有些东西,当你即将失去了的时候,你才懂得它的弥足珍贵,也许亡羊补牢,为时未晚!
建议67:不同的列表选择不同的遍历算法
测试来看简单for循环比foreach能快那么一丢丢。
建议68:频繁插入和删除时使用LinkedList
ArrayList在进行插入元素时:
public void add(int index, E element) {
//检查下标是否越界
rangeCheckForAdd(index);
//若需要扩容,则增大底层数组的长度
ensureCapacityInternal(size + 1); // Increments modCount!!
//给index下标之后的元素(包括当前元素)的下标加1,空出index位置
System.arraycopy(elementData, index, elementData, index + 1,size - index);
//赋值index位置元素
elementData[index] = element;
//列表长度加1
size++;
}注意看arrayCopy方法,只要插入一个元素,其后的元素就会向后移动一位,虽然arrayCopy是一个本地方法,效率非常高,但频繁的插入,每次后面的元素都要拷贝一遍,效率变的就低了。而使用LinkedList就显得更好了,LinkedList是一个双向列表,它的插入只是修改了相邻元素的next和previous引用。
原理不说了。
修改元素:LinkedList不如ArrayList,因为LinkedList是按顺序存储的,因此定位元素必然是一个遍历过程,效率大打折扣。而ArrayList的修改动作是数组元素的直接替换,简单高效。
LinkedList:删除和插入效率高;ArrayList:修改元素效率高。
建议69:列表相等只关心元素数据
判断集合是否相等只须关注元素是否相等即可,不用看容器
建议70:子列表只是原列表的一个视图
List接口提供了subList方法,其作用是返回一个列表的子列表,这与String类subSting有点类似。
注意:subList产生的列表只是一个视图,所有的修改动作直接作用于原列表。
建议71:推荐使用subList处理局部列表
我们来看这样一个简单的需求:一个列表有100个元素,现在要删除索引位置为20~30的元素。这很简单,一个遍历很快就可以完成,代码如下:
public class Client71 {
public static void main(String[] args) {
// 初始化一个固定长度,不可变列表
List initData = Collections.nCopies(100, 0);
// 转换为可变列表
List list = new ArrayList(initData);
// 遍历,删除符合条件的元素
for (int i = 0; i < list.size(); i++) {
if (i >= 20 && i < 30) {
list.remove(i);
}
}
}
} 这段代码很符合我的风格!
下面用subList解决这个问题:
public static void main(String[] args) {
// 初始化一个固定长度,不可变列表
List initData = Collections.nCopies(100, 0);
// 转换为可变列表
List list = new ArrayList(initData);
//删除指定范围内的元素
list.subList(20, 30).clear();
} 建议72:生成子列表后不要再操作原列表
注意:subList生成子列表后,保持原列表的只读状态。
建议73:使用Comparator进行排序
1、默认排序
Collections.sort(list)
2、按某字段排序
Collections.sort(list,new PositionComparator())
知道这些就行了,原文写的太晦涩了,我感觉没啥用!
想了解更多的使用Comparator进行排序
建议74:不推荐使用binarySearch对列表进行检索
不推荐,干脆就不要写了,好吗?
对列表进行检索就使用indexOf就挺好的!
public class Client74 {
public static void main(String[] args) {
List cities = new ArrayList ();
cities.add("上海");
cities.add("广州");
cities.add("广州");
cities.add("北京");
cities.add("天津");
//indexOf取得索引值
int index1= cities.indexOf("广州");
//binarySearch找到索引值
int index2= Collections.binarySearch(cities, "广州");
System.out.println("索引值(indexOf):"+index1);
System.out.println("索引值(binarySearch):"+index2);
}
} binarySearch采用的是二分法搜索的Java版实现。从中间开始搜索,结果肯定是2了。
使用binarySearch的二分法查找比indexOf的遍历算法性能上高很多,特别是在大数据集且目标值又接近尾部时,binarySearch方法与indexOf方法相比,性能上会提升几十倍,因此从性能的角度考虑时可以选择binarySearch。
建议75:集合中的元素必须做到compareTo和equals同步
一看到标题,短时间有些发懵,简单来说,
indexOf依赖equals方法查找,binarySearch则依赖compareTo方法查找;
equals是判断元素是否相等,compareTo是判断元素在排序中的位置是否相同。
注意:实现了compareTo方法就应该覆写equals方法,确保两者同步。
建议76:集合运算的并集、交集、差集
1、并集 addAll
2、交集 retainAll
3、差集 removeAll
4、无重复的并集
并集是集合A加集合B,那如果集合A和集合B有交集,就需要确保并集的结果中只有一份交集,此为无重复的并集,此操作也比较简单,代码如下:
//删除在list1中出现的元素
list2.removeAll(list1);
//把剩余的list2元素加到list1中
list1.addAll(list2);之所以介绍并集、交集、差集,那是因为在实际开发中,很少有使用JDK提供的方法实现集合这些操作,基本上都是采用了标准的嵌套for循环:要并集就是加法,要交集就是contains判断是否存在,要差集就使用了!contains(不包含)。
之所以会写这么low的东西是想告诫自己多用JDK提供的方法,不要总想着自己去实现,很多东西Java老贼都有现成的!
建议77:使用shuffle打乱列表
简而言之,言而总之,shuffle就是用来打乱list列表顺序的,应用的场景比如
1、在抽奖程序中:比如年会的抽奖程序,先使用shuffle把员工顺序打乱,每个员工的中奖几率相等,然后就可以抽出第一名、第二名。
2、用于安全传输方法:比如发送端发送一组数据,先随机打乱顺序,然后加密发送,接收端解密,然后进行排序!
建议78:减少hashmap中元素的数量
1、hashmap和ArrayList的长度都是动态增加的,二者机制有些不同
2、先说hashmap,它在底层是以数组的方式保存元素的,其中每一个键值对就是一个元素,也就是说hashmap把键值对封装成一个entry对象,然后再将entry对象放到数组中,也就是说hashmap比ArrayList多一层封装,多出一倍的对象。
在插入键值对时会做长度校验,如果大于或者等于阈值,则数组长度会增大一倍。
hashMap的size大于数组的0.75倍时,就开始扩容,一次扩容两倍。
3、ArrayList的扩容策略,它是在小于数组长度的时候才会扩容1.5倍。
综合来说,HashMap比ArrayList多了一层Entry的底层封装对象,多占用了内存,并且它的扩容策略是2倍长度的递增,同时还会根据阈值判断规则进行判断,因此相对于ArrayList来说,同样的数据,它就会优先内存溢出。
注:Entry是Map中用来保存一个键值对的,而Map实际上就是多个Entry的集合。
建议79:集合中哈希码不要重复
1、Java中hashcode的理解
JVM每new一个Object,都会在Hash哈希表中产生一个hashcode。假设不同的对象产生了相同的hashcode,hash key相同导致冲突,那么就在这个hash key的地方产生了一个链表,将同样hashcode的对象放到单链表中,串到一起。
重写equals时一定要重写hashcode方法
两个相等对象的equals方法一定为true, 但两个hashcode相等的对象不一定是相等的对象。
hashcode相等仅仅保证两个对象在hash表里的同一个hash链上,继而通过equals方法才能确定是不是同一个对象。
总而言之,hashmap中hashcode应避免冲突。
建议80:多线程使用Vector或HashTable
Vector是ArrayList的多线程版本,HashTable是HashMap的多线程版本。
建议81:非稳定排序推荐使用List
什么叫非稳定排序?
public static void main(String[] args) {
SortedSet set = new TreeSet();
// 身高180CM
set.add(new Person(180));
// 身高175CM
set.add(new Person(175));
set.first().setHeight(185);
for (Person p : set) {
System.out.println("身高:" + p.getHeight());
}
} 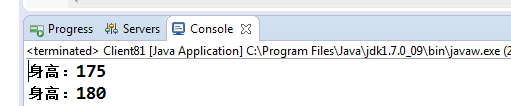
奇了怪了,为什么呢?这个就是非稳定排序。
SortedSet接口(TreeSet实现了此接口)只是定义了在给集合加入元素时将其进行排序,并不能保证元素修改后的排序结果,因此TreeSet适用于不变量的集合数据排序。
解决方法:
1、Set集合重排序:重新生成一个Set对象,再排序。
set.first().setHeight(185);
//set重排序
set=new TreeSet(new ArrayList(set)); 感觉如果这么写就失去了代码了乐趣了,太愚蠢了,pass。
2、使用List解决
使用Collections.sort()方法对List排序。
list中允许有重复的元素,避免重复可以先转成HashSet,去重后再转回来。
建议82:由点及面,集合大家族总结
Java中的集合类实在是太丰富了,有常用的ArrayList、HashMap,也有不常用的Stack、Queue,有线程安全的Vector、HashTable,也有线程不安全的LinkedList、TreeMap,有阻塞式的ArrayBlockingQueue,也有非阻塞式的PriorityQueue等,整个集合大家族非常庞大,可以划分以下几类:
1、List
实现List接口的集合主要有:ArrayList、LinkedList、Vector、Stack,其中ArrayList是一个动态数组,LinkedList是一个双向链表,Vector是一个线程安全的动态数组,Stack是一个对象栈,遵循先进后出的原则。
stack简介:
Stack来自于Vector,那么显然stack的底层实现是数组。
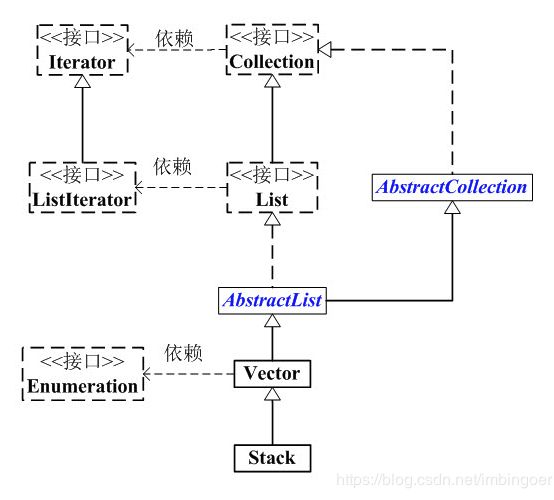
stack的方法:
① push(xx); //入栈
② pop() ; //栈顶元素出栈
③ empty() ; //判定栈是否为空
④ peek(); //获取栈顶元素
⑤ search(xx); //判端元素num是否在栈中,如果在返回1,不在返回-1。

2、Set
Set是不包含重复元素的集合,其主要实现类有:EnumSet、HashSet、TreeSet,其中EnumSet是枚举类型专用Set,所有元素都是枚举类型;HashSet是以哈希吗决定其元素位置的Set,其原理和hashmap相似,它提供快速的插入和查找方法;TreeSet是一个自动排序的Set,它实现了SortedSet接口。
3、Map
HashMap、HashTable、Properties、EnumMap、TreeMap等。
其中properties是hashtable的子类,它的主要用途是从property文件中加载数据,并提供方便的操作,EnumMap则要求其key必须是一个枚举类型。
map中还有一个WeakHashMap类需要简单说明一下,它是一个采用弱键方式的map类,它的特点是:WeakHashMap对象的存在并不会阻止垃圾回收器对键值对的回收,也就是说使用WeakHashMap不用担心内存溢出的问题,GC会自动删除不用的键值对,但存在一个严重的问题:GC是静悄悄的回收的(何时回收,God,Knows!)我们的程序无法知晓该动作,存在着重大的隐患。
WeakHashMap存在重大隐患,那这个东西什么时候使用呢?
在《Effective Java》一书中第六条,消除陈旧对象时,提到了weakHashMap,使用短时间内就过期的缓存时最好使用weakHashMap。
4、Queue
浅谈Java队列Queue
5、数组
数组与集合的最大区别是数组能够容纳基本类型,而集合只能容纳引用类型,所有的集合底层存储的都是数组。