一致性hash算法
1、一个分布式缓存场景
- 假设有A、B、C编号是0、1、2 的 3台服务器集群,现在需要将几万张图片均匀的缓存到集群上,如何实现

其实 哈希表已经告诉我们答案了、 就是对key进行hash运算然后对哈希表大小进行取模计算出桶下标

同理、这里的key就是图片名称(假设图片名称全局唯一),除数就是集群机器数,余数就是服务器编号 .
计算过程为: hash("图片名称") % 集群机器数 = 服务器编号 .
- 方便后续说明,称为普通哈希计算
经过这样的计算,那么我们的图片一定是能够缓存到集群的某一台服务器上面的
现有一个 a.img需要缓存到集群, 假设经过hash函数后值为8, 然后再对集群机器数3进行取模 . 即 hash("a.img) % 3 =》 8 % 3 = 2 则说明这个a.img图片交给服务器编号2处理,取缓存这个图片. 这样下次读取只要根据图片名称然后根据普通哈希计算就可以计算出这个图片缓存到哪个服务器上面了.
但是如果这时集群机器数挂了一台变成2了, 这时如果要再去读取图片a.img, 则经过普通hash运算后 hash("a.img) % 2 =》 8 % 2 = 0 计算出的结果是服务器编号0, 然后它就去服务器编号0读取缓存、可是我们只它之前是缓存到这个服务器编号2上面的, 也就是说这个图片再也无法根据图片名称去找回来了, 也就是缓存失效了.
这样因为服务器集群数量的变化可能导致大量的缓存同一时刻失效. 也就是所谓缓存雪崩问题
这时一致性Hash算法登场了,虽说不能完全避免缓存失效, 但它可以大大减少缓存失效的比例, 只影响一小部分的数据
2、一致性hash算法怎么减缓这个问题
假设有一个环(被称为hash环)、想象里面有2的32次方个位置存放数据、每个位置就是存放我们服务器集群节点.
现在需要把我们的3台服务器节点打到这个环上, 打到这个环上的过程与普通hash算法一致. 就是 hash( "服务器名称") % 2^32 = 余数, 那么这个余数就是它在这个环上的位置. 假设3台服务器ABC打到环上的位置如下:
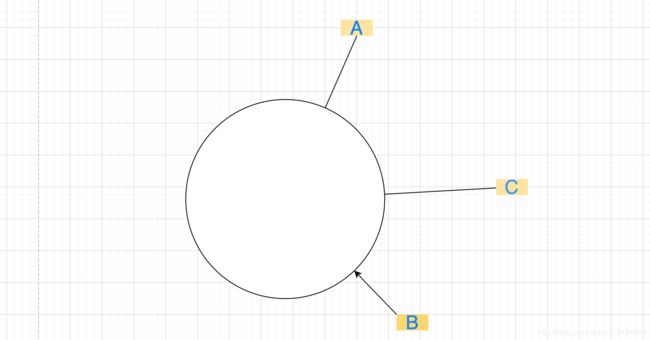
现在假设要缓存图片a,但是不知道缓存到哪个服务器上面?
我们可以把要缓存的图片名称a.img经过普通哈希计算后即 hash( "a.img") % 2^32 = 余数计算出它在环上的位置, 然后顺时针寻找遇到的第一个节点, 就是负责处理它请求的节点. 这个过程我们称之为一致性hash算法
比如要缓存abc、3个图片, 则经过一致性hash计算后图片a、b交给服务器A处理、图片c交给服务器C处理

现在面对同样的问题, 即假设服务器C挂掉了, 集群机器数变化了, 现在要读取图片c,则经过一致性hash计算后, 读取图片c的请求是交给服务器B处理. 而之前它是缓存到服务器C的,然后它去服务器B读取发现读取不到, 也就是说它缓存还是失效了. 但是我们发现缓存的图片a和b经过一致性hash计算后还是交给服务器A处理, 丝毫不受影响, 也就说缓存并没有失效.
如果运气好,之前的图片c先是缓存在B--> A(顺时针) 这片区域 甚至所有缓存都没有失效, 均还是交给服务器A处理

这便是一致性hash算法解决的问题, 减少大面积的映射失效,可以大幅度减少缓存雪崩的可能性
3、普通一致性数据倾斜问题
如果只是把集群的节点打在hash环上, 这样还会导致一个数据倾斜的问题. 就是每个服务器处理的图片数量不够均匀.
比如假设又来了4张图片defg、都打在了如下区域,经过一致性hash计算后也就是说他们最终都会交给服务器A处理. 而服务器C只处理一个图片, 服务器B甚至没有处理图片. 这就失去了我们分布式缓存的意义,搞个单机全部存储在上面得了

如何解决?
假设我们的集群机器数够多,然后全部打在hash环上是长这样、他们均匀分割了hash环,这样如果来了一个图片经过一致性hash计算后, 这个处理它的服务器是谁的不确定性是不是大大增加

但是我们不可能有那么多服务器、 我们可以给给每个真实节点生成N个虚拟节点然后打到哈希环上、目的是为了打散这个环、均匀分割这个环. 这样从逻辑上哈希环是被均匀分割的. 也就是说打到这个环上的图片寻找处理服务器的是更随机的
只要这个虚拟节点和真实节点有关系,这个虚拟节点就能找回到真实节点.
- 比如真实节点服务器A生成的虚拟节点服务器名称为 A_1, 那么虚拟节点名称不就是真实节点名称A再拼接上
_序号吗, 是不是就可以找回真实节点, 所以说虚拟节点的名称的生成得根据真实节点你的名称来扩展
比如:
- 给真实节点A生成4个虚拟节点即 A_0、A_1、A_2、A_3
(实际上可以生成几百几千个都行), 然后通通把它们打到这个哈希环上即可. 真实节点B和C处理方法同理 - 这样处理后, 这个哈希环看起来就被服务器节点均匀的分割了, 大大降低数据倾斜的问题
ps: 这时只打入虚拟节点即可,不用打入真实节点到环上面

现在来了一个图片a.img要处理, 经过一致性hash计算后a.img交给是服务器B的虚拟节点B_2处理、然后 从 B_2中截取出真实服务器节点B,然后最终交给服务器B去处理这个图片
3、代码实现
关键是如何表示这个环, 其实只要是有序的循环集合就可以
假设服务器ABC打在了哈希环的1\4\6号位置上, 然后a.img图片经过计算后是落在2位置上,然乎顺时针寻找第一个比2大的服务器节点, 发现是服务器B的4, 然后这个图片就交给服务器B处理, 当服务器C挂掉后, 这个图片按照算法丝毫不受影响还是交给服务器B处理.

java实现
- 这里
hash环采用TreeMap, 因为它是有序的, 而且它的SortedMap可以很方便的寻找到比该key第一个大的节点.(也就是顺时针寻找.....)
public class ConsistentHashStrategy {
/** 哈希环: 存放虚拟节点,key表示虚拟节点的hash值,value表示虚拟节点的名称 */
private SortedMap<Integer, String> hashRing = new TreeMap<>();
/** 虚拟节点的数目 */
private static final int VIRTUAL_NODES = 2;
// 删除节点的所有虚拟节点
public void removeNode(String node){
System.out.println("删除服务器节点: " + node);
for (int i = 0; i < VIRTUAL_NODES; i++) {
// 虚拟节点名称中保存了真实节点,这样就可以找回到真实节点
String virtualNodeName = node + "&&VN" + i;
int hash = getHash(virtualNodeName);
hashRing.remove(hash);
}
}
// 新增节点
public void addNode(String node){
// 给该节点生成VIRTUAL_NODES个虚拟节点
for (int i = 0; i < VIRTUAL_NODES; i++) {
String virtualNodeName = node + "&&VN" + i;
int hash = getHash(virtualNodeName);
hashRing.put(hash, virtualNodeName);
}
}
// 在hash环上寻找处理该key的服务器节点
public String getServer(String key){
int hash = getHash(key);
// 顺时针寻找到处理该key的第一个节点
// 就是从右子树中找到第一个比该key大的子树
SortedMap<Integer, String> sortedMap = hashRing.tailMap(hash);
String targetNode;
if (sortedMap.isEmpty()){
// 如果sortedMap为null表示 hash寻找到了哈希环的尾部, 直接寻找到hash环第一个节点即可
targetNode = hashRing.get(hashRing.firstKey());
}else {
targetNode = sortedMap.get(sortedMap.firstKey());
}
// 最后把找到的虚拟节点名称截取一下就可以获得真实节点名称
return targetNode != null && !"".equals(targetNode) ? targetNode.substring(0,targetNode.indexOf("&&")) : null;
}
// 打印出hash环上的所有服务器节点
public void printNodes(){
System.out.println("=============虚拟节点===============");
int index = 1;
for(Integer hashKey : hashRing.keySet()){
System.out.println("["+(index++)+"] "+ hashRing.get(hashKey) + "\t\t\t哈希值: [" + hashKey + "]");
}
System.out.println("========================================");
}
// FNV1_32_HASH算法
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
}
测试代码:
static ConsistentHashStrategy hashStrategy = new ConsistentHashStrategy();
public static void main(String[] args) {
// 1-打入5个真实节点
hashStrategy.addNode("data_100");
hashStrategy.addNode("data_101");
hashStrategy.addNode("data_102");
hashStrategy.addNode("data_103");
hashStrategy.addNode("data_104");
// 2-打印环上的所有节点
hashStrategy.printNodes();
// 存一个key,
write("id_0");
write("id_1");
write("id_2");
write("id_3");
// 读取数据
read("id_0");
read("id_1");
read("id_2");
read("id_3");
//
System.out.println("===================");
// 假设data_103节点挂掉
hashStrategy.removeNode("data_103");
hashStrategy.printNodes();
// 再次读取数据
read("id_0");
read("id_1");
read("id_2");
read("id_3");
}
public static void write(String key){
String server = hashStrategy.getServer(key);
System.out.println("写缓存: 把["+ key + "]存储到: [" + server + "] 服务器中");
}
public static void read(String key){
String server02 = hashStrategy.getServer(key);
System.out.println("读缓存: ["+key+ "] 去[" + server02 + "]服务器: ");
}
输出
=============虚拟节点===============
[1] data_102&&VN0 哈希值: [167530316]
[2] data_101&&VN1 哈希值: [285594866]
[3] data_100&&VN1 哈希值: [348736648]
[4] data_100&&VN0 哈希值: [512262047]
[5] data_104&&VN0 哈希值: [680985543]
[6] data_103&&VN1 哈希值: [998745087]
[7] data_101&&VN0 哈希值: [1134856140]
[8] data_104&&VN1 哈希值: [1463870490]
[9] data_102&&VN1 哈希值: [1873521012]
[10] data_103&&VN0 哈希值: [1950521208]
========================================
写缓存: 把[id_0]存储到: [data_104] 服务器中
写缓存: 把[id_1]存储到: [data_103] 服务器中
写缓存: 把[id_2]存储到: [data_102] 服务器中
写缓存: 把[id_3]存储到: [data_101] 服务器中
读缓存: [id_0] 去[data_104]服务器:
读缓存: [id_1] 去[data_103]服务器:
读缓存: [id_2] 去[data_102]服务器:
读缓存: [id_3] 去[data_101]服务器:
===================
删除服务器节点: data_103
=============虚拟节点===============
[1] data_102&&VN0 哈希值: [167530316]
[2] data_101&&VN1 哈希值: [285594866]
[3] data_100&&VN1 哈希值: [348736648]
[4] data_100&&VN0 哈希值: [512262047]
[5] data_104&&VN0 哈希值: [680985543]
[6] data_101&&VN0 哈希值: [1134856140]
[7] data_104&&VN1 哈希值: [1463870490]
[8] data_102&&VN1 哈希值: [1873521012]
========================================
读缓存: [id_0] 去[data_104]服务器:
读缓存: [id_1] 去[data_101]服务器:
读缓存: [id_2] 去[data_102]服务器:
读缓存: [id_3] 去[data_101]服务器:
从输出可以看到 id_0和 id_2和 id_3缓存数据的读取丝毫不受影响, 而存储id_1的服务器data_03挂掉了, 它就交给给了服务器data_101处理