推荐系统之YoutubeDNN代码详解
推荐系统之YoutubeDNN代码详解
import pandas as pd
from deepctr.feature_column import SparseFeat, VarLenSparseFeat
from sklearn.preprocessing import LabelEncoder
from tensorflow.python.keras import backend as K
from tensorflow.python.keras.models import Model
import random
import numpy as np
from tqdm import tqdm
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from deepmatch.models import *
from deepmatch.utils import sampledsoftmaxloss
from tensorflow.keras.utils import plot_model
import warnings
warnings.filterwarnings("ignore")
应用实例
以movielens数据为例,取200条样例数据进行流程演示
data = pd.read_csvdata = pd.read_csv("./data/movielens_sample.txt")
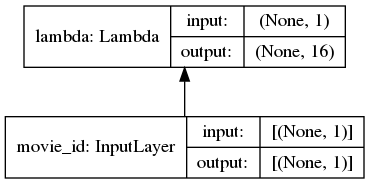
sparse_features = ["movie_id", "user_id",
"gender", "age", "occupation", "zip", ]
SEQ_LEN = 50
negsample = 3
data.head()
| user_id | movie_id | rating | timestamp | title | genres | gender | age | occupation | zip | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1193 | 5 | 978300760 | One Flew Over the Cuckoo's Nest (1975) | Drama | F | 1 | 10 | 48067 |
| 1 | 1 | 661 | 3 | 978302109 | James and the Giant Peach (1996) | Animation|Children's|Musical | F | 1 | 10 | 48067 |
| 2 | 1 | 914 | 3 | 978301968 | My Fair Lady (1964) | Musical|Romance | F | 1 | 10 | 48067 |
| 3 | 1 | 3408 | 4 | 978300275 | Erin Brockovich (2000) | Drama | F | 1 | 10 | 48067 |
| 4 | 1 | 2355 | 5 | 978824291 | Bug's Life, A (1998) | Animation|Children's|Comedy | F | 1 | 10 | 48067 |
data.info()
RangeIndex: 233 entries, 0 to 232
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 233 non-null int64
1 movie_id 233 non-null int64
2 rating 233 non-null int64
3 timestamp 233 non-null int64
4 title 233 non-null object
5 genres 233 non-null object
6 gender 233 non-null object
7 age 233 non-null int64
8 occupation 233 non-null int64
9 zip 233 non-null int64
dtypes: int64(7), object(3)
memory usage: 18.3+ KB
data["user_id"].value_counts()
2 129
1 53
3 51
Name: user_id, dtype: int64
data.columns
Index(['user_id', 'movie_id', 'rating', 'timestamp', 'title', 'genres',
'gender', 'age', 'occupation', 'zip'],
dtype='object')
首先对于数据中的特征进行ID化编码,然后使用 gen_date_set and gen_model_input来生成带有用户历史行为序列的特征数据
features = ['user_id', 'movie_id', 'gender', 'age', 'occupation', 'zip']
feature_max_idx = {
}
for feature in features:
lbe = LabelEncoder()
data[feature] = lbe.fit_transform(data[feature]) + 1 # 默认编码从0开始
feature_max_idx[feature] = data[feature].max() + 1 # 作为Embedding向量的大小设定
# 构建用户画像
user_profile = data[["user_id", "gender", "age", "occupation", "zip"]].drop_duplicates('user_id')
user_profile.set_index("user_id", inplace=True)
user_profile
| gender | age | occupation | zip | |
|---|---|---|---|---|
| user_id | ||||
| 1 | 1 | 1 | 1 | 1 |
| 2 | 2 | 3 | 3 | 3 |
| 3 | 2 | 2 | 2 | 2 |
# 构建物品画像
item_profile = data[["movie_id"]].drop_duplicates('movie_id')
item_profile.head()
| movie_id | |
|---|---|
| 0 | 66 |
| 1 | 39 |
| 2 | 47 |
| 3 | 191 |
| 4 | 147 |
# 用户历史点击文章序列
user_item_list = data.groupby("user_id")['movie_id'].apply(list)
user_item_list
user_id
1 [66, 39, 47, 191, 147, 68, 85, 166, 33, 48, 34...
2 [66, 180, 144, 127, 70, 132, 77, 89, 177, 100,...
3 [147, 68, 84, 126, 11, 183, 37, 71, 80, 168, 2...
Name: movie_id, dtype: object
def gen_data_set(data, negsample=0):
data.sort_values("timestamp", inplace=True)
item_ids = data['movie_id'].unique()
train_set = []
test_set = []
for reviewerID, hist in tqdm(data.groupby('user_id')):
pos_list = hist['movie_id'].tolist()
rating_list = hist['rating'].tolist()
if negsample > 0:
candidate_set = list(set(item_ids) - set(pos_list))
neg_list = np.random.choice(candidate_set,size=len(pos_list)*negsample,replace=True)
for i in range(1, len(pos_list)):
hist = pos_list[:i]
if i != len(pos_list) - 1:
train_set.append((reviewerID, hist[::-1], pos_list[i], 1, len(hist[::-1]),rating_list[i]))
for negi in range(negsample):
train_set.append((reviewerID, hist[::-1], neg_list[i*negsample+negi], 0,len(hist[::-1])))
else:
test_set.append((reviewerID, hist[::-1], pos_list[i],1,len(hist[::-1]),rating_list[i]))
random.shuffle(train_set)
random.shuffle(test_set)
print(len(train_set[0]),len(test_set[0]))
return train_set,test_set
def gen_model_input(train_set,user_profile,seq_max_len):
train_uid = np.array([line[0] for line in train_set])
train_seq = [line[1] for line in train_set]
train_iid = np.array([line[2] for line in train_set])
train_label = np.array([line[3] for line in train_set])
train_hist_len = np.array([line[4] for line in train_set])
# 填补缺失值
train_seq_pad = pad_sequences(train_seq, maxlen=seq_max_len, padding='post', truncating='post', value=0)
# 标签 movie_id:最后一次的点击视频id号
train_model_input = {
"user_id": train_uid, "movie_id": train_iid, "hist_movie_id": train_seq_pad,
"hist_len": train_hist_len}
# 添加用户信息
for key in ["gender", "age", "occupation", "zip"]:
train_model_input[key] = user_profile.loc[train_model_input['user_id']][key].values
return train_model_input, train_label
train_set, test_set = gen_data_set(data, negsample)
train_model_input, train_label = gen_model_input(train_set, user_profile, SEQ_LEN)
test_model_input, test_label = gen_model_input(test_set, user_profile, SEQ_LEN)
100%|██████████| 3/3 [00:00<00:00, 28.22it/s]
5 6
配置一下模型定义需要的特征列,主要是特征名和embedding词表的大小
embedding_dim = 16
user_feature_columns = [SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
SparseFeat("gender", feature_max_idx['gender'], embedding_dim),
SparseFeat("age", feature_max_idx['age'], embedding_dim),
SparseFeat("occupation", feature_max_idx['occupation'], embedding_dim),
SparseFeat("zip", feature_max_idx['zip'], embedding_dim),
VarLenSparseFeat(SparseFeat('hist_movie_id', feature_max_idx['movie_id'], embedding_dim,
embedding_name="movie_id"), SEQ_LEN, 'mean', 'hist_len'),
]
item_feature_columns = [SparseFeat('movie_id', feature_max_idx['movie_id'], embedding_dim)]
定义一个YoutubeDNN模型,分别传入用户侧特征列表user_feature_columns和物品侧特征列表item_feature_columns。然后配置优化器和损失函数,开始进行训练。
K.set_learning_phase(True)
import tensorflow as tf
if tf.__version__ >= '2.0.0':
tf.compat.v1.disable_eager_execution()
model = YoutubeDNN(user_feature_columns, item_feature_columns, num_sampled=5, user_dnn_hidden_units=(64, 16))
plot_model(model, show_shapes=True, show_layer_names=True, rankdir="BT", to_file="./imgs/model.png")
WARNING:root:
DeepCTR version 0.8.3 detected. Your version is 0.8.2.
Use `pip install -U deepctr` to upgrade.Changelog: https://github.com/shenweichen/DeepCTR/releases/tag/v0.8.3
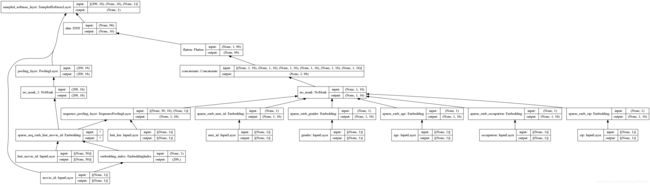
model.compile(optimizer="adagrad", loss=sampledsoftmaxloss, experimental_run_tf_function=False) # "binary_crossentropy"
history = model.fit(train_model_input, train_label, # train_label,
batch_size=256, epochs=5, verbose=1, validation_split=0.0, )
WARNING:tensorflow:From /home/gavin/anaconda3/lib/python3.8/site-packages/tensorflow/python/keras/optimizer_v2/adagrad.py:82: calling Constant.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
WARNING:tensorflow:From /home/gavin/anaconda3/lib/python3.8/site-packages/tensorflow/python/keras/optimizer_v2/adagrad.py:82: calling Constant.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
Train on 908 samples
Epoch 1/5
908/908 [==============================] - 1s 556us/sample - loss: 1.4003
Epoch 2/5
908/908 [==============================] - 0s 22us/sample - loss: 1.1123
Epoch 3/5
908/908 [==============================] - 0s 24us/sample - loss: 1.0816
Epoch 4/5
908/908 [==============================] - 0s 22us/sample - loss: 1.2225
Epoch 5/5
908/908 [==============================] - 0s 25us/sample - loss: 0.9680
Generate user features for testing and full item features for retrieval
# 测试阶段
test_user_model_input = test_model_input
all_item_model_input = {
"movie_id": item_profile['movie_id'].values}
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
# user_embs = user_embs[:, i, :] # i in [0,k_max) if MIND
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
print(user_embs.shape)
(3, 16)
print(item_embs.shape)
(208, 16)
plot_model(user_embedding_model, show_shapes=True, show_layer_names=True, rankdir="BT", to_file="./imgs/dnn.png")
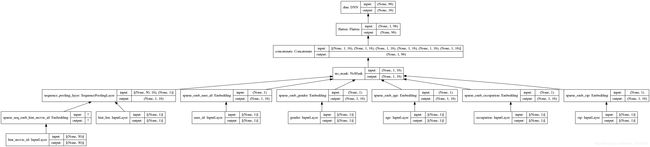
plot_model(item_embedding_model, show_shapes=True, show_layer_names=True, rankdir="BT", to_file="./imgs/emb.png")
[Optional] ANN search by faiss and evaluate the result
test_true_label = {
line[0]:[line[2]] for line in test_set}
import numpy as np
import faiss
from tqdm import tqdm
from deepmatch.utils import recall_N
index = faiss.IndexFlatIP(embedding_dim)
# faiss.normalize_L2(item_embs)
index.add(item_embs)
# faiss.normalize_L2(user_embs)
D, I = index.search(np.ascontiguousarray(user_embs), 50)
s = []
hit = 0
for i, uid in tqdm(enumerate(test_user_model_input['user_id'])):
try:
pred = [item_profile['movie_id'].values[x] for x in I[i]]
filter_item = None
recall_score = recall_N(test_true_label[uid], pred, N=50)
s.append(recall_score)
if test_true_label[uid] in pred:
hit += 1
except:
print(i)
print("recall", np.mean(s))
print("hr", hit / len(test_user_model_input['user_id']))
3it [00:00, 769.93it/s]
recall 0.0
hr 0.0
源码分析
召回
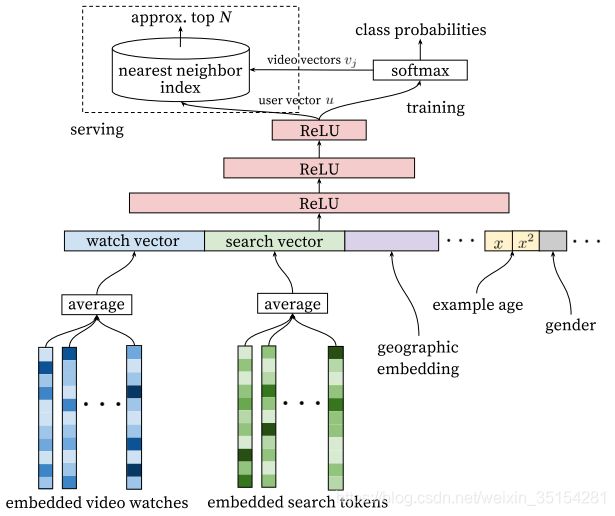
def YoutubeDNN(user_feature_columns, item_feature_columns, num_sampled=5,
user_dnn_hidden_units=(64, 32),
dnn_activation='relu', dnn_use_bn=False,
l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, output_activation='linear', seed=1024, ):
"""Instantiates the YoutubeDNN Model architecture.
:param user_feature_columns: An iterable containing user's features used by the model.
:param item_feature_columns: An iterable containing item's features used by the model.
:param num_sampled: int, the number of classes to randomly sample per batch.
:param user_dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of user tower
:param dnn_activation: Activation function to use in deep net
:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in deep net
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
:param seed: integer ,to use as random seed.
:param output_activation: Activation function to use in output layer
:return: A Keras model instance.
"""
if len(item_feature_columns) > 1:
raise ValueError("Now YoutubeNN only support 1 item feature like item_id")
item_feature_name = item_feature_columns[0].name
item_vocabulary_size = item_feature_columns[0].vocabulary_size
# 为稀疏特征创建对应的Embedding字典
embedding_matrix_dict = create_embedding_matrix(user_feature_columns + item_feature_columns, l2_reg_embedding,
seed=seed)
# 获得用户输入特征
user_features = build_input_features(user_feature_columns)
user_inputs_list = list(user_features.values())
user_sparse_embedding_list, user_dense_value_list = input_from_feature_columns(user_features, user_feature_columns,
l2_reg_embedding, seed=seed,
embedding_matrix_dict=embedding_matrix_dict)
user_dnn_input = combined_dnn_input(user_sparse_embedding_list, user_dense_value_list)
item_features = build_input_features(item_feature_columns)
item_inputs_list = list(item_features.values())
user_dnn_out = DNN(user_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout,
dnn_use_bn, output_activation=output_activation, seed=seed)(user_dnn_input)
item_index = EmbeddingIndex(list(range(item_vocabulary_size)))(item_features[item_feature_name])
item_embedding_matrix = embedding_matrix_dict[item_feature_name]
#获得每一个item的Embedding向量
item_embedding_weight = NoMask()(item_embedding_matrix(item_index))
pooling_item_embedding_weight = PoolingLayer()([item_embedding_weight])
output = SampledSoftmaxLayer(num_sampled=num_sampled)(
[pooling_item_embedding_weight, user_dnn_out, item_features[item_feature_name]])
model = Model(inputs=user_inputs_list + item_inputs_list, outputs=output)
# 设置属性接口,调用对应的数据
model.__setattr__("user_input", user_inputs_list)
model.__setattr__("user_embedding", user_dnn_out)
model.__setattr__("item_input", item_inputs_list)
model.__setattr__("item_embedding",
get_item_embedding(pooling_item_embedding_weight, item_features[item_feature_name]))
return model
sampled_softmax_loss
import tensorflow as tf
a = tf.nn.sampled_softmax_loss(weights=tf.constant([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10], [11, 12], [13, 14], [15, 16], [17, 18], [19, 20]]),
# [num_classes, dim] = [10, 2]
biases=tf.constant([0., 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]),
# [num_classes] = [10]
labels=tf.constant([[2], [3], [5]]),
# [batch_size, num_true] = [3, 1]
inputs=tf.constant([[0.2, 0.1], [0.4, 0.1], [0.22, 0.12]]),
# [batch_size, dim] = [3, 2]
num_sampled=2,
num_classes=10,
num_true = 1,
seed = 2020,
name = "sampled_softmax_loss"
)
with tf.compat.v1.Session() as sess:
print(sess.run(a))
[0.09744156 0.23907095 0.05459948]
参考
看Youtube怎么利用深度学习做推荐
Deep Neural Network for YouTube Recommendation论文精读
Sampled Softmax
Sampled Softmax论文翻译
论文笔记:Deep neural networks for YouTube recommendations
解读与增加个人理解Deep Neural Networks for YouTube Recommendations YouTubeDNN推荐召回与排序
如何通俗理解sampled softmax机制?