基于pytorch模型剪枝的实现(极大的减少模型计算参数加快模型运行速度)
深度模型剪枝实现以及一些网络优化技巧
- 模型剪枝:Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017).
-
- 基于论文的代码复现以及拓展:
- 在网络上中加入其它优化方法
-
- 最强深度学习优化器Ranger
- warm up与consine learning rate
-
- 为什么使用warmup?
- label smooth
- apex混合精度训练
- 梯度累加
- 其他网络部署的方式:
模型剪枝:Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017).
论文参考:Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017).
1. 概述
导读:这篇文章是一篇关于CNN网络剪枝的文章,文章里面提出通过BatchNorm层的
scaling参数确定重要的channel,排除不重要的channel,从而达到网络瘦身的目的。
此外文章还引入了L1范数,通过L1范数约束的稀疏特性使得BN的scaling参数趋于0,
从而帮助确定非重要的channel,并按照给定的阈值剪裁掉。
文章中对于剪裁的流程可以归纳为下图1所示,通过BN的scaling参数确定非重要的channel并剪裁掉,之后再根据需要是否再进行迭代剪裁。

2. 剪裁方法
文章中将正则化引入到网络的损失函数中,其总的定义如下:
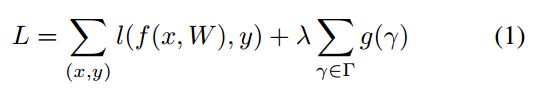
这里引入scaling参数有如下需要注意的事项:
1)scaling参数是加载BN层上的,若是对于没有BN的CNN网络来说加入scaling会增加卷积的权值参数,带来不了稀疏的结构;
2)在BN层的前面添加scaling参数会被BN给补偿回来;
3)加在BN层的后面就相当于是两个Scaling参数进行运算了,也是达到不了稀疏的目的的;
这篇文章的剪裁方法是迭代进行的,其剪裁的流程图见下图所示:

3.裁剪后的网络参数情况

基于论文的代码复现以及拓展:
基于Learning Efficient Convolutional Networks Through Network Slimming论文。实现的代码及其拓展的github地址为:https://github.com/Culturenotes/Network-Slimming。
目前加入了Resnet和Densenet的网络模型剪枝的实现,后续将会添加EfficientNet、MobileNet、Xception、shuffleNet的模型剪枝实现。如果感兴趣可以和我一起改进并且实现他们。
在网络上中加入其它优化方法
最强深度学习优化器Ranger
Ranger=RAdam+LookAhead。强强结合,性能更优速度更快!
RAdam可以说是优化者在培训开始时建立的最佳基础。RAdam利用动态整流器根据方差调整Adam的自适应动量,并有效地提供自动预热,根据当前数据集定制,以确保扎实的训练开始。
LookAhead受到深度神经网络损失表面理解的最新进展的启发,并在整个训练期间提供了稳健和稳定探索的突破。“减少了对广泛超参数调整的需求”,同时实现“以最小的计算开销实现不同深度学习任务的更快收敛”。
因此,两者都在深度学习优化的不同方面提供了突破,并且这种组合具有高度协同性,可能为您的深度学习结果提供最佳的两种改进。因此,对更加稳定和强大的优化方法的追求仍在继续,通过结合两项最新突破(RAdam + LookAhead),Ranger的整合有望为深度学习提供又一步。
代码实现如下:
import math
import torch
from torch.optim.optimizer import Optimizer
def centralized_gradient(x, use_gc=True, gc_conv_only=False):
if use_gc:
if gc_conv_only:
if len(list(x.size())) > 3:
x.add_(-x.mean(dim=tuple(range(1, len(list(x.size())))), keepdim=True))
else:
if len(list(x.size())) > 1:
x.add_(-x.mean(dim=tuple(range(1, len(list(x.size())))), keepdim=True))
return x
class Ranger(Optimizer):
def __init__(self, params, lr=1e-3, # lr
alpha=0.5, k=6, N_sma_threshhold=5, # Ranger options
betas=(.95, 0.999), eps=1e-5, weight_decay=1e-5, # Adam options
use_gc=True, gc_conv_only=False, gc_loc=True
):
# parameter checks
if not 0.0 <= alpha <= 1.0:
raise ValueError(f'Invalid slow update rate: {alpha}')
if not 1 <= k:
raise ValueError(f'Invalid lookahead steps: {k}')
if not lr > 0:
raise ValueError(f'Invalid Learning Rate: {lr}')
if not eps > 0:
raise ValueError(f'Invalid eps: {eps}')
# prep defaults and init torch.optim base
defaults = dict(lr=lr, alpha=alpha, k=k, step_counter=0, betas=betas,
N_sma_threshhold=N_sma_threshhold, eps=eps, weight_decay=weight_decay)
super().__init__(params, defaults)
# adjustable threshold
self.N_sma_threshhold = N_sma_threshhold
# look ahead params
self.alpha = alpha
self.k = k
# radam buffer for state
self.radam_buffer = [[None, None, None] for ind in range(10)]
# gc on or off
self.gc_loc = gc_loc
self.use_gc = use_gc
self.gc_conv_only = gc_conv_only
# level of gradient centralization
#self.gc_gradient_threshold = 3 if gc_conv_only else 1
print(
f"Ranger optimizer loaded. \nGradient Centralization usage = {self.use_gc}")
if (self.use_gc and self.gc_conv_only == False):
print(f"GC applied to both conv and fc layers")
elif (self.use_gc and self.gc_conv_only == True):
print(f"GC applied to conv layers only")
def __setstate__(self, state):
print("set state called")
super(Ranger, self).__setstate__(state)
def step(self, closure=None):
loss = None
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError(
'Ranger optimizer does not support sparse gradients')
p_data_fp32 = p.data.float()
state = self.state[p] # get state dict for this param
if len(state) == 0:
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
# look ahead weight storage now in state dict
state['slow_buffer'] = torch.empty_like(p.data)
state['slow_buffer'].copy_(p.data)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(
p_data_fp32)
# begin computations
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
# GC operation for Conv layers and FC layers
# if grad.dim() > self.gc_gradient_threshold:
# grad.add_(-grad.mean(dim=tuple(range(1, grad.dim())), keepdim=True))
if self.gc_loc:
grad = centralized_gradient(grad, use_gc=self.use_gc, gc_conv_only=self.gc_conv_only)
state['step'] += 1
# compute variance mov avg
exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
# compute mean moving avg
exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1)
buffered = self.radam_buffer[int(state['step'] % 10)]
if state['step'] == buffered[0]:
N_sma, step_size = buffered[1], buffered[2]
else:
buffered[0] = state['step']
beta2_t = beta2 ** state['step']
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * \
state['step'] * beta2_t / (1 - beta2_t)
buffered[1] = N_sma
if N_sma > self.N_sma_threshhold:
step_size = math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (
N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])
else:
step_size = 1.0 / (1 - beta1 ** state['step'])
buffered[2] = step_size
# apply lr
if N_sma > self.N_sma_threshhold:
denom = exp_avg_sq.sqrt().add_(group['eps'])
G_grad = exp_avg / denom
else:
G_grad = exp_avg
if group['weight_decay'] != 0:
G_grad.add_(p_data_fp32, alpha=group['weight_decay'])
# GC operation
if self.gc_loc == False:
G_grad = centralized_gradient(G_grad, use_gc=self.use_gc, gc_conv_only=self.gc_conv_only)
p_data_fp32.add_(G_grad, alpha=-step_size * group['lr'])
p.data.copy_(p_data_fp32)
# integrated look ahead...
# we do it at the param level instead of group level
if state['step'] % group['k'] == 0:
# get access to slow param tensor
slow_p = state['slow_buffer']
# (fast weights - slow weights) * alpha
slow_p.add_(p.data - slow_p, alpha=self.alpha)
# copy interpolated weights to RAdam param tensor
p.data.copy_(slow_p)
return loss
官方源码请参考:https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
RAdam论文参考:
RAdam(Liu,Jiang,He,Chen,Liu,Gao,Han) - “ 关于自适应学习率和超越的变化 ”
LookAhead论文参考:
LookAhead(Zhang,Lucas,Hinton,Ba) - “ Lookahead Optimizer:k向前迈进,后退一步 ”
warm up与consine learning rate
warm up最早来自于这篇文章:
https://arxiv.org/pdf/1706.02677.pdf
根据这篇论文所描述的,我们一般只在前5个epoch使用warm up。
consine learning rate来自于这篇文章:https://arxiv.org/pdf/1812.01187.pdf
通常情况下,把warm up和consine learning rate一起使用会达到更好的效果。
为什么使用warmup?
1、 理性分析
因为模型的weights是随机初始化的,可以理解为训练之初模型对数据的“理解程度”为0(即:没有任何先验知识),在第一个epoches中,每个batch的数据对模型来说都是新的,模型会根据输入的数据进行快速调参,此时如果采用较大的学习率的话,有很大的可能使模型对于数据“过拟合”(“学偏”),后续需要更多的轮次才能“拉回来”;
当模型训练一段时间之后(如:10epoches或10000steps),模型对数据具有一定的先验知识,此时使用较大的学习率模型就不容易学“偏”,可以使用较大的学习率加速模型收敛;
当模型使用较大的学习率训练一段时间之后,模型的分布相对比较稳定,此时不宜从数据中再学到新特点,如果仍使用较大的学习率会破坏模型的稳定性,而使用小学习率更容易获取local optima。
2 、感性分析
刚开始模型对数据完全不了解,这个时候步子太大,容易扯着dan,此时需要使用小学习率摸着石头过河;
对数据了解了一段时间之后,可以使用大学习率朝着目标大步向前;
快接近目标时,使用小学习率进行探索,此时步子太大,容易错过最近点
代码实现**:
# MultiStepLR without warm up
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=args.milestones, gamma=0.1)
# warm_up_with_multistep_lr
warm_up_with_multistep_lr = lambda epoch: epoch / args.warm_up_epochs if epoch <= args.warm_up_epochs else 0.1**len([m for m in args.milestones if m <= epoch])
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=warm_up_with_multistep_lr)
# warm_up_with_cosine_lr
warm_up_with_cosine_lr = lambda epoch: epoch / args.warm_up_epochs if epoch <= args.warm_up_epochs else 0.5 * ( math.cos((epoch - args.warm_up_epochs) /(args.epochs - args.warm_up_epochs) * math.pi) + 1)
scheduler = torch.optim.lr_scheduler.LambdaLR( optimizer, lr_lambda=warm_up_with_cosine_lr)
上面的三段代码分别是不使用warm up+multistep learning rate 衰减、使用warm up+multistep learning rate 衰减、使用warm up+consine learning rate衰减。代码均使用pytorch中的lr_scheduler.LambdaLR自定义学习率衰减器。
label smooth
对于分类任务,通常我们使用cross entropy损失函数进行训练,即:
criterion = nn.CrossEntropyLoss().cuda()
在这篇文章:https://arxiv.org/pdf/1812.01187.pdf 中给出了带label smooth的cross entropy函数计算公式。我们在pytorch中实现了它,代码如下:
class LabelSmoothCELoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, pred, label, smoothing=0.1):
pred = F.softmax(pred, dim=1)
one_hot_label = F.one_hot(label, pred.size(1)).float()
smoothed_one_hot_label = (
1.0 - smoothing) * one_hot_label + smoothing / pred.size(1)
loss = (-torch.log(pred)) * smoothed_one_hot_label
loss = loss.sum(axis=1, keepdim=False)
loss = loss.mean()
return loss
使用时,只需要:
criterion = LabelSmoothCELoss().cuda()
替换掉原来的cross entropy损失函数即可。
apex混合精度训练
apex是NVIDIA发布的开源混合精度训练工具库。该工具库提供了AMP(自动混合精度)和FP16_Optimizer两种不同的库。AMP提供自动混合精度训练支持,该库会自动检查执行的操作,对于FP16安全的操作在训练中Cast到FP16精度,反之则选择FP32精度。FP16_Optimizer提供的是高阶版混合精度训练,其提供了更多详细的实现细节,对于整个网络完全采用FP16精度训练。
这里只介绍如何用apex实现最简单的自动混合精度训练支持。
首先安装apex工具库。如果你是Python3.7环境,使用下列命令安装:
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
如果你是Python3.6环境,则使用下列命令安装:
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir ./
安装完成后,在train.py中进行下列修改:
from apex import amp
......
......
# 定义好Model和optimizer后,增加下面这行代码:
model, optimizer = amp.initialize(model, optimizer, opt_level='O1')
# 反传梯度原本的代码是loss.backward(),改为下面两行代码:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
这样在训练时就会使用apex自动混合精度训练了。使用apex后,对于同一个训练任务,可有效降低显存占用25-30%。在同样batchsize的情况下,使用apex会比不使用apex的情况下训练速度会稍稍变慢,但由于使用apex后,显存占用减少,因此可以继续扩大batchsize,这样相比原来的Batchsize训练速度还是要快很多。最后,在同样的batchsize情况下,使用apex训练出的模型性能和未使用apex时基本一致。
梯度累加
当我们的显卡资源有限时,训练时往往跑不起大的batchsize。梯度累加可以用较少的显卡模拟较大batchsize情况下的训练。具体来说,我们每次用小的batchsize计算出各个变量的梯度,然后把梯度累加起来,最后当小的batchsize累加和等于我们设定的大batchsize时再更新梯度。注意这个模拟较大Batchsize是近似的,因为bn层仍然按照小的batchsize来更新。
在train.py中,进行下列修改,就可以实现梯度累加:
inputs, labels = inputs.cuda(), labels.cuda()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss = loss / args.accumulation_steps
loss.backward()
if iter_index % args.accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
其中,loss = loss / args.accumulation_steps根据累加次数把loss做除法,使得在不修改学习率的情况下最终累加的反传梯度数量级与原来一致(由于我们在累加的过程中考虑了多次小batchsize产生的loss,但又除以了累加次数,所以在loss.backward()多次累加后就近似相当于大batchsize计算出的loss产生的梯度)。
最后,我们经过累加的梯度次数后才使用optimizer.step()更新一次网络参数,然后使用optimizer.zero_grad()将梯度清零。
需要注意的是,由于batchsize仍然按照真实的小batchsize更新,因此真实batchsize不宜设置的太小,否则误差会比较大。对于分类任务,一般真实batchsize不宜小于32。
其他网络部署的方式:
下一篇,将讲解使用TensoRrt的c++接口使用,比较网络剪枝之后使用trt加速,和未进行网络剪枝trt加速,以及原生pytorch部署后运行的速度对比。