Python快速入门学习笔记:第六天
这个是为准备考研复试,希望做一个textCNN文本情感分析打语言基础的自学笔记,博主本身本科非计算机专业,如果网友们有幸看见本文,博客中内容如有疏漏,不吝赐教
第8节 文件
8.1 从创建文件对象开始
创建文件对象可以使用open(),基本语法格式如:open(name[, mode[, buffering]]),只有文件名,而没有目录代表在当前目录的文件。如果是全路径,
如:D:\Download\google-access-helper-2.3.0\readme.txt,
可以写成:open(r"D:\Download\google-access-helper-2.3.0\readme.txt","a")
顺便说一下在路径前面加r是为了防止\转义。
常见的打开方式有:
| 模式 | 描述 |
|---|---|
| r | 读模式 |
| w | 写模式(不存在则创建,存在则重写) |
| a | 追加模式(不存在则创建,存在则在末尾追加) |
| b | 二进制模式(可与其他模式混用) |
| + | 读写模式(可与其他模式混用) |
当我们使用了open以后,一定要记得使用close关闭流。如:
try:
f = open("Demo_01.txt", "w")
str = "ABCDEFG\n"
l = ['12345', '678980']
f.write(str)
f.writelines(l)
except BaseException as e:
print(e)
finally:
f.close()
执行效果如下:

另外,python处理文件的一个更好的方式是使用with关键字,下面的异常节也有描述。with作为上下文管理器,可以自动管理上下文资源,无论什么原因跳出了文件的执行,都能正常关闭文件。如:
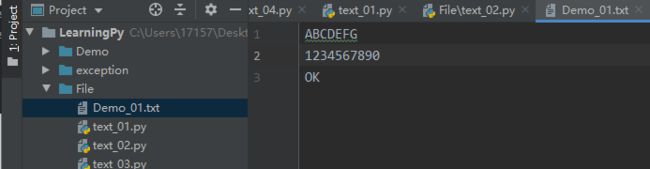
with open("Demo_01.txt", "a") as f:
f.write("\nOK")
运行结果为:
8.2 文本的读取
常见的文本文件读取方法有:read,readline,readlines。其中:
- read从文件中读取size个字符,并作为结果放回。如果没有size参数,则会读取整个文件
- readline读取一行内容作为返回,读取到文件末尾,会返回空字符串
- readlines文本文件中,每一行作为一个字符串返回存入列表中,返回该列表
# 三个方法的实例
with open("Demo_01.txt", "r", encoding="utf-8") as f:
str = f.read(3)
print(str, end="\n")
print("---------------------------------")
with open("Demo_01.txt", "r", encoding="utf-8") as f:
while True:
line = f.readline()
if not line:
break
else:
print(line, end="")
print("\n---------------------------------")
with open("Demo_01.txt", "r", encoding="utf-8") as f:
content = f.readlines()
for line in content:
print(line.rstrip())
同时,对于一些非文本文件,可以采用处理二进制文件文本文件的方式处理它,例如:对一些MP3,JPEG文件。

暂时把它重构成一个图片格式的文件来练习:

然后尝试输入和输出二进制文件:
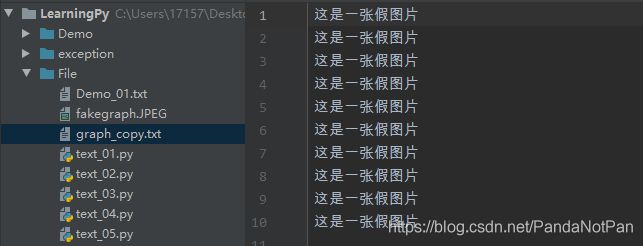
with open("fakegraph.JPEG", "rb") as f:
with open("graph_copy.txt", "wb") as w:
for line in f.readlines():
w.write(line)
print("OK!")
可以得到一个经过类似copy操作的新文件,重构文件属性可以看见经过执行后的文件:
8.3 序列化
序列化是指:将对象转化成“串行化”数据形式,存储到硬盘或者网络传输到其他的低分,反序列化是其逆过程。我们可以用pickle模块中的函数,实现序列化和反序列操作。
语法结构大概为:
pickle.dump(obj,file) # 前者为被序列化对象,后者为存储文件
pickle.load(file) # 从file读取数据,反序列化成对象
具体使用方法如代码所示:
import pickle
str1 = "ABC"
str2 = 123
str3 = [1, 2, 3]
with open("data.dat","wb") as f:
pickle.dump(str1, f)
pickle.dump(str2, f)
pickle.dump(str3, f)
with open("data.dat","rb") as f:
re1 = pickle.load(f)
re2 = pickle.load(f)
re3 = pickle.load(f)
print(re1);print(re2);print(re3)
if re1 is str1:
print("True")
else:
print("False")
由最后的判断结果false可见,序列化后的内容和反序列化后的内容是一样的,但是不再是同一个对象。
8.4 CSV文件
csv文件是逗号分隔符文本格式,常用与数据交换,excel文件和数据库数据导入和导出。
CSV文件中:
- 不能指定字体颜色等样式
- 值没有类型,所有值都是字符串
- 不能指定字体颜色等样式
- 不能指定单元格宽高,无法合并
- 不能嵌入图像图表
总之,它只是一个单纯的列表形式的文件。如:
import csv
with open("excel_demo.csv", "r") as f:
a = csv.reader(f)
for row in a:
print(row)
with open("excel.csv", "w", newline="") as f:
b = csv.writer(f)
b.writerow(["ID","姓名","年龄"])
b.writerow(["8001","ALICE","25"])
b.writerow(["8002", "ZOOM", "31"])
c = [["asd","zxc"],["123","456"],["qwer","asdf"]]
b.writerow(c)
最后产生新的文本输出的结果:
ID,姓名,年龄
8001,ALICE,25
8002,ZOOM,31
"['asd', 'zxc']","['123', '456']","['qwer', 'asdf']"
第9节:异常
写程序的时候,我们有时候要求程序可以在部分错误的情况下,报出错误之后程序依然可以向下执行。在以往对于错误的解决往往是用if判断语句来判断运行或者输入结果来规避错误,例如以前处理错误:用if语句判断条件设置除数不能为0,否则在else代码块中打印出报错。
但是在实际开发中,出现错误的原因多种多样,并不能写一大堆的if语句,低效又繁琐。在Python中,为了解决代码运行过程中可能出现的异常,设置了异常处理机制。
Python中的异常处理机制try…except…类似于之前学习的Java中的try…catch…,基本语法格式如:
0
try:
# code...
except BaseException as e:
# code...
其中,BaseException作为所有异常的父类经常会被使用到,as关键字也是指代了之前的BaseException,当然也可以去掉。
和if…else if一样,try…except…也可以使用多次,来同时处理多个异常。但是在使用多个except时,需要注意的是,子类最好放在父类之前。假如代码中第一个except就是BaseException,那么所有的异常都可以在第一个except处理。
try:
a = 5
b = input("Input:")
c = float(a)/float(b)
except ZeroDivisionError:
print("Divisor can't be 0")
except ValueError:
print("Can't convert a string to a number")
except NameError:
print("Not define")
except BaseException as e:
print(e)
else:
print(c)
在异常处理过程中,也需要一个终结所有问题的方式:无论程序执行地是否顺利,最后都可以以我们想要的方式结束程序的执行。于是就诞生了finally关键字。
finally可以终结所有异try…except…else代码块的执行结果,无论程序是否发生异常,最终都要执行finally里面的内容。因此也常被用来管理和结束某些资源的占用,以避免浪费。
try:
f = open("text_01.txt", "r") # 以读方式打开文件text_01
content = f.readline()
print(content)
except FileNotFoundError:
print("Not Found!")
finally:
print("Run close")
try:
f.close()
except BaseException as e:
print(e)
print("End")
但是代码太长并非好事,可能会为后期维护带来麻烦,于是引入了with关键字。使用效果如下:
with open("text_01.txt", "r") as f:
content = f.readline()
print(content)
用现有的三行代码代替了上面一堆代码所做的事情,虽然with很方便但是并不能完全取代try…except…finally结构。
with可以自动管理资源,with代码块在执行完毕之后可以自动还原进入代码执行之前的现场或上下文。无论是否异常总能保证资源的正常释放。with关键字在网络通信和文件管理上可以发挥很大的用处。具体参考内容:浅谈 Python 的 with 语句
秉承“万物皆对象”的原则,在Python中,除了已经提供好的异常类型,有时候我们也需要针对项目本身,自己定义一些异常以方便我们在开发中的使用。
通常继承Exception或者其子类即可,并以Exception为后缀命名。
class NumException(Exception):
def __init__(self, numInfo):
Exception.__init__(self)
self.numInfo = numInfo
def __str__(self):
return "Error!"
# 下面是测试代码 #
if __name__ == "__main__":
# 若结果为TRUE,模块为独立文件运行。
num = int(input())
if num < 0:
raise NumException(num)
else:
print(num+1024)
最后,对于系统爆出来的异常,要经常观察内容和统计结果。对各个异常进行学习也是能够有效了解和认识Python语言机制的方法。
第10节 模块与包
10.1 模块
模块类似于其他一些语言的头文件,或者Java的package。使用起来相对来说比较方便,语法简单。基本语法为:import module1[, module2[,... moduleN]
需要注意的是,from…import…结构导入的是文件下的内容,我们直接使用这些内容即可,前面再也不需要加文件名称。例如:
import math as m
from math import fabs
from math import * # 整体导入,慎用
print(m.fabs(-1)) # 第一句导入奏效
print(fabs(-1)) # 第二句导入奏效
除了这样的静态导入,python也有使用import动态导入,具体如下:
name = "math" # 命名了这个模块
m = __import__(name) # 开始导入
print(m.pi) # 使用模块
但是这个方法只是可行,并不常用,也不建议使用。如果需要的话,可以使用importlib进行操作。如:
import importlib
m = importlib.import_module("math")
print(m.pi)
import语句导入的模块会被导入一次,它的本质是使用了__import__()。当导入一个模块的时候,python解释器进行执行最后生成一个对象,这个对象就是代表了被夹在的模块。
在动态导入的时候,遇到了自己也没有解决问的代码问题。如果以后深入了Python语言了解,再拐回头来看这个问题:
import text_01
text_01.print_star()
# 测试动态导入
import text_02
import importlib
def print_star():
print("************************************")
print("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
importlib.reload(text_02)
print("end")
最后的输出结果:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
************************************
end
************************************
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
************************************
end
本以为会打印两行星号,为什么星号一共打印三行?
10.2 包
包是一种管理 Python 模块命名空间的形式,比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。就好像使用模块的时候不用担心不同模块之间的全局变量相互影响一样,这种形式也不用担心不同库之间的模块重名的情况。具体使用如:
在新建的时候,选择创建Python package,建立一个包
import package.A # 仅导入此包,包名package
from package.A import module_1 # 导入包中的module_1模块
from package.A.module_1 import function_name # 导入模块中的函数
导入包的本质是包中的“init.py”文件,也就意味着执行了这个包下面的此文件。因此在导入模块的时候不需要再一个个导入。从本质上讲,包是一个含有__init__.py的文件夹。