本文作者:代码家,资深开发者,热衷于开源社区, GitHub 20K 的 Star,15K 的 Follower;数字货币信奉者,热爱二级市场交易(股票+数字货币);目前在真格基金做投资。如果你想与代码家交流,可以加他的微信:daimajia(著名来源和身份),如果你在创业,或者有想法创业,也欢迎投递 BP 或者和代码家邮件交流: [email protected]
在工业时代,煤炭和钢铁的使用量是一个国家发达程度的指标。而到了信息时代,数据量将是新的发达程度指标,几乎所有行业竞争本质上都是数据的竞争。支撑数据增长的背后,是一代又一代不断演化的数据库引擎,在真格基金的投资工作中,不断的开始有中国团队尝试挑战数据库领域海外的垄断地位,打造新一代的数据库引擎。业余时间,对整个数据库发展史做了个简单的总结。
整个数据库大致经历了四个发展阶段。
第一阶段:非关系型数据库
在现代意义的数据库出来之前(20 世纪 60 年代),文件系统(File system)可以说是最早的数据库,程序员们读取文本文件,并通过代码提取文件中的关键数据,在脑海中尝试构造数据与数据之间的关系。当年能流行起来的编程语言,往往都有很强的文件和数据处理能力(比如 Perl 语言)。随着数据量的增长,数据维度的多元化,以及对于数据可信和数据安全的要求不断提升,简单的将数据存储在 txt 文本中,成为极其具有挑战的事情。
随后,人们开始提出数据库管理系统(Database Management System, DBMS)的概念。数据库的演进抽象来看是人们对 数据结构 和 数据关系 这两个维度展开的思考和优化。
层次模型和网络模型(1960)
第一阶段的数据库模型(Database model) 是层次模型(Hierarchical Databases)。
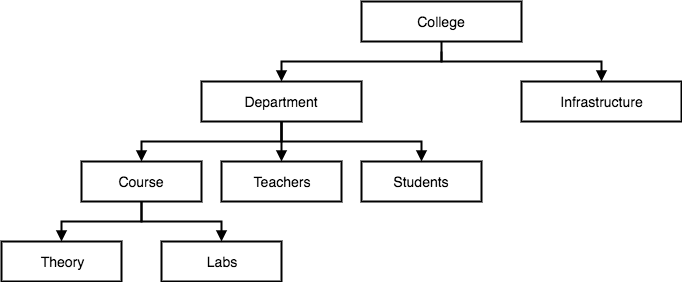
图 1:一个表达学校结构的层次模型数据库
层次模型是最早的数据库模型。随着早期 IBM 大型机逐渐推广开来。这个模型相对于文本文件管理数据,是个巨大的提升,但也有很多问题。
问题:
尽管能比较好的表达 一对一 ( one to one) 结构,但在 多对多(many to many) 结构上难以表达
- 如:图中能较好的表达一个系有多个老师,但很难表达一个老师可能属于多个系。
层次结构不够灵活
- 如:添加一个新的数据库关系有可能对整个数据库结构带来巨大变化,以至于在真正的开发中带来巨大的工作量
- 查询数据需要脑海中随时有最新的结构图,且需要遍历树状结构做推导
而后在层次模型的基础之上,人们提出了优化方案,即:网络模型(Network Model)。
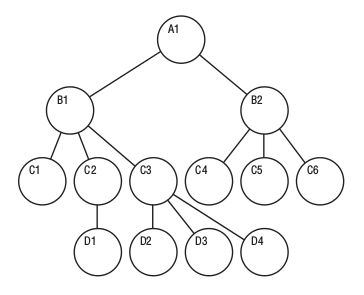
图 2:网状模型的数据库
网络模型是关系型数据库出来之前最为流行的数据库模型。很好的解决了数据的多对多的问题。但依然存在以下问题:
问题:
- 难以从代码层面实现和维护
- 查询数据需要脑海中随时有最新的结构图
第二阶段:关系型数据库
模型初期(1970)
关系模型( Relational Model) 是相对网络模型的巨大飞跃。在网络模型中,不同类型的数据总是会依赖另一类数据,如图 1 中,Teachers 从属于 Departments,这是层次模型和网络模型在真实设计和开发中痛苦的根源(因为你总是要在脑海中记录当前的网络结构,想象一下一个拥有几千张表的复杂系统)
关系模型一大创新就是拆掉了表和表之间的链接,将关系只存储在当前表中的某一个字段中(fields),从而实现不同的表之间的相对独立。如下表:当你只看 Table2 的时候,你就知道 Product_code 会指向一个 产品的具体细节,Table2 和 Table1 在保持相对独立的同时,又自然而然的连接了起来。
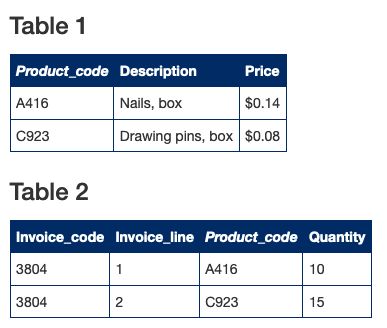
图 3:关系型数据库
Table2 中的 Product_code 列指向了 Table1 中对应的数据,从而建立 Table2 和 Table1 的关系
1970年,当 E.F.Codd 开发出这个模型时,人们认为是难以实现的,正如上面的例子一般,当你检索 Table2 时,遇到 Product_code 列,就需要再去 Table1 遍历一遍。受限于当时的硬件条件,这种检索方法总是会让机器难以负载。但很快,大家质疑的问题,在摩尔定律加持下,已经不再是问题。大家如今所听说的 IBM DB2, Ingres, Sybase, Oracle, Informix, MySQL 就是诞生在这个时代。
至此数据库领域诞生了一个大的分类:联机事务处理 OLTP(on-line transaction processing),代指一类专门用于日常事务的数据库,如银行交易用的增删改查数据库。后面还会提到另一类数据库,专门用于从大量数据中发现决策的辅助数据库 On-Line Analytical Processing – OLAP(联机分析处理)数据库。
数据仓库(1980s)
随着关系型数据库的发展,不同业务场景数据化,人们开始有了汇集不同业务场景数据,并尝试进行数据分析并辅助业务决策的想法(Decision Support System)。在此需求之上,诞生了数据仓库( Data warehouse)的概念。
如下图:一个企业往往把不同的业务场景数据存在不同的数据库中,在没有成熟的数据仓库产品之前,数据分析师往往需要自己做大量的前期准备工作来汇集自己所需的数据。而数据仓库本质上就是解决数据分析和挖掘的业务场景。

图 4:数据仓库
解释:ETL 是 Extract(提取),Transform(转换),Load(加载)的缩写。因为数据在不同的数据库或者系统中,可能存在格式不统一,单位不统一等等情况。需要做一次数据的预处理。数据仓库是一个面向主题的、集成的、非易失的、随时间变化的用来支持管理人员决策数据集合。
OLAP(联机分析处理)
1980 年代有了数据仓库的概念和实现后,人们尝试在此基础上做数据分析。但分析的过程出现一些新的问题。最明显的是效率问题。因为之前的关系型数据库并不是为数据分析而打造。数据分析师想要的是一个支持多维的数据视图和多维数据操作的引擎。
如下面的数据魔方一般,相比于上面提到的关系型数据库中的二维数据展示和二维数据操作而言。OLAP 数据库对多个维度的数据可以快速的组建和操作。
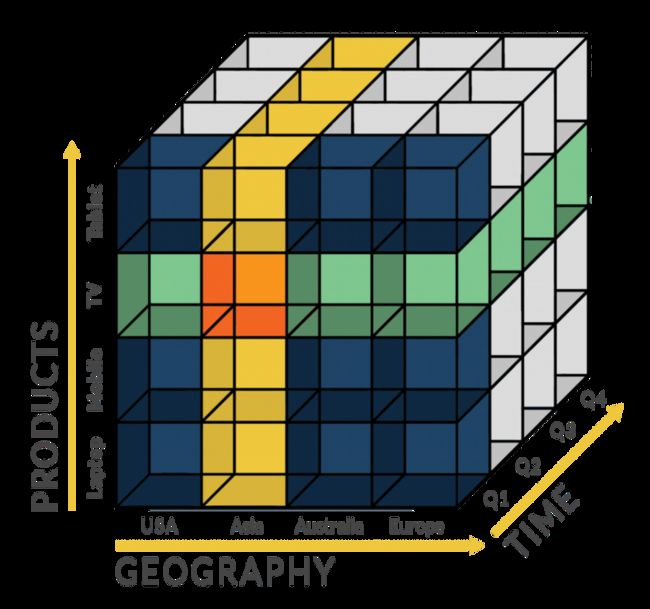
数据魔方
将多个维度的数据组织和展示
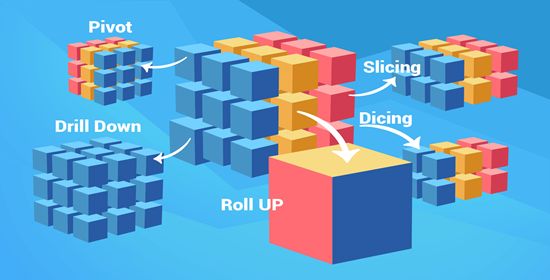
数据魔方的多种操作
1993 年,关系型数据库创始人Edgar F. Codd提出联机分析处理(OLAP)的概念。本质上是多维数据库和多维分析能力的概念。目标是满足决策支持或多维环境特定的查询和报表需求。
第三阶段:NoSQL
时间继续推进,互联网时代到来以后,数据量的暴增给关系型数据库也带来的新的挑战。最为明显的挑战有以下两点:
挑战一:数据列的扩展成本巨高
关系型数据库因为提前定义了 Table 的字段(Fields),当数据库已经拥有数以亿计条的数据之后,业务场景需要一列新的数据,你惊讶的发现,在关系型数据库的规则限制下,你必须要同时操作这数以亿计的数据爱完成新的一列的添加(不然数据库会有报错出现),对生产环境的服务器性能挑战极大。
可以想象一下 Facebook,Twitter, Weibo 这样的社交网站,每天字段都在不断的变化,来添加各种新的功能。
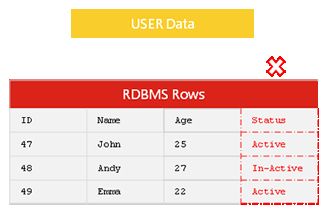
比如需要添加 status 列,你必须要在某一时刻同时为数以亿计的行,添加 Active 或者 In-Active 内容,否则数据库会无法满足合规约束
挑战二:数据库性能的挑战
业务规模不断上升之后,关系型数据库的性能问题开始浮出水面,虽然数据库供应商都提出了各种解决方案,但底层关系绑定式的设计依然是性能天花板的根本原因。开发人员开始尝试分库、分表、加缓存等极限操作来挤出性能。
在此挑战之上,人们提出了新的数据库模型 – NoSQL。
针对扩展数据列的问题,NoSQL 提出了新的数据存储格式,去掉了关系模型的关系性。数据之间无关联,这样就换回了架构上的扩展性。
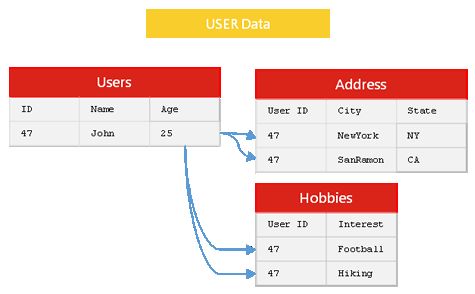

新的数据结构,将相关性数据都放在一起
NoSQL 更底层的创新源自于天生为集群可扩展场景所打造。
而在 NoSQL 理论基础之上,根据企业应用场景又拓展出了四大类型的数据库:
- 文档型数据库(Document-Oriented):如大名鼎鼎的 MongoDB、CouchDB。文档泛指一种数据的存储结构,如 XML、JSON、JSONB 等。
- 键值数据库(Key-Value Database) :大家所听说的 Redis、Memcached、Riak 都是键值对数据库
- 列式存储数据库(Column-Family):如 Cassandra、HBase
- 图数据库(Graph-oriented):如 Neo4j、OrientDB 等。聚焦在数据间关系链的数据组织方式。
随着企业数据的不断变大,对数据处理能力也提出了新的要求。日常所听到的大数据(Big Data)一词,代表一个庞大的技术体系结构。包括了数据的采集,整理,计算,存储,分析等环节。数据库只是其中一环。如下图,饿了么2017 年大数据架构,文中所提到的数据库,基本上只代表了图中存储环节。大家日常所听到的 Hadoop、Kafka、Hive、Spark、Materialize等都是大数据引擎,千万不要搞混了。
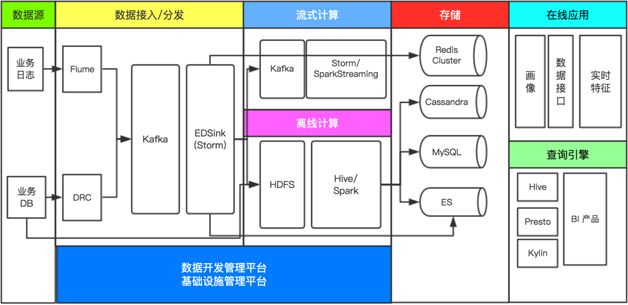
数据库只是大数据概念中的一部分
第四阶段:
随着云时代的到来,基于云环境所打造的云原生数据库不断地开始占了数据库市场份额。
云原生数据库和托管/自建数据库最大的区别就是:云原生数据库是面向独立资源的云化,其CPU、内存、存储等均可实现独立的弹性,利用大型云厂商的海量资源池,最大化其资源利用率,降低成本,同时支持独立扩展特定资源,满足多种用户不断变化的业务需求,实现完全的Serverless; 而托管数据库还是局限于传统的服务器架构,各项资源等比率的限制在一个范围内,其弹性范围,资源利用率都受到较大的限制,无法充分利用云的红利。
基于云原生数据库技术,未来创业团队无需花费巨大精力来应对海量数据来袭,只需聚焦在业务即可。
云原生数据库的代表如:阿里云的 PolarDB、腾讯云的 CynosDB、华为云的 TaurusDB、亚马逊云的 Aurora。
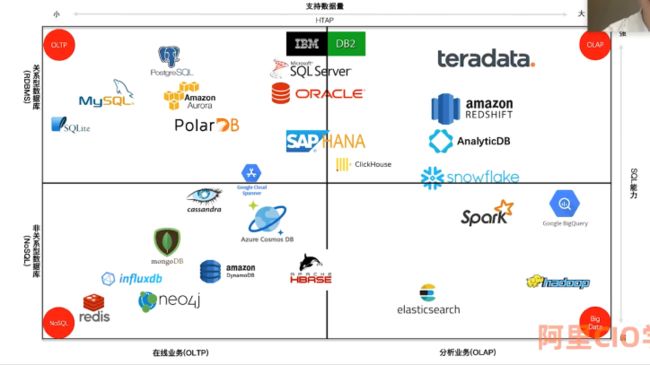
最后,以阿里 CIO 学院的一个数据库分布图结束这篇文章,图示中的数据库产品和分布图很好的代表了当前数据库产业的格局。
附录:
数据库领域里有一个不得不提的 CAP 理论,感兴趣的可以阅读阮一峰的 Blog。
CAP 理论
在近代数据库领域,有一个 CAP 理论,CAP 分别代表:
- Consistency(数据一致性)
- Availability(数据可用性)
- Partition tolerance(分区容错)
CAP 理论简单理解就是分布式数据库不可能同时做到一致性、可用性和分区容错这三个指标。更具体的解释可以参考阮一峰的 Blog,写的非常棒,这里就不展开。
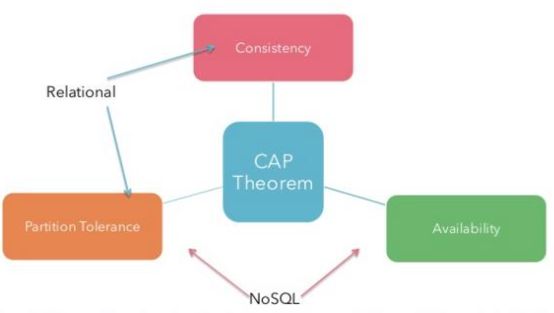
关系型数据库库选择了一致性和分区容错,而 NoSQL 为了适应业务需要,选择了分区容错和可用性。