Java集合基础知识总结(绝对经典)
一、数组Array和集合的区别
1、数组是大小固定的,并且同一个数组只能存放类型一样的数据(基本类型/引用类型)
2、JAVA集合可以存储和操作数目不固定的一组数据。
3、若程序时不知道究竟需要多少对象,需要在空间不足时自动扩增容量,则需要使用容器类库,array不适用。
注:使用相应的toArray()和Arrays.asList()方法可以相互转换。
二、Java集合
集合类存放于Java.util包中。
集合类存放的都是对象的引用,而非对象本身,出于表达上的便利,我们称集合中的对象就是指集合中对象的引用。
集合类型主要有三种:set(集)、list(列表)、map(映射)。

三、Collection接口
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素。Java SDK提供的类都是继承自Collection的“子接口”如List和Set。
如何遍历Collection中的每一个元素?不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素。典型的用法如下:
Iterator it = collection.iterator(); // 获得一个迭代子
while(it.hasNext()) {
Object obj = it.next(); // 得到下一个元素
}由Collection接口派生的两个接口是List和Set。
四、Set
Set接口同样是Collection接口的一个子接口,Set不包含重复的元素。
HashSet:使用hashmap的一个集的实现。虽然集定义成无序,但必须存在某种方法能高效地找到一个对象。使用一个hashmap对象实现集的存储和检索操作时在固定时间内实现的。
TreeSet:在集中以升序对对象排序的集的实现。这意味着从一个TreeSet对象获得第一个迭代器将按升序提供对象。TreeSet类使用了一个TreeMap。
为优化hashset空间的使用,可以调优初始容量和负载因子。TreeSet 不包含调优选项,因为树总是平衡的,保证了插入、删除、查询的性能的高效。
当您要从集合中以有序的方式抽取元素时,TreeSet实现会有用处。为了能顺利进行,添加到TreeSet的元素必须是可排序的。
import java.util.*;
public class SetExample {
public static void main(String args[]) {
Set set = new HashSet();
set.add("Bernadine");
set.add("Elizabeth");
set.add("Gene");
set.add("Elizabeth");
set.add("Clara");
System.out.println(set);
Set sortedSet = new TreeSet(set);
System.out.println(sortedSet);
}
}五、List
List接口继承了Collection接口,定义一个允许重复项的有序集合。该接口不但能够对列表的一部分进行处理,还添加了面向位置的操作。
实际上有两种list:一种是基本的ArrayList,其优点在于随机访问元素,另一种是更强大的LinkedList,它并不是快速随机访问设计的,而是具有更通用的方法。
- List : 次序是List最重要的特点:它保证维护元素特定的顺序。
- ArrayList : 由数组实现的List。允许对元素进行快速随机访问,但是向List中间插入与移除元素的速度很慢。
- LinkedList : 对顺序访问进行了优化,向List中间插入与删除的开销并不大,随机访问则相对较慢。还具有下列方法:addFirst(), addLast(), getFirst(), getLast(), removeFirst() 和 removeLast(), 这些方法 (没有在任何接口或基类中定义过)使得LinkedList可以当作堆栈、队列和双向队列使用。
- Vector:实现一个类似数组一样的表,自动增加容量来容纳你所需的元素。使用下标存储和检索对象就象在一个标准的数组中一样。你也可以用一个迭代器从一个Vector中检索对象Vector是唯一的同步容器类!!
- stack:这个类从vector派生而来,并增加了方法实现栈,一种后进先出的存储结构。
List的用法示例:
package collection;
import java.util.*;
public class SetExample {
public static void main(String[] args) {
List linkedList = new LinkedList();
for (int i = 0; i <= 5; i++) {
linkedList.add("a"+i);
}
System.out.println(linkedList);
linkedList.add(3,"a100");
System.out.println(linkedList);
linkedList.set(6,"a200");
System.out.println(linkedList);
System.out.println(linkedList.get(2));
System.out.println(linkedList.indexOf("a3"));
linkedList.remove(1);
System.out.println(linkedList);
}
}
六、list和set对比
Set子接口:无序,不允许重复,检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List子接口:有序,可以有重复元素,和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
Set和List具体子类:
Set
|————HashSet:以哈希表的形式存放元素,插入删除速度很快。
List
|————ArrayList:动态数组
|————LinkedList:链表、队列、堆栈。
七、map
1、map接口不是Collection接口的继承。
不重复的键到值的映射。
2、Map.Entry 接口
map的entrySet()方法返回一个实现map.entry接口的对象集合。集合中每个对象都是底层map中一个特定的键值对。
3、HashMap 类和 TreeMap 类
在map中插入、删除和定位元素,HashMap是最好的选择。但如果您要按顺序遍历键,那么TreeMap 会更好。根据集合大小,先把元素添加HashMap,再把这种映射转换成一个用于有序键遍历的TreeMap 可能更快。
为了优化hashmap空间的使用,您可以调优初始容量和负载因子。这个treeMap没有调优选项,因为该树总处于平衡状态。
- hashtable:实现一个映象,所有的键必须非空。为了能高效的工作,定义键的类必须实现hashcode()方法和equal()方法。这个类时前面Java实现的一个继承,并且通常能在实现映象的其它类中更好地使用。
- hashmap:实现一个映象,运行存储空对象,而且允许键是空(由于键必须是唯一的,当然只能有一个空)。
- WeakHashMap:如果有一个键对于一个对象而言不再被引用,键将被舍弃,WeakHashMap在具有大量数据时使用。
- TreeMap: 实现这样一个映象,对象是按键升序排列的。
4、map的使用示例
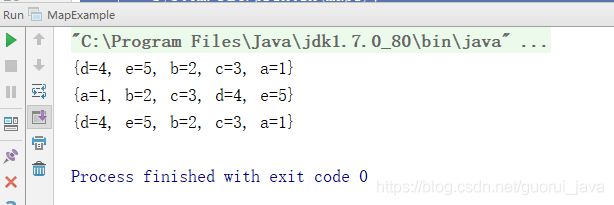
以下程序演示了具体map类的使用。该程序对自命令行传递的词进行频率计数。hashmap起初用于数据存储。后来,映射被转换为TreeMap以显示有序的键列列表。
package collection;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;
public class MapExample {
public static void main(String[] args) {
String[] array = {"a","b","c","d","e"};
Map map = new HashMap();
Integer ONE = new Integer(1);
for (int i=0, n=array.length; i5、控制台输出
八、HashMap、Hashtable、ConcurrentHashMap的原理与区别
1、HashTable
- 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
- 初始size为11,扩容:newsize = olesize*2+1
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
2、HashMap
(1)HashMap简介
- 底层数组+链表实现,可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
- 计算index方法:index = hash & (tab.length – 1)
(2)HashMap加载因子
- 哈希冲突:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较。
- 加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
- 空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。
(3)HashMap容量
HashMap和Hashtable都是用hash算法来决定其元素的存储,因此HashMap和Hashtable的hash表包含如下属性:
- 容量(capacity):hash表中桶的数量
- 初始化容量(initial capacity):创建hash表时桶的数量,HashMap允许在构造器中指定初始化容量
- 尺寸(size):当前hash表中记录的数量
- 负载因子(load factor):负载因子等于“size/capacity”。负载因子为0,表示空的hash表,0.5表示半满的散列表,依此类推。轻负载的散列表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)
除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
HashMap和Hashtable的构造器允许指定一个负载极限,HashMap和Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。
“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:
- 较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询)
- 较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销
程序猿可以根据实际情况来调整“负载极限”值。
3、ConcurrentHashMap
- 底层采用分段的数组+链表实现,线程安全
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
- Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
- 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
Hashtable和HashMap都实现了Map接口,但是Hashtable的实现是基于Dictionary抽象类的。Java5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
HashMap基于哈希思想,实现对数据的读写。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来存储值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞时,对象将会储存在链表的下一个节点中。HashMap在每个链表节点中储存键值对对象。当两个不同的键对象的hashcode相同时,它们会储存在同一个bucket位置的链表中,可通过键对象的equals()方法来找到键值对。如果链表大小超过阈值(TREEIFY_THRESHOLD,8),链表就会被改造为树形结构。
在HashMap中,null可以作为键,这样的键只有一个,但可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该key,也可以表示该key所对应的value为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个key,应该用containsKey()方法来判断。而在Hashtable中,无论是key还是value都不能为null。
Hashtable是线程安全的,它的方法是同步的,可以直接用在多线程环境中。而HashMap则不是线程安全的,在多线程环境中,需要手动实现同步机制。
Hashtable与HashMap另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。
先看一下简单的类图:

从类图中可以看出来在存储结构中ConcurrentHashMap比HashMap多出了一个类Segment,而Segment是一个可重入锁。
ConcurrentHashMap是使用了锁分段技术来保证线程安全的。
锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap提供了与Hashtable和SynchronizedMap不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
九、解惑
1、什么是iterator
对集合的遍历,遍历的时候不建议修改集合。
2、Iterator与ListIterator有什么区别?
Iterator:只能正向遍历集合
ListIerator:继承Iterator,可以双向列表遍历
3、HashMap与HashTable有什么区别?
HashMap允许空值作为键或值,不同步的,迭代时采用的是快速失败机制
HashTable不允许空值,同步的
注:有多线程的可能时,使用hashtable,反之使用hashmap。非线程安全的数据结构能带来更好地性能。
如果将来有可能需要按顺序获取键值对,hashmap是更好地选择,因为hashmap的一个子类LinkedHashMap。
如果多线程时使用hashmap,Collections.synchronizedMap()可以代替,总的来说HashMap更灵活。
4、在Hashtable上下文中同步是什么意思?
同步意味着在一个时间点只能有一个线程可以改变哈希表,任何线程在执行hashtable的更新操作前需要获取对象锁,其它线程等待锁的释放。
5、为什么Vector不推荐使用?
使用时ArrayList优先于Vector,Vector是同步的,性能会低一些,如果迭代一个vector,还要加锁,以避免其他线程同一时刻改变集合,加锁效率更慢。
上一篇:Java面试题总结(附答案)
下一篇:Java基础知识总结(绝对经典)