Python 高效编程小技巧
个人博客:临风|刀背藏身
Python 一直被我拿来写算法题,小程序,因为他使用起来太方便了,各种niubi闪闪的技能点也在写算法的过程中逐渐被挖掘到,感谢万能的谷哥度娘SOF以及各大博客网站,在这里整理一二。
几句废话:
因为我是懒癌晚期,最不喜欢在文章里发图片,因为Mweb写作或者是马克飞象写作,可以直接拖图进来,但是上传博客的话,就需要考虑是使用服务器上的媒体库,还是放七牛,放七牛上还得用它的命令行工具,或者是Web端操作,想想都好麻烦。所以,本地一直存放着几篇写完的文章楞是没有上传(一篇探索红黑树,一篇是设计模式C++版半完全指南,一篇是Linux的小文章),就是因为往里边塞了太多图片的原因。所以以后写文,尽量控制图片 <= 3。
下面进入密集式正题,过于炫技的部分被我去掉了,因为我看过之后只是碎了膝盖,然而并不常用。因为自己很少做整理,现在知道整理的强大之处了,所以以后也会注意相关知识的整理。以下方法的适用场景我也就不用多说了,因为都是最最常见的场景:
1. 拆箱(这个方法比较常见,非常高效)
变量声明利用拆箱这种方式,非常高效,这也算是Python 里最常用的技巧了,也是我最开始使用 Python 时感觉非常惊奇的功能。
>>> a, b, c = 1, 2, 3 >>> a, b, c (1, 2, 3) >>> a, b, c = [1, 2, 3] >>> a, b, c (1, 2, 3) >>> a, b, c = (2 * i + 1 for i in range(3)) >>> a, b, c (1, 3, 5) >>> a, (b, c), d = [1, (2, 3), 4] >>> a, b, c, d 1, 2, 3, 4 拆箱也可用于变量交换
>>> a, b = 1, 2
>>> a, b = b, a >>> a, b (2,1) 2. 指定步长的切割
刚开始接触Python 的时候,被Python 深拷贝的方式逗乐了,写Python 你可以利用想象力写代码。深拷贝利用的就是这个指定步长的切割。
>>> a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> a[::2] [0, 2, 4, 6, 8, 10] >>> a[2:8:2] [2, 4, 6] # 下边这个实现深拷贝 >>> print a[::1] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # 逆序拷贝 >>> print a[::-1] [10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0] # 你还可以给切割的部分赋值,也可以借此插入数组 >>> a = [1, 2, 3, 4, 5] >>> a[2:3] = [0, 0] >>> a [1, 2, 0, 0, 4, 5] >>> a[1:1] = [8, 9] >>> a [1, 8, 9, 2, 0, 0, 4, 5] # 还有命名列表切割方式 >>> a = [0, 1, 2, 3, 4, 5] >>> last_three = slice(-3, None) >>> last_three slice(-3, None, None) >>> a[last_three] [3, 4, 5] 3. 压缩器zip
zip 这个也是靠想象力实现各种各样的功能。
- 列表 or 迭代器的压缩与解压缩
>>> a = [1, 2, 3] >>> b = ['a', 'b', 'c'] >>> z = zip(a, b) >>> z [(1, 'a'), (2, 'b'), (3, 'c')] >>> zip(*z) [(1, 2, 3), ('a', 'b', 'c')] - 列表相邻元素压缩器
>>> a = [1, 2, 3, 4, 5, 6] >>> zip(*([iter(a)] * 2)) [(1, 2), (3, 4), (5, 6)] >>> group_adjacent = lambda a, k: zip(*([iter(a)] * k)) >>> group_adjacent(a, 3) [(1, 2, 3), (4, 5, 6)] >>> group_adjacent(a, 2) [(1, 2), (3, 4), (5, 6)] >>> group_adjacent(a, 1) [(1,), (2,), (3,), (4,), (5,), (6,)] >>> zip(a[::2], a[1::2]) [(1, 2), (3, 4), (5, 6)] >>> zip(a[::3], a[1::3], a[2::3]) [(1, 2, 3), (4, 5, 6)] >>> group_adjacent = lambda a, k: zip(*(a[i::k] for i in range(k))) >>> group_adjacent(a, 3) [(1, 2, 3), (4, 5, 6)] >>> group_adjacent(a, 2) [(1, 2), (3, 4), (5, 6)] >>> group_adjacent(a, 1) [(1,), (2,), (3,), (4,), (5,), (6,)] - 用压缩器翻转字典
>>> m = {
'a': 1, 'b': 2, 'c': 3, 'd': 4} >>> m.items() [('a', 1), ('c', 3), ('b', 2), ('d', 4)] >>> zip(m.values(), m.keys()) [(1, 'a'), (3, 'c'), (2, 'b'), (4, 'd')] >>> mi = dict(zip(m.values(), m.keys())) >>> mi { 1: 'a', 2: 'b', 3: 'c', 4: 'd'} 4. 列表展开
列表展开的方式五花八门,动用大脑可以创造各种各样的方法,最便于理解的是以下两种:
>>> a = [[1, 2], [3, 4], [5, 6]] >>> sum(a, []) [1, 2, 3, 4, 5, 6] >>> [x for l in a for x in l] [1, 2, 3, 4, 5, 6] 5. 生成器表达式
>>> g = (x ** 2 for x in xrange(10)) >>> next(g) 0 >>> next(g) 1 >>> next(g) 4 >>> sum(x ** 3 for x in xrange(10)) 2025 >>> sum(x ** 3 for x in xrange(10) if x % 3 == 1) 408 6. 字典推导和集合推导
一上来我打成了推倒是什么心理,相信在平时推导过列表,他还有更多的应用方式。
# 这个是最常见的推导
>>> list1 = [1,2,3,4,5] >>> list2 = [x + 1 for x in list1] >>> list2 [2, 3, 4, 5, 6] # 我们可以用语法来创建集合和字典表,开开脑洞 >>> some_list = [1, 2, 3, 4, 5, 2, 5, 1, 4, 8] >>> even_set = { x for x in some_list if x % 2 == 0 } >>> even_set set([8, 2, 4]) # 其实,我们有更简单的方式创建一个集合: >>> setlist = { 1,2,3,4,5,2,3,4} >>> setlist set([1,2,3,4,5]) # 创建字典表 >>> d = { x: x % 2 == 0 for x in range(1, 11) } >>> d { 1: False, 2: True, 3: False, 4: True, 5: False, 6: True, 7: False, 8: True, 9: False, 10: True} # 利用这个脑洞,你还可以用字典推导翻转字典 >>> m = { 'a': 1, 'b': 2, 'c': 3, 'd': 4} >>> m { 'd': 4, 'a': 1, 'b': 2, 'c': 3} >>> {v: k for k, v in m.items()} { 1: 'a', 2: 'b', 3: 'c', 4: 'd'} 另外,刚刚提到了,直接省略set 方式的创建集合,它还有一些在这基础之上更犀利的应用。
>>> A = {
1, 2, 3, 3} >>> A set([1, 2, 3]) >>> B = { 3, 4, 5, 6, 7} >>> B set([3, 4, 5, 6, 7]) >>> A | B set([1, 2, 3, 4, 5, 6, 7]) >>> A & B set([3]) >>> A - B set([1, 2]) >>> B - A set([4, 5, 6, 7]) >>> A ^ B set([1, 2, 4, 5, 6, 7]) >>> (A ^ B) == ((A - B) | (B - A)) True 7. Counter 计数器
对于我们来说,数一个东西,是非常常用的,然而这件事又不是程序员喜欢做的事情,我们用 counter 来完成这个操作。他在我们python 内置的库里。
>>> from collections import Counter
>>> c = Counter('hello world') >>> c Counter({ 'l': 3, 'o': 2, ' ': 1, 'e': 1, 'd': 1, 'h': 1, 'r': 1, 'w': 1}) >>> c.most_common(2) [('l', 3), ('o', 2)] 8. 双端队列
我们都知道,队列和栈实际上就是对在双端队列的基础上实现的,python可以直接操作双端队列。当然也在内置的库 collections 里。
>>> Q = collections.deque()
>>> Q.append(1)
>>> Q.appendleft(2) >>> Q.extend([3, 4]) >>> Q.extendleft([5, 6]) >>> Q deque([6, 5, 2, 1, 3, 4]) >>> Q.pop() 4 >>> Q.popleft() 6 >>> Q deque([5, 2, 1, 3]) >>> Q.rotate(3) >>> Q deque([2, 1, 3, 5]) >>> Q.rotate(-3) >>> Q deque([5, 2, 1, 3]) 同时,我们还可以在括号里添加 maxlen 来限制双端队列的最大长度。last_three = collections.deque(maxlen=3)
9. 默认词典
一般情况下,空词典它就是空的,但是我们利用 collections 里的函数,可以实现默认的字典。
>>> m = dict()
>>> m['a']
Traceback (most recent call last):
File "", line 1, in KeyError: 'a' # 你可以在括号里添加各种条件 >>> m = collections.defaultdict(int) >>> m['a'] 0 >>> m['b'] 0 >>> m = collections.defaultdict(str) >>> m['a'] '' >>> m['b'] += 'a' >>> m['b'] 'a' >>> m = collections.defaultdict(lambda: '[default value]') >>> m['a'] '[default value]' >>> m['b'] '[default value]' 10. 利用json库打印出漂亮的JSON串
这个方法就是为了让让人面对眼花缭乱的JSON串,能够打印出一个漂亮的可读的格式,对于在控制台交互编程,或者是做日志是,还是非常有用的。另外,也可以注意一下pprint 这个模块。
import json
data = {
"status": "OK", "count": 2, "results": [{ "age": 27, "name": "Oz", "lactose_intolerant": true}, { "age": 29, "name": "Joe", "lactose_intolerant": false}]} >>> print(json.dumps(data)) # No indention { "status": "OK", "count": 2, "results": [{ "age": 27, "name": "Oz", "lactose_intolerant": true}, { "age": 29, "name": "Joe", "lactose_intolerant": false}]} >>> print(json.dumps(data, indent=2)) { "status": "OK", "count": 2, "results": [ { "age": 27, "name": "Oz", "lactose_intolerant": true }, { "age": 29, "name": "Joe", "lactose_intolerant": false } ] } 11. 最大和最小的几个列表元素
这个经常用到啊,少年们。
import random, heapq
a = [random.randint(0, 100) for __ in xrange(100)] b = heapq.nsmallest(5, a) c = heapq.nlargest(5, a) print b,c [1, 2, 3, 5, 7] [100, 100, 100, 99, 98] 12. 一些更贴近大脑的写法,和一些掉了下巴的代码段
有一些语句,写出来你就能读懂,就像读一篇文章一样。有时候,其他语言用了超长的代码写出来的程序,python只需要几行,甚至是,1行。
- 数值比较
x = 2
if 3 > x > 1: print x >>> 2 if 1 < x > 0: print x >>> 2 - 有这么一个算法题,打印数字1到100,3的倍数打印“Fizz”来替换这个数,5的倍数打印“Buzz”,对于既是3的倍数又是5的倍数的数字打印“FizzBuzz”。对此,我们只使用一行代码,搞定它.
for x in range(1, 101):print"fizz"[x % 3*4::]+"buzz"[x % 5*4::]or x 13. 一个超小型的Web服务
我们在两台机器或者服务器之间做一些简单的基础的RPC之类的交互,我们就可以用到python 这个神奇的模块。
服务器:
from SimpleXMLRPCServer import SimpleXMLRPCServer
def file_reader(file_name): with open(file_name, 'r') as f: return f.read() server = SimpleXMLRPCServer(('localhost', 8000)) server.register_introspection_functions() server.register_function(file_reader) server.serve_forever() 客户端:
import xmlrpclib
proxy = xmlrpclib.ServerProxy('http://localhost:8000/')
proxy.file_reader('/tmp/secret.txt')
这样就得到了一个远程文件读取工具,超小型,没有外部依赖,当然没有任何安全可言,仅作家里使用,当然我现在还没用过这个。
随着近几年人工智能的流行,从而引发了一个编程语言的兴起,我想说到这,大家应该都明白了这是什么吧,没错它就是大名鼎鼎的——Python
对于python,我给大家总结了以下几点:Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。Python 是交互式语言: 这意味着,您可以在一个Python提示符,直接互动执行写你的程序。Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。在这里,我给大家就分享一个关于Python的奇技淫巧吧!1.控制台操作控制台不闪退
os.system('pause')2.获取控制台大小
rows, columns = os.popen('stty size', 'r').read().split()3.输入输出控制解决输入提示中文乱码问题
raw_input(unicode('请输入文字','utf-8').encode('gbk'))4.格式化输出
print a.prettify()5.接受多行输入
text=""while1:data=raw_input(">>")if data.strip()=="stop":breaktext+="%s " % dataprint text--------------------------->>1>>2>>3>>stop1236.同行输出
Print'%s' % a,Print'%s ' % a7.标准输入输出
sys.stdout.write("input") 标准输入sys.stdout.flush() 刷新缓冲区8.print的功能与sys.stdout.write类似,因为2.x中print默认就是将输出指定到标准输出中(sys.stdout)。颜色控制控制台颜色控制(适用于windows)
WConio.textcolor(WConio.YELLOW)print"yellow"WConio.textcolor(WConio.BLUE)print"blue"9.输出颜色控制(全平台)
red = '[1;31m'green = '[1;32m'yellow = '[1;33m'white = '[1;37m'reset = '[0m’print red+"color is red"+resetprint green+"color is green"+reset10.进度条控制
方案一from __future__ import divisionimport sys,timej = '#'for i in range(1,61):j += '#'sys.stdout.write(str(int((i/60)*100))+'% ||'+j+'->'+" ")sys.stdout.flush()time.sleep(0.1)方案二import sysimport timefor i in range(1,61):sys.stdout.write('#'+'->'+"")sys.stdout.flush()time.sleep(0.5)方案三from progressbar import *import timeimport osrows, columns = os.popen('stty size', 'r').read().split() #获取控制台sizeconsole_width=int(columns)total = 10progress = ProgressBar()deftest():'''进度条函数,记录进度'''for i in progress(range(total)):test2()deftest2():'''执行函数,输出结果'''content="nMask'Blog is http://thief.one"sys.stdout.write(" "+content+" "*(console_width-len(content)))time.sleep(1)sys.stdout.flush()test()11.更多高级用法可以使用progressbar模块。系统操作系统信息获取python安装路径
from distutils.sysconfig import get_python_libprint get_python_lib12.获取当前时间
c=time.ctime()#自定义格式输出ISOTIMEFORMAT=’%Y-%m-%d %X’time.strftime( ISOTIMEFORMAT, time.localtime() )13.查看系统环境变量
os.environ["PATH"]14.获取系统磁盘
os.popen("wmic VOLUME GET Name")15.获取当前路径(包括当前py文件名)
os.path.realpath(__file__)16.当前平台使用的行终止符
os.linesep17.获取终端大小
rows, columns = os.popen('stty size', 'r').read().split()#python3以后存在可以使用osos.get_termial_size()18.退出程序
return:返回函数的值,并退出函数。exit():直接退出。sys.exit(): 引发一个SystemExit异常,若没有捕获错误,则python程序直接退出;捕获异常后,可以做一些额外的清理工作。sys.exit(0):为正常退出,其他(1-127)为不正常,可抛异常事情供捕获。(一般用于主线程中退出程序)os._exit(0): 直接退出python程序,其后的代码也不会执行。(一般用于线程中退出程序)

19.网络操作域名解析为ip
ip= socket.getaddrinfo(domain,'http')[0][4][0]获取服务器版本信息
sUrl = 'http://www.163.com'sock = urllib2.urlopen(sUrl)sock.headers.values()20.文件操作输出一个目录下所有文件名称
defsearch(paths):if os.path.isdir(paths): #如果是目录files=os.listdir(paths) #列出目录中所有的文件for i in files:i=os.path.join(paths,i) #构造文件路径search(i) #递归elif os.path.isfile(paths): #如果是文件print paths #输出文件名21.文件查找
import globprint glob.glob(r"E:/*.txt") #返回的是一个列表查找文件只用到三个匹配符:”*”, “?”, “[]“”*”匹配0个或多个字符;”?”匹配单个字符;”[]“匹配指定范围内的字符,如:[0-9]匹配数字。22.查找指定名称的文件夹的路径
defsearch(paths,file_name,tag,lists):if os.path.isdir(paths): #如果是目录if file_name==tag: #如果目录名称为taglists.append(paths) #将该路径添加到列表中else: #如果目录名称不为tagtry:files_list=os.listdir(paths) #列出目录中所有的文件for file_name in files_list:path_new=os.path.join(paths,file_name) #构造文件路径search(path_new,file_name,tag,lists) #递归except: #遇到特殊目录名时会报错passelif os.path.isfile(paths): #如果是文件passreturn lists23.数据操作判断数据类型
isinstance("123",(int,long,float,complex)24.字符串(string)去掉小数点后面的数字
a=1.21311b=Int(math.floor(a))25.字符串倒置
>>> a = "codementor">>> a[::-1]26.字符串首字母变大写
info = 'ssfef'print info.capitalize()print info.title()27.返回一个字符串居中,并使用空格填充至长度width的新字符串。
"center string".center(width) #width设置为控制台宽度,可控制输出的字符串居中。28.列举所有字母
printstring.ascii_uppercase 所有大写字母printstring. ascii_lowercase 所有小写字母printstring.ascii_letters 所有字母(包括大小写)29.列表(list)列表去重
ids = [1,4,3,3,4,2,3,4,5,6,1]ids = list(set(ids))30.列表运算
a=[1,2,3]b=[3,4,5]set(a)&set(b) 与set(a)|set(b) 或set(a)-set(b) 非31.单列表元素相加
a = ["Code", "mentor", "Python", "Developer"]>>> print " ".join(a)Code mentor Python Developer32.多列表元素分别相加
list1 = ['a', 'b', 'c', 'd']list2 = ['p', 'q', 'r', 's']>>> for x, y in zip(list1,list2):print x, yapbqcrds33.将嵌套列表转换成单一列表
a = [[1, 2], [3, 4], [5, 6]]>>> import itertools>>> list(itertools.chain.from_iterable(a))[1, 2, 3, 4, 5, 6]34.列表内元素相加
a=[1,2,3](数字)sum(a)35.产生a-z的字符串列表
map(chr,range(97,123))36.列表复制
a=[1,2,3]b=a当对b进行操作时,会影响a的内容,因为共用一个内存指针,b=a[:] 这样就是单独复制一份了。37.列表解析if+else配合列表解析
[i if i >5 else -i for i in range(10)]38.字典操作(dict)筛选出值重复的key
list1=self.dict_ip.items()ddict=defaultdict(list)for k,v in list1:ddict[v].append(k)list2=[(i,ddict) for i in ddict if len(ddict)>1]dict_ns=dict(list2)39.字典排序(py2)
file_dict={"a":1,"b":2,"c":3}file_dict_new=sorted(file_dict.iteritems(), key=operator.itemgetter(1),reverse=True) ##字典排序,reverse=True由高到低,itemgetter(1)表示按值排序,为0表示按key排序。40.模块操作导入模块时,设置只允许导入的属性或者方法。
deftest(a,b):return a+breduce(test,range(10))结果:从0+1+2......+9
显示有限的接口到外部
当发布python第三方package时,并不希望代码中所有的函数或者class可以被外部import,在__init__.py中添加__all__属性,该list中填写可以import的类或者函数名, 可以起到限制的import的作用, 防止外部import其他函数或者类。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#!/usr/bin/env python
# -*- coding: utf-
8
-*-
from base
import
APIBase
from client
import
Client
from decorator
import
interface
, export, stream
from server
import
Server
from storage
import
Storage
from util
import
(LogFormatter, disable_logging_to_stderr,
enable_logging_to_kids, info)
__all__ = [
'APIBase'
,
'Client'
,
'LogFormatter'
,
'Server'
,
'Storage'
,
'disable_logging_to_stderr'
,
'enable_logging_to_kids'
,
'export'
,
'info'
,
'interface'
,
'stream'
]
|
with的魔力
with语句需要支持上下文管理协议的对象, 上下文管理协议包含__enter__和__exit__两个方法。 with语句建立运行时上下文需要通过这两个方法执行进入和退出操作。
其中上下文表达式是跟在with之后的表达式, 该表达式返回一个上下文管理对象。
# 常见with使用场景
with open("test.txt", "r") as my_file: # 注意, 是__enter__()方法的返回值赋值给了my_file,
for line in my_file:
print line
详细原理可以查看这篇文章, 浅谈 Python 的 with 语句。
知道具体原理,我们可以自定义支持上下文管理协议的类,类中实现__enter__和__exit__方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
|
#!/usr/bin/env python
# -*- coding: utf-
8
-*-
class
MyWith(object):
def __init__(self):
print
"__init__ method"
def __enter__(self):
print
"__enter__ method"
return
self # 返回对象给as后的变量
def __exit__(self, exc_type, exc_value, exc_traceback):
print
"__exit__ method"
if
exc_traceback is None:
print
"Exited without Exception"
return
True
else
:
print
"Exited with Exception"
return
False
def test_with():
with MyWith() as my_with:
print
"running my_with"
print
"------分割线-----"
with MyWith() as my_with:
print
"running before Exception"
raise Exception
print
"running after Exception"
if
__name__ ==
'__main__'
:
test_with()
执行结果如下:
__init__ method
__enter__ method
running my_with
__exit__ method
Exited without Exception
------分割线-----
__init__ method
__enter__ method
running before Exception
__exit__ method
Exited with Exception
Traceback (most recent call last):
File
"bin/python"
, line
34
, in
exec(compile(__file__f.read(), __file__,
"exec"
))
File
"test_with.py"
, line
33
, in
test_with()
File
"test_with.py"
, line
28
, in test_with
raise Exception
Exception
证明了会先执行__enter__方法, 然后调用with内的逻辑, 最后执行__exit__做退出处理, 并且, 即使出现异常也能正常退出
filter的用法
相对filter而言, map和reduce使用的会更频繁一些, filter正如其名字, 按照某种规则过滤掉一些元素。
#!/usr/bin/env python
# -*- coding: utf-
8
-*-
lst = [
1
,
2
,
3
,
4
,
5
,
6
]
# 所有奇数都会返回True, 偶数会返回False被过滤掉
print filter(lambda x: x %
2
!=
0
, lst)
#输出结果
[
1
,
3
,
5
]
一行作判断
当条件满足时, 返回的为等号后面的变量, 否则返回
else
后语句。
lst = [
1
,
2
,
3
]
new_lst = lst[
0
]
if
lst is not None
else
None
print new_lst
# 打印结果
|
1
装饰器之单例
使用装饰器实现简单的单例模式
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
# 单例装饰器
def singleton(cls):
instances = dict() # 初始为空
def _singleton(*args, **kwargs):
if
cls not in instances: #如果不存在, 则创建并放入字典
instances[cls] = cls(*args, **kwargs)
return
instances[cls]
return
_singleton
@singleton
class
Test(object):
pass
if
__name__ ==
'__main__'
:
t1 = Test()
t2 = Test()
# 两者具有相同的地址
print t1, t2
staticmethod装饰器
类中两种常用的装饰, 首先区分一下他们:
普通成员函数, 其中第一个隐式参数为对象
classmethod装饰器, 类方法(给人感觉非常类似于OC中的类方法), 其中第一个隐式参数为类
staticmethod装饰器, 没有任何隐式参数. python中的静态方法类似与C++中的静态方法
#!/usr/bin/env python
# -*- coding: utf-
8
-*-
class
A(object):
# 普通成员函数
def foo(self, x):
print
"executing foo(%s, %s)"
% (self, x)
@classmethod
# 使用classmethod进行装饰
def class_foo(cls, x):
print
"executing class_foo(%s, %s)"
% (cls, x)
@staticmethod
# 使用staticmethod进行装饰
def static_foo(x):
print
"executing static_foo(%s)"
% x
def test_three_method():
obj = A()
# 直接调用噗通的成员方法
obj.foo(
"para"
) # 此处obj对象作为成员函数的隐式参数, 就是self
obj.class_foo(
"para"
) # 此处类作为隐式参数被传入, 就是cls
A.class_foo(
"para"
) #更直接的类方法调用
obj.static_foo(
"para"
) # 静态方法并没有任何隐式参数, 但是要通过对象或者类进行调用
A.static_foo(
"para"
)
if
__name__ ==
'__main__'
:
test_three_method()
# 函数输出
executing foo(<__main__.A object at
0x100ba4e10
>, para)
executing class_foo(, para)
executing class_foo(, para)
executing static_foo(para)
executing static_foo(para)
|
property装饰器
定义私有类属性
将property与装饰器结合实现属性私有化(更简单安全的实现get和set方法)。
#python内建函数
property(fget=None, fset=None, fdel=None, doc=None)
fget是获取属性的值的函数,fset是设置属性值的函数,fdel是删除属性的函数,doc是一个字符串(像注释一样)。从实现来看,这些参数都是可选的。
property有三个方法getter(), setter()和delete() 来指定fget, fset和fdel。 这表示以下这行:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class
Student(object):
@property
#相当于property.getter(score) 或者property(score)
def score(self):
return
self._score
@score
.setter #相当于score = property.setter(score)
def score(self, value):
if
not isinstance(value,
int
):
raise ValueError(
'score must be an integer!'
)
if
value <
0
or value >
100
:
raise ValueError(
'score must between 0 ~ 100!'
)
self._score = value
|
iter魔法
通过yield和__iter__的结合,我们可以把一个对象变成可迭代的
通过__str__的重写, 可以直接通过想要的形式打印对象
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#!/usr/bin/env python
# -*- coding: utf-
8
-*-
class
TestIter(object):
def __init__(self):
self.lst = [
1
,
2
,
3
,
4
,
5
]
def read(self):
for
ele in xrange(len(self.lst)):
yield ele
def __iter__(self):
return
self.read()
def __str__(self):
return
','
.join(map(str, self.lst))
__repr__ = __str__
def test_iter():
obj = TestIter()
for
num in obj:
print num
print obj
if
__name__ ==
'__main__'
:
test_iter()
|
神奇partial
partial使用上很像C++中仿函数(函数对象)。
在stackoverflow给出了类似与partial的运行方式:
|
1
2
3
4
5
6
7
8
9
10
11
|
def partial(func, *part_args):
def wrapper(*extra_args):
args = list(part_args)
args.extend(extra_args)
return
func(*args)
return
wrapper
|
利用用闭包的特性绑定预先绑定一些函数参数,返回一个可调用的变量, 直到真正的调用执行:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
#!/usr/bin/env python
# -*- coding: utf-
8
-*-
from functools
import
partial
def sum(a, b):
return
a + b
def test_partial():
fun = partial(sum,
2
) # 事先绑定一个参数, fun成为一个只需要一个参数的可调用变量
print fun(
3
) # 实现执行的即是sum(
2
,
3
)
if
__name__ ==
'__main__'
:
test_partial()
# 执行结果
|
5
神秘eval
eval我理解为一种内嵌的python解释器(这种解释可能会有偏差), 会解释字符串为对应的代码并执行, 并且将执行结果返回。
看一下下面这个例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#!/usr/bin/env python
# -*- coding: utf-
8
-*-
def test_first():
return
3
def test_second(num):
return
num
action = { # 可以看做是一个sandbox
"para"
:
5
,
"test_first"
: test_first,
"test_second"
: test_second
}
def test_eavl():
condition =
"para == 5 and test_second(test_first) > 5"
res = eval(condition, action) # 解释condition并根据action对应的动作执行
print res
if
__name__ == '_
exec
|
exec在Python中会忽略返回值, 总是返回None, eval会返回执行代码或语句的返回值
exec和eval在执行代码时, 除了返回值其他行为都相同
在传入字符串时, 会使用compile(source, ‘’, mode)编译字节码。 mode的取值为exec和eval
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
#!/usr/bin/env python
# -*- coding: utf-
8
-*-
def test_first():
print
"hello"
def test_second():
test_first()
print
"second"
def test_third():
print
"third"
action = {
"test_second"
: test_second,
"test_third"
: test_third
}
def test_exec():
exec
"test_second"
in action
if
__name__ ==
'__main__'
:
test_exec() # 无法看到执行结果
getattr
|
getattr(object, name[, default])返回对象的命名属性,属性名必须是字符串。如果字符串是对象的属性名之一,结果就是该属性的值。例如, getattr(x, ‘foobar’) 等价于 x.foobar。 如果属性名不存在,如果有默认值则返回默认值,否则触发 AttributeError 。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
|
# 使用范例
class
TestGetAttr(object):
test =
"test attribute"
def say(self):
print
"test method"
def test_getattr():
my_test = TestGetAttr()
try
:
print getattr(my_test,
"test"
)
except AttributeError:
print
"Attribute Error!"
try
:
getattr(my_test,
"say"
)()
except AttributeError: # 没有该属性, 且没有指定返回值的情况下
print
"Method Error!"
if
__name__ ==
'__main__'
:
test_getattr()
# 输出结果
test attribute
test method
命令行处理
def process_command_line(argv):
""
"
Return a
2
-tuple: (settings object, args list).
`argv` is a list of arguments, or `None`
for
``sys.argv[
1
:]``.
""
"
if
argv is None:
argv = sys.argv[
1
:]
# initialize the parser object:
parser = optparse.OptionParser(
formatter=optparse.TitledHelpFormatter(width=
78
),
add_help_option=None)
# define options here:
parser.add_option( # customized description; put --help last
'-h'
,
'--help'
, action=
'help'
,
help=
'Show this help message and exit.'
)
settings, args = parser.parse_args(argv)
# check number of arguments, verify values, etc.:
if
args:
parser.error(
'program takes no command-line arguments; '
'"%s" ignored.'
% (args,))
# further process settings & args
if
necessary
return
settings, args
def main(argv=None):
settings, args = process_command_line(argv)
# application code here, like:
# run(settings, args)
return
0
# success
if
__name__ ==
'__main__'
:
status = main()
sys.exit(status)
读写csv文件
# 从csv中读取文件, 基本和传统文件读取类似
import
csv
with open(
'data.csv'
,
'rb'
) as f:
reader = csv.reader(f)
for
row in reader:
print row
# 向csv文件写入
import
csv
with open(
'data.csv'
,
'wb'
) as f:
writer = csv.writer(f)
writer.writerow([
'name'
,
'address'
,
'age'
]) # 单行写入
data = [
(
'xiaoming '
,
'china'
,
'10'
),
(
'Lily'
,
'USA'
,
'12'
)]
writer.writerows(data) # 多行写入
|
各种时间形式转换
只发一张网上的图, 然后查文档就好了, 这个是记不住的
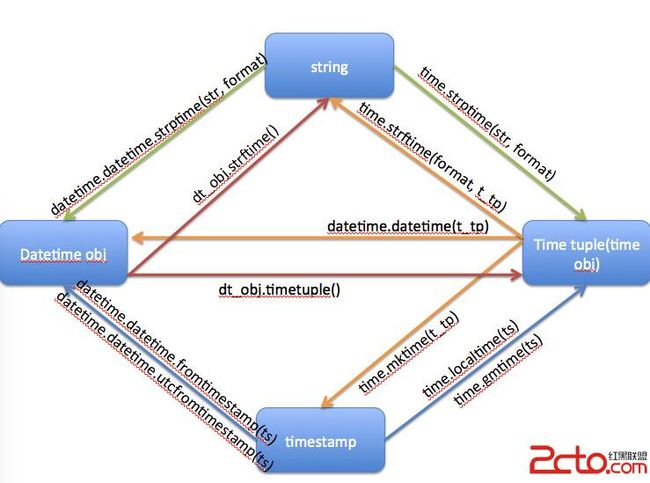
字符串格式化
一个非常好用, 很多人又不知道的功能:
|
1
2
3
4
5
|
>>> name =
"andrew"
>>>
"my name is {name}"
.format(name=name)
'my name is andrew'
|
python奇技淫巧
叶落下了思念,风摇曳那些岁岁年年
本文用作记录,在使用python过程中遇到的一些奇技淫巧,有些代码是本人所写,有些则是python内置函数,有些则取之互联网。在此记录,只为备份以及遗忘时方便查找。
本文将会持续更新,内容仅限记录一些常用好用却又永远记不住的代码或者模块。
控制台操作
控制台不闪退
|
1
|
os.system(
'pause')
|
获取控制台大小
|
1
|
rows, columns = os.popen(
'stty size', 'r').read().split()
|
输入输出控制
解决输入提示中文乱码问题
|
1
|
raw_input(unicode(
'请输入文字','utf-8').encode('gbk'))
|
格式化输出
|
1
|
print a.prettify()
|
接受多行输入
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
text=
""
while 1:
data=raw_input(
">>")
if data.strip()=="stop":
break
text+=
"%s\n" % data
print text
---------------------------
>>1
>>2
>>3
>>stop
1
2
3
|
同行输出
|
1
2
|
Print
'%s' % a,
Print
'%s \r' % a
|
标准输入输出
|
1
2
|
sys.stdout.write(
"input") 标准输入
sys.stdout.flush() 刷新缓冲区
|
print的功能与sys.stdout.write类似,因为2.x中print默认就是将输出指定到标准输出中(sys.stdout)。
颜色控制
控制台颜色控制(适用于windows)
|
1
2
3
4
|
WConio.textcolor(WConio.YELLOW)
print "yellow"
WConio.textcolor(WConio.BLUE)
print "blue"
|
输出颜色控制(全平台)
|
1
2
3
4
5
6
7
8
|
red =
'\033[1;31m'
green =
'\033[1;32m'
yellow =
'\033[1;33m'
white =
'\033[1;37m'
reset =
'\033[0m’
print red+"color is red"+reset
print green+"color is green"+reset
|
进度条控制
方案一
|
1
2
3
4
5
6
7
8
|
from __future__ import division
import sys,time
j =
'#'
for i in range(1,61):
j +=
'#'
sys.stdout.write(str(int((i/60)*100))+
'% ||'+j+'->'+"\r")
sys.stdout.flush()
time.sleep(0.1)
|
方案二
|
1
2
3
4
5
6
|
import sys
import time
for i in range(1,61):
sys.stdout.write(
'#'+'->'+"\b\b")
sys.stdout.flush()
time.sleep(0.5)
|
方案三
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from progressbar import *
import time
import os
rows, columns = os.popen(
'stty size', 'r').read().split() #获取控制台size
console_width=int(columns)
total = 10
progress = ProgressBar()
def
test():
'''
进度条函数,记录进度
'
''
for i in progress(range(total)):
test2()
def test2():
'''
执行函数,输出结果
'
''
content=
"nMask'Blog is http://thief.one"
sys.stdout.write(
"\r"+content+" "*(console_width-len(content)))
time.sleep(1)
sys.stdout.flush()
test()
|
更多高级用法可以使用progressbar模块。
系统操作
系统信息
获取python安装路径
|
1
2
|
from distutils.sysconfig import get_python_lib
print get_python_lib
|
获取当前python版本
|
1
2
|
sys.version_info
sys.version
|
获取当前时间
|
1
2
3
4
|
c=time.ctime()
#自定义格式输出
ISOTIMEFORMAT=’%Y-%m-%d %X’
time.strftime( ISOTIMEFORMAT, time.localtime() )
|
查看系统环境变量
|
1
|
os.environ[
"PATH"]
|
获取系统磁盘
|
1
|
os.popen(
"wmic VOLUME GET Name")
|
获取当前路径(包括当前py文件名)
|
1
|
os.path.realpath(__file__)
|
当前平台使用的行终止符
|
1
|
os.linesep
|
获取终端大小
|
1
2
3
|
rows, columns = os.popen(
'stty size', 'r').read().split()
#python3以后存在可以使用os
os.get_termial_size()
|
退出程序
- return:返回函数的值,并退出函数。
- exit():直接退出。
- sys.exit(): 引发一个SystemExit异常,若没有捕获错误,则python程序直接退出;捕获异常后,可以做一些额外的清理工作。
- sys.exit(0):为正常退出,其他(1-127)为不正常,可抛异常事情供捕获。(一般用于主线程中退出程序)
- os._exit(0): 直接退出python程序,其后的代码也不会执行。(一般用于线程中退出程序)
网络操作
域名解析为ip
|
1
|
ip= socket.getaddrinfo(domain,
'http')[0][4][0]
|
获取服务器版本信息
|
1
2
3
|
sUrl =
'http://www.163.com'
sock = urllib2.urlopen(sUrl)
sock.headers.values()
|
文件操作
open函数,使用wb、rb代替w、r
|
1
2
|
with open(
"test.txt","wr") as w:
w.write(
"test")
|
这种写法可以兼容python2/3。
输出一个目录下所有文件名称
|
1
2
3
4
5
6
7
8
|
def search(paths):
if os.path.isdir(paths): #如果是目录
files=os.listdir(paths)
#列出目录中所有的文件
for i in files:
i=os.path.join(paths,i)
#构造文件路径
search(i)
#递归
elif os.path.isfile(paths): #如果是文件
print paths #输出文件名
|
文件查找
|
1
2
3
4
5
6
|
import glob
print glob.glob(r"E:/*.txt") #返回的是一个列表
查找文件只用到三个匹配符:”*”, “?”, “[]“
”*”匹配0个或多个字符;
”?”匹配单个字符;
”[]“匹配指定范围内的字符,如:[0-9]匹配数字。
|
查找指定名称的文件夹的路径
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
def search(paths,file_name,tag,lists):
if os.path.isdir(paths): #如果是目录
if file_name==tag: #如果目录名称为tag
lists.append(paths)
#将该路径添加到列表中
else: #如果目录名称不为tag
try:
files_list=os.listdir(paths)
#列出目录中所有的文件
for file_name in files_list:
path_new=os.path.join(paths,file_name)
#构造文件路径
search(path_new,file_name,tag,lists)
#递归
except:
#遇到特殊目录名时会报错
pass
elif os.path.isfile(paths): #如果是文件
pass
return lists
|
数据操作
判断数据类型
|
1
|
isinstance(
"123",(int,long,float,complex)
|
字符串(string)
字符串推导
|
1
2
3
4
|
a=
"True"
b=a
if a=="True" else "False"
>>>
print b
True
|
format方法拼接字符串与变量
|
1
2
3
4
5
6
7
|
a=
"{test} abc {test2}".format(test="123",test2="456")
>>>>
print a
123 abc 456
或者:
a=
"{},{}".format(1,2)
>>>>>
print a
1,2
|
去掉小数点后面的数字
|
1
2
|
a=1.21311
b=Int(math.floor(a))
|
字符串倒置
|
1
2
|
>>> a =
"codementor"
>>> a[::-1]
|
字符串首字母变大写
|
1
2
3
|
info =
'ssfef'
print info.capitalize()
print info.title()
|
返回一个字符串居中,并使用空格填充至长度width的新字符串。
|
1
|
"center string".center(width) #width设置为控制台宽度,可控制输出的字符串居中。
|
列举所有字母
|
1
2
3
|
print string.ascii_uppercase 所有大写字母
print string. ascii_lowercase 所有小写字母
print string.ascii_letters 所有字母(包括大小写)
|
列表(list)
列表去重
|
1
2
|
ids = [1,4,3,3,4,2,3,4,5,6,1]
ids = list(
set(ids))
|
判断列表为空
|
1
2
|
a=[]
if not a:
|
列表运算
|
1
2
3
4
5
|
a=[1,2,3]
b=[3,4,5]
set(a)&set(b) 与
set(a)|set(b) 或
set(a)-set(b) 非
|
单列表元素相加
|
1
2
3
|
a = [
"Code", "mentor", "Python", "Developer"]
>>>
print " ".join(a)
Code mentor Python Developer
|
多列表元素分别相加
|
1
2
3
4
5
6
7
8
|
list1 = [
'a', 'b', 'c', 'd']
list2 = [
'p', 'q', 'r', 's']
>>>
for x, y in zip(list1,list2):
print x, y
ap
bq
cr
ds
|
将嵌套列表转换成单一列表
|
1
2
3
4
|
a = [[1, 2], [3, 4], [5, 6]]
>>> import itertools
>>> list(itertools.chain.from_iterable(a))
[1, 2, 3, 4, 5, 6]
|
列表内元素相加
|
1
2
|
a=[1,2,3](数字)
sum(a)
|
产生a-z的字符串列表
|
1
|
map(chr,range(97,123))
|
列表复制
|
1
2
3
|
a=[1,2,3]
b=a
当对b进行操作时,会影响a的内容,因为共用一个内存指针,b=a[:] 这样就是单独复制一份了。
|
列表推导
if+else配合列表解析
|
1
|
[i
if i >5 else -i for i in range(10)]
|
多层嵌套列表
|
1
2
3
4
|
a=[[1,2],[3,4]]
b=[
for j in i for i in a]
print b
[1,2,3,4]
|
生成一个生成器,调用next方法,可以减少内存开支。
|
1
|
a=(i
else i+1 for i in b if i==1)
|
字典推导
更换key与value位置
|
1
2
|
dict={
"a":1,"b":2}
b={value:key
for key value in dict.items()}
|
字典操作(dict)
筛选出值重复的key
|
1
2
3
4
5
6
|
list1=self.dict_ip.items()
ddict=defaultdict(list)
for k,v in list1:
ddict[v].append(k)
list2=[(i,ddict[i])
for i in ddict if len(ddict[i])>1]
dict_ns=dict(list2)
|
字典排序(py2)
|
1
2
|
file_dict={
"a":1,"b":2,"c":3}
file_dict_new=sorted(file_dict.iteritems(), key=operator.itemgetter(1),reverse=True)
##字典排序,reverse=True由高到低,itemgetter(1)表示按值排序,为0表示按key排序。
|
字典值判断
|
1
2
3
|
b={
"a":1}
a=b.get(
"a","") #如果不存在a,则返回””
c=a
if a else 0 #如果存在a,则返回a,不然返回0
|
模块操作
导入模块时,设置只允许导入的属性或者方法。
|
1
2
3
4
5
6
7
8
9
10
|
fb.py:
-----------------------
__all__=[
"a","b"]
a=
"123"
c=
"2345"
def b():
print “123”
-----------------------
from fb import *
可以导入__all__内定义的变量,a跟b()可以导入,c不行。如果不定义__all__则所有的都可以导入。
|
导入上级目录下的包
|
1
2
|
sys.path.append(
"..")
from spider.spider_ import spider_
|
导入外部目录下的模块
|
1
|
需要在目标目录下创建__init__.py文件,内容随便。
|
增加模块属性
|
1
2
3
4
|
有时候源代码中,我们需要写上自己的名字以及版本介绍信息,可以用__name__的方式定义。
a.py:
#! -*- coding:utf-8 -*-
__author__=
"nMask"
|
然后当我们导入a这个模块的时候,可以输出dir(a)看看
|
1
2
3
4
5
|
>>> import p
>>>
print dir(p)
[
'__author__', '__builtins__', '__doc__', '__file__', '__name__', '__package__']
>>>
print p.__author__
nmask
|
动态加载一个目录下的所有模块
|
1
2
3
4
5
6
7
8
9
10
11
|
目录:
---
test
----a.py
----b.py
---c.py
c.py导入
test下面的所有模块:
for path in ["test"]:
for i in list(set([os.path.splitext(i)[0] for i in os.listdir("./"+path)])):
if i!="__init__" and i!=".DS_Store": ##排除不必要的文件
import_string =
"import path+"."+i+"
exec import_string #执行字符串中的内容
|
函数操作
eval/exec
|
1
2
3
4
|
def
test(content):
print content
exec(“test(‘abc')”)
|
输出:abc
说明:exec函数没有返回值
|
1
2
3
4
|
def
test(content):
return content
print eval(“test(‘abc')”)
|
输出:abc
说明:eval函数有返回值
装饰器函数
输出当前时间装饰器
|
1
2
3
4
5
|
def current_time(aclass):
def wrapper():
print "[Info]NowTimeis:",time.ctime()
return aclass()
return wrapper
|
itertools迭代器
|
1
2
3
|
p=product([
"a","b","c","d"],repeat=2)
----
[(
"a","a"),("b","b")......]
|
reduce函数
函数本次执行的结果传递给下一次。
|
1
2
3
4
|
def
test(a,b):
return a+b
reduce(
test,range(10))
结果:从0+1+2......+9
|
enumerate函数
输入列表元素以及序列号
|
1
2
3
|
n=[
"a","b","c"]
for i,m in enumerate(n):
print(i,m)
|
函数超时时间设置
@于2017.05.27更新
利用signal设置某个函数执行的超时时间
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import time
import signal
def
test(i):
time.sleep(0.999)
#模拟超时的情况
print "%d within time"%(i)
return i
def fuc_time(time_out):
# 此为函数超时控制,替换下面的test函数为可能出现未知错误死锁的函数
def handler(signum, frame):
raise AssertionError
try:
signal.signal(signal.SIGALRM, handler)
signal.alarm(time_out)
#time_out为超时时间
temp =
test(1) #函数设置部分,如果未超时则正常返回数据,
return temp
except AssertionError:
print "%d timeout"%(i)# 超时则报错
if __name__ == '__main__':
for i in range(1,10):
fuc_time(1)
|
函数出错重试
利用retrying模块实现函数报错重试功能
|
1
2
3
4
5
6
7
8
|
import random
from retrying import retry
@retry
def have_a_try():
if random.randint(0, 10) != 5:
raise Exception(
'It's not 5!')
print 'It
's 5!'
|
如果我们运行have_a_try函数,那么直到random.randint返回5,它才会执行结束,否则会一直重新执行,关于该模块更多的用法请自行搜索。
程序操作
@于2017.05.27更新
Ctrl+C退出程序
利用signal实现ctrl+c退出程序。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import signal
import sys
import time
def handler(signal_num,frame):
print "\nYou Pressed Ctrl-C."
sys.exit(signal_num)
signal.signal(signal.SIGINT, handler)
# 正常情况可以开始你自己的程序了。
# 这里为了演示,我们做一个不会卡死机器的循环。
while 1:
time.sleep(10)
# 当你按下Ctrl-C的时候,应该会输出一段话,并退出.
|
程序自重启
利用os.execl方法实现程序自重启
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import time
import sys
import os
def restart_program():
python = sys.executable
print "info:",os.execl(python, python, * sys.argv)
#os.execl方法会代替自身进程,以达到自重启的目的。
if __name__ == "__main__":
print 'start...'
print u"3秒后,程序将结束...".encode("utf8")
time.sleep(3)
restart_program()
|