论文笔记《Improving Docker Registry Design based on Production Workload Analysis》
论文笔记《Improving Docker Registry Design based on Production Workload Analysis》
会议:File and Storage Technologies(FAST)
时间:2018-12-15
思维导图
梗概
为了更好地研究 docker 注册表服务对 docker 的作用,本文基于75天的时间内从五个托管生产级注册表的IBM数据中心收集的跟踪信息,对注册表工作进行分析。
本文编写了一个跟踪重播器来进行分析,推断出许多关于容器工作负载的关键点,例如请求类型分布,访问模式和响应时间。基于这些关键点,本文得出注册表的设计优化点,并提高了注册表的性能。
追踪器和重播器都是开源的,网址如下:
文档:https://dssl.cs.vt.edu/drtp/
github:https://github.com/chalianwar/docker-performance
1. 介绍
本文对一个真实的Docker注册表工作负载进行了大规模和全面的分析。
首先从IBM Cloud container registry service中的五个数据中心收集大跨度的生产级跟踪。
跟踪覆盖了注册中心服务的所有可用区域和许多组件,在75天的时间里,总共有超过3800万的请求和超过181.3 TB的数据传输
通过跟踪和分析数据,初步发现:
- 与push操作相比,工作负载是高度读密集型的,包括90- 95%的pull操作
- 不同注册中心的特征不同。工作负载不仅取决于注册的目的,还取决于注册中心服务的年龄;较旧的注册中心服务在访问模式和图像流行方面显示出更可预测的趋势。
- 观察到25%的请求是针对前10个库的,12%的请求是针对前10个层的。此外,注册中心将95%的时间花在从后端对象存储中获取图像内容上。
根据这些发现,提出了几个容器注册表服务的设计指示
2. 背景知识
每一层都有一个称为digest的内容可寻址标识符,该标识符通过获取其数据的抗碰撞散列(默认为SHA256)来唯一地标识一层。这使得Docker能够有效地检查两个层是否相同,并对它们进行重复数据删除,以便在不同的图像之间共享。
2.1 Docker Registry
本文使用 Docker Registry V2 的 Rest API 做测试;分别包括 pull 和 push 操作
push与pull的工作顺序相反。在本地创建清单之后,守护进程首先将所有层推入注册表,然后将manifest推入注册表。
下表为论文中提及的 Docker Registry Rest API
| http方法 | URL | 作用 |
|---|---|---|
| GET | {name}/manifests/{tag} | 获取图像清单,其中name定义用户和存储库名称,而tag定义图像标签。 |
| HEAD | {name}/blobs/{digest} | 检查注册表中是否有可用的层 |
| GET | {name}/blobs/{digest} | 拉取压缩的层tar文件 |
| HEAD | {name}/blobs/{digest} | 检查一个层是否已经存在于注册表中 |
| POST | {name}/blobs/uploads/ | 若层不在,使用此URL进行上传开始操作,其返回一个URL包含一个唯一的上传标识符(uuid),客户端可以使用它来传输实际的层数据。 |
| PUT | {name}/blobs/upload/{uuid} | 使用单片上传整个层数据 |
| PATCH | {name}/blobs/upload/{uuid} | 使用分块策略上传层数据,请求在头部指定一个字节范围以及blob的相应部分 |
| PUT | {name}/manifests/{digest} | 上传完所有layers后,上传 manifest 文件信息 |
Docker 在上传层数据时可以选择使用单片或分块传输上传层。单片传输上载在一个PUT请求中装载一层的全部数据。为了进行分块传输,Docker使用PATCH 请求在头部指定一个字节范围以及blob的相应部分。
2.2 IBM 云容器 Registry
IBM的租户众多,并且其V2版本是基于开源 Docker Registry 搭建的。
其包含超过十八个组件,本文中主要追踪了三个组件,如下图所示:
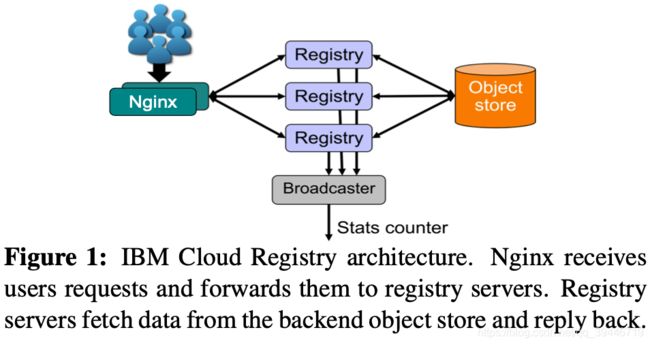
- Nginx:负载均衡器。跟踪它可以提供响应时间信息
- Registry:使用OpenStack Swift作为后端对象存储。跟踪它可以提供关于请求分布的信息
- Broadcaster:提供注册表事件过滤和分发,例如,它会在推送新镜像时通知其他的漏洞能力顾问组件。跟踪它可以研究层的大小
尽管Nginx会进行log记录,但是本文对Registry和Broadcaster也进行了日志收集。
不仅如此,本文还介绍了 IBM 容器仓库分布于五个地理位置:Dallas (dal), London (lon), Frank- furt (fra), Sydney (syd), 和 Montreal。
每个不同地点的容器仓库提供不同的功能,如面向客户的,作为开发和测试用的,面向内部员工的,等等;并且根据功能的不同,其仓库规模也不同,不同的容器仓库其使用年龄也不同
每个可用地区(AZ)都有一个单独的控制平面和入口路径,但是后端组件,例如对象存储,是共享的。这意味着AZ是完全网络隔离的,但是在AZ之间共享映像。
3. 跟踪方法
本文获得了 IBM 云仓库的系统日志服务的访问权限,除了收集追踪信息,本文还开发了追踪回放器用于评估其他指标
3.1 日志服务
IBM 云容器日志服务是由 ELK 技术栈进行管理
- ElasticSearch
- Logstash
- Kibana
每个服务器上的Logstash代理将日志发送到一个集中的日志服务器,在那里它们被索引并添加到ElasticSearch集群中。
每个AZ有自己的ElasticSearch集群,每日日志数据达2TB,这包括系统使用情况、运行状况信息、来自不同组件的日志等。收集的数据按时间排序。
3.2 收集数据
通过在ElasticSearch 中对三个组件的日志收集,收集了和镜像推拉有关的所有请求。从2017-6-20 到 2017-9-2 ,得到了表1 的数据
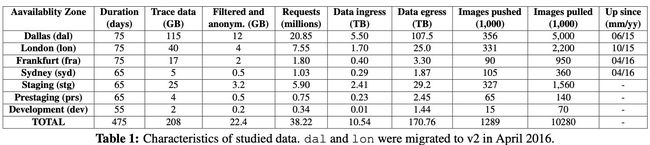
通过移除重复项和过滤数据,剔除掉了22.4G的匿名追踪数据
下图就是单次匿名追踪的记录格式

3.3 跟踪重播器
主要介绍了 跟踪重播器 的架构,用途,行为方式和作用影响
跟踪重播器架构如下图所示:
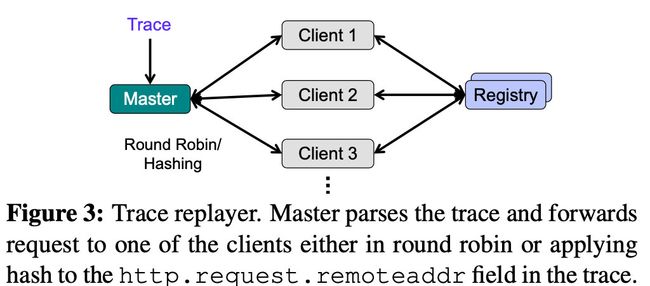
跟踪重播器作用主要是将收集来的追踪信息,通过重播的方式进行再现。各组件的行为如下:
-
Master:master 节点一次解析一个请求的匿名跟踪文件,并将其转发给其中一个客户端。请求以轮询方式或散列http.request跟踪中的remoteaddr字段转发给客户端。
通过使用散列,跟踪回放器维护请求的位置,以确保与一个镜像推或拉对应的所有HTTP请求都是由相同的客户端节点生成的,就像原始注册中心服务所看到的那样。
-
Client:客户端负责向 Registry 发出HTTP请求。
对于所有PUT层请求,客户端都会生成一个具有相应大小的随机文件,并将其传输到注册表。 由于新生成的文件的内容与在跟踪中看到的层的内容不同,因此两者的digest / SHA256将有所不同。 因此,在成功完成请求后,客户端将以请求延迟以及新生成的文件的摘要回复主服务器。 Master 维护一个跟踪中的摘要及其对应的新生成的摘要之间的映射。 对于此层将来所有的GET请求,Master 都会发出对新摘要的请求,而不是在原跟踪中看到的摘要请求。 对于所有GET请求,客户端仅报告延迟。
跟踪重播器以两种模式发出请求:
- 尽可能快
- 保持原样
跟踪重播器的主端是多线程的,并且在单独的线程中跟踪每个客户端的进度。 一旦所有客户端完成工作,就可以计算总吞吐量和延迟。 每个请求延迟,每个客户端延迟和吞吐量分别记录。
跟踪重播器通过两种模式可以执行两种分析
- 大规模注册表设置的性能分析
- 脱机跟踪分析:在这种模式下,主服务器不把请求转发给客户端,而是把它们交给一个分析插件来处理任何请求的操作。例如,trace播放器可以模拟不同的缓存策略,并确定使用不同缓存大小的效果。
4. 工作负载特征
本文针对 Registry 优化提出了5个问题:
- 本文的一般工作量是多少?什么是请求类型和大小分布?
- 生产,暂存,预阶段和开发部署之间的响应时间是否有所不同?
- Registry 请求是否有空间局限性?
- 后续请求之间存在相关性吗?可以预测未来的请求吗?
- 工作负载的时间属性是什么?是否有突发事件,在时间上有局限性吗?
4.1 请求分析
根据拿到的请求日志,将其分为请求类型分布和请求大小分布
请求类型分布
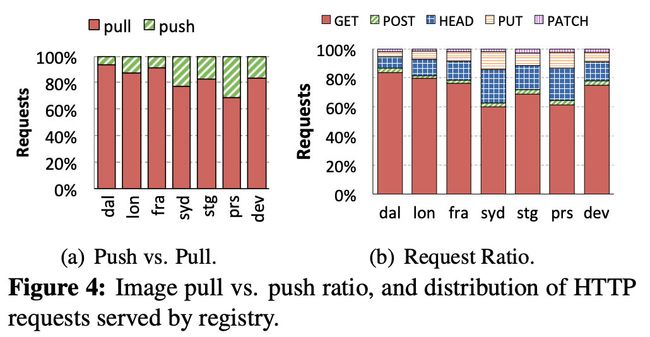
上图的a显示了 push 和 pull 在每个 registry 的比例,registry 是读密集型的
Syd registry 显示出较低的拉取比例 78%,因为它是一个较新的 registry,因此它比成熟的registry 需要更密集地进行数据填充。
图b显示了,所有注册中心接收60%以上的GET请求和10%-22%的HEAD请求。PUT请求比PATCH请求多了1.9-5.8倍,因为PUT用于上传清单文件(除了层之外),而且许多层都足够小,可以在一个请求中上传。
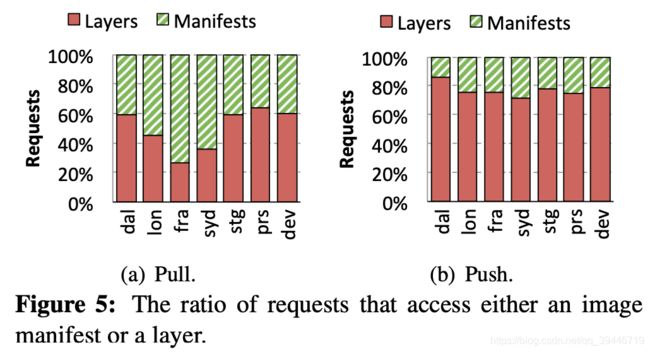
上图显示 清单文件(manifest) 和 层文件的请求比例。对于 pull 而言,更多的请求是对于层,syd 和 fra registry 的清单请求更多,是因为有很多请求都是拉取过一次再拉取
push 操作里,访问层比清单比例更大
请求大小分布
图6显示的是在 GET 请求中的,清单和层大小的累积分布函数
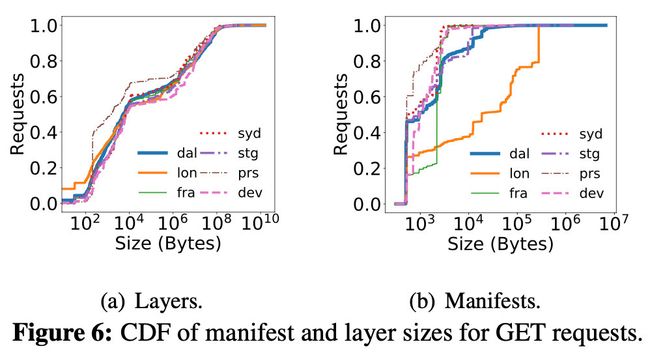
6a可以看到,65%的层小于1MB,80%的小于10MB
6b则显示了,清单大小一般在1KB左右
对于lon registry 来说,大量的请求都是针对与旧Docker版本兼容的清单,因此增加了它们的大小。
4.2 registry 加载和响应时间
加载分布
通过研究各个 regsitry 的每分钟被请求数,得到两个结论
- 首先,开发和预开发注册中心的利用率很低。
- 其次,注册表负载随着年龄的增长而增加。
响应时间分布
对于层请求来说,大部分请求都可以在1到10s完成,对于清单请求则完成时间更低
4.3 热度分析
本文还对层,清单,库等热度进行分析,发现top 1,2 的热度和命中率很高,之后就呈断崖式下降
启发就是,过小的缓存不足以有效地缓存数据。例如,根据这些结果,我们估计数据集大小的2%的缓存大小可以提供40%或更高的命中率。缓存对于提高容器注册中心的性能非常有效。
4.4 请求相关
本文还研究对某个清单的GET请求是否总是会导致相应层的后续GET请求。
本文将一次请求会话的时间阈值定义为1分钟,然后计算一个会话中跟随GET manifest请求的所有GET层请求。
在大多数情况下,GET manifest请求之后没有任何后续请求。原因是,每当客户端已经获取一个镜像,然后提取一个镜像,只有清单文件被请求检查镜像中是否有任何更改。这表明GET清单和层请求之间没有很强的相关性。
总的来说,分析表明,如果考虑前面的PUT请求,那么GET清单请求和后续层请求之间存在很强的相关性。
4.5 时间特性
客户和请求并发性
间隔时间和空闲时间
间隔时间定义为两个后续请求之间的时间
空闲时间是指没有活动请求的时间。
分析表明虽然一些可用分区有大量的空闲期,但它们的持续时间很短,因此很难用传统的资源供应方法来利用它们
4.6 分析总结*
经过大量的数据和多维度的分析,总结出了7条结论
-
GET请求在所有注册表中占主导地位,超过一半的请求是针对层的,这为有效的层缓存和注册表预取提供了机会。
-
65%的层小于1mb, 80%的层小于10mb,这使得各个层都适合缓存。
-
registry 负载受 registry 预期用例和注册表年龄的影响。
与长期运行的生产系统相比,年轻的非生产注册中心的负载更低。
在为AZ提供资源以节省成本和更有效地使用现有资源时,应该考虑到这一点。
-
响应时间与注册表负载相关,因此也取决于注册表的使用年限(较年轻的注册表的负载较少)和用例。
-
对层、清单、库和用户的 registry 访问是严重倾斜的。有非常少的热门的镜像会被频繁访问,但热度会迅速下降。因此,缓存技术是可行的,但应该谨慎选择缓存大小。
-
PUT请求与后续的GET清单和GET层请求之间有很强的相关性。注册中心可以利用这个模式将层从后端对象存储区预取到缓存中,这大大减少了客户端的拉取延迟。对于流行镜像和非流行镜像都存在这种相关性。
-
尽管周末的请求率下降幅度很小,但我们没有发现可用于改善资源配置的明显重复峰值。
5. Registry 设计改善*
通过上述的分析,对 registry 进行两点改善
- 对热度层使用一个多层缓存
- 一个新推送层的跟踪器,它支持从后端对象存储中预取最新的层。
5.1 实现
对于缓存和预取,我们实现了两个单独的模块。为了实现内存层缓存,我们修改了注册表的Swift存储驱动程序(修改/添加了大约200 LoC)。修改后的驱动程序将小的层存储在内存中,对大的层使用Swift。
5.2 性能分析
本文在一样的配置环境下比较了四种不同的后端
- 直接用OpenStack Swift
- 缓存小于1mb的层,其余层用Swift存储(内存+ Swift)
- 本地文件系统与SSD(本地FS)
- 重定向,即注册表通过Swift中的层链接进行回复,然后客户端直接从Swift中获取层。
结果如下图所示:
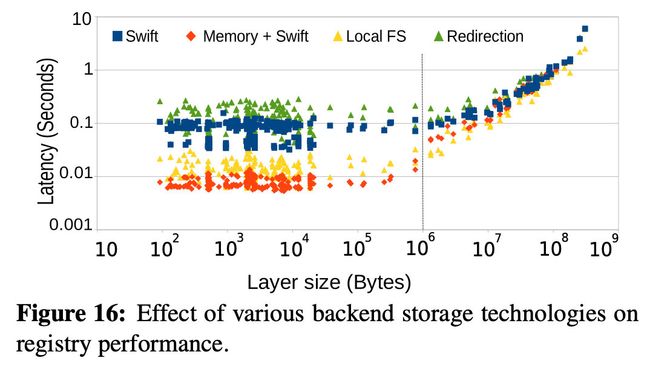
结果突出了注册表的快速后端存储系统的优势,并展示了缓存可以显著提高注册表性能的机会。
5.3 二级缓存**
本文观察到,一小部分的层太大了,不能证明使用内存来缓存它们是合理的。
因此,设计了一个由主存(用于较小的层)和ssd(用于较大的层)组成的两级缓存。
命中率分析
缓存策略:使用 LRU 缓存策略。淘汰时,从内存缓存中逐出的任何对象在完全逐出之前都会首先进入SSD缓存。将小于100 MB的层存储在内存级缓存中,而较大的层存储在SSD级缓存中。
为每个AZ选择数据输入的2%、4%、6%、8%和10%的缓存大小
对于SSD级缓存大小,我们选择内存缓存大小为10×、15×和20×
下图为命中率分析图

缓存对于大部分registry 还是有效的,但是 prs 和 dev 这两个跟踪表示注册表开发团队的测试交互,因此在这种情况下,我们看不到使用缓存的任何好处。
5.4 预取层**
预取算法如下图所示:

算法描述:
L M t h r e s h LM_{thresh} LMthresh:PUT层和随后的GET清单请求之间持续时间的阈值
M L t h r e s h ML_{thresh} MLthresh:保持预取层的持续时间阈值
上述两个阈值是配置的
if r=PUT layer then:当接收到PUT时,存储库和请求中指定的层将被添加到一个包含请求到达时间和客户端地址的查找表中。
else if r=GET manifest then:当在某个阈值 L M t h r e s h LM_{thresh} LMthresh内从客户端接收到GET清单请求时,主机检查查找表是否包含请求中指定的存储库。如果是命中,并且客户端的地址不在表中,那么客户端的地址就添加到表中,并且从后端对象存储中预取层。
命中分析
下图为预取技术的命中分析,单条bar 表示 ML 值,而一组条则为 LM 值

提高 M L t h r e s h ML_{thresh} MLthresh可以显著提高命中率,但提高 LM 命中率只有略微提高
6. 相关工作
Docker 容器
Docker 仓库
工作负载分析
缓存和预取
7. 总结
本文在75天的时间跨度内跟踪了在5个不同地理位置的 registry,总共3800万个请求,最终拿到了181.3 TB的跟踪日志
本文提供了改进Docker注册表性能和使用的见解。提出了有效的缓存和预取策略,利用特定于注册表的工作负载特征来显著提高性能。
最后,开源了跟踪器,并提供了一个跟踪回放器,它可以作为容器注册和基于容器的虚拟化的新研究和研究的坚实基础。