摘要:本文将系统介绍在GaussDB(DWS)系统中影响性能的坏味道SQL及SQL模式,帮助大家能够从原理层面尽快识别这些坏味道SQL,在调优过程中及时发现问题,进行整改。
数据库的应用中,充斥着坏味道的SQL,非常影响查询的性能。坏味道SQL,即由于开发者写的随意,导致执行性能较差,需要通过优化SQL语句进行调优的SQL。在GaussDB(DWS)分布式场景下,相对于单机环境,将出现更多的坏味道SQL语句。本文将系统介绍在GaussDB(DWS)系统中影响性能的坏味道SQL及SQL模式,帮助大家能够从原理层面尽快识别这些坏味道SQL,在调优过程中及时发现问题,进行整改。从大的方面来看,主要包含不支持下推导致的坏味道、不支持重分布导致的坏味道、数据类型转换导致的坏味道、全局性操作导致的坏味道、NestLoop类低效运算导致的坏味道和冗余操作导致的坏味道。本文将介绍每一类坏味道的原因,以及如何进行SQL改写及调优。
一.不支持下推导致的坏味道
在GaussDB(DWS)分布式场景下,数据运算应该全部下推到DN上执行,才能获得比较好的性能收益。但对于某些场景,数据必须在CN上执行,导致语句无法全部下推到DN运算,会导致两个主要的瓶颈点:
(1)只有基表扫描在DN执行,需要将大量数据传输到CN上,网络开销增大。
(2)原先可以在DN上分布式执行的数据,均由CN单个执行,瓶颈加大。
通常情况下,我们不支持不下推函数、复合类型、复杂语法及组合(例如:某些场景的with recursive语法,rollup函数+多count(distinct)语法)的下推,所以应该尽量避免在语句中使用以上元素。在客户场景中,经常遇到函数不能下推导致的问题,本篇博文重点以函数下推为例,讲述如何解决类似的问题。如下图计划所示,在语句中包含了不支持下推的函数unship_func(),导致整个计划不能下推,计划中出现“_REMOTE_TABLE_QUERY_”的字样,即会出现上述的瓶颈问题。遇到类似问题,需要根据具体应用场景,为函数设置合理的下推属性,使其可以下推。

通常来说,函数可以通过可变性和下推维度进行划分,主要包含以下函数属性:

以上两个属性可以通过系统表pg_proc的provalitile和proshippable字段查询。目前GaussDB以CN/DN行为是否一致作为下推标准,支持大部分immutable和stable函数的下推,以及特定场景少量volatile函数的下推。对于用户自定义函数,由于数据库无法知晓函数的行为,因为不知道函数的属性,因为默认是volatile和unshippable的。包含对应函数的语句将无法下推到DN执行。用户可以根据函数的行为,判断返回结果是否恒定,以及是否可以下推,设置对应的属性。具体的设置方法为:
(1)如果函数的返回结果是恒定的,比如数字计算函数,日期计算函数,则可以为其设置immutable属性。
(2)如果函数中使用了数据表,且数据表均是复制表的只读操作且不涉及事务操作(所以DN数据均相同,可以下推到一个DN上执行),则可以为其设置shippable属性。其余情况则还是不能下推,如果错误设置,会引发不可预知错误,因此需要慎重设置。
如果无法使函数下推,可以对语句进行改写,使不涉及函数的部分能够部分下推到DN执行。例如,对于以下SQL语句:
select unship_func() from t1 join t2 on t1.a=t2.a;
复制代码可以改写为:
select unship_func() from (select * from t1 join t2 on t1.a=t2.a);
复制代码这样,t1和t2 join的部分可以推到DN执行,只有unship_func()的计算是逐行在CN执行的,流程变化如下图所示,在join结果集较小的情况下,性能也可以得到明显的提升。

二.不支持重分布导致的坏味道
在share-nothing架构的分布式场景下,数据使用哈希分布在不同DN上,并且通过数据重分布使得中间结果均匀分布在各个DN上进行并行计算,进行执行查询的加速。所以在执行过程中,一直保持数据能够均匀分布在DN上,是保证性能的关键。通常情况下,我们需要进行表的关联(Join)和聚集(Agg)操作,这就需要关联和聚集列能够支持重分布,从而进行灵活的重分布操作。在GaussDB(DWS)中,不支持重分布的类型主要有real和double类型,因此使用这两种类型进行操作时,将导致无法生成重分布的计划,在实际使用时要尽量避免。首先,在进行表定义时,要尽量避免使用这两种类型,使用numeric类型进行替代。同时,还要避免使用返回值为这两种类型的函数,进行关联和聚集运算,例如:ceil, floor, pow, sqrt, 以及一些分析类聚集函数如stddev_samp等。如果必须使用此类函数进行相关运算,需要在计算完对这些类型进行类型转换,转换成numeric类型。例如下面的语句:
select count(distinct ceil(a)) from t1;
复制代码由于ceil()返回值为double,原始生成的计划是不能下推的:

如果我们显式将ceil()转换成numeric类型,得到的下推计划如下:

三.数据类型转换导致的坏味道
数据库在进行不同列的比较、计算运算时,如果类型不同,需要进行类型转换。通常情况下,由优化先低的类型往优先级高的类型转换,字符串的优先级较数字较低,同时数字类型,精度低的会向精度高的转换。在应用中,经常遇到的是,字符串和数字进行比较,导致字符串需要转成数字进行比较操作。由于数据库的基本调优都是基于基表列的,数据转换后就会带来以下性能问题:
(1)无法使用索引。由于索引是基于列的排序构造的,字符串转换成数字后的排序性与字符串不一致(’2’与’12’,字符串’2’大,数字12大),故无法使用索引,对于返回数据量少的场景,使用全表扫描带来性能问题。
(2)无法进行分区剪枝。GaussDB(DWS)支持range分区,即根据分区键值的范围创建不同的分区。当需要进行分区键上的范围操作时,进行分区剪枝。而字符串转换成数字后,道理与(1)类似,打破排序性,导致分区剪枝失效。
(3)需要进行网络重分布操作。在进行表的关联,聚集操作时,如果涉及表分布键的操作,可以在本地并行进行。但如果涉及到类型转换,则hash值发生变化,需要进行网络重分布,增加了网络开销。
(4)估算不够准确,可能造成计划的性能问题。我们收集的统计信息都是基于基表列的,如果进行类型转换,则缺少转换后的统计信息,同样可能造成计划不准。
因此,在表设计之初就要把数据类型定义好,数字类型尽量使用整型或numeric(浮点型),尽量少使用字符串数据类型,除了与数字比较产生上述开销外,变长的字符串在处理时还产生了额外的空间申请释放,内存拷贝的开销,都是无形中性能的损耗。
四.全局性操作导致的坏味道
前面提到,GaussDB(DWS)分布式数据库的优势,就是利用多DN的资源进行并行计算,提高吞吐量。但有些SQL在这些方面不够注意,导致执行过程中由于全局性操作仅能在一个DN或CN上执行,造成了性能瓶颈。不能下推即属于这一类型问题。除了不能下推,本章节主要讨论在DN上进行全局操作导致的问题。客户场景遇到的主要问题,是需要对全量大数据量进行排序的问题,比如:windowagg函数没有partition by,但包含order by的问题。例如如下语句:
select * from (select ss_sold_date_sk, sum(ss_sales_price) over
(order by ss_sold_date_sk rows 2 preceding)
sum_2, sum(ss_sales_price) over (order by ss_sold_date_sk rows 5 preceding) sum_5 from store_sales), date_dim where ss_sold_date_sk=d_date_sk and d_year=2000 and d_moy=5 order by 1;执行计划如下:
复制代码执行计划如下:

计划中第4层将所有DN的数据广播到一个DN上进行全局排序,并计算sum窗口函数的值,导致性能瓶颈。对于类似情况,在语义允许的情况下,尽量给窗口函数增加partition by的字段,这样分组计算时,GaussDB(DWS)可以将计算分配到不同的DN上进行,提高执行效率。
五.NestLoop类低效运算导致的坏味道
NestLoop是最简单的表关联手段,当然也是最低效的,每条元组之间都要进行匹配,数据量大的时候经常执行不出来。所以在GaussDB(DWS)中,我们经常使用HashJoin进行表的关联。但有些SQL语句从语义上决定,只能使用NestLoop的方式执行,导致性能问题。总结起来,有以下几方面:
(1)无等值关联条件场景
在GaussDB(DWS)中,我们推荐使用等值关联,这样可以使用HashJoin进行执行加速。但对于非等值关联条件,只能使用NestLoop的方式进行连接,同时需要将其中一个表进行Broadcast广播到所有DN进行。如果两个表都比较大,将导致性能瓶颈。例如如下:
select * from t1 join t2 on t1.a计划如下:

类似的场景还有:<1> select from t1 join t2 on 1=1;这个语句无关联条件,我们称为笛卡尔积关联,返回结果行数为t1和t2行数的乘积。<2> select from t1 join t2 on t1.a=t2.a and t1.a=5;这个语句虽然有等值关联条件,但关联条件还有个过滤条件t1.a=5,所以实际上t1.a=t2.a=5,是在a=5过滤基础上的笛卡尔积。这类语句都会导致性能瓶颈。
(2)相关子查询场景
相关子查询,即子查询中需要依赖父查询的列值进行迭代计算的场景。例如如下语句:select (select ss_item_sk from store_sales where ss_item_sk 计划如下: 在分布式框架下,为了保证每一行父查询元组均能够在子查询中迭代计算出结果,需要所有DN均维护一份子查询表的全局数据,在上面的计划中,子查询中的store_sales表进行了广播和物化,将数据存在所有DN上,见8层算子。第3层算子每一行数据均需要通过迭代子查询计算(第4层及之下的SubPlan 1)获得是否匹配的信息。这个计划执行非常慢且耗费资源,原因是: a) 在DN节点非常多的分布式环境下,将数据广播到所有DN上进行物化,将导致网络资源和IO资源耗费巨大,同时大数据量的广播耗时也很长。 b) 对于父查询的每一行元组,均需要迭代计算子查询的值,类似于NestLoop的执行方式,效率极低。 以上两个问题带来的语句性能问题在各个客户现场均被识别,因此需要进行通用子链接提升转成join的查询重写来解决该问题。 在之前的版本中,我们已经支持了如下场景的子链接提升,即将子链接转化为join获得性能提升,这些子链接均出现在where条件里,包括: a) IN/NOT IN的非相关子查询。 b) EXISTS/NOT EXISTS的等值相关子查询。 c) 包含Agg表达式的等值相关子查询。 d) 以上场景子查询的OR场景。 当然,目前我们还不支持目标列上出现相关子查询的场景,以及相关子查询中出现不等值比较的场景,需要首先识别出坏味道,进行语义等价的整改。 当查询语句中包含NOT IN谓词时,例如如下语句: 其计划如下图所示: 我们发现其走了NestLoop计划,原因是NOT IN的特殊语义,NULL值和任意值的比较结果是NULL,不是true,所以需要单独在Join条件上加上IS NULL的条件,导致等值关联变成非等值关联。一般客户场景下,使用NOT IN并不是为了处理NULL值,而是对NOT IN语义的误解,因此需要将两侧的NULL值去除(验证无NULL值,或建立临时表)后,使用下面两种方法解决性能问题: a) 如果确认关联列没有NULL值,需要在关联列上建立NOT NULL约束,比如示例SQL语句,要在t表的a列和b列上均建立NOT NULL约束。 b) 可以将语句改写成NOT EXISTS,例如示例语句可以改写为: IN list场景是指语句中包含大量常数的IN条件,例如如下语句: 通常情况下,会生成基表扫描的查询计划,即对于customer表的每一条,需要检查c_customer_sk列是否会和IN list中的某个值匹配,匹配即返回该条元组。当IN list中的条件比较多时,匹配近似于NestLoop的操作。针对这种场景,GaussDB(DWS)实现了In list to Join的查询优化规则,根据代价估算,针对In list中的值较多的场景,生成Hash Join的计划,极大提升性能,如下图所示: 但代价估算存在估算不准的情况,对于列存表有min/max过滤,有时转成Join并不一定性能最好,因此我们增加了GUC参数:qrw_inlist2join_optmode,用户可以手动设置该参数的值进行调优,其值说明如下: a) cost_base,即根据代价估算,默认值。 b) rule_base,强制使用转换成Join的优化规则。 c) 不小于2的整数,表示当In list中的常量个数不小于N时,使用转换成Join的优化规则。 在GaussDB(DWS)场景中,经常会遇到一类SQL,其中存在大量的冗余操作,导致执行时进行了大量无效计算。这类语句的场景很多,需要根据performance数据详细分析,以下举几个例子简单看一下。 例如如下语句,语句中有大量case when语句,大多数条件都是一样的,只是default值存在不同,但执行时,每个分支的case when均需要执行,导致时间成倍增加。 这种情况下需要对语句进行深入分析,根据语义进行等价改写。通常我们可以把case when加到过滤条件,分成多个子查询分别求值,或提取公共部分进行改写。经过优化后,消除了case when,性能得到了提升,修改后的语句如下所示。 再看一个例子,下图的例子中,会进行聚集函数的计算,但在下方的case when中频繁引用这些聚集函数,导致聚集函数计算多遍。 经过等价优化后,在子查询中仅计算一遍聚集函数,在父查询的case when中,直接使用计算好的聚集函数的值,避免多次计算,优化后的语句如下图所示。 在应用中,经常出现提取前若干条数据的场景。例如如下语句: 即取按a排序后的从start到end的行数,对应的执行计划如下所示: 我们发现对所有的数据进行了排序,然后返回了前10条数据,数据量较大时,所有数据量全排将大量耗费时间。这种情况下,我们可以在子查询中加入limit语句,这样排序变为top N排序,减少了排序的时间,修改后的语句为: 对应的计划变为: 在GaussDB(DWS)场景中,通常为分析类应用,最终均需要进行聚集操作。通常聚集都是在语句最后进行,起到去重统计的效果。但是,如果去重前的重复值较多,但会显著影响关联的性能,如SQL语句: 其计划如下图所示: t1.c1和t2.c1有大量重复值,导致Join完之后行数激增,Join性能较差,因此需要将Agg下推到Join之前进行,通过提前的Agg操作减少Join结果的行数,修改后的语句为: 我们称这个改写规则为Eager Agg,相反,如果改写后的语句,在子查询中的Agg去重效果不明显,但耗时较长,则可以做反向改写,去除冗余的Agg操作,我们称之为Lazy Agg。 以上只列出了客户场景经常出现的需要改写的语句,当然,要想深得SQL改写精髓,还是要深入了解GaussDB(DWS)实现原理,找到性能瓶颈,才能进行针对性的改写,起到事半功倍的效果。 本文分享自华为云社区《GaussDB(DWS)性能调优系列实战篇四:十八般武艺之SQL改写》,原文作者:两杯咖啡。
(3)Not in场景
select * from t t1 where t1.a not in (select b from t);
复制代码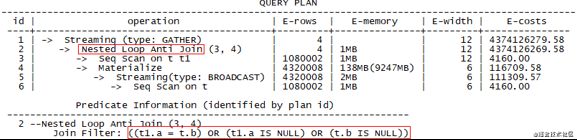
select * from t t1 where not exists (select 1 from t where t.b=t1.a);
复制代码(4)IN list场景
select count(*) from customer where c_customer_sk in (1, 101, 201, 1001, 2001, 10001, 20001, 100001, 200001, 500001, 800001);
复制代码
六.冗余操作导致的坏味道
(1)语句中存在大量冗余case when语句的场景

![]()


(2)排序仅取部分数据的场景
select a from (select a, row_number() over (order by a desc) rid from t1) where rid between 
select a from (select a, row_number() over (order by a desc) rid from t1
limit 
(3)聚集操作顺序出现问题的场景
select t1.c1, count(*) from t1 join t2 on t1.c1=t2.c1 group by t1.c1;
复制代码
select t1.a, c1*c2 from (select t1.a, count(*) c1 from t1 group by t1.a) t1 join (select t2.a, count(*) c2 from t2 group by t2.a) t2 on t1.a=t2.a;
复制代码