好像还挺好玩的GAN重制版1——Keras搭建DCGAN平台利用深度卷积神经网络实现图片生成
好像还挺好玩的GAN重制版1——Keras搭建DCGAN平台利用深度卷积神经网络实现图片生成
- 学习前言
- 源码下载地址
- 什么是DCGAN
- 生成网络的构建
- 判断网络的构建
- 训练思路
-
- 判别器的训练
- 生成器的训练
- 利用DCGAN生成图片
学习前言
我又死了我又死了我又死了!

源码下载地址
https://github.com/bubbliiiing/dcgan-keras
喜欢的可以点个star噢。
什么是DCGAN
DCGAN的全称是Deep Convolutional Generative Adversarial Networks,翻译为深度卷积对抗生成网络。
它是由Alec Radford在论文Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks中提出的。
实际上它就是在GAN的基础上增加深度卷积网络结构。
论文中给出的DCGAN结构如图所示。其使用反卷积将特征层的高宽不断扩大,整体结构看起来像普通神经网络的逆过程。

生成网络的构建
对于生成网络来讲,它的目的是生成假图片,它的输入是正态分布随机数。输出是假图片。
在GAN当中,我们将这个正态分布随机数长度定义为100,在经过处理后,我们会得到一个(64,64,3)的假图片。
在处理过程中,我们会使用到反卷积,反卷积的概念是相对于正常卷积的,在正常卷积下,我们的特征层的高宽会不断被压缩;在反卷积下,我们的特征层的高宽会不断变大。

在DCGAN的生成网络中,我们首先利用一个全连接,将输入长条全连接到16,384(4x4x1024)这样一个长度上,这样我们才可以对这个全连接的结果进行reshape,使它变成(4,4,1024)的特征层。
在获得这个特征层之后,我们就可以利用反卷积进行上采样了。
在每次反卷积后,特征层的高和宽会变为原来的两倍,在四次反卷积后,我们特征层的shape变化是这样的:
( 4 , 4 , 1024 ) − > ( 8 , 8 , 512 ) − > ( 16 , 16 , 256 ) − > ( 32 , 32 , 128 ) − > ( 64 , 64 , 3 ) 。 (4,4,1024)->(8,8,512)->(16,16,256)->(32,32,128)->(64,64,3)。 (4,4,1024)−>(8,8,512)−>(16,16,256)−>(32,32,128)−>(64,64,3)。
此时我们再进行一次tanh激活函数,我们就可以获得一张假图片了。
实现代码如下:
def conv_out_size_same(size, stride):
return int(math.ceil(float(size) / float(stride)))
def generator(d=128, image_shape=[64,64,3]):
conv_options = {
'kernel_initializer': initializers.normal(mean=0.0, stddev=0.02),
}
batchnor_options = {
'gamma_initializer' : initializers.normal(mean=0.1, stddev=0.02),
'beta_initializer' : initializers.constant(0),
'momentum' : 0.9
}
inputs = layers.Input([100,])
s_h, s_w = image_shape[0], image_shape[1]
s_h2, s_w2 = conv_out_size_same(s_h, 2), conv_out_size_same(s_w, 2)
s_h4, s_w4 = conv_out_size_same(s_h2, 2), conv_out_size_same(s_w2, 2)
s_h8, s_w8 = conv_out_size_same(s_h4, 2), conv_out_size_same(s_w4, 2)
s_h16, s_w16 = conv_out_size_same(s_h8, 2), conv_out_size_same(s_w8, 2)
x = layers.Dense(s_h16*s_w16*d*8, **conv_options)(inputs)
x = layers.Reshape([s_h16,s_w16,d*8])(x)
x = layers.BatchNormalization(**batchnor_options)(x)
x = layers.Activation("relu")(x)
x = layers.Conv2DTranspose(filters=d*4, kernel_size=4, strides=2, padding="same", **conv_options)(x)
x = layers.BatchNormalization(**batchnor_options)(x)
x = layers.Activation("relu")(x)
x = layers.Conv2DTranspose(filters=d*2, kernel_size=4, strides=2, padding="same", **conv_options)(x)
x = layers.BatchNormalization(**batchnor_options)(x)
x = layers.Activation("relu")(x)
x = layers.Conv2DTranspose(filters=d, kernel_size=4, strides=2, padding="same", **conv_options)(x)
x = layers.BatchNormalization(**batchnor_options)(x)
x = layers.Activation("relu")(x)
x = layers.Conv2DTranspose(filters=3, kernel_size=4, strides=2, padding="same", **conv_options)(x)
x = layers.Activation("tanh")(x)
model = Model(inputs, x)
return model
判断网络的构建
对于生成网络来讲,它的目的是生成假图片,它的输入是正态分布随机数。输出是假图片。
对于判断网络来讲,它的目的是判断输入图片的真假,它的输入是图片,输出是判断结果。
判断结果处于0-1之间,利用接近1代表判断为真图片,接近0代表判断为假图片。
判断网络的构建和普通卷积网络差距不大,都是不断的卷积对图片进行下采用,在多次卷积后,最终接一次全连接判断结果。
实现代码如下:
def discriminator(d=128, image_shape=[64,64,3]):
conv_options = {
'kernel_initializer': initializers.normal(mean=0., stddev=0.02),
}
batchnor_options = {
'gamma_initializer' : initializers.normal(mean=0.1, stddev=0.02),
'beta_initializer' : initializers.constant(0),
'momentum' : 0.9
}
inputs = layers.Input(image_shape)
x = layers.Conv2D(filters=d, kernel_size=4, strides=2, padding="same", **conv_options)(inputs)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2D(filters=2*d, kernel_size=4, strides=2, padding="same", **conv_options)(x)
x = layers.BatchNormalization(**batchnor_options)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2D(filters=4*d, kernel_size=4, strides=2, padding="same", **conv_options)(x)
x = layers.BatchNormalization(**batchnor_options)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Conv2D(filters=8*d, kernel_size=4, strides=2, padding="same", **conv_options)(x)
x = layers.BatchNormalization(**batchnor_options)(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.3)(x)
x = layers.Dense(1, **conv_options)(x)
x = layers.Activation("sigmoid")(x)
model = Model(inputs, x)
return model
训练思路
DCGAN的训练可以分为生成器训练和判别器训练:
每一个step中一般先训练判别器,然后训练生成器。
判别器的训练
在训练判别器的时候我们希望判别器可以判断输入图片的真伪,因此我们的输入就是真图片、假图片和它们对应的标签。
因此判别器的训练步骤如下:
1、随机选取batch_size个真实的图片。
2、随机生成batch_size个N维向量,传入到Generator中生成batch_size个虚假图片。
3、真实图片的label为1,虚假图片的label为0,将真实图片和虚假图片当作训练集传入到Discriminator中进行训练。

生成器的训练
在训练生成器的时候我们希望生成器可以生成极为真实的假图片。因此我们在训练生成器需要知道判别器认为什么图片是真图片。
因此生成器的训练步骤如下:
1、随机生成batch_size个N维向量,传入到Generator中生成batch_size个虚假图片。
2、将虚假图片的Discriminator预测结果与1的对比作为loss对Generator进行训练(与1对比的意思是,让生成器根据判别器判别的结果进行训练)。

利用DCGAN生成图片
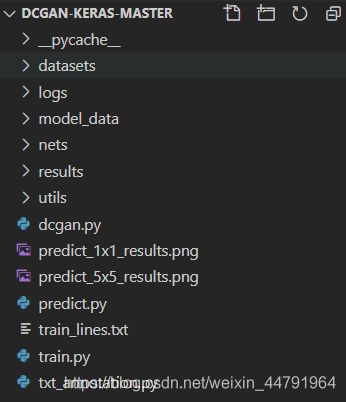
DCGAN的库整体结构如下:
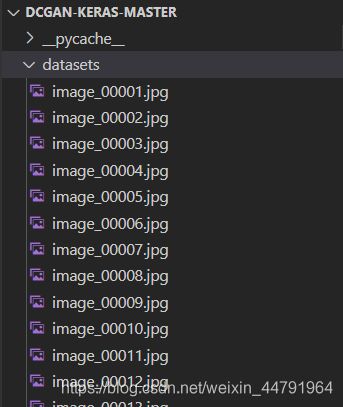
在训练前需要准备好数据集,数据集保存在datasets文件夹里面。
在完成数据集准备后,运行train.py即可开始训练。
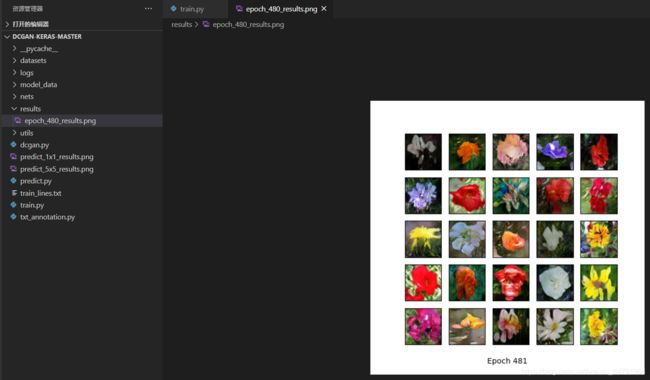
训练过程中,可在results文件夹内查看训练效果: