推荐系统之DeepFM代码详解
DeepFM
网络结构

源码
class BaseModel:
pass
class DeepFM(BaseModel):
"""Instantiates the DeepFM Network architecture.
:param linear_feature_columns: An iterable containing all the features used by linear part of the model.
:param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
:param use_fm: bool,use FM part or not
:param dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of DNN
:param l2_reg_linear: float. L2 regularizer strength applied to linear part
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN
:param init_std: float,to use as the initialize std of embedding vector
:param seed: integer ,to use as random seed.
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
:param dnn_activation: Activation function to use in DNN
:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN
:param task: str, ``"binary"`` for binary logloss or ``"regression"`` for regression loss
:param device: str, ``"cpu"`` or ``"cuda:0"``
:return: A PyTorch model instance.
"""
def __init__(self,
linear_feature_columns, dnn_feature_columns, use_fm=True,
dnn_hidden_units=(256, 128),
l2_reg_linear=0.00001, l2_reg_embedding=0.00001, l2_reg_dnn=0, init_std=0.0001, seed=1024,
dnn_dropout=0,
dnn_activation='relu', dnn_use_bn=False, task='binary', device='cpu'):
super(DeepFM, self).__init__(linear_feature_columns, dnn_feature_columns, l2_reg_linear=l2_reg_linear,
l2_reg_embedding=l2_reg_embedding, init_std=init_std, seed=seed, task=task,
device=device)
self.use_fm = use_fm
self.use_dnn = len(dnn_feature_columns) > 0 and len(
dnn_hidden_units) > 0
if use_fm:
self.fm = FM()
if self.use_dnn:
self.dnn = DNN(self.compute_input_dim(dnn_feature_columns), dnn_hidden_units,
activation=dnn_activation, l2_reg=l2_reg_dnn, dropout_rate=dnn_dropout, use_bn=dnn_use_bn,
init_std=init_std, device=device)
self.dnn_linear = nn.Linear(
dnn_hidden_units[-1], 1, bias=False).to(device)
self.add_regularization_weight(
filter(lambda x: 'weight' in x[0] and 'bn' not in x[0], self.dnn.named_parameters()), l2_reg_dnn)
self.add_regularization_weight(self.dnn_linear.weight, l2_reg_dnn)
self.to(device)
def forward(self, X):
sparse_embedding_list, dense_value_list = self.input_from_feature_columns(X, self.dnn_feature_columns,
self.embedding_dict)
# 1.线性层
logit = self.linear_model(X)
# 2.FM层
if self.use_fm and len(sparse_embedding_list) > 0:
# sparse_embedding_list -->(F, B, 1, 4)
fm_input = torch.cat(sparse_embedding_list, dim=1) #(B, F, E)
logit += self.fm(fm_input)
# 3.Deep层
if self.use_dnn:
dnn_input = combined_dnn_input(
sparse_embedding_list, dense_value_list)
dnn_output = self.dnn(dnn_input)
dnn_logit = self.dnn_linear(dnn_output)
logit += dnn_logit
y_pred = self.out(logit)
return y_pred
FM模型
模型结构:

交叉项计算公式:
交 叉 项 : 1 / 2 ∗ ∑ i = 1 k ( ( ∑ i = 1 n v i k ∗ x i ) 2 − ∑ i = 1 n v i k 2 ∗ x i 2 ) 交叉项:1/2*\sum_{i=1}^{k}((\sum_{i=1}^n{v_{ik}*x_{i}})^2 - \sum_{i=1}^{n}{v_{ik}^2*x_{i}^2}) 交叉项:1/2∗i=1∑k((i=1∑nvik∗xi)2−i=1∑nvik2∗xi2)
class FM(nn.Module):
"""Factorization Machine models pairwise (order-2) feature interactions
without linear term and bias.
Input shape
- 3D tensor with shape: ``(batch_size,field_size,embedding_size)``.
Output shape
- 2D tensor with shape: ``(batch_size, 1)``.
References
- [Factorization Machines](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
"""
def __init__(self):
super(FM, self).__init__()
def forward(self, inputs):
fm_input = inputs # (B, F, E)
square_of_sum = torch.pow(torch.sum(fm_input, dim=1, keepdim=True), 2)
sum_of_square = torch.sum(fm_input * fm_input, dim=1, keepdim=True)
cross_term = square_of_sum - sum_of_square
cross_term = 0.5 * torch.sum(cross_term, dim=2, keepdim=False)
return cross_term
# 实例化
fm = FM()
input_ = torch.rand((32, 26, 4))
fm(input_).shape
torch.Size([32, 1])
相关计算
b = torch.sum(input_ * input_, dim=1, keepdim=True)
b.size()
torch.Size([32, 1, 4])
Linear层的探索
线性层
class Linear(nn.Module):
def __init__(self, feature_columns, feature_index, init_std=0.0001, device='cpu'):
super(Linear, self).__init__()
self.feature_index = feature_index
self.device = device
# 判断为稀疏特征还是稠密特征,并创建相对应的List
self.sparse_feature_columns = list(
filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if len(feature_columns) else []
self.dense_feature_columns = list(
filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if len(feature_columns) else []
self.varlen_sparse_feature_columns = list(
filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if len(feature_columns) else []
self.embedding_dict = create_embedding_matrix(feature_columns, init_std, linear=True, sparse=False,
device=device)
# nn.ModuleDict(
# {feat.embedding_name: nn.Embedding(feat.dimension, 1, sparse=True) for feat in
# self.sparse_feature_columns}
# )
# .to("cuda:1")
for tensor in self.embedding_dict.values():
nn.init.normal_(tensor.weight, mean=0, std=init_std)
if len(self.dense_feature_columns) > 0:
self.weight = nn.Parameter(torch.Tensor(sum(fc.dimension for fc in self.dense_feature_columns), 1)).to(
device)
torch.nn.init.normal_(self.weight, mean=0, std=init_std)
def forward(self, X):
sparse_embedding_list = [self.embedding_dict[feat.embedding_name](
X[:, self.feature_index[feat.name][0]:self.feature_index[feat.name][1]].long()) for
feat in self.sparse_feature_columns]
dense_value_list = [X[:, self.feature_index[feat.name][0]:self.feature_index[feat.name][1]] for feat in
self.dense_feature_columns]
varlen_embedding_list = get_varlen_pooling_list(self.embedding_dict, X, self.feature_index,
self.varlen_sparse_feature_columns, self.device)
sparse_embedding_list += varlen_embedding_list
if len(sparse_embedding_list) > 0 and len(dense_value_list) > 0:
linear_sparse_logit = torch.sum(
torch.cat(sparse_embedding_list, dim=-1), dim=-1, keepdim=False)
# 只对稠密矩阵执行权重项目
linear_dense_logit = torch.cat(
dense_value_list, dim=-1).matmul(self.weight)
linear_logit = linear_sparse_logit + linear_dense_logit
elif len(sparse_embedding_list) > 0:
linear_logit = torch.sum(
torch.cat(sparse_embedding_list, dim=-1), dim=-1, keepdim=False)
elif len(dense_value_list) > 0:
linear_logit = torch.cat(
dense_value_list, dim=-1).matmul(self.weight)
else:
linear_logit = torch.zeros([X.shape[0], 1])
return linear_logit
Embeddind_list探索
linear_sparse_logit

相关计算
# sparse_embedding_list
C = [torch.rand((32, 1, 4)) for i in range(26)]
cat_vector = torch.cat(C, dim=-1)
cat_vector.size()
torch.Size([32, 1, 104])
len(C)
26
logit = torch.sum(cat_vector, dim=-1, keepdim=False)
logit.size()
torch.Size([32, 1])
torch.cat(C, dim=1).size()
torch.Size([32, 26, 4])
13*25
325
linear_dense_logit
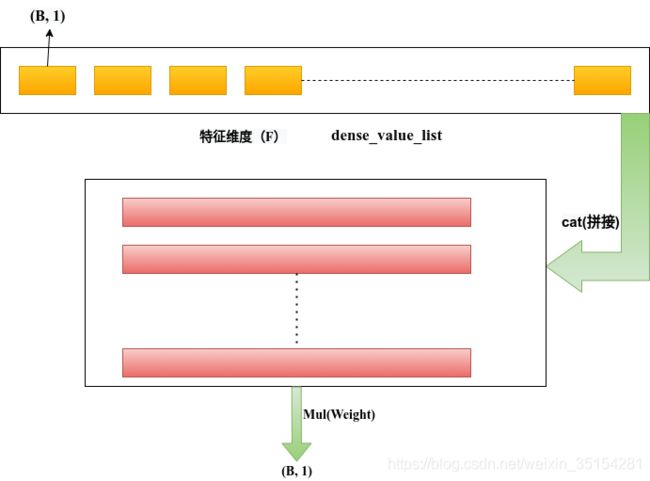
相关计算
# dense_value_list
weight = torch.rand(26, 1)
C = [torch.rand((32, 1)) for i in range(26)]
# 拼接
dense_vector = torch.cat(C, dim=-1)
dense_vector.size()
torch.Size([32, 26])
# 加权求和
torch.matmul(dense_vector, weight).size()
torch.Size([32, 1])
参考
DeepFM算法