简介: 第十一届中国数据库技术大会(DTCC2020),在北京隆重召开。在12.23日性能优化与SQL审计专场上,邀请了阿里巴巴数据库技术团队高级技术专家梁高中为大家介绍DAS之基于Workload的全局自动优化实践。 SQL自动优化是阿里云数据库自治服务重要自治场景之一,该服务支撑阿里巴巴集团全网慢SQL的自动优化,目前已累计自动优化超4900万慢SQL。阿里在构建这一能力过程中有经验也有教训,期望从基于Workload的全局优化能力构建历程、智能化自动优化闭环实践两个方面和大家分享。
SQL自动优化是阿里云数据库自治服务重要自治场景之一,该服务支撑阿里巴巴集团全网慢SQL的自动优化,目前已累计自动优化超4900万慢SQL。阿里在构建这一能力过程中有经验也有教训,期望从基于Workload的全局优化能力构建历程、智能化自动优化闭环实践两个方面和大家分享。

演讲嘉宾简介:
梁高中,阿里巴巴数据库技术团队高级技术专家,2017年加入阿里巴巴集团,目前负责阿里巴巴阿里云数据库自治服务研发负责人。加入阿里巴巴前,曾就职于IBM,华为等,拥有12+年的数据库产品、数据库优化经验,曾担任数据库优化专家系统,跨源跨数据中心联邦数据库等开发团队负责人。
以下内容根据演讲视频以及PPT整理而成。
本次分享主要围绕以下三个方面:
一、SQL优化场景
二、核心诊断能力构建
三、自动优化闭环
一、SQL优化场景
- SQL优化挑战
===========
数据库诊断优化是提高数据库性能和稳定性的关键技术之一, SQL优化是其中至关重要的一环。目前约80%的数据库性能问题可通过SQL优化手段解决。SQL优化目前还是面临着很多挑战,首先,SQL优化需要基于多方面的数据库领域专家知识和经验。而且SQL优化耗时繁重,当面临如阿里这样的大规模的业务场景时,SQL持续优化充满挑战。下图中有一个基于真实业务数据所画出的,随时间变化的数据库慢SQL趋势图
,T1代表着发现数据库实例因慢SQL造成性能异常的时间点,而T2表示优化过程结束,恢复常态时间点。那么T1越短表示发现性能异常的耗费时间越少。其次T2-T1时间是异常处理时长,如果处理时间过长,一方面会严重影响业务,另一方面大大增加故障风险。

- SQL优化三大场景
=============
如果将SQL优化功能提供给用户,主要涉及三种场景。首先是单SQL工具辅助诊断。用户可以选择以单SQL为输入,辅助诊断工具会根据给定SQL及相关环境信息,给出优化建议(改写、最优索引建议等),最大化加速查询。还有基于负载全局辅助诊断工具,主要以Workload负载为优化单位,综合考虑Workload中影响整体性能的特征,实现负载整体性能最大化提升同时最大化降低空间消耗。这两个场景以辅助决策方式,为用户提供SQL诊断和优化。还有一种场景是自动SQL优化,通过构建完善的自动化流程,实现问题SQL识别、优化建议生成、评估自动上线,后续跟踪、收益计算的全自动化流程。
二、核心诊断能力构建
支持SQL优化,就需要对核心诊断能力进行构建。那什么是核心诊断能力?即针对问题SQL,给出非常准确的建议。用户通常会遇到下面几种SQL优化问题。
- 单SQL优化诊断
============
SQL优化的本质是创造条件,发现可以提升的点,如SQL改写,创建SQL索引等,从而让数据库优化器选择最优或者次优的SQL执行计划。下图中间核心位置的是SQL优化引擎,两边是从核心能力衍生出的对外场景,左边是对外提供的SQL自动优化的闭环,右边是为用户提供的SQL优化建议。那么单SQL优化诊断能力的构建面临几个主要的问题,首先是应该采用哪种优化推荐算法?是基于规则方式还是基于代价模型方式?针对WHAT-IF内核能力缺失的数据库,应该如何选择?第二点,足够覆盖度的测试集,既如何构建一个庞大的测试案例库用于其核心能力验证?拥有足够覆盖度,因为准确的测试案例库往往是核心诊断能力构建过程中至关重要的一环。第三点,如何在大规模业务场景下提供诊断服务能力,阿里需要服务于云上几十万级的数据库实例的SQL优化诊断,那么如何实现复杂的计算服务服务化拆分,计算服务的横向伸缩,最大化的并行,资源访问分布式环境下的并发控制,不同优先级的有效调度消除隔离,峰值缓冲等等?第四点,如何让SQL诊断能力持续改进。

单SQL优化诊断 —— 优化推荐算法选择·面临挑战
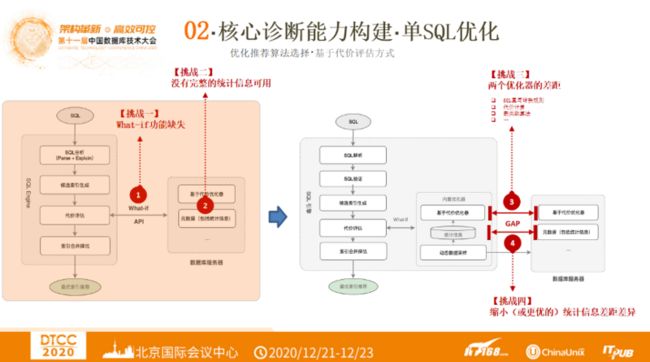
第一类推荐算法是基于规则式的,其明显的特点是基于事先编辑好的规则来优化。第二类是基于代价评估方式。下图左侧是目前传统商业化最优索引推荐引擎架构,SQL导入之后,对其进行分析,生成候选索引。然后通过代价评估,这时会通过数据库服务器WHAT-IF能力获得这些候选索引的代价。基于WHAT-IF接口返回的结果进行代价评估,最后进行最终的索引合并择优。这是传统数据库中基于代价评估的最优索引推荐流程。但是,对于例如MySQL这样的数据库引擎,这个过程中还是面临几个挑战:
挑战一:在MySQL中WHAT-IF功能是缺失的;
挑战二:MySQL中没有完整的统计信息可使用;
因此需要对此架构进行优化,既在SQL引擎和数据库服务器间加一个内置优化器,通过内置优化器提供WHAT-IF功能。但这种架构依然会面临几个挑战:
挑战三:如何最大限度缩小两个优化器的差距;
挑战四:内置优化器中的统计信息与MySQL中的统计信息存在差异,那么应该如何缩小或者优化它们之间的统计信息的差异?
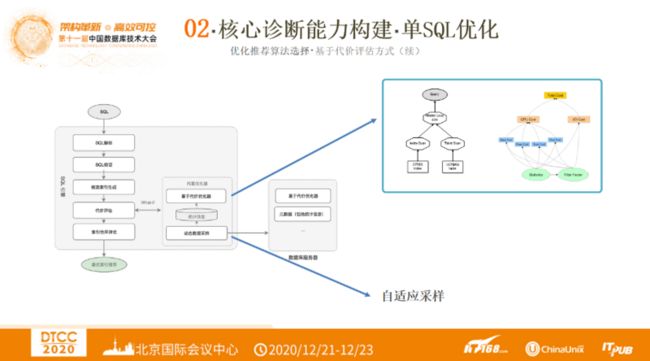
单SQL优化诊断 —— 优化推荐算法选择·基于代价评估方式
首先在内置优化器部分,阿里会在物理计划基础上进行代价评估,然后从中选择。这里与传统数据库中的优化器不同点在于加入候选索引、SQL改写的考量。另外,优化器是基于统计信息进行代价计算,因此在统计信息问题上采用了自适应采样算法,自适应采样实现在指定误差范围内自适应决定数据采样量。还需要注意的一点是数据采样的过程不能对目标数据库实例造成太大的压力。
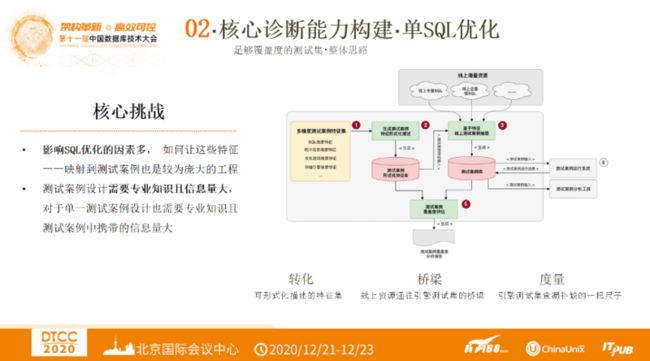
单SQL优化诊断 —— 足够覆盖度的测试集·整体思路
为了保证SQL优化引擎覆盖足够全面,那么就需要足够的测试集。选择测试集时会面临三个问题,首先在选择的测试集中要包含什么样的测试案例?第二点,多少测试案例能够证明已经足够全面?第三点,目前SQL优化引擎的能力在什么位置?测试集的选择之所以困难是因为影响SQL优化的因素太多, 如何让这些特征一一映射到测试案例也是较为庞大的工程。还有,测试案例设计需要专业知识且信息量大,对于单一测试案例设计也需要专业知识且测试案例中携带的信息量大。
测试案例覆盖度分析报告是通过下图右侧的流程来生成,首先是分析影响SQL优化的因素,将其分解为多维度的测试案例特征集。之后通过特征形式化描述,生成测试案例形式化特征库。之后借助阿里丰富的业务场景,收集线上全量SQL及全量慢SQL。然后结合形式化的特征,抽取线上测试案例,生成测试案例库。最后结合测试案例运行系统和测试案例分析工具,评估测试案例覆盖度,生成分析报告。整个过程中首先是在对多维度特征进行形式化转化,然后通过线上资源构建通往引擎测试集的桥梁,另外,对引擎测试集构建查漏补缺的一把尺子。
单SQL优化诊断 —— 足够覆盖度的测试集·测试用例特征化
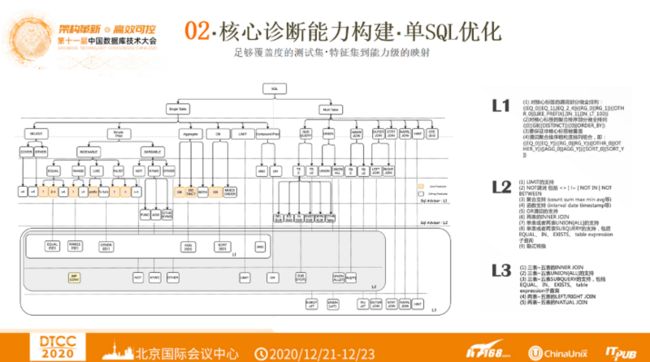
下图展示了测试用例特征化的结构。首先从影响索引选择的因素出发,列出这些因素。然后将SQL分为Single Table 和Multi Table两个场景,分别从影响因素往下分SQL语句。再通过三种场景,完成特征集到能力级的映射。
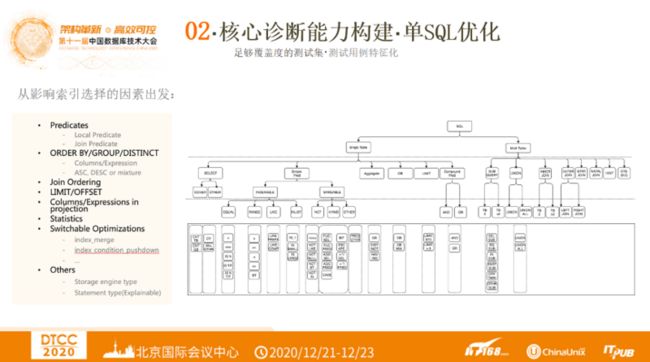
这三种场景分别是L1、L2、L3。L1支持对核心标签谓词部分、聚合排序部分做全排列,保证非核心标签被覆盖,对谓词聚合排序做粗粒度排列组合。L2包括对LIMIT的支持、NOT谓词、聚合支持、函数支持、OR谓词的支持、两表的INNER JOIN、单表或两表的UNION、SUBQUERY支持、隐式转换等。L3包括三表到五表的INNER JOIN、UNION、SUBQUERY、LEFT/RIGHT JOIN、NATUAL JOIN等。
单SQL优化诊断 —— 大规模诊断能力与数据驱动
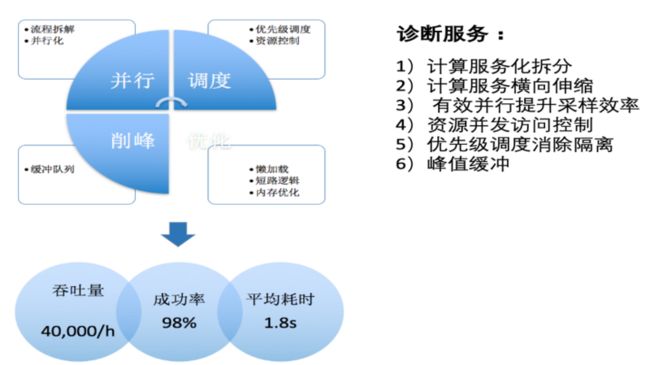
支持大规模的业务场景的诊断服务,SQL优化策略的实践还需要完成很多的事情。首先对计算服务进行拆分、保证计算服务横向伸缩、还要有效保证并行采样效率、控制资源并发访问、消除优先级调度隔离、缓冲业务峰值。这样才能满足在线上支持大规模业务场景的SQL优化的应用。
- 基于Workload全局优化
==================
上面一直在讨论对单SQL的优化策略,那么从支持业务角度而言,还是需要从全局出发,做全局优化。全局优化是以Workload负载为优化单位,综合考虑Workload中影响整体性能的特征,实现负载整体性能最大化提升,同时最大化降低空间消耗。如下图左侧,从全量SQL中提取Workload负载情况,通过SQL全局优化引擎,在考虑存储约束条件S,以及成本约束条件C的情况下,输出需要创建的新索引、需要改写的新索引、需要删除的新索引、并提供SQL改写建议。

下图左侧的表格里是一系列简单的SQL语句和Workload特征,包括INSERT语句,SELECT语句,在每个时间段内执行次数。如果从单SQL优化的角度,会推荐SQL2-SQL6的四条优化语句。但是从Workload全局优化角度考虑会推荐两项SQL优化。Workload全局优化相比与单SQL优化整体RT下降了14.45%,索引空间节省了50%。

三、SQL自动优化闭环
- SQL自动优化闭环 —— 实践效果
=====================
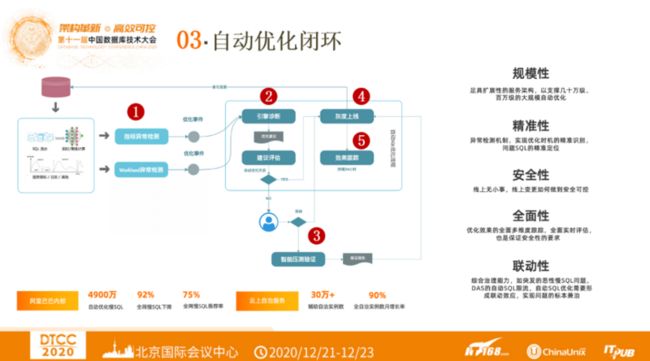
SQL自动优化闭环指的是从问题SQL识别到基于Workload全局优化建议自动生成与评估、优化上线再到量化追踪评估的全自动优化闭环。自动优化闭环将人工的被动式优化转变为以智能化为基础的主动式优化。下图左侧展示了整个SQL自动优化闭环的几个关键优化节点。首先是持续24小时的跟踪,进行指标异常检测和Workload异常检测,发现异常点。之后通过SQL优化引擎,给出优化建议。如果用户采纳自动优化建议,则灰度上线。如果不采纳,则需要通过智能压测验证,再到灰度上线,然后进行优化效果跟踪。
阿里实现了SQL优化的全自动化闭环,自动SQL优化持续保持数据库实例运行在最佳优化状态,目前阿里内部自动优化了4900万慢SQL,全网慢SQL显著下降了92%,全网慢SQL推荐率达到了75%。自动优化闭环在云上辅助自治了30万多的服务实例,全网实例月增长率达到90%。SQL自动优化闭环希望从规模性、精准性、安全性、全面性、联动性等方面持续优化提升,服务更多用户。
- SQL自动优化闭环 —— 生成基于压测的优化收益报告
==============================
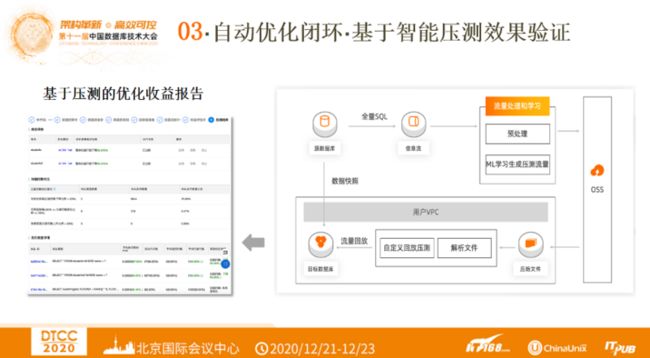
下图左侧是基于压测的优化收益报告。根据SQL优化引擎生成的SQL优化的建议,选取用户真实的负载数据情况,进行压测。压测完成之后生成在真实的场景下对优化建议的综合评估,分析优化收益。
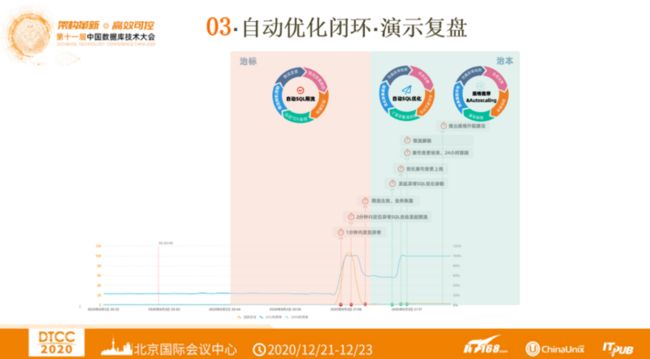
- SQL自动优化闭环 —— 演示复盘
=====================
SQL优化为用户提供了丰富的测试场景,基于SQL自动优化只是其中一个场景。那如何将SQL自动优化与其它测试场景混合到一起?这又将产生什么奇妙的效果?同时可以解决哪些问题?
下图展示了随时间变化的数据库性能变化图,以及过程中SQL自动优化做的事情。图中黄色线条是活跃会话数,深蓝色线条表示CPU利用率,浅蓝色线条是IOPS利用率。第一个阶段是橙黄色部分,既在2020年9月3日21:06 数据库出现异常,此时可以1分钟内发现异常、2分钟内定位异常,并自动发现SQL限流,然后限流生效,黄色活跃会话数回归原位,深蓝色CPU利用率下降,业务恢复正常。到第二阶段绿色部分SQL自动优化启动,在2020年9月3日21:17 发起异常SQL优化诊断,紧接着优化索引变更上线,索引变更结束,进行24小时跟踪,然后解除限流。随即推出规格升配(Autoscaling)建议,根据负载的变
化升级数据库规格。
作者:stromal
原文链接
本文为阿里云原创内容,未经允许不得转载