基于Keras+YOLOv3的口罩佩戴情况检测系统【超详细!!!保姆级教程】
目录
- 1. 开发环境
- 2. 制作数据集
- 3. 修改配置文件
- 4. 训练数据集
- 5. 检测效果
- 6. UI界面实现
- 7. 结束语
1. 开发环境
硬件环境(个人笔记本电脑)
- 处理器:Inter(R)Core(TM)i7-9750H CPU
- 内存:8.00GB
- 显卡:NVDIA GeForce GTX 1650
- 硬盘:可用空间300GB以上
软件环境
- win10 64位
- python3.7.0
- TensorFlow-GPU 1.13.1
- Keras2.2.4
- OpenCV4.2.0
- PyQt5
- 当然还有很多python的模块包,但是我这里记不清啦~如果有需要pip install就可以~
关于开发环境稍后我会专门写一篇博客详细介绍,帮助大家避雷。很多小白可能还没机会感受AI的快乐就被配置环境劝退了哈哈哈,想当初我也是踩了很多很多坑,说多了都是泪啊 ~
YOLOv3的原理不和大家讲了,毕竟不是一句两句话能说清的,对于初学者来说肯定有些难理解,不过没关系,大家一开始都是初学者,慢慢来别放弃,总有一天大家都能看懂原理 ~
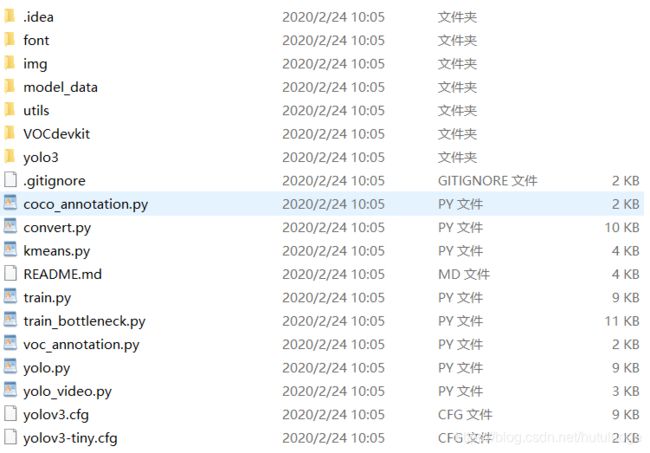
但是要和大家展示一下下载下来的yolov3文件夹结构,为了方便描述,博主就称它为根目录吧 ~
就是下图,有一个大概的印象,便于后面我们复现。这个文件夹我在评论区给到大家 ~~
2. 制作数据集
配置好环境后,我们要准备自己的人脸口罩数据集了!
要检测口罩佩戴情况,就要先获取一定数量的相关图片,放入设计好的神经网络中训练(本文是YOLOv3),这些相关图片就叫做数据集,啊当然不只是单纯的图片,我们还要对这些图片做一些处理,也就是本章内容。
笔者的数据集是从一位老前辈那里求来的,是一个非常完美非常OK的数据集,省的大家自己去爬虫了。
数据集包含6366张高质量图片,有戴口罩的人、不戴口罩的人、用手或其他物品遮挡脸的人等多种情况,确保样本的多样性和全面性。
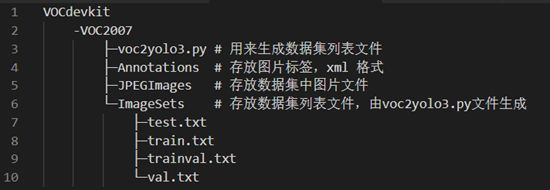
数据集文件夹VOCdevkit在根目录里,结构见下图。其中,
- JPEGImages文件夹存放收集到的原始图片,依次以1-6366命名;
- Annotations文件夹存放使用labelImg工具生成的含有所有目标位置和类别信息的图片标签,每个文件对应一张图片(具体怎么生成下面马上讲到);
- ImageSets文件夹存放数据集列表文件,通常为train.txt、test.txt等,分类并保存不同用途的图像(听不懂没关系下面都会讲到)。
- 制作图像的.xml文件
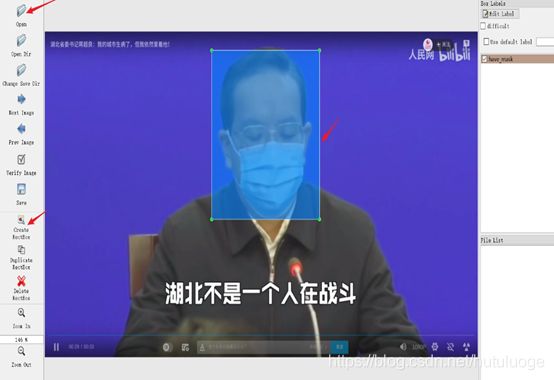
我们使用labelImg手动标注,如下图:选择界面左侧的“Open”打开图像后,点击“Create RectBox”画框,就可以画矩形框并标记(类别会在画好目标框后自动弹出以供选择)。
labelimg这个工具能够在一张图片中标注多个目标,非常方便。关于labelimg的详细使用方法在此。
不过我知道你们都懒得亲自动手做,所以我把我的数据集分享给你们。
将所有生成的标签文件放入Annotations文件夹中,便完成了数据集制作的第一步,每个图片和生成的xml文件是一一对应的。
- 将.xml文件转换成.txt文件
上一步制作出原始图像的.xml文件后,还需要将所有图像分类。
运行VOCdevkit->VOC2007下的voc2yolo3.py文件,记得检查一下其中的xmlfilepath和saveBasePath路径,xmlfilepath对应Annotations,saveBasePath对应ImageSets/Main
多说几句,下图是voc2yolo3.py中的主要代码,它的用途是:一般我们设训练验证集 : 训练集 = 1 : 9,训练验证集中10%用作验证集,90%用作测试集。
运行完voc2yolo3.py这个神奇的文件后,我们就得到了trainval.txt, test.txt, train.txt和val.txt这四个文件(在VOCdevkit\VOC2007\ImageSets\Main文件夹下),分类保存不同用途的图片名称。

- 将.jpg文件转换成.txt文件
完成训练集的划分之后,我们运行voc_annotation.py文件(文件位置在根目录)。这样一来,可以生成train.txt, val.txt和test.txt三个文件(也在根目录),分别保存着训练、验证和测试集的路径。
我随便打开一个比如train文件给大家瞅一眼,这些文本文档中每一行为一张图片的信息,依次是图片的路径、名称、尺寸和目标框的坐标及类别标签(0表示没口罩,1表示有口罩)。
如果一张图中有多个对象,则依次罗列各个对象的位置信息和类别。

还要再强调一下,路径问题是导致出错的主要原因,咱们大家每个人电脑的情况都不同,所以一定要仔细检查核对自己的路径哈 ~~
3. 修改配置文件
- 下载YOLOv3预训练权重——yolov3.weights.然后执行如下命令将darknet下的yolov3配置文件转换成keras适用的h5文件:

两行命令,其中上面一行是yolov3,下面一行是tiny轻量版yolov3。tiny yolo网络结构比yolo简单一些,训练得比较快,因为我笔记本配置一般,所以我就选择tiny版来进行训练的,效果也OK。 - 修改model_data里面yolo_anchors.txt和tiny_yolo_anchors.txt中的先验框的值,这里我们利用kmeans.py(在根目录下)来生成。
生成先验框的时候注意:打开kmeans.py翻到最下面第98行,
如果是标准版yolov3,则修改为cluster_number = 9,对应第 61 行 f = open(“yolo_anchors.txt”, ‘w’),
如果是轻量版yolov3,则修改为cluster_number = 6,对应第 61 行 f = open(“tiny_yolo_anchors.txt”, ‘w’)。 - 接着我们来到model_data文件夹,将里面的voc_classes.txt文件中的classes改成自己的classes。
这个要和voc_annotation.py文件第7行对应,比如我第7行是classes = [“face”, “face_mask”],那么我voc_classes.txt文件中就应该是face(此处省略回车换行)face_mask。
至此,我们的人脸口罩数据集和基本配置文件就已经准备完毕了,然后我们可以去睡觉了 ~ 其他的就听天命吧 ~
4. 训练数据集
啊睡觉之前还有最后一步:在根目录下新建一个logs文件夹,然后运行train.py,再然后就是漫长的训练过程,训练好的模型存放在logs下。
博主第一次训练时batchsize设置为2,大概训练了五六个小时,效果比较差,于是把batchsize调整到10又训练了大概一天吧(害比较久远了我也记不太清,反正就是训练了很久很久),最后得到的模型效果就比较好了。如果大家有什么提高模型精度和速度的方法也欢迎分享~
这次真的可以去睡觉/吃火锅/吃瓜/玩耍了!
5. 检测效果
耍完了睡饱了,电脑也训练好了,接下来就是见证奇迹的时刻,鸡不鸡冻?超级鸡冻的!
好了淡定一下,然后去logs文件夹下,把“trained_weights_final.h5”文件名复制一下,是的没错它就是我们最终训练出的最优的模型(笑
复制了之后打开根目录下yolo.py文件,把第23行model_path改为logs/trained_weights_final.h5
然后第24行如果你想用轻量版那就model_data/tiny_yolo_anchors.txt,标准版就model_data/yolo_anchors.txt
改好之后保存。
然后正式开始检测。敲键盘win+r,如下图
 输入cmd,点击确定,进入命令行
输入cmd,点击确定,进入命令行

用“cd”命令切换到根目录下,比如在我的电脑上,这套代码的位置是C:\Users\13262\Desktop\graduationProject\yolov3_keras_GUI\yolov3_keras_GUI,那就在命令行中输入“cd C:\Users\13262\Desktop\graduationProject\yolov3_keras_GUI\yolov3_keras_GUI”如下图
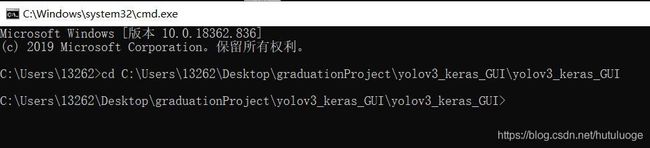
然后运行yolo_video.py程序,分为以下3种情况 :
- 如果想开启摄像头实时检测,则输入“python yolo_video.py --input",回车后程序启动,不附图了。
- 如果想上传本地图片检测,则输入"python yolo_video.py --image",回车后程序启动,如下图
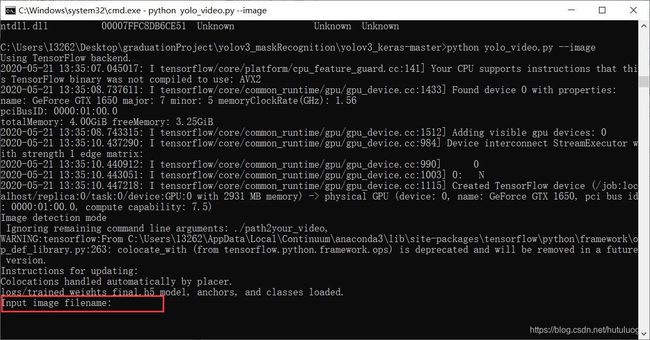
红框处输入图片路径和名称,如果图片在当前文件夹下(如我给的代码中图片保存在img文件夹下),则直接输入“.\img\XXX".
举个栗子: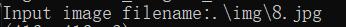 ,回车后变成这样
,回车后变成这样
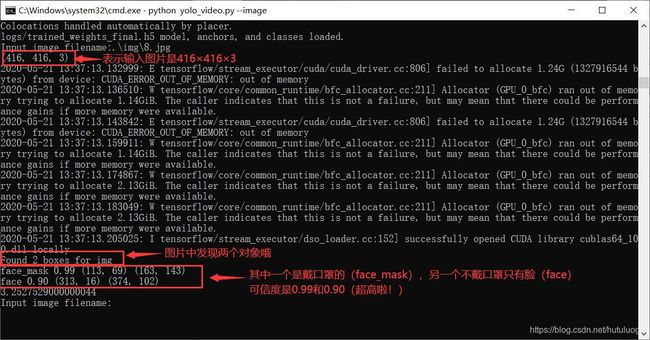
顺便弹出来图片,哈哈,大功告成了~

- 如果想上传本地视频检测,则先将yolo.py第174行vid = cv2.VideoCapture(0)改为
vid = cv2.VideoCapture(video_path),然后在命令行输入“python yolo_video.py --input xxx”,xxx表示上传的视频的路径和名称,回车后程序启动。 - 如果想上传本地视频检测并保存,那么除了第3点的步骤之外,还要在yolo.py第172行
def detect_video(yolo, video_path, output_path=""):中补充保存路径,如:output_path=“C:\Users\xxx\xxxxx”.
6. UI界面实现
模型训练好了,效果也看到了,接下来如果能集成一个UI界面就显得超酷了!
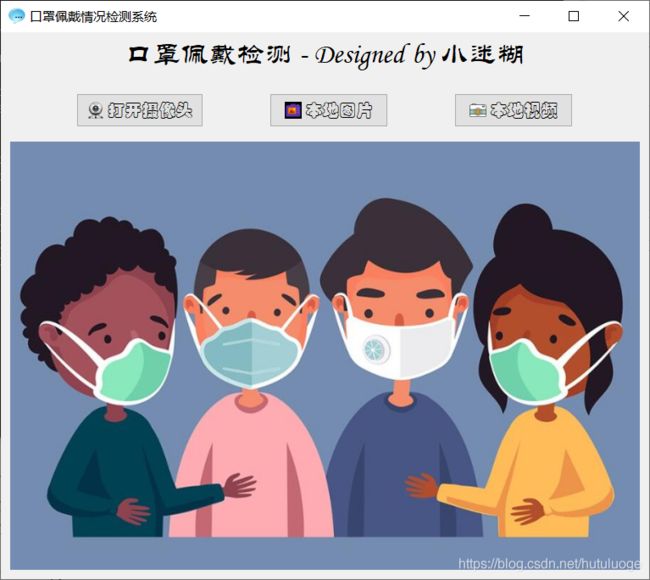
博主采用PyQt5进行设计,首先看一下最后的效果GIF图,运行后的界面如下,因为csdn不允许上传太大的图片,所以我把界面的三个功能分成三张图片上传
- 打开摄像头实时检测
2.上传本地图片检测
- 上传本地视频检测
7. 结束语
咳咳,我感觉自己讲的差不多了,最后祝福大家都能在基于深度学习的目标检测的道路上一路顺风 ~ 收获多多 ~
不过由于博主能力有限,上述步骤可能有些遗漏了细节的地方,希望大家热心指出 ~~
然后有什么问题大家可以留言或者私聊我,我们一起学习一起探讨一起进步 ~~
最后的最后,你们的点赞打赏和关注是博主最大的动力 ~ 大部分代码都免费分享给大家了,如果想要获取完整代码文件(包括我自己训练的权重,Gui界面代码等)欢迎私聊我 ,我会很快回复 ~~
创作和分享真是非常不易啦,希望大家多多理解和支持 ~~