基于Python+OpenCV的人脸识别实现带墨镜效果
环境以及执行步骤
- 相关介绍
-
- 环境配置
- 相关库安装介绍
- 上代码
- github地址
- 动图介绍
- 改进
相关介绍
你好! 项目起初来源于一本科生的毕业设计,由于我给了一版更加优秀,所以初始版本的例子给予分享。其中可能最难的地方就在于环境配置,其他的要求基本没啥。对了可以随意的添加你想要的图片效果,就在文件夹里替换就行。本次代码也是基于这个大佬的文章
https://www.makeartwithpython.com/blog/deal-with-it-generator-face-recognition/
环境配置
起初Opencv就不是为了Python所使用的,谁让他简单易用而且库多呢,对吧,而且谁让我这两年就学了python呢(此处狗头)。原谅我才疏学浅:
- win ,window10+python3.6以上+vs2017+opencv+pycharm;
- mac,macos+python3.6以上+opencv+pycharm;
详细库如下所示:
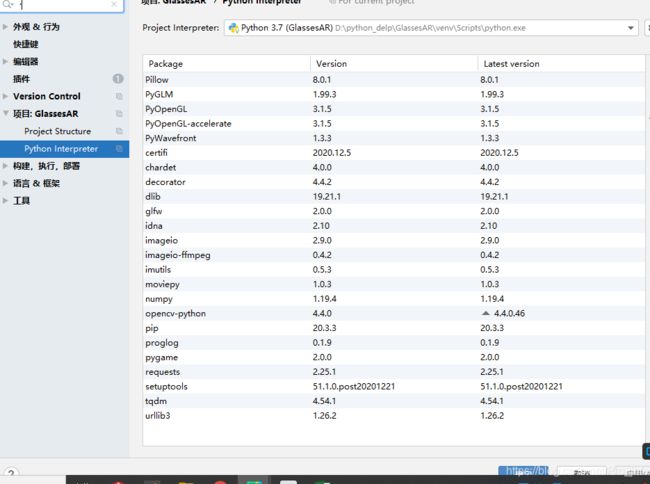
相关库安装介绍
一般玩python的人都知道,这些库就跟做饭加酱油一样,放那种调料,该怎么放它饭好吃一直是各个csdn大佬的贡献,所以我也不多比比,直接上各位大佬的教程。
1、切记安装一定要对应python版本号,建议python3.6以上,下面是安装教程。
https://blog.csdn.net/u012325865/article/details/83961127
2、由于在安装python版本的opencv支持库回遇到版本以及32位64位的问题,需要自己去寻找python版本的.whl下载.下面的地址是各种whl网址
https://www.lfd.uci.edu/~gohlke/pythonlibs/
上面网址详细说明了whl的库文件如何使用。
https://blog.csdn.net/weixin_38168838/article/details/99738371?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-11&spm=1001.2101.3001.4242
3、cmake与dlib安装比较复杂,这两个库是必须要安装的,且需要支持的环境,而且由于windows系统并不集成vs相关库而opencv却又是需要安装vs库,所以建议直接下菜vs2017版本。下面网址会详细描述。
https://www.cnblogs.com/wdzn/p/9675821.html
4、待各种库文件安装完毕需要执行realtime_liu即可进行视频实时换眼镜,这里在弹出框里进行按键操作,d按键代表开始,c按键代表替换眼镜,q按键代表退出程序。
上代码
说得多不如做的做,直接上代码。
#具体啥玩意的你就点击运行就行了。d键是开始,c键是替换照片,q键是结束。这代码一看就会。
import dlib
from PIL import Image, ImageDraw, ImageFont
import random
import cv2
from imutils.video import VideoStream
from imutils import face_utils, translate, rotate, resize
import numpy as np
vs = VideoStream().start()
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')
max_width = 500
frame = vs.read()
frame = resize(frame, width=max_width)
fps = vs.stream.get(cv2.CAP_PROP_FPS) # need this for animating proper duration
animation_length = fps * 5
current_animation = 0
glasses_on = fps * 3
# uncomment for fullscreen, remember 'q' to quit
# cv2.namedWindow('deal generator', cv2.WND_PROP_FULLSCREEN)
#cv2.setWindowProperty('deal generator', cv2.WND_PROP_FULLSCREEN,
# cv2.WINDOW_FULLSCREEN)
deal = Image.open("./Glasses/0.png")
text = Image.open('text.png')
dealing = False
number =0
while True:
frame = vs.read()
frame = resize(frame, width=max_width)
img_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = []
rects = detector(img_gray, 0)
img = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
# print(rects)
for rect in rects:
face = {
}
shades_width = rect.right() - rect.left()
# predictor used to detect orientation in place where current face is
shape = predictor(img_gray, rect)
shape = face_utils.shape_to_np(shape)
# grab the outlines of each eye from the input image
leftEye = shape[36:42]
rightEye = shape[42:48]
# compute the center of mass for each eye
leftEyeCenter = leftEye.mean(axis=0).astype("int")
rightEyeCenter = rightEye.mean(axis=0).astype("int")
# compute the angle between the eye centroids
dY = leftEyeCenter[1] - rightEyeCenter[1]
dX = leftEyeCenter[0] - rightEyeCenter[0]
angle = np.rad2deg(np.arctan2(dY, dX))
# print((shades_width, int(shades_width * deal.size[1] / deal.size[0])))
# 图片重写
current_deal = deal.resize((shades_width, int(shades_width * deal.size[1] / deal.size[0])),
resample=Image.LANCZOS)
current_deal = current_deal.rotate(angle, expand=True)
current_deal = current_deal.transpose(Image.FLIP_TOP_BOTTOM)
face['glasses_image'] = current_deal
left_eye_x = leftEye[0,0] - shades_width // 4
left_eye_y = leftEye[0,1] - shades_width // 6
face['final_pos'] = (left_eye_x, left_eye_y)
# I got lazy, didn't want to bother with transparent pngs in opencv
# this is probably slower than it should be
# 图片动画以及配置
if dealing:
# print("current_y",int(current_animation / glasses_on * left_eye_y))
if current_animation < glasses_on:
current_y = int(current_animation / glasses_on * left_eye_y)
img.paste(current_deal, (left_eye_x, current_y-20), current_deal)
else:
img.paste(current_deal, (left_eye_x, left_eye_y-20), current_deal)
# img.paste(text, (75, img.height // 2 - 52), text)
# 起初动画配置
if dealing:
current_animation += 1
frame = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
# 按键选择
cv2.imshow("deal generator", frame)
key = cv2.waitKey(1) & 0xFF
#退出程序
if key == ord("q"):
break
# 开始程序
if key == ord("d"):
dealing = not dealing
# 图片切换
if key == ord("c"):
# 让图片从上面重新开始
# current_animation = 0
number = str(random.randint(0, 8))
print(number)
deal = Image.open("./Glasses/"+number+".png")
cv2.destroyAllWindows()
vs.stop()
github地址
这是大佬原始
https://github.com/burningion/automatic-memes.git
这是我的也就是本文的
https://github.com/Proshare/Auto-Glasses.git
动图介绍
本人太丑,我就不上了,就随便整个别人的吧(原始老哥贼帅),我这唯一区别就是可以替换眼镜。
改进
由于本科毕设不能太low,就最好能做到那种眼镜360度跟着头部来进行角度替换,所以这个就过时了。于是出了第二版,这里就不上代码了,等明年这同学搞完我再贴上代码。类似于这种。
http://pan.baidu.com/s/1dDGs7Sl