥裁剪之后的结果。
第三步,再用HiZ产生的depth,产生一次depth裁剪。
这三步完成后,我们就可以生成Indirect Draw Arguments的buffer,将其dispatch出去。

GPU Driven的其他应用
除了地形以外,GPU Driven还可以应用在草地以及家园等系统中。
应用 Grass(场景的植被管理)
有经验的渲染程序可能直接会意识到这一点。草的geometry和地形的patch或者是sector的管理是一个非常类似的概念,他们都有LOD,都有不同的geometry的表现。绘制这些geometry LOD的时候,最好的方法是通过Multi Draw Instanced Indirect的方案来做。
另外一点这些草的Texture,每种草的Texture它其实对应在地形上更像是一个地形的Virtual Texture机制。我们也可以用bindless的方式去做绑定。可是在Vulkan 1.0 的平台情况下,我们这两个API,Multi Draw Instanced Indirect或者是bindless,都没办法获得更好的支持。因此在天刀手游的实现里,我们只能采用将草的每种类型完成一次GPU Driven的culling和Draw Indirect Buffer的生成。

应用家园渲染
在家园的玩法里头,主要是可以让玩家尽可能多的定制我们整个家园的地形,地表,墙壁,物件,地板等等。在这个层面上,我们知道,它其实是需求非常多的geometry类型。第二它的区域相对来说比较小,只有128m*128m的自定义空间,而在这种小的自定义空间的情况下,遮挡剔除必须要做的非常好的一种技术。这两点来看,GPU Driven非常非常的适合应用在家园渲染的情况下。
问题在于家园里的这些物件其实和草的类型一样,都非常依赖于Multi Draw Instanced Indirect和bindless这两种api的实现。对天刀手游来说只能退而求其次,利用地形步骤算出来的HiZ buffer做遮挡剔除,我们送入一套做遮挡剔除buffer的内容,然后通过CPU从readback的方案来获得这些buffer的遮挡剔除结果,然后在CPU端组织尽量多的instance对象。即使采用这样的方式,在家园渲染情况下,也获得了比较好的渲染效率。

光照的优化
修改和提升了整体的光照表达,引入了自动曝光,提升了Tone mapping(把HDR变成LDR的过程)的效果。解决了由于真实物理单位引入之后,在不同的光照环境下lighting体现的一些细节的颜色丢失的问题。并且重新对sky lighting进行了定义,使得整个场景的室外表现更加丰富和具有对比度。
Compute的尝试
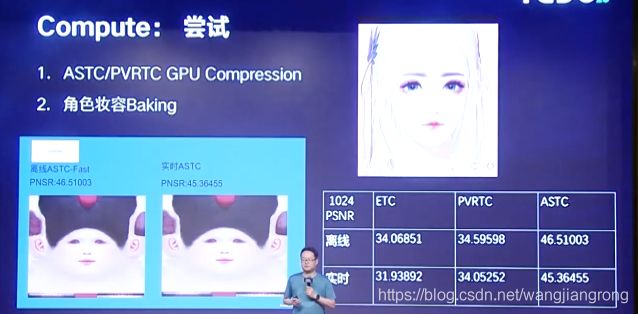
在完成了compute的基础机制上,进行了其他的尝试。其中一条是,完成了在ASTC和PVRTC的GPU实时压缩。这个也是通过GPU compute来实现的,这个功能可以用在角色的妆容系统上。
妆容系统
在天刀手游中,整个角色他的妆容系统是需要完成多个Feature的绘制,如果不能很好的baking到一张贴图上,在实时渲染的情况下,它会产生更多的一些开销。在实时baking到贴图上,我们还希望它能够尽量去做压缩,来减少内存的使用。测试了一些compute compression的效果,在PSNR和效率上都能获得比较好的表现
尝试Virtual Texture Compression
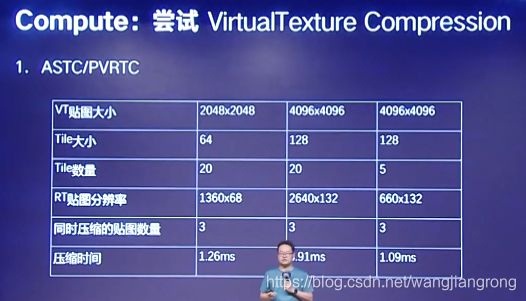
尝试了对于Virtual Texture的压缩,前面提到地形的Virtual Texture技术,是需要更新大量的地形块数据。越多的地形块数据,才能使你更新的频率变低。
在天刀手游中,我们使用2048*2048,三张不经压缩的材质。我们通过调整贴图的尺寸,大小,数量以及压缩方式。基本上能够把大张贴图的压缩时间控制在4ms以下,可以达到使用的效果。

远处来看,地表材质很难观察到差异性,这种算法对比了一下它的细节表现,我们仍然可以看到压缩后是有一些Blocking的瑕疵(如下图)。这样的瑕疵在天刀手游的画面品质下是不能接受的。因此该方案被放弃。

尝试Cluster deferred
尝试了Cluster deferred,它主要应用于家园室内场景。该场景,它首先是一个封闭的空间,有大量的动态的物体,动态的光照效果。下图中的图片中大概有55盏灯,从左上角的一张蓝色背景图来看这个区域被多少光源照亮的情况。最多的话可能是8盏灯以上的照亮。
在这个技术方案实现之后,发现仍然解决不了几个问题
第一个问题就是deferred本身带有的问题,即它的带宽问题,需要更好的设计GBuffer搁置。也需要去应用一些API,例如subpass,或者一些更好的pass combine的操作。
第二个问题在于它材质的复杂度,一个deferred的材质和forward的材质,在整个大世界的使用,是很难做兼容融合的。这个也增大了shader的复杂度以及工作量。
这个方向对未来也许是一个比较好的技术点,但是在现有的架构下还是不够成熟,该方案也被放弃。
