python的Tesseract-OCR-04-识别,使用jTessBoxEditor 提高数字验证码识别准确率
python的Tesseract-OCR-04-识别,使用jTessBoxEditor 提高数字验证码识别准确率
文章目录
- 前言
- 一、训练图库的生成
-
- 1.生成训练图库
- 2.图像读取以及二值化
- 3.形态学操作
- 4.保存图像以及批量生成
- 二、数字验证码识别
-
- 1.安装训练工具
- 2.获取训练图库
- 3.Merge样本文件
- 4.生成BOX文件
- 5.字符配置文件
- 6.编辑字符
- 7.执行批处理文件
- 7.移动num.traineddata文件
- 三、识别数字验证码
- 四、总结
前言
第二次写博文了,也可以说是自己的学习笔记,希望对你们也有帮助,有问题有错误,欢迎指正,我都会一一更正,谢谢各位。
文章可能会稍微比较长,我会分成三个部分来介绍:训练图库的生成、训练图库、数字验证码的识别。
一、训练图库的生成
首先就是批量生成数字验证码这部分的操作以及代码的实现我都在我的另一个文章中写了,我就不过多赘述了,下面的链接就是了。
https://blog.csdn.net/weixin_46874767/article/details/111406957
1.生成训练图库
因为有之前的代码作为基础,所以可以接着之前已经编写过的代码直接生成批量的训练图像,因为数字验证码都带有噪点和噪线,所以需要进行形态学操作,将噪点和噪线去除掉。
代码最好是结合之前自动生成数字验证码一起来看,我这里就不贴出完整的代码,如果想要完整的代码可以直接在评论区那里说一下,也可以直接找我,
代码如下(示例):
# 读取图像以及二值化
image = cv.imread(r'G:\image1\noise_verification code\%s.png' %name, cv.IMREAD_GRAYSCALE)
ret, binary = cv.threshold(image, 225, 255, cv.THRESH_BINARY_INV)
#形态学操作
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
bin1 = cv.morphologyEx(binary, cv.MORPH_OPEN, kernel)
# cv.imshow('image1', bin1)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
bin2 = cv.morphologyEx(bin1, cv.MORPH_CLOSE, kernel)
# cv.imshow('image2', bin2)
cv.waitKey(0)
cv.bitwise_not(bin2, bin2)
#保存图像
cv.imwrite(r'G:\image1\train2\%s.tif' % name, bin2)
#循环生成训练图像,想要多少张就循环多少次,
for i in range(30):
generate_image()
2.图像读取以及二值化
首先就是读取图像,读取之前已经生成好的带有噪点噪线的数字验证码图像,这一步就不过多介绍了。
3.形态学操作
上面用到的形态学是开操作和闭操作,首先就是生成一个卷积核,
第一个参数是卷积核的形状,这里选择矩形就可以
第二个参数卷积核大小,因为我们这里的图像不是很大,而且噪声噪点也不多所以就(2,2)或(3,3)大小的卷积核就够了,我这里选了(2,2)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
然后就开闭操作,开闭操作可以理解成也是腐蚀膨胀的一种,但是他们的腐蚀膨胀的程度比直接腐蚀膨胀会稍微弱一点。先使用开操作将噪点噪线去除掉,然后再进行闭操作恢复数字的形状,
bin1 = cv.morphologyEx(binary, cv.MORPH_OPEN, kernel)
# cv.imshow('image1', bin1)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
bin2 = cv.morphologyEx(bin1, cv.MORPH_CLOSE, kernel)
4.保存图像以及批量生成
cv.imwrite(r'G:\image1\train2\%s.tif' % name, bin2)
#循环生成训练图像,想要多少张就循环多少次,
for i in range(30):
generate_image()
二、数字验证码识别
这一步的内容是文章的重点,步骤也会比较多。下面我会细讲
.
1.安装训练工具
安装 jTessBoxEditor:
官方网址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/

在使用jTessBoxEditor之前需要安装JRE,因为这是由JAVA开发的,
JRE下载官网:http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
按照自己的电脑情况来进行下载。
jTessBoxEditor下载完之后不用进行安装直接解压就好了。
2.获取训练图库
就是第上面的第一章:获取训练图库。
3.Merge样本文件
在你解压jTessBoxEditor的地址,找到一个train.bat双击打开,点击Tools>>Merge TIFF
按住ctrl键,选择你所有的样本图像,然后点击打开
之后合并保存,为了方便 tif文面命名格式[lang].[fontname].exp[num].tif
lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式
例如和可以命名成num.font.exp[0].tif
4.生成BOX文件
打开cmd命令,切换到你图像保存的位置。

输入下面的命令:
tesseract num.font.exp[0].tif num.font.exp[0] batch.nochop makebox
在训练图库中就会生成一个box文件

5.字符配置文件
在文件夹内,新建一个文本文件,名为font_properties,记住不要带后缀,用记事本打开,写入内容为:
font 0 0 0 0 0
【语法】:fontname italic bold fixed serif fraktur
【语法】:fontname为字体名称,italic为斜体,bold为黑体字,
fixed为默认字体,serif为衬线字体,fraktur德文黑字体,
1和0代表有和无,精细区分时可使用
6.编辑字符
打开 jTessBoxEditor,依次点击Box Editor、Open,选择num.font.exp[0].tif文件打开
将每一张训练图像都进行校正,主要有两个方向,一个就是char,还有一个就是字符框的大小。

训练完成之后记得保存
替换掉之前的box文件,
7.执行批处理文件
在目标目录下,新建一个txt文件,复制代码,重命名为 do.bat,直接更改后缀名就可以
代码如下
echo Run Tesseract for Training..
tesseract.exe num.font.exp[0].tif num.font.exp[0] nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp[0].box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp[0].tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
执行完do.bat文件之后,会生成很多文件

7.移动num.traineddata文件
把num.traineddata文件移动到Tesseract-OCR 安装目录下的 tessdata 文件夹

至此训练的步骤以及完成了,距离胜利还差一步就是识别了。
三、识别数字验证码
直接给出代码:
for path in paths:
image = cv.imread(path, cv.IMREAD_GRAYSCALE)
ret, binary = cv.threshold(image, 225, 255, cv.THRESH_BINARY_INV)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
bin1 = cv.morphologyEx(binary, cv.MORPH_OPEN, kernel)
# cv.imshow('image1', bin1)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
bin2 = cv.morphologyEx(bin1, cv.MORPH_CLOSE, kernel)
# cv.imshow('image2', bin2)
cv.waitKey()
cv.bitwise_not(bin2, bin2)
textImage = Image.fromarray(bin2)
text = tess.image_to_string(textImage, lang='num')
number.append(text)
# 保存识别出来的数字
with open(r"G:\image1\noise_verification code\result.txt", 'w', encoding='UTF-8') as f:
for i in range(30):
f.write(number[i])
着重了解这句代码:
第一个参数:就是你要识别的图像,一般是二值化图像,识别前景区域(即白色区域)
第二个参数:就是你要使用的语言,也就是你训练之后得到的语言,在上述的2.7章节那里的文件
text = tess.image_to_string(textImage, lang='train')
最后的效果图如下:基本都可以识别出来,也不会有错误,(至于其中的横线就使需要形态学的优化了),而且程序执行的时间也很快
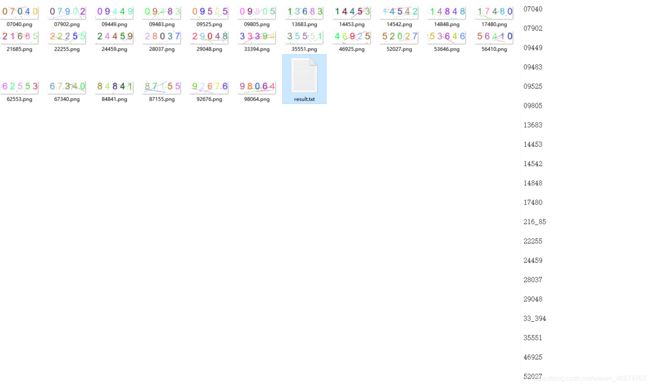

下面是不训练,直接识别的效果:


四、总结
对比过后,效果不言而喻,经过训练之后识别的速度也有提升,准确率也很高,当然形态学部分的去噪点噪声就是需要优化的部分了。
因为文章内容比较多,也是一次性写完的,难免会有错误,或者纰漏之处,欢迎在评论区指出,我都会一一改正