Pytorch学习笔记三深度神经网络DNN
Geoffrey Hinton提出了一种名为“深度信念网络”的神经网络,可以使用“贪婪逐层预训练”的策略有效地进行神经网络的训练。紧接着,这种方法在其他神经网络的训练上也取得了成功。在诸如图像识别、语音识别等领域,这些新型的神经网络取得了令人瞩目的成绩,标志着机器学习一个全新时代的到来。这些新型的神经网络统称为深度学习,因为这些神经网络的模型可以有多个隐含层。深度学习主要包括深度神经网络DNN、卷积神经网络CNN、循环神经网络RNN、LSTM以及强化学习等。
深度学习之所以能够成功,是因为解决了神经网络的训练问题,使得包含多个隐含层的神经网络模型变得可能。神经网络训练问题的解决,包括了四个方面的因素:
(1)硬件设备特别是高性能GPU的进步,极大地提高了数值运算和矩阵运算的速度,神经网络的训练时间明显减少。
(2)大规模得到标注的数据集(如CIFAR10和ImageNet等)可以避免神经网络因为参数过多而得不到充分训练的问题。
(3)新型神经网络的提出,包括深度信念网络、受限玻尔兹曼机、卷积神经网络CNN、循环神经网络RNN、LSTM等。
(4)优化算法上的进步,包括ReLU激活函数、Mini-Batch梯度下降算法、新型优化器、正则化、Batch Normalization以及Dropout等。
本章主要介绍深度神经网络、梯度下降算法、优化器及正则化等优化训练技巧。
1.深度神经网络
如果神经网络中前后层的所有结点都是相连的,那么这种网络结构称为全连接层网络结构。深度神经网络是最基础的神经网络之一,最显著的特征是其隐含层由全连接层构成。全连接层是一个经典的神经网络结构层。如下图所示,该深度神经网络主要包括1个输入层,3个隐含层和1个输出层。前后层的所有结点都是两两相连的。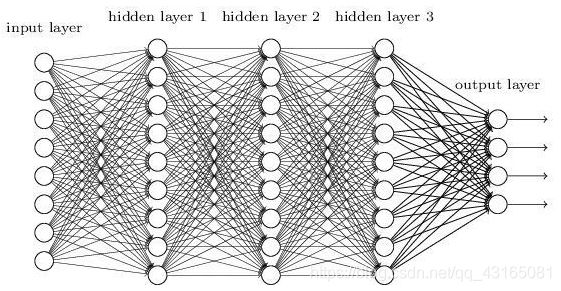
深度神经网络是传统神经网络的扩展,看起来就是深度神经网络包含多个隐含层。不过,这个看似小小的飞跃的背后,经历了长达20年的艰辛探索。1986年基于后向传播的神经网络取得成功,人们期待神经网络一飞冲天,结果很快发现神经网络只能在有限的领域有效,同时还有严苛的训练技巧。直到2006年,Hilton提出“贪婪逐层训练”的策略进行神经网络训练,在图像识别和语音识别领域率先突破,才取得了令人瞩目的成绩。后续研究发现,这种逐层训练的技巧不是完全必要的,在训练数据和计算资源充足的情况下,使用ReLU激活函数、Mini-Batch梯度下降算法、新型优化器、正则化、Batch Normalization及Dropout等算法,就能训练得到比较满意的深度学习模型。那么传统的神经网络为什么难以训练呢?
1.神经网络为何难以训练
神经网络在层数较多的网络模型训练的时候很容易出问题。除了计算资源不足和带标注的训练数据因素引起的问题外,还表现出两个重大的问题:梯度消失问题和梯度爆炸问题。这两个问题在模型的层数增加时会变得更加明显。例如在上图所示的深度神经网络中,如果存在梯度消失问题,根据反向传播算法原理,接近输出的隐含层3的权值更新相对正常;在反方向上,权值更新越来越不明显,以此类推,接近输入层的隐含层1的权值更新几乎消失,导致经过很多次的训练后,仍然接近初始化的权值,这样导致隐含层1相当于只对输入层做了一个同一映射,那么整个神经网络相当于不包括隐含层1的神经网络。
这个问题是如何产生的呢?在神经网络的训练中,以反向传播算法为例(假设神经网络中一个隐含层,且对每个神经元都有![]()
σ 表示Sigmoid激活函数),如下图所示:
根据链式法则可以推导如下:
而Sigmoid函数的公式为: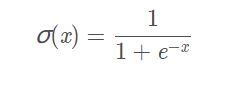
Sigmoid函数的导数σ′(x)的图像如下所示:
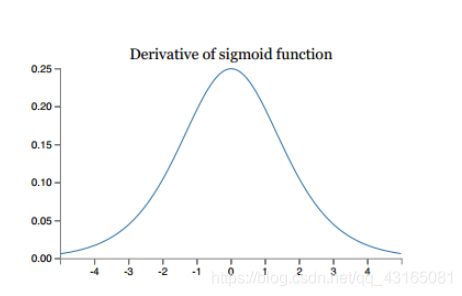

上面分析了神经网络训练中出现的两大问题:梯度消失和梯度爆炸。分析神经网络出现的问题,可以从分析损失函数错误平面开始。前面章节已经详细讨论了损失函数。从对损失函数错误平面的讨论引申出优化思路——梯度下降。同时,神经网络也出现泛化问题(欠拟合),深度学习模型在训练集上表现好,而在测试集上表现差。这时需要考虑新的思路,提高模型泛化的能力,需要正则化了。接下来就详细介绍梯度下降算法及其改进,还有模型正则化方法,它们是深度学习模型训练不可或缺的。
2.梯度下降
深度学习算法的训练都是以梯度下降算法及其改进算法为核心的。在深度学习中,训练的最终目的是使损失函数最小。如何使损失函数最小呢?从数学知识知道,对于连续可导函数,函数的最小值就是它导数为0的极值点,可以通过求导并令导数为0来找到极值点,或者可以采用逐步逼近的方法把极值点找出来。梯度,在数学上说是一个向量,指向函数值上升最快的方向。那么梯度的反方向就是函数值下降最快的方向。每次沿着梯度下降方向更新变量,就能找到函数最小值。对于深度学习的训练来说,同样采用梯度下降算法求解。
1.批量梯度下降
使用整个训练集的优化算法称为批量算法,因为它们会在一个大批量中同时处理所有样本。批量梯度下降算法每次学习都使用整个训练集,其优点在于每次更新都会朝着正确的方向进行,最终能保证收敛到全局最小值,这样收敛速度快,迭代次数少。但其缺点也很明显,就是每次梯度更新都要遍历整个数据集,需要大量的计算,内存消耗极多,特别是在数据集规模较大的时候,同时它还不利于分布式训练。
2.随机梯度下降
每次只使用单个样本的优化算法称为随机梯度下降。随机梯度下降算法每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的。随机梯度下降算法最大的缺点在于有时不会按照梯度下降最快的方向进行,因此可能带来扰动。对于局部极小值点,扰动使得梯度下降方向从当前的局部极小值点跳到另一个局部极小值点,最后难以收敛。由于扰动,收敛速度会变慢,往往需要更多的迭代次数才能收敛。
3.Mini-Batch梯度下降
大多数用于深度学习的梯度下降算法介于批量梯度下降和随机梯度下降之间,使用一个以上但又不是全部的训练样本,称为小批量梯度下降算法(Mini-Batch Gradient Descent)。
小批量梯度下降算法需要样本随机抽取。计算梯度需要样本满足相互独立的条件,而现实中数据自然排列,前后样本之间具有一定的关联性。因此需要把样本顺序随机打乱,以便满足样本独立性的要求。小批量梯度下降综合了批量梯度下降和随机梯度下降,在更新速度和迭代次数中间取得一个平衡,每次更新从训练集中随机选择m个样本(m 相对于批量梯度下降,Mini-Batch梯度下降降低了收敛扰动性,即降低了参数更新的方差,使得更新更加稳定。相对于批量梯度下降,其提高了每次学习的速度,并且不用担心内存瓶颈,可以利用矩阵运算提高计算效率。一般而言,每次更新随机选择50~256个样本进行学习,但是也要根据具体问题而选择,实践中可以进行多次试验,选择一个更新速度和迭代次数都较合适的样本数。Mini-Batch梯度下降可以保证收敛性,又可以保证更新速度快,常用于神经网络的训练中。 目前,Mini-Batch梯度下降是深度学习中的主流方法。在深度学习实践中,批量梯度下降和随机梯度下降可以看做Mini-Batch梯度下降的特例,批量梯度下降看作是Mini-Batch的size大小是整个数据集,随机梯度下降可以看做是Mini-Batch的size为1的情况。因此只有一种MIni-Batch的方法就够了。在PyTorch中同样如此。Mini-Batch方法是作为数据加载函数torch.utils.data.DataLoader的一个参数batch_size出现的,如果值为1就是随机梯度下降,如果值是数据集大小就是批量梯度下降,如果值在二者之间就是Mini-Batch梯度下降。特别指出,DataLoader只涉及数据集的划分,并不涉及梯度下降算法本身。 对梯度下降算法可以进行多方面的优化,可以加速梯度下降,可以改进学习率。在PyTorch中,有一个优化器Optimizer的概念,具体的包名叫做torch.optim。其中包含的具体的优化算法有SGD、Momentum、RMSProp、AdaGrad和Adam。其中,Momentum是加速梯度下降,其他三种方法是改进学习率。下面将逐一介绍这些优化算法的原理和使用。 在深度学习和PyTorch中,SGD就是Mini-Batch梯度下降算法,随机梯度下降方法及其变种是深度学习中应用最多的优化方法。SGD方法流程如下: 目前,最流行并且使用很高的优化算法包括SGD、具有动量的SGD、RMSProp、AdaDelta和Adam。如果你的数据是稀疏的,那么最好使用自适应学习率SGD优化方法(AdaGrad、AdaDelta、RMSProp和Adam),因为不需要在迭代过程中对学习率进行人工调整。RMSProp是AdaGrad的一种扩展,与AdaDelta类似,但是改进版的AdaDelta使用RMS取自动更新学习率,并且不需要设置初始学习率。Adam是在RMSProp基础上使用动量与偏差修正。RMSProp、AdaDelta与Adam在类似的情形下表现的差不多。得益于偏差修正,Adam略优于RMSProp,因为其在接近收敛时梯度变得更加稀疏。因此,Adam可能是目前最好的SGD优化方法。 有趣的是,最近很多论文都是使用原始的SGD梯度下降算法,并且使用简单的学习速率退火调整(无动量项)。现有的实验已经表明:SGD能够收敛于最小值点,但是相对于其他的SGD,它可能花费的时间更长,并且依赖于健壮的初始值及学习速率退火调整策略,并且很容易陷入局部极小值点,甚至鞍点。因此如果你在意收敛速度或者训练一个更深或者更复杂的网络,应该选择一个自适应学习速率的SGD。 为了使得学习过程无偏,应该在每次迭代中随机打乱训练集中的样本。在验证集上如果连续的多次迭代过程中损失函数不再显著地降低,那么应该提前结束训练。对梯度增加随机噪声会增加模型的健壮性,即使初始参数值选择的不好,并适合对特别深层次的网络进行训练。其原因在于增加随机噪声有更多的可能性跳过局部极值点并去寻找一个更好的局部极值点,这种可能性在深层次的网络中更常见 前面介绍的是深度学习的优化方法,是为了让训练过程更加高效。此外,我们要求模型不仅在训练集上表现良好,而且也要在测试集上表现良好。同时满足这两个条件的能力称为模型的泛化能力。如果一个模型在训练集表现良好,但是在测试集表现很差,则称为模型过拟合。如果一个模型在训练集和测试集都表现很差,则称为模型欠拟合。如下图所示: 在深度学习中,L2正则化又称为权值衰减。L2正则化通常的做法是只针对权重W,而不针对偏置b。对模型参数W的L2正则化被定义为: 通常来讲,正则化的神经网络要比未正则化的神经网络的泛化能力更好。 在PyTorch中,只实现有L2正则化,没有实现L1正则化。在torch.optim.SGD和其他torch.optim优化算法中,weight_decay就是L2正则化。 鉴于在某些情况下非标准化分布的层的特征可能是最优的,标准化每一层的输出特征反而会使得网络的表达能力变得不好,BN层加上了两个可学习的缩放参数和偏移参数以便使模型自适应地调整层的特征分布。 Batch Normalization是一种非常简单而又实用的加速收敛的技术。其作用有: 使得模型训练收敛速度更快 在测试时,训练求得的均值和方差将用来标准化测试数据。 参数含义: Dropout是指在深度神经网络的训练过程中,对于某些神经元,按照一定的概率将其暂时从网络中丢弃,这样可以让模型更加健壮,因为它不会太依赖某些局部的特征(因为局部特征有可能被丢弃)。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个小批量都是在训练不同的网络。 (1)建立一个维度和本层神经元相同的矩阵D 在PyTorch中,Dropout有专门的Dropout层,包括两个类: 在训练中,Dropout的输出需要乘以1/(1-p),这样训练和测试将满足同一分布。 torch.manual_seed(1) # 确定随机种子,保证结果可重复 LR = 0.01 x = torch.unsqueeze(torch.linspace(-1,1,1500),dim=1) plt.scatter(x.numpy(),y.numpy()) torch_dataset = Data.TensorDataset(x,y) class Net(torch.nn.Module): net_SGD = Net() nets = [net_SGD, net_Momentum, net_AdaGrad, net_RMSprop, net_Adam] opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR) optimizers = [opt_SGD, opt_Momentum, opt_AdaGrad, opt_RMSprop, opt_Adam] loss_func = torch.nn.MSELoss() for epoch in range(EPOCH): labels = [‘SGD’, ‘Momentum’, ‘AdaGrad’, ‘RMSprop’, ‘Adam’] plt.legend(loc=‘best’) 本节介绍如何使用PyTorch实现一个简单的深度神经网络(手写数字识别程序),对手写数字数据集MNIST进行学习和预测,预期可以达到98%左右的准确率。该神经网络由1个输入层、1个全连接层结构的隐含层和1个输出层构成。我们通过这个例子可以掌握设计深度神经网络的特征及参数的配置。 import torch torch.manual_seed(1) # 设置人工种子,保证结果可重复 #加载训练数据(可以手动下载数据放到./data目录) #训练集的shuffle必须为True,表示每次从60000训练样本中随机选择100个作为一个批次 class Net(nn.Module): net = Net(input_size,hidden_size,num_classes) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(net.parameters(),lr=learning_rate) for epoch in range(num_epochs): for images,labels in test_loader: print(‘Accuracy of the network on the 10000 test images: %d %%’ % (100*correct/total)) Accuracy of the network on the 10000 test images: 98 %
用法示例:
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
在函数torch.utils.data.DataLoader中,实现数据加载功能,根据Mini-Batch方法和采样机制,对数据集进行划分,并在数据集上提供单进程或多进程迭代器,各个参数的意义如下:
3.优化器
1.SGD

2.Momentum
SGD方法是常用的优化方法,但其收敛过程会很慢,Momentum方法可以加速收敛。Momentum方法顾名思义,类似物理上的动量。设想一下,从山顶滚下一个铁球,铁球在滚下山的过程中,速度越来越快,动量不断增加,加速冲向终点。基于动量的梯度下降算法是如何表现的呢?算法在更新模型参数时,对于那些当前的梯度方向与上一次梯度方向相同的参数进行加强,即这些方向上更快了;对于那些当前的梯度方向与上一次梯度方向不同的参数进行削减,即这些方向上减缓了。因此Momentum方法可以获得更快的收敛速度和减少扰动。使用了动量的SGD算法流程如下:
在PyTorch中,Momentum方法调用函数是torch.optim.SGD,注意SGD和Momentum方法都是调用同一个函数,靠设置参数momentum进行区分:
class torch.optim.SGD(params,lr=,momentum=0,dempening=0,weight_decay=0,nesterov=False)
参数含义:
3.AdaGrad
学习率是SGD的一个关键参数,但是它是比较难以设置的参数之一,因为它对神经网络模型有很大的影响。如何自适应地设置模型参数的学习率是深度学习的研究方向之一。AdaGrad算法,根据每个参数所有梯度历史平方和的平方根,成比例的缩放参数,能独立地适应调整所有模型参数的学习率。损失最大的参数相应地有一个快速下降的学习率,损失较小偏导的参数在学习率上的下降幅度相对较小。在参数空间中更为平缓的倾斜方向会取得更大的进步。AdaGrad算法具有一些令人满意的理论性质。然而,实践中发现,在训练神经网络时,从训练开始时积累的梯度平方会导致有效学习率过早和过量减小。AdaGrad只在某些深度学习模型上效果不错。AdaGrad算法流程如下:
在PyTorch中,AdaGrad方法调用函数torch.optim.Adagrad:
class torch.optim.Adagrad(params,lr=0.001,lr_decay=0,weight_decay=0)
参数含义:
4.RMSProp
AdaGrad在凸函数中能够快速收敛,但实际神经网络的损失函数难以满足这个条件。Hilton修改AdaGrad的计算梯度平方累加为对应的指数衰减平均,这就是RMSProp方法。AdaGrad根据平方梯度的整个历史收缩学习率,使得学习率过早和过快的衰减。RMSProp使用指数衰减平均以丢弃遥远过去的历史,可以避免学习率下降过快的问题。在实践中,RMSProp已被证明是一种有效且实用的深度神经网络优化算法。目前它是深度学习从业者经常采用的优化方法之一。RMSProp算法流程如下:
在PyTorch中,RMSProp方法调用函数torch.optim.RMSProp:
class torch.optim.RMSProp(params,lr=0.001,alpha=0.99,eps=1e-8,weight_decay=0,momentum=0,centered=False)
参数含义:
5.Adam
Adam是另一种学习率自适应的优化算法,被看作RMSProp方法和动量方法的结合。首先,在Adam中,动量直接并入了梯度一阶矩的估计。将动量加入RMSProp最直观的方法是将动量应用于收缩后的梯度。其次,Adam包括偏置修正,修正从原点初始化的一阶矩和二阶矩的估计。Adam方法的优点在于经过偏置校正后,每一次迭代学习率都有一个确定的范围,从而使得参数比较平稳。Adam方法通常被认为是优秀的优化方法。Adam算法流程如下:
在PyTorch中,Adam方法调用函数torch.optim.Adam:
class torch.optim.Adam(params,lr=0.001,betas=(0.9,0.99),eps=1e-8,weight_decay=0)
参数含义:
6.选择正确的优化算法
前面讨论了一系列算法,通过自适应每个模型参数的学习率以解决优化深度模型中的难题。此时,一个自然的问题是:应该选择哪种算法呢?遗憾的是,目前在这一点上没有达成共识。chaul et al. (2014)展示了许多优化算法在大量学习任务上极具价值的比较。结果表明,具有自适应学习率(以RMSProp和AdaDelta为代表)的算法族表现得相当健壮,性能差不多,但是没有哪个算法脱颖而出。4.正则化
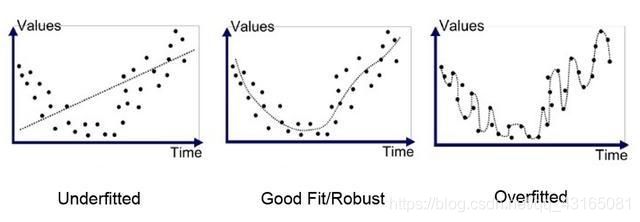
要在欠拟合和过拟合中间取得平衡,一个常用的方法是正则化(Regularization)。正则化的思想就是在目标函数中引入额外的信息来惩罚过大的权重参数。假设神经网络模型在训练过程中使用的目标函数是J(θ),那么在优化时不是直接优化J(θ),而是优化J(θ)+λR(W)其中λλ称为正则项系数,λR(W)称为正则项,λ∈[0,∞],λλ等于0表示不使用正则化,λλ越大表示正则化惩罚越大。需要说明的是,在深度学习中,参数包括每一层神经网络的权重W和偏置b通常只对权重做正则化惩罚而不对偏置做正则化惩罚。
1.参数规范惩罚
参数规范惩罚包括L2参数正则化和L1参数正则化。
(1)L2参数正则化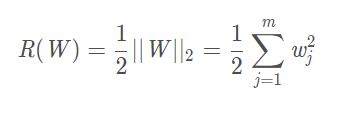
L2正则化能让权重W变小,这也是权值衰减的由来。过拟合的时候,在某些小区间内,函数值的变化比较剧烈,由于函数在某些小区间里的导数值比较大,而自变量可大可小,要使得导数比较大,这意味着权值W的值比较大。正则化约束参数的范数使其不能太大,可以在一定程度上减少过拟合的情况。
2)L1参数正则化
对模型参数W的L1正则化被定义为: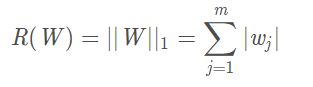
相比L2正则化,L1正则化会产生更稀疏的解。L1正则化的稀疏性已经广泛应用于特征选择机制。
2.Batch Normalization
在机器学习中,如果训练数据和测试数据都符合相同的状态分布,那么训练的模型能够较好地预测测试数据集上的数据;反之,训练的模型在测试数据集上的表现就会很差。在训练神经网络模型时,可以事先将特征去相关,并使得它们满足一个比较好的分布,比如标准正态分布,这样模型的第一层网络一般都会有一个比较好的输入特征。但是随着模型层次的加深,网络的非线性变换使得每一层的结果变得相关了,并且不再满足标准正态分布。更糟糕的是,可能这些隐含层的特征分布已经发生了偏移。为了解决这个问题,研究人员提出在层与层之间加入BN层(Batch Normalization,批量标准化层)。训练时,BN层会利用隐含层输出结果的均值与方差标准化每一层特征的分布,并且维护所有Mini-Batch数据的均值和方差,最后把样本的均值和方差的无偏估计量用于测试时使用。
模型隐含层输出特征分布更稳定,更利于模型的学习
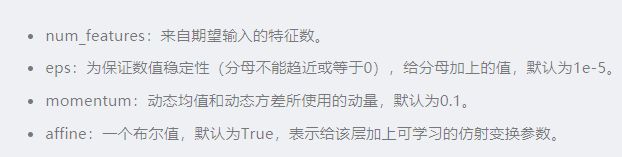
在PyTorch中,有封装好的Batch Normalization层,相应的类定义如下,可以直接使用:
class torch.nn.BatchNorm1d(num_features,eps=1e-5,momentum=0.1,affine=True)
class torch.nn.BatchNorm2d(num_features,eps=1e-5,momentum=0.1,affine=True)
class torch.nn.BatchNorm3d(num_features,eps=1e-5,momentum=0.1,affine=True)
对于小批量(Mini-Batch)的2d或3d输入进行批量标准化(Batch Normalization)操作,在每一个小批量数据中,计算输入各个维度的均值和标准差。gamma和beta是可学习的、大小为C的参数向量(C为输入大小)。在训练时,该层计算每次输入的均值和方差,并进行移动平均。移动平均默认的动量值为0.1。
使用示例:
带有可学习的参数
m = nn.BatchNorm1d(100)
不带有可学习的参数
m = nn.BatchNorm1d(100,affine=False)
input = autograd.Variable(torch.randn(20,100))
output = m(input)3.Dropout
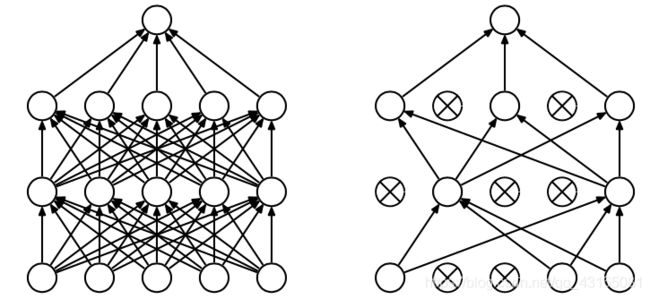
左图是一个标准的全连接的神经网络,右图是对左图应用了dropout的结果,会以一定的概率随机的丢弃一些神经元。在实践中通过把神经元的输出置为0来“关闭”神经元。具体步骤如下:
(2)根据概率(keep_prop)将D中的元素置为0,置为0的神经元表示该神经元失效,不参与后续计算
(3)将本层激活函数的输出与D相乘作为新的输出
(4)新的输出将除以keep_prop,以保证训练和测试满足同一分布,这样在测试中Dropout就可以参与计算了。
class torch.nn.Dropout(p=0.5,inplace=False)
class torch.nn.Dropout2d(p=0.5,inplace=False)
Dropout在训练中根据伯努利分布随机将输入张量中的部分元素(概率p)置为0。对于每次前向调用,被置为0的元素都是随机的。参数含义如下:
p:将元素置为0的概率,默认为0.5
inplace:若设置True,则对input进行直接处理。默认为False
其中,Dropout2d的输入来自conv2d模块。
示例如下:
import torch
torch.manual_seed(1)
m = torch.nn.Dropout(p=0.5)
input = torch.autograd.Variable(torch.randn(5,5))
output = m(input)
print(input)
print(output)
变量input是
tensor([[-1.5256, -0.7502, -0.6540, -1.6095, -0.1002],
[-0.6092, -0.9798, -1.6091, -0.7121, 1.1712],
[ 1.7674, -0.0954, 0.1394, -1.5785, -0.3206],
[-0.2993, 1.8793, 0.3357, 0.2753, 1.7163],
[-0.0561, 0.9107, -1.3924, 2.6891, -0.1110]])
变量output是:
tensor([[-3.0512, -0.0000, -0.0000, -0.0000, -0.0000],
[-1.2184, -1.9595, -0.0000, -1.4243, 0.0000],
[ 3.5349, -0.1907, 0.2787, -0.0000, -0.0000],
[-0.5987, 3.7587, 0.6715, 0.5507, 3.4326],
[-0.0000, 0.0000, -0.0000, 5.3782, -0.2220]])
7.优化器的使用示例
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
BATCH_SIZE = 20
EPOCH = 10生成数据
y = x.pow(3) + 0.1 * torch.normal(torch.zeros(*x.size()))数据画图
plt.show()把数据转换为torch需要的类型
loader = Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=2)定义模型
def init(self):
super(Net, self).init()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
不同的模型
net_Momentum = Net()
net_RMSprop = Net()
net_AdaGrad = Net()
net_Adam = Net()不同的优化器
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_AdaGrad = torch.optim.Adagrad(net_AdaGrad.parameters(), lr=LR)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
losses_his = [[], [], [], [], []]训练模型
print('Epoch: ', epoch)
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y) for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x)
loss = loss_func(output, b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.item())
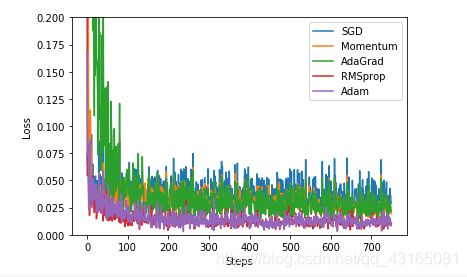
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.xlabel(‘Steps’)
plt.ylabel(‘Loss’)
plt.ylim((0, 0.2))
plt.show()
5.PyTorch示例:深度神经网络实现
1.配置库和配置参数
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.autograd import Variable
input_size = 784 # 图片为28*28=784个特征,输入层大小:m * 784
hidden_size = 500 # 隐含层大小:784 * 500
num_classes = 10 # 输出层大小:500 * 10
num_epochs = 5 # 训练5轮
batch_size = 100 # 每个批次100个样本,60000个训练样本要分成600个批次进行
learning_rate = 0.001 # 学习率0.0012.加载MNIST数据集
train_dataset = dsets.MNIST(root=’./data’,
train=True,
transform=transforms.ToTensor(),
download=True)
加载测试数据
test_dataset = dsets.MNIST(root=’./data’,
train=False,
transform=transforms.ToTensor()
)

3.数据的批处理
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
#测试集的shuffle要为False,即要保证10000个测试样本都只被预测一遍
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)4.创建DNN模型
def init(self,input_size,hidden_size,num_classes):
super(Net,self).init()
self.fc1 = nn.Linear(input_size,hidden_size) # 线性变换,即:m * 784 --> 784 * 500
self.relu = nn.ReLU() # 激活函数
self.fc2 = nn.Linear(hidden_size,num_classes) # 线性变换,即:784 * 500 --> 500 * 10def forward(self,x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
print(net)

使用交叉熵损失函数:CrossEntropyLoss
使用Adam优化器
训练5轮
# 每次从60000训练样本中随机选择100个作为一个批次,所以共重复600次
for i,(images,labels) in enumerate(train_loader):
images = Variable(images.view(-1,28*28)) # images大小:100 * 784
labels = Variable(labels) # labels大小:100 * 1
optimizer.zero_grad() # 梯度清零
outputs = net(images) # 输入网络,前向传播
loss = criterion(outputs,labels) # 计算损失
loss.backward() # 损失后向传播
optimizer.step() # 更新梯度
# 每隔100个批次打印一次信息
if (i+1)%100 == 0:
print(‘Epoch [%d/%d], Step[%d/%d], Loss: %.4f’ % (epoch+1,num_epochs,i+1,len(train_dataset)//batch_size,loss.item()))

correct = 0 # 记录预测正确的个数
total = 0 # 记录预测的总个数(一般就是测试集大小)测试集大小10000,每个批次大小100个,共100个批次
images = Variable(images.view(-1,28*28)) # images大小:100 * 784
outputs = net(images) # 使用训练好的网络进行计算
_,predicted = torch.max(outputs.data,1) # 数字识别共10分类,会得到10个概率值,以最大概率的类别为预测类别
total += labels.size(0) # 累加预测总个数
correct += (predicted==labels).sum() # 累加预测正确总个数打印全部测试集上的正确率