实验七:掌握基本的MapReduce编程方法 (JAVA+Python实现)(编程实现文件合并和去重操作,编写程序实现对输入文件的排序,对给定的表格进行信息挖掘)
一、实验目的:
1. 理解MapReduce的工作机制;
2. 掌握基本的MapReduce编程方法
3. 重点理解map过程,shuffle过程和reduce过程
二、实验环境:
Hadoop+Eclipse+JDK
三、实验内容和要求:
1.编程实现文件合并和去重操作
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。
输入文件A的样例如下:
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
输入文件B的样例如下:
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
根据输入文件A和B合并得到的输出文件C的样例如下:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
2. 编写程序实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。下面是输入文件和输出文件的一个样例供参考。
输入文件1的样例如下:
33
37
12
40
输入文件2的样例如下:
4
16
39
5
输入文件3的样例如下:
1
45
25
根据输入文件1、2和3得到的输出文件如下:
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
3. 对给定的表格进行信息挖掘
下面给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
输入文件内容如下:
child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
Mark Alma
输出文件内容如下:
grandchild grandparent
Steven Alice
Steven Jesse
Jone Alice
Jone Jesse
Steven Mary
Steven Frank
Jone Mary
Jone Frank
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
四、问答题
1. 说明Map过程的执行流程
- Map过程通过在输入列表中的每一项执行函数,生成一系列的输出列表。
2. 说明Shuffle过程的执行流程(包括如何分区,排序,分组)
- 因为频繁的磁盘I/O操作会严重的降低效率,因此“中间结果”不会立马写入磁盘,而是优先存储到map节点的“环形内存缓冲区”,在写入的过程中进行分区(partition),也就是对于每个键值对来说,都增加了一个partition属性值,然后连同键值对一起序列化成字节数组写入到缓冲区(缓冲区采用的就是字节数组,默认大小为100M)。当写入的数据量达到预先设置的阙值后(mapreduce.map.io.sort.spill.percent,默认0.80,或者80%)便会启动溢写出线程将缓冲区中的那部分数据溢出写(spill)到磁盘的临时文件中,并在写入前根据key进行排序(sort)和合并(combine,可选操作)。溢出写过程按轮询方式将缓冲区中的内容写到mapreduce.cluster.local.dir属性指定的目录中。当整个map任务完成溢出写后,会对磁盘中这个map任务产生的所有临时文件(spill文件)进行归并(merge)操作生成最终的正式输出文件,此时的归并是将所有spill文件中的相同partition合并到一起,并对各个partition中的数据再进行一次排序(sort),生成key和对应的value-list,文件归并时,如果溢写文件数量超过参数min.num.spills.for.combine的值(默认为3)时,可以再次进行合并。至此,map端shuffle过程结束,接下来等待reduce task来拉取数据。对于reduce端的shuffle过程来说,reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge最后合并成一个分区相同的大文件,然后对这个文件中的键值对按照key进行sort排序,排好序之后紧接着进行分组,分组完成后才将整个文件交给reduce task处理。
3. 说明Reduce过程的执行流程
- Reduce过程在一个输入的列表进行扫描工作,随后生成一个聚集值,作为最后的输出
五、实验结果与分析(含程序、数据记录及分析和实验总结等):
所有关键代码在文档最后
1. 将你设计的几个页面截图拷贝粘贴到此处,每张截图后附上关键代码 (关键代码见附录)
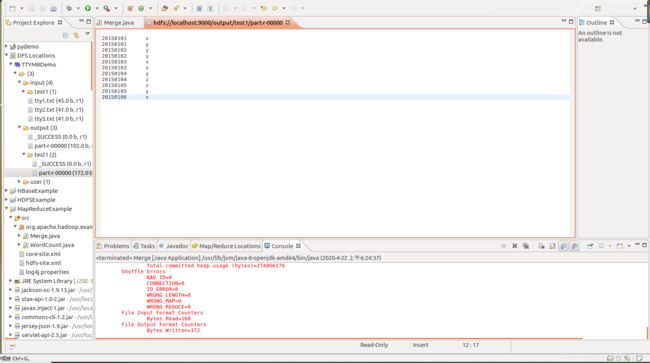
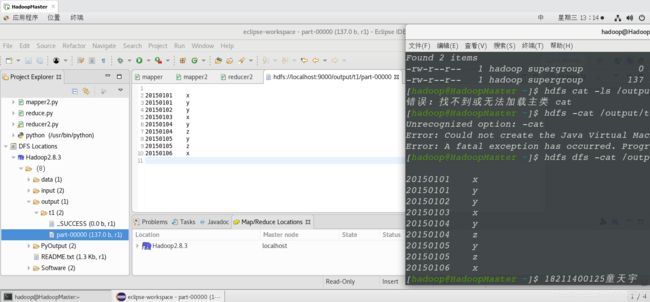
注:文件事先上传至 /input/test1中,上图分别是java和python mapreduce的运行结果
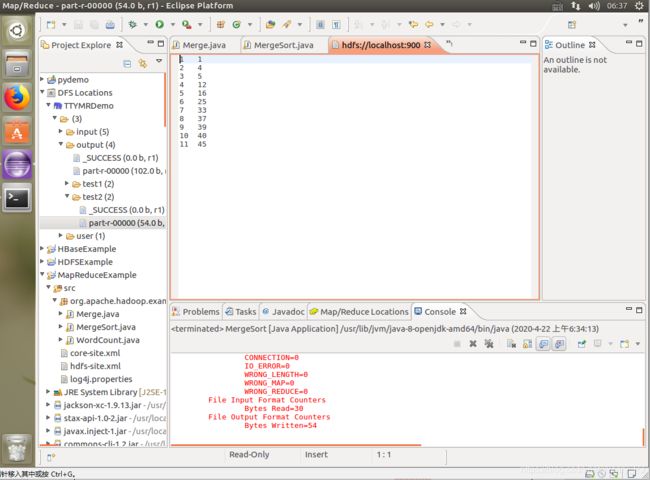
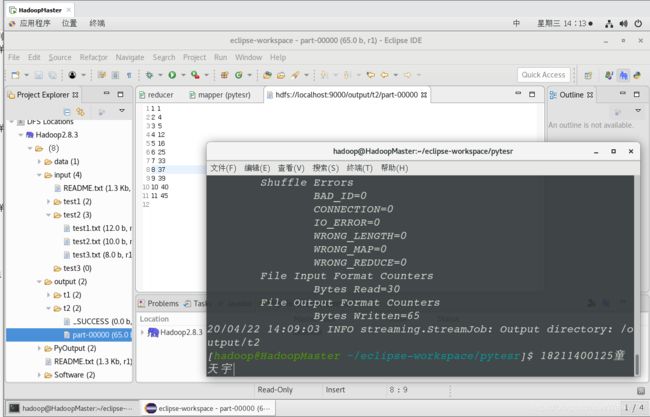
注:测试文件事先上传到/input/test2中, 上图为java和python测试结果
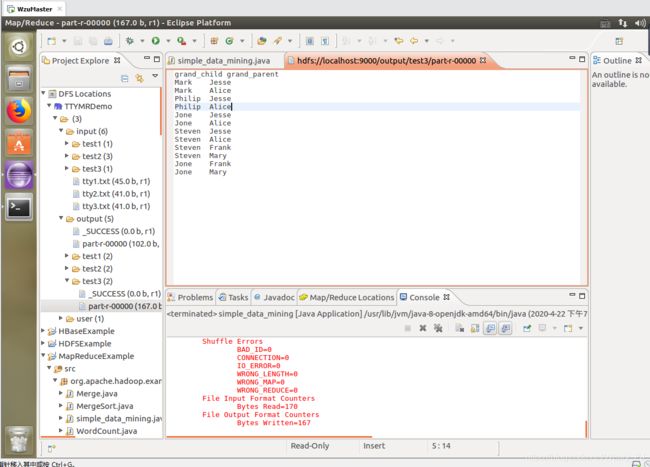
2. 截图中应包含各位同学的个人信息,防止抄袭
3. 实验总结(学到的知识点、遇到的难点、心得等)必须要写(否则大扣分)
在做实验的时候遇到了下面几个问题,现在已经一一解决:
1. 实验配置的问题 :
- eclipse中hadoop插件的配置: 已经解决并整理为博客:点击此处
- 尝试用python运行,需要下载Pydev插件 已解决
2. 代码思路的问题 :
因为之前只学习了词频统计的应用,在面对其他问题的时候突然没有什么好的思路,原因是因为对map 和 reduce的原理还不是特别清楚 查阅了大量资料之后 理解, map阶段将 输入的信息整理成
下面给出三个实验的思路:
- 编程实现文件合并和去重操作
本道题主要目的是去重,我在编写的时候的思路就是 通过map函数读取 key,value 因为我的目的是去重,所以在这里我完全可以把整个数据作为一个key,而value我可以不管他 而reduce会接受到的是
可以从python字典的角度来理解,我们把文档的每一行作为字典的键,出现的次数作为值,最终我们循环输出所有的键 - 编写程序实现对输入文件的排序
因为MR自带排序,所以我们只要把输入的数字以int的形式交给map map将这个数字作为key输出,而rerduce函数将map输入的key复制到输出的value上即可,因为要输入排序的序号,所以再定义个变量用来记录输出数字的排序即可 - 对给定的表格进行信息挖掘
本题其实相当于一个表的自身join,但是我们需要转化一下,输入的文件只是child和parent ,将他正序输出一次作为右表,反序输出一次作为左表,这样就可以完成child parent grand三个字段的两张表操作,输出的时候加上两张表的标识来区分 reduce函数则用来取出左表中的child 即为grandchild 再取出右表的parent相当于grandparent即可
实验代码
总:上传文件代码
vim test1.txt # 里面放上要测试的文本
hdfs dfs - mkdir /input/test1/ # 创建文件夹
hdfs dfs - put test1.txt /input/test1/ # 上传文件
第一题Java解
1. package org.apache.hadoop.example;
2.
3. import java.io.IOException;
4.
5. import org.apache.hadoop.conf.Configuration;
6. import org.apache.hadoop.fs.Path;
7. import org.apache.hadoop.io.IntWritable;
8. import org.apache.hadoop.io.Text;
9. import org.apache.hadoop.mapreduce.Job;
10. import org.apache.hadoop.mapreduce.Mapper;
11. import org.apache.hadoop.mapreduce.Reducer;
12. import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
13. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
14. import org.apache.hadoop.util.GenericOptionsParser;
15.
16. public class Merge {
17.
18. /**
19. * @param args
20. * 对A,B两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C
21. */
22. //在这重载map函数,直接将输入中的value复制到输出数据的key上 注意在map方法中要抛出异常:throws IOException,InterruptedException
23. public static class Map extends Mapper<Object, Text, Text, Text> {
24. private static Text text = new Text();
25. public void map(Object key, Text value, Context content) throws IOException, InterruptedException {
26.
27. text = value;
28. content.write(text, new Text(""));
29. }
30. }
31. //在这重载reduce函数,直接将输入中的key复制到输出数据的key上 注意在reduce方法上要抛出异常:throws IOException,InterruptedException
32. public static class Reduce extends Reducer<Text, Text, Text, Text> {
33. public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
34. context.write(key, new Text(""));
35. }
36. }
37.
38.
39. public static void main(String[] args) throws Exception{
40.
41. // TODO Auto-generated method stub
42. Configuration conf = new Configuration();
43. conf.set("fs.default.name","hdfs://localhost:9000");
44. String[] otherArgs = new String[]{
"/input/test1","/output/test1"}; /* 直接设置输入参数 */
45. if (otherArgs.length != 2) {
46. System.err.println("Usage: wordcount " );
47. System.exit(2);
48. }
49. Job job = Job.getInstance(conf,"Merge and duplicate removal");
50. job.setJarByClass(Merge.class);
51. job.setMapperClass(Map.class);
52. job.setCombinerClass(Reduce.class);
53. job.setReducerClass(Reduce.class);
54. job.setOutputKeyClass(Text.class);
55. job.setOutputValueClass(Text.class);
56. FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
57. FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
58. System.exit(job.waitForCompletion(true) ? 0 : 1);
59. }
60.
61. }
第一题 Python解
# mapper.py
62. #!/usr/bin/env python3
63. import sys
64. for line in sys.stdin:
65. if line:
66. print(line),
# reducer.py
67. #!/usr/bin/env python
68. from operator import itemgetter
69. import sys
70.
71. li = []
72. for line in sys.stdin:
73. if line in li:
74. continue
75. print(line),
76. li.append(line)
77.
运行脚本
78. hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.8.3.jar \
79. -file ~/eclipse-workspace/PyWordCount/mapper2.py -mapper ~/eclipse-workspace/PyWordCount/mapper2.py \
80. -file ~/eclipse-workspace/PyWordCount/reducer2.py -reducer ~/eclipse-workspace//PyWordCount/reducer2.py \
81. -input /input/test1/ -output /output/t1
第二题Java解
82. package org.apache.hadoop.example;
83.
84. import java.io.IOException;
85.
86.
87. public class MergeSort {
88.
89. /**
90. * @param args
91. * 输入多个文件,每个文件中的每行内容均为一个整数
92. * 输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数
93. */
94. //map函数读取输入中的value,将其转化成IntWritable类型,最后作为输出key
95. public static class Map extends Mapper<Object, Text, IntWritable, IntWritable>{
96.
97. private static IntWritable data = new IntWritable();
98. public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
99. /********** Begin **********/
100. String line = value.toString();
101. data.set(Integer.parseInt(line));
102. context.write(data, new IntWritable(1));
103. /********** End **********/
104.
105. }
106. }
107.
108. //reduce函数将map输入的key复制到输出的value上,然后根据输入的value-list中元素的个数决定key的输出次数,定义一个全局变量line_num来代表key的位次
109. public static class Reduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
110. private static IntWritable line_num = new IntWritable(1);
111.
112. public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException{
113. /********** Begin **********/
114. for(IntWritable num : values) {
115. context.write(line_num, key);
116. line_num = new IntWritable(line_num.get() + 1);
117. }
118. /********** End **********/
119. }
120. }
121.
122. //自定义Partition函数,此函数根据输入数据的最大值和MapReduce框架中Partition的数量获取将输入数据按照大小分块的边界,然后根据输入数值和边界的关系返回对应的Partiton ID
123. public static class Partition extends Partitioner<IntWritable, IntWritable>{
124. public int getPartition(IntWritable key, IntWritable value, int num_Partition){
125. /********** Begin **********/
126. int Maxnumber = 65223;//int型的最大数值
127. int bound = Maxnumber / num_Partition + 1;
128. int Keynumber = key.get();
129. for(int i = 0; i < num_Partition; i++){
130. if(Keynumber < bound * i && Keynumber >= bound * (i - 1)) {
131. return i - 1;
132. }
133. }
134. return -1 ;
135. /********** End **********/
136.
137. }
138. }
139.
140. public static void main(String[] args) throws Exception{
141. // TODO Auto-generated method stub
142. Configuration conf = new Configuration();
143. conf.set("fs.default.name","hdfs://localhost:9000");
144. String[] otherArgs = new String[]{
"/input/test2","/output/test2"}; /* 直接设置输入参数 */
145. if (otherArgs.length != 2) {
146. System.err.println("Usage: wordcount " );
147. System.exit(2);
148. }
149. Job job = Job.getInstance(conf,"Merge and Sort");
150. job.setJarByClass(MergeSort.class);
151. job.setMapperClass(Map.class);
152. job.setReducerClass(Reduce.class);
153. job.setPartitionerClass(Partition.class);
154. job.setOutputKeyClass(IntWritable.class);
155. job.setOutputValueClass(IntWritable.class);
156. FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
157. FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
158. System.exit(job.waitForCompletion(true) ? 0 : 1);
159.
160. }
161.
162. }
Python解
# Mapper.py
163. #!/usr/bin/env python3
164. import sys
165. for line in sys.stdin:
166. if line:
167. print (line,end='')
# reducer.py
168. #!/usr/bin/env python3
169. from operator import itemgetter
170. import sys
171.
172. con = 1
173. li = []
174. for line in sys.stdin:
175. if line:
176. a = str(line).strip()
177. li.append(int(a))
178. for i in sorted(li):
179. print(con,i),
180. con += 1
运行脚本
182. hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.8.3.jar \
183. -file ~/eclipse-workspace/pytesr/mapper.py -mapper ~/eclipse-workspace/pytesr/mapper.py \
184. -file ~/eclipse-workspace/pytesr/reducer.py -reducer ~/eclipse-workspace//pytesr/reducer.py \
185. -input /input/test2/ -output /output/t2
第三题
186. package org.apache.hadoop.example;
187.
188. import java.io.IOException;
189. import java.util.*;
190.
191. import org.apache.hadoop.conf.Configuration;
192. import org.apache.hadoop.fs.Path;
193. import org.apache.hadoop.io.IntWritable;
194. import org.apache.hadoop.io.Text;
195. import org.apache.hadoop.mapreduce.Job;
196. import org.apache.hadoop.mapreduce.Mapper;
197. import org.apache.hadoop.mapreduce.Reducer;
198. import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
199. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
200. import org.apache.hadoop.util.GenericOptionsParser;
201.
202. public class simple_data_mining {
203. public static int time = 0;
204.
205. /**
206. * @param args
207. * 输入一个child-parent的表格
208. * 输出一个体现grandchild-grandparent关系的表格
209. */
210. //Map将输入文件按照空格分割成child和parent,然后正序输出一次作为右表,反序输出一次作为左表,需要注意的是在输出的value中必须加上左右表区别标志
211. public static class Map extends Mapper<Object, Text, Text, Text>{
212. public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
213. /********** Begin **********/
214. String line = value.toString();
215. String[] childAndParent = line.split(" ");
216. List<String> list = new ArrayList<>(2);
217. for (String childOrParent : childAndParent) {
218. if (!"".equals(childOrParent)) {
219. list.add(childOrParent);
220. }
221. }
222. if (!"child".equals(list.get(0))) {
223. String childName = list.get(0);
224. String parentName = list.get(1);
225. String relationType = "1";
226. context.write(new Text(parentName), new Text(relationType + "+"
227. + childName + "+" + parentName));
228. relationType = "2";
229. context.write(new Text(childName), new Text(relationType + "+"
230. + childName + "+" + parentName));
231. }
232.
233. /********** End **********/
234. }
235. }
236.
237. public static class Reduce extends Reducer<Text, Text, Text, Text>{
238. public void reduce(Text key, Iterable<Text> values,Context context) throws IOException,InterruptedException{
239. /********** Begin **********/
240.
241. //输出表头
242. if (time == 0) {
243. context.write(new Text("grand_child"), new Text("grand_parent"));
244. time++;
245. }
246.
247. //获取value-list中value的child
248. List<String> grandChild = new ArrayList<>();
249. //获取value-list中value的parent
250. List<String> grandParent = new ArrayList<>();
251. //左表,取出child放入grand_child
252. for (Text text : values) {
253. String s = text.toString();
254. String[] relation = s.split("\\+");
255. String relationType = relation[0];
256. String childName = relation[1];
257. String parentName = relation[2];
258. if ("1".equals(relationType)) {
259. grandChild.add(childName);
260. } else {
261. grandParent.add(parentName);
262. }
263. }
264.
265. //右表,取出parent放入grand_parent
266. int grandParentNum = grandParent.size();
267. int grandChildNum = grandChild.size();
268. if (grandParentNum != 0 && grandChildNum != 0) {
269. for (int m = 0; m < grandChildNum; m++) {
270. for (int n = 0; n < grandParentNum; n++) {
271. //输出结果
272. context.write(new Text(grandChild.get(m)), new Text(
273. grandParent.get(n)));
274. }
275. }
276. }
277.
278. /********** End **********/
279.
280. }
281. }
282. public static void main(String[] args) throws Exception{
283. // TODO Auto-generated method stub
284. Configuration conf = new Configuration();
285. conf.set("fs.default.name","hdfs://localhost:9000");
286. String[] otherArgs = new String[]{
"/input/test3","/output/test3"}; /* 直接设置输入参数 */
287. if (otherArgs.length != 2) {
288. System.err.println("Usage: wordcount " );
289. System.exit(2);
290. }
291. Job job = Job.getInstance(conf,"Single table join");
292. job.setJarByClass(simple_data_mining.class);
293. job.setMapperClass(Map.class);
294. job.setReducerClass(Reduce
295. .class);
296. job.setOutputKeyClass(Text.class);
297. job.setOutputValueClass(Text.class);
298. FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
299. FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
300. System.exit(job.waitForCompletion(true) ? 0 : 1);
301.
302. }
303.
304. }