1 数据库
存放数据的仓库。例如你的账号信息,订单记录等。
2 SQL
Structured Query Language,用于访问和处理关系数据库的标准的计算机语言。
按照功能又可分为四大类;
- DQL
查询语言,基本语句 SELECT;
- DML
操纵语言,主要有三种形式,INSERT、UPDATE 和 DELETE;
- DDL
定义语言,创建表、视图、索引等,CREATE TABLE;
- DCL
控制语言,用来授权或回收某种特权,基本形式有 GRANT、 COMMIT 和 ROLLBACK;
3 NoSQL
Not Only SQL,泛指非关系型的数据库,通常以键值对或者文档形式存储。例如 Redis、MongoDB。
关系型数据库(MySQL)能通过外键建立表之间的联系,且相比 NoSQL 而言,还具备 ACID 特性。
但 NoSQL 操作无须 SQL 解析,读写性能较高,相比关系型数据库来说,不用预设存储结构,且天然支持分布式存储。
4 范式
数据库满足一定要求的条件称为数据库范式。又能根据程度的不同,简称为第 N 范式。
- 第一范式 1NF
所有属性不可再分,例如属性 product 就不能分为 title 和 price,可以单独设置两个属性 productTitle、productPrice;
- 第二范式 2NF
每张表都有一个属性作为唯一标识,其他属性完全依赖该标识,例如自增主键ID;
- 第三范式 3NF
所有的非主属性不依赖于其他的非主属性。例如订单表中可以关联商品ID,但不应该关联商品非主属性 title 和 price 等;
为了提高查询效率,通常会添加冗余字段,这也就违背了 3NF,也称之为反三范式。
5 MySQL
MySQL 是一个 Oracle 旗下的关系型数据库,使用 SQL 语言进行增删改查操作。
开源免费,性能也比较好,和 PHP、Java 等 Web 开发语言完美配合,在中小型企业应用非常广泛。
后续内容都是基于 MySQL 数据库的前提下。
6 存储引擎
常见的有 MyISAM 和 InnoDB 引擎;
| 引擎 | 默认版本 | 外键 | 锁粒度 | count(*) | 事务 |
|---|---|---|---|---|---|
| MyISAM | < 5.5 | 不支持 | 表锁 | 变量存储 | 不支持 |
| InnoDB | >= 5.5 | 支持 | 行锁 | 全表扫描 | 支持 |
7 事务
一条或多条 SQL 组成一个事务(transaction),具备 ACID 四个特性;
- Atomicity 原子性
一个事务内的所有操作,要么全部完成,要么全部失败;
- Consistency 一致性
事务开始前后结束后不会破坏数据库的完整性,也就是说写入或修改的结构需要符合预设的规则;
- Isolation 隔离性
防止事务交叉执行时导致数据的不一致。根据隔离程度分为 read uncommitted、read committed、repeatable read 和 serializable;
- Durability 持久性
事务结束后,对数据的修改是永久的;
事务交叉执行可能会造成“脏读”、“幻读” 和 “不可重复读”;
- 脏读
一个事务读取到另外一个事务还未提交的数据;
- 不可重复读
一个事务内,多次读取同一数据返回结果不同;由于在此期间在数据被其他事务修改并已提交;
- 幻读
一个事务内,多次读取,返回不存在的记录;由于在此期间有其他事务写入数据;
| read uncommitted | read committed | repeatable read | serializable | |
|---|---|---|---|---|
| 脏读 | √ | × | × | × |
| 不可重复读 | √ | √ | × | × |
| 幻读 | √ | √ | √ | × |
8 索引
数据库的“目录”,在数据量较大的情况下,可以极大地提高查询效率。
常见的索引数据结构有 B+ 树、Hash。以最常用的 B+ 树为例;
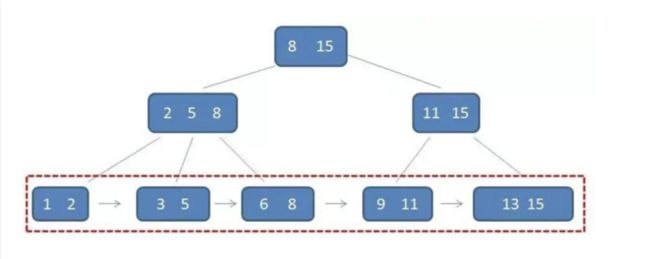
按照 B+ 树存储方式可以把索引分为两大类;
- 聚簇索引;
叶子节点存放了一整行的信息;
- 非聚簇索引;
叶子节点存放的是对应那行数据的主键,和该索引的值;
为什么是 B+ 树?
- 磁盘代价低;
- 查询更加稳定;
- 便于遍历;
- 支持范围查询;
一张结构为 id,groupId,name 的 t_user 表,id 为主键(聚簇索引),groupId 为普通索引(非聚簇索引)。
select name from t_user where groupId = 123;先在叶子节点上得到对应的主键 id,然后再根据主键 id 得到 name 的值,这种行为称之为回表。
select groupId from t_user where groupId = 123;直接在叶子节点上就能得到 groupId 的值,不用回表操作,这种索引也被称为覆盖索引。
按照功能类型又可以把索引分为三大类;
- 普通索引;
最基本的索引类型,没有限制条件;
- 唯一索引;
保证索引字段的值唯一,允许有 NULL;主键是一种特殊的唯一索引,不允许有 NULL;
- 联合索引;
多个字段组成一个索引,具有“最左前缀”的原则;
什么是最左前缀?a、b、c 三个字段组成联合索引,那么生效的列为 a、ab、abc、ac。(等值判断时顺序可交换,范围查询时会停止匹配)
9 锁
宏观来看,锁分为两种;行锁可归纳为两类;
- 共享锁(S)
share,又称为读锁,已有 S 锁,可以加其他 S 锁,但不能加 X 锁;
- 排他锁(X)
exclusive,又称为写锁,X 与其他任何锁互斥;
InnoDB 是通过给索引项加锁实现的行锁,可分为三种类型;
- record lock
行级锁,锁定对应索引项;
- gap lock
间隙锁,锁定索引项之间的间隙,左开右闭;
- next-key lock
前两种的结合;
如果不通过索引项检索数据,会锁住整个表。
InnoDB 加锁方法:
- 对于 UPDATE、DELETE、INSERT 自动加 X 锁;
- 对于普通 SELECT 不会加任何锁;
- SELECT ... LOCK IN SHARE MODE 显示加 S 锁;
- SELECT ... FOR UPDATE 显示加 X 锁;
查询当前数据库锁状态;
select * from information_schema.innodb_locks;对于不同类型的索引,加锁的方式也不一样;
- 普通索引
加 next-key lock;
- 唯一索引
加 record lock;
由于普通索引叶子节点存储了主键,所以加锁的字段是:普通索引 + 主键索引;
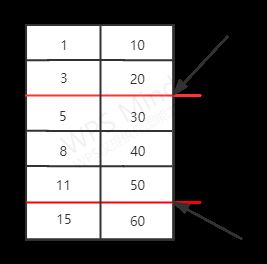
假设有如下数据表 t_ lock,其中 id 为主键,xid 为 普通索引;
+-----+----+
| xid | id |
+-----+----+
| 1 | 10 |
| 3 | 20 |
| 5 | 30 |
| 8 | 40 |
| 11 | 50 |
+-----+----+给 (8, 40) 这条记录加 X 锁;
select * from t_lock where xid = 8 for update;那么根据 next-key lock 的定义,锁住区间为 (5, 30) 到 (8, 40),(8, 40) 到 (11, 50) 这两个区间;
便于理解我会合并为一个区间 (5, 30) 到 (11, 50)。
按照所以排序规则,假设另插入 (xid, id) 记录,那么总是满足以下条件;
- xid < 5;id 无限制;(正常)
- xid = 5;id < 30;(正常)
- xid = 5;id > 30;(阻塞)
- xid > 5 && xid < 11;id 无限制;(阻塞)
- xid = 11;id < 50;(阻塞)
- xid = 11;id > 50;(正常)
- xid > 11;id 无限制;(正常)
简单图示,当插入的数据落在这个区间则会阻塞,反之亦然;
10 RR 幻读
上面事务章节描述 RR 会导致幻读,MySQL 在 RR 下通过如下两点规避掉了;
- MVCC
Multi-Version Concurrency Control,多版本并发控制。在普通 SELECT (快照度)时引入版本,同一个事务中只能读取不大于当前版本的数据快照;
- next-key lock
需要加 X 锁的操作(当前读),加 next-key lock 可以有效避免产生幻读;
11 SQL 执行顺序
根据创建时间升序,查找支付成功超过 3 单的用户,需要去重;
select distinct t1.nickname
from t1 inner join t2
on t1.uid = t2.uid
where t2.pay_time > 0
group by t1.uid, t1.nickname
having count(*) > 3
order by t2.create_time
limit 10- from
- on
- join
- where
- group
- having
- order
- select
- distinct
- limit
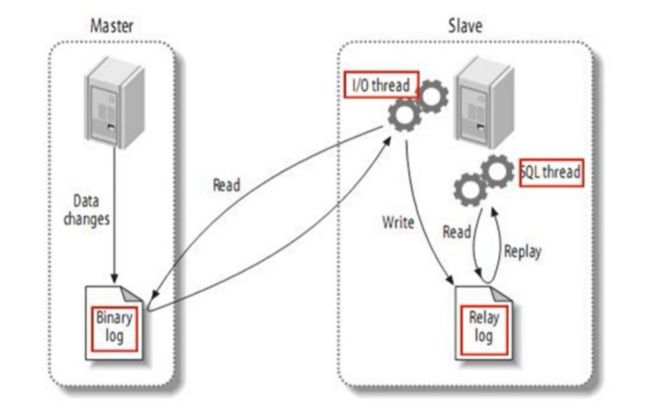
12 binlog
binlog 是 MySQL 最重要的日志,记录了所有的 DDL 和 DML 语句,主要目的是;
- 主从复制;
在 Master 开启 binlog,并传递到 Slave 节点来达到 Master-Slave 数据一致性;
- 数据恢复;
通过 mysqlbinlog 恢复数据;
检查 binlog 是否开启;
show variables like 'log_bin';编辑 mysql 配置文件/etc/mysql/mysql.conf.d/mysqld.cnf,开启 binlog 功能;
[mysqld]
server-id=1
log-bin=/var/lib/mysql/mysql-bin常用几个命令;
- show master status;
- show binary logs;
- mysqlbinlog -v --start-position 2755 --stop-position 3076 mysql-bin.000003;
例如误删除了某条记录;
- 通过 mysqlbinlog 定位到误操作的 position;
- 通过 mysqlbinlog 定位到误删之前最早入库的 position;
- 截取中间 binlog 日志, echo > db.sql 输出到可执行 SQL 文件中;
- 执行恢复数据即可;
可直接流式执行:mysqlbinlog -v --start-position 2432 --stop-position 2533 mysql-bin.000003 | mysql -uroot -p
mysqldump 是用来备份数据库的,例如备份 db_test 数据库;
mysqldump -h127.0.0.1 -uroot -p123456 db_test > db.sql13 性能优化
- 索引;
给经常用作查询条件,且区分度较高的字段建立索引;
- 分页查询;
where id > ${lastId} order by id limit ${size},提高大表分页效率;
- 批量操作;
批量插入用 insert into xxx values (xxx...), (xxx...),批量更新用 case when id;
- not null;
null 会额外占用空间,且 count(xxx) 不会参与统计,若是索引列 is not null 也会失效;