Python (一)浏览器的操作和简单对象的定位
一、浏览器的操作
1、浏览器最大化
在统一的浏览器大小下运行用例,可以比较容易的跟一些基于图像比对的工具进行结合,提升测试的灵活性及普遍适用性。比如可以跟sikuli 结合,使用sikuli 操作flash。(待实验)
import time
from selenium import webdriver
browser = webdriver.Firefox()
browser.get("http://www.baidu.com")
print("浏览器最大化")
browser.maximize_window() # 将浏览器最大化
time.sleep(30)
browser.quit()
2、设置浏览器宽和高
在不同的浏览器大小下访问测试站点,对测试页面截图并保存,然后观察或使用图像比对工具对被测页面的前端样式进行评测。比如可以将浏览器设置成移动端大小(320x480),然后访问移动站点,对其样式进行评估
browser.set_window_size(400,800)
3、控制浏览器前进、后退
浏览器上有一个后退、前进按钮,对于浏览网页的人是比较方便的;对于web 自动化测试来说是 一个比较难模拟的操作;webdriver 提供了back()和forward()方法,使实现这个操作变得非常简单。
# 控制浏览器前进、后退
importtime
fromseleniumimportwebdriver
driver = webdriver.Firefox()
# 访问百度页面
first_url ="http://www.baidu.com"
print("now access ")
print(first_url)
driver.get(first_url)
time.sleep(2)
# 访问新闻页面
second_url ="http://news.baidu.com"
print("now access")
print(second_url)
driver.get(second_url)
time.sleep(2)
# 后退到百度页面
print("back to ")
print(first_url)
driver.back()
time.sleep(2)
# 前进到新闻页面
print("forward to")
print(second_url)
driver.forward()
time.sleep(2)
二、简单对象的定位
对象(元素)的定位和操作是自动化测试的核心,其中操作又建立在定位的基础上。 一个对象就像是一个人,他会有各种的特征(属性),如比我们可以通过一个人的身份证号、姓名或者他的住址找到这个人。那么一个元素也有类似的属性,我们可以通过这种区别于其他元素的唯一属性来定位这个元素
webdriver 提供了一系列的元素定位方法,常用的有以下几种
id
name
class name
tag name
link text
partial link text
xpath
css selector
分别对应python webdriver 中的方法为:
find_element_by_id()
find_element_by_name()
find_element_by_class_name()
find_element_by_tag_name()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_xpath()
find_element_by_css_selector()
1、id和name定位
id 和name 是我们最常用的定位方式,因为大多数元素都有这两个属性,而且在对控件的id 和name命名时一般使其有意义也会取不同的名字。通过这两个属性使我们找一个页面上的属性变得相当容易。

通过元素中所带的id 和name 属性对元素进行定位:
id=”gs_htif0”
find_element_by_id("gs_htif0")
name=”btnK”
find_element_by_name("btnK")
name=”btnI”
find_element_by_name("btnI")
2、tag name 和 class name定位
不是所有的前端开发人员都喜欢为每一个元素添加id 和name 两个属性,但除此之外,一个元素不单单只有id 和name,它还有class 属性;而且每个元素都会有标签。

通过元素中带的class 属性对元素进行定位:
class=”jhp_big”
find_element_by_class_name("jhp_big")
class=”s_ipt”
find_element_by_class_name("s_ipt")
##通过tag 标签名对对元素进行定位:
find_element_by_tag_name("div")
find_element_by_tag_name("form")
find_element_by_tag_name("input")
tag name 定位应该是所有定位方式中最不靠谱的一种了,因为在一个页面中具有相同tag name 的元素极其容易出现。
3、link text 和 partial text定位
有时候需要操作的元素是一个文字链接,那么可以通过link text 或partial link text 进行元素定位。

通过link text 定位元素:
ind_element_by_link_text("新闻")
find_element_by_link_text("贴吧")
find_element_by_link_text("一个很长的文字连接")
通partial link text 也可以定位到上面几个元素:
find_element_by_partial_link_text("新")
find_element_by_partial_link_text("吧")
find_element_by_partial_link_text("一个很长的")
当一个文字连接很长时,可以通过partial_text只取其中的一部分,只要取的部分可以唯一标识元素。一般一个页
面上不会出现相同的文件链接,通过文字链接来定位元素也是一种简单有效的定位方式。
4、Xpath定位
XPath 是一种在XML 文档中定位元素的语言。因为HTML 可以看做XML 的一种实现,所以selenium 用户可使用这种强大语言在web 应用中定位元素。


用xpath 来定位最后一个元素。
用绝对路径定位:
find_element_by_xpath("/html/body/div[2]/form/span/input")
当我们所要定位的元素很难找到合适的方式时,都可以通这种绝对路径的方式位,缺点是当元素在很多级目录下时,我们不得不要写很长的路径,而且这种方式难以阅读和维护。
相对路径定位:
find_element_by_xpath("//input[@id=’input’]") #通过自身的id 属性定位
find_element_by_xpath("//span[@id=’input-container’]/input") #通过上一级目录的id 属性定位
find_element_by_xpath("//div[@id=’hd’]/form/span/input") #通过上三级目录的id 属性定位
find_element_by_xpath("//div[@name=’q’]/form/span/input")#通过上三级目录的name 属性定位
通过上面的例子,我们可以看到XPath 的定位方式非常灵活和强大的,而且XPath 可以做布尔逻辑运算,例如://div[@id=’hd’ or @name=’q’]
缺点:
1、性能差,定位元素的性能要比其它大多数方式差;
2、不够健壮,XPath会随着页面元素布局的改变而改变;
- 兼容性不好,在不同的浏览器下对XPath 的实现是不一样的。
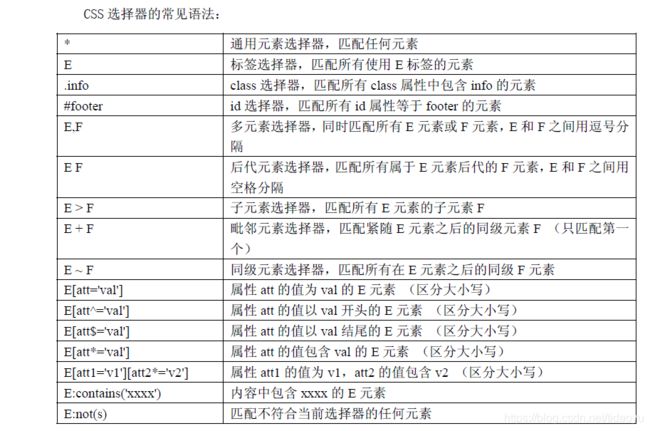
5、CSS定位
这个好难!!!!!!!!!!!!!!看的晕。。。。。
CSS(Cascading Style Sheets)是一种语言,它被用来描述HTML 和XML 文档的表现。CSS 使用选
择器来为页面元素绑定属性。这些选择器可以被selenium 用作另外的定位策略。
后期再补吧。。。。。
上面是我收集的一些视频资源,在这个过程中帮到了我很多。如果你不想再体验一次自学时找不到资料,没人解答问题,坚持几天便放弃的感受的话,可以加入我们群【1127563538】,里面有各种软件测试资源和技术讨论。
当然还有面试,面试一般分为技术面和hr面,形式的话很少有群面,少部分企业可能会有一个交叉面,不过总的来说,技术面基本就是考察你的专业技术水平的,hr面的话主要是看这个人的综合素质以及家庭情况符不符合公司要求,一般来讲,技术的话只要通过了技术面hr面基本上是没有问题(也有少数企业hr面会刷很多人)
我们主要来说技术面,技术面的话主要是考察专业技术知识和水平,上面也是我整理好的精选面试题。
加油吧,测试人!如果你需要提升规划,那就行动吧,在路上总比在起点观望的要好。事必有法,然后有成。
资源不错就给个推荐吧~