python爬虫:Ajax爬取B站视频标题、播放量、评论量
从B站找了一位up主徐大sao,主页如下。
链接: https://space.bilibili.com/390461123/video.
我们先来试一下直接用request获取url。
url='https://space.bilibili.com/390461123/video'
response = requests.get(url)
print(response.text)
输出如下。

如果我们打开浏览器开发者模式,会发现浏览器中显示的HTML和用request爬到的结果不一样。在浏览器中正常显示的页面数据,使用 requests 却没有得到结果。这是因为 requests 获取的都是原始 HTML 文档,而浏览器中的页面则是经过 JavaScript 数据处理后生成的结果。这些数据的来源有多种,可能是通过 Ajax 加载的,可能是包含在 HTML 文档中的,也可能是经过 JavaScript 和特定算法计算后生成的。这时我们需要分析网页后台向接口发送的 Ajax 请求,如果可以用 requests 来模拟 Ajax 请求,就可以成功抓取了。
Ajax
Ajax,全称为 Asynchronous JavaScript and XML,即异步的 JavaScript 和 XML。它不是一门编程语言,而是利用 JavaScript 在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
发送 Ajax 请求到网页更新的过程可以简单分为以下 3 步:
- 发送请求
- 解析内容
- 渲染网页
Ajax分析
真实的数据其实都是通过一次次 Ajax 请求得到的,如果想要抓取这些数据,我们需要知道这些请求到底是怎么发送的,发往哪里,发了哪些参数。
我们打开浏览器开发者模式,切换到 Network 面板,勾选上 「Preserve Log」并切换到 「XHR」选项卡,如图所示。

这里就是页面加载过程中浏览器与服务器之间发送请求和接收响应的所有记录。
切换到第2页,看一下页面的变化。

多了一条数据,即Ajax 请求,叫作 xhr。用鼠标点击这个请求,可以查看这个请求的详细信息。

随后我们点击 Preview,即可看到响应的内容,它是 JSON 格式的。这里 Chrome 为我们自动做了解析,点击箭头即可展开和收起相应内容。
我们可以观察到,返回结果是页面的信息,包括视频标题、简介、播放量等,这也是用来渲染个人主页所使用的数据。JavaScript 接收到这些数据之后,再执行相应的渲染方法,整个页面就渲染出来了。

页面逻辑
我们首先分析页面数据加载的逻辑。分别点击3,4,5页,这时候可以看到页面上的数据发生了变化,同时在开发者工具下方会监听到几个 Ajax 请求。

我们点击第4页的Ajax请求查看详情,观察其请求的 URL、参数以及响应内容是怎样的。
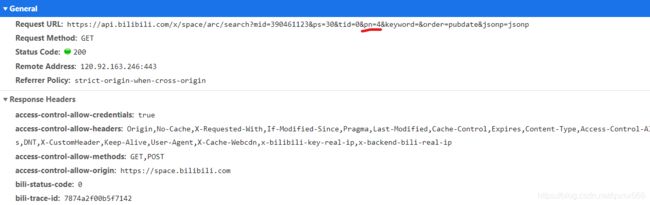
观察到其 Ajax 接口请求的 URL 地址为:https://api.bilibili.com/x/space/arc/search?mid=390461123&ps=30&tid=0&pn=4&keyword=&order=pubdate&jsonp=jsonp. 这里有1个参数pn,其值为 4。
通过观察多个 Ajax 接口的参数,我们可以发现这么一个规律:pn 的值即为当前页数。
接着我们再观察下响应的数据,切换到 Preview 选项卡。

可以看到结果是一些 JSON 数据,它有一个 vlist 字段,这是一个列表,列表的每一个元素都是一个字典。观察一下字典的内容,发现我们可以看到对应的视频数据的字段了,如 title、play、comment,对比下浏览器中的真实数据,各个内容是完全一致的,而且这个数据已经非常结构化了,完全就是我们想要爬取的数据。这样的话,我们只需要把所有页面的 Ajax 接口构造出来,那么所有的列表页数据我们都可以轻松获取到了。
代码实现
首先导入库,定义 INDEX_URL,这里把 pn 预留出来变成占位符,可以动态传入参数构造成一个完整的列表页 URL。。
import requests
import pandas as pd
INDEX_URL = 'https://api.bilibili.com/x/space/arc/search?mid=390461123&ps=30&tid=0&pn={page}&keyword=&order=pubdate&jsonp=jsonp'
定义一个通用的爬取方法。
def scrape_api(url):
response = requests.get(url)
return response.json()
这个方法专门用来处理 JSON 接口,最后的 response 调用的是 json 方法,它可以解析响应的内容并将其转化成 JSON 字符串。
在这个基础之上,我们定义一个爬取每页的方法。
def scrape_index(page):
url = INDEX_URL.format(page=page)
return scrape_api(url)
这里我们构造了一个URL,并把页数page传进去。构造好 URL 之后,直接调用 scrape_api 方法并返回结果即可。由于这时爬取到的数据已经是 JSON 类型了,爬到的数据就是我们想要的结构化数据,因此解析这一步这里我们就可以直接省略。
提出JSON中的信息,生成dataframe。
TOTAL_PAGE = 21
data = []
for page in range(1, TOTAL_PAGE + 1):
index_data = scrape_index(page)
allvideos = index_data.get('data')
videolist = allvideos.get('list').get('vlist')
for item in videolist:
title = item.get('title')
play = item.get('play')
comment = item.get('comment')
data.append((title, play, comment))
df = pd.DataFrame(data,columns=['title', 'play', 'comment'])
df

到这里就完成了。其实我原本还想提取每个视频的发布时间,很奇怪的是在vlist中并没有发现这个元素,那它是从哪儿来的呢。
参考:https://kaiwu.lagou.com/course/courseInfo.htm?courseId=46#/detail/pc?id=1674.