python爬虫实战(九) B站热门视频信息爬取(复杂版)| scrapy+selenium爬取B站生活区热门视频信息
在爬取动态网页时,一般尽量先找相应网页的API接口。但当接口不好找(或者接口的URL中含有加密参数)时,这时候就需要selenium来帮忙了。但由于selenium爬取速度比较慢,此时结合scrapy就能极大地提高爬取速度。今天,就来分享下scrapy+selenium爬取B站生活区热门视频信息~

本次爬取的核心关键词:动态页面加载+二级页面爬取
目录
-
-
-
- 一、scrapy基本介绍
- 二、爬虫分析
- 三、各部分代码
-
-
一、scrapy基本介绍
scrapy的五大核心部件:spiders、engine、scheduler、downloader、pipline
scrapy基本工作流程如下图所示
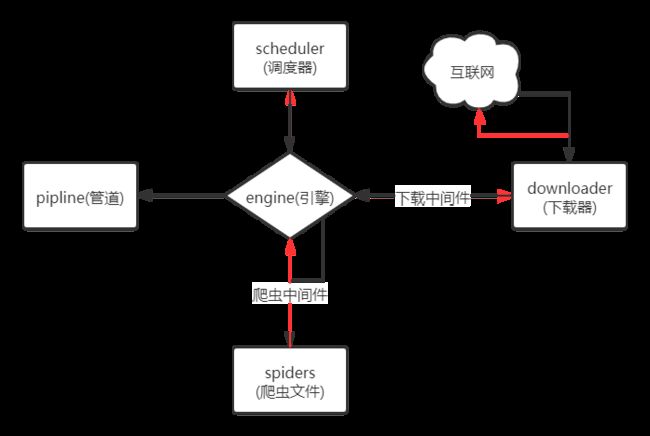
- 首先spiders将需要爬取的URL地址封装为requests对象,发送给engine(红色箭头所示)
- 引擎收到后将其交给调度器处理。调度器内部有两个部件:过滤器和队列。顾名思义,过滤器先将重复的requests对象过滤后,放入队列,再将其交给引擎。(黑色箭头所示)
- 此时,引擎再将去重后的requests对象交给下载器,中间会经过下载中间件(添加用户代理、IP等都是在这里进行的)。下载器收到后会向互联网发送请求,然后返回响应给下载器,再由下载器交还给引擎
- 引擎将其响应response交给爬虫文件spiders。spiders中的parse函数将会对其响应进行解析提取数据,获取进一步需要爬取的URL(例如二级页面的URL)。
- spiders再将其数据和URL交给引擎,引擎将数据传给pipline进行持久化存储;而需要进一步爬取的URL再次交给调度器存放,以此重复上述过程。
通过这样梳理流程,我们就知道这五个部件各自的作用:
- spiders:提取数据及URL
- scheduler:存放requests对象
- downloader:向互联网发送请求,并返回响应
- engine:数据流处理、触发事务(方法属性调用)(感觉像个交警,处理来自四面八方的事务)
- pipline:对提取的数据进行预处理,并可进行存储
注意的点:
- requests对象是一个类,里面有一些常用的属性,例如url地址、headers、cookie、proxy等
- 整个过程中,下载器是异步请求数据的!
- scrapy只能爬取静态网页!也就是下载器请求网页返回的响应是没有经过Ajax渲染的!
个人感觉scrapy在处理多级页面的时候非常方便,只需要通过回调函数callback直接即可将响应传给下一级页面处理的函数!(不需要像selenium那样只有点开二级页面的链接才能获取响应)
二、爬虫分析
-
想法来源:代码小白也能学会的爬虫软件——Webscraper基本介绍. 当时只是爬取了热门视频封面的一些信息,但关于视频的三连信息、发布时间等这些只能点开每个视频才能获取。如果单一的用selenium去爬,速度还是挺让人捉急的,所以就想和最近学的scrapy结合一下爬取啦~
-
B站生活区组成:搞笑、绘画、日常、运动、动物圈、汽车、手工、其他
-
爬取内容:热门视频的名称、上传的UP主、播放量、发布时间、弹幕数、点赞数、收藏数
以搞笑区热门视频为例,如下图所示(需要爬取的部分已用红框框出):
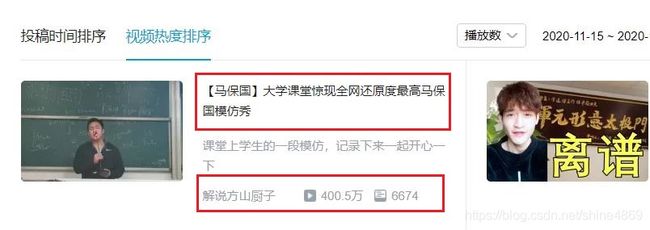
点开第一个视频后,需要爬取的信息如下:


一开始想法是这样的:通过xpath获取首页各个视频的URL,然后利用scrapy中的callback交给自定义的二级页面处理函数就可以啦~想法是挺美好的,但是打开查看首页的源码才发现:各个视频信息是要JS加载的!如下图所示:
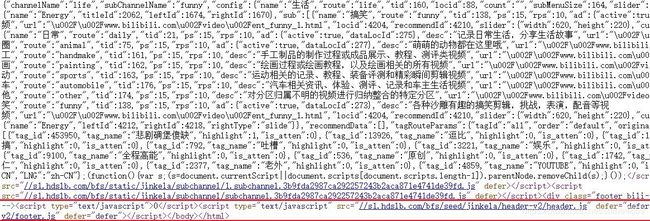
这就需要在scrapy通过下载中间件修改响应对象,以selenium去请求网页,返回动态加载的response信息即可。需要注意的是,虽然一级页面需要动态加载,但点开视频后的二级页面是可以直接拿到我们需要的信息!如下图所示(红框处则是视频的三连信息):

这样我们在写代码的时候,二级页面就无需动态请求了,在一定程度上也能加快爬取的速度。
- URL简单分析



注意:图1和图2是搞笑区的第1页和第2页的URL,不难看出,翻页只需要改变红框处的数字即可。图3是日常区的第1页URL,易知只需改变对应模块的英文即可实现多个模块爬取。
三、各部分代码
每个模块爬取前100页的视频数据
spiders
import scrapy
from selenium import webdriver
from spider_bilibili.items import SpiderBilibiliItem
from copy import deepcopy
import os
os.chdir('C:/users/dell/desktop')
class BilibiliSpider(scrapy.Spider):
name = 'bilibili'
allowed_domains = ['bilibili.com']
start_urls = [
"https://www.bilibili.com/v/life/funny/#/all/click/0/{}/2020-11-13,2020-11-20".format(page) for page in range(1,100)]+\
["https://www.bilibili.com/v/life/painting/#/all/click/0/{}/2020-11-13,2020-11-20".format(page) for page in range(1,100)]+ \
["https://www.bilibili.com/v/life/daily/#/all/click/0/{}/2020-11-13,2020-11-20".format(page) for page in range(1, 100)]+\
["https://www.bilibili.com/v/life/sports/#/all/click/0/{}/2020-11-13,2020-11-20".format(page) for page in range(1, 100)]+\
["https://www.bilibili.com/v/life/animal/#/all/click/0/{}/2020-11-13,2020-11-20".format(page) for page in range(1, 100)]+\
["https://www.bilibili.com/v/life/automobile/#/all/click/0/{}/2020-11-13,2020-11-20".format(page) for page in range(1, 100)]+\
["https://www.bilibili.com/v/life/handmake/#/all/click/0/{}/2020-11-13,2020-11-20".format(page) for page in range(1, 100)]+\
["https://www.bilibili.com/v/life/other/#/all/click/0/{}/2020-11-13,2020-11-20".format(page) for page in range(1, 100)]
second_url = []
def __init__(self):
self.opt= webdriver.ChromeOptions()
self.opt.add_argument('--headless')
self.opt.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=self.opt)
def close(self,spider):
self.driver.quit()
def parse(self, response):
item = SpiderBilibiliItem()
li_list = response.xpath('//ul[@class="vd-list mod-2"]/li')
for li in li_list:
item["up_name"] = li.xpath('.//div[@class="up-info"]/a/text()').extract_first()
item["video_name"] = li.xpath('.//div[@class="r"]/a/text()').extract_first()
item["views"] = li.xpath('.//div[@class="v-info"]/span[1]/span/text()').extract_first()
item["living_comments"] = li.xpath('.//div[@class="v-info"]/span[2]/span/text()').extract_first()
item["href"] = 'https:'+li.xpath('.//div[@class="r"]/a/@href').extract_first()
self.second_url.append(item["href"])
yield scrapy.Request(
item["href"],
callback=self.parse_detail,
meta = {
"item":deepcopy(item)} #一定要深拷贝,否则数据都会重复
)
def parse_detail(self,response):
item = response.meta["item"]
item["likes"] =response.xpath('//div[@class="ops"]/span[@class="like"]/text()').extract_first()
item["coins"] = response.xpath('//div[@class="ops"]/span[@class="coin"]/text()').extract_first()
item["collections"] = response.xpath('//div[@class="ops"]/span[@class="collect"]/text()').extract_first()
item["release_time"] =response.xpath('//div[@class="video-data"]/span[3]/text()').extract_first()
yield item
print(item)
items
import scrapy
class SpiderBilibiliItem(scrapy.Item):
up_name = scrapy.Field()
video_name = scrapy.Field()
views = scrapy.Field()
release_time = scrapy.Field()
href = scrapy.Field()
living_comments = scrapy.Field()
likes = scrapy.Field()
coins = scrapy.Field()
collections = scrapy.Field()
middlewares
import time
from scrapy.http import HtmlResponse
import random
from selenium.common.exceptions import TimeoutException
class SpiderBilibiliDownloaderMiddleware:
user_agent_list = [
"Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16",
"Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14",
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
]
def process_request(self, request, spider):
request.headers["User-Agent"] = random.choice(self.user_agent_list)
def process_response(self, request, response, spider):
if request.url not in spider.second_url:
try:
spider.driver.get(request.url)
time.sleep(2)
spider.driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(3)
except TimeoutException as e:
print(e)
page_text = spider.driver.page_source
return HtmlResponse(request.url,body=page_text,encoding='utf-8',request=request)
else:
return response
def process_exception(self, request, exception, spider):
pass
piplines
import csv
class SpiderBilibiliPipeline:
fp = None
def open_spider(self,spider):
print('开始爬虫')
self.fp = open('bilibili.csv','w',encoding='gb18030')
self.writer = csv.writer(self.fp,delimiter=',',lineterminator='\n')
self.writer.writerow(['up主名称','视频名称','发布时间','播放量','弹幕数','点赞数','投币数','收藏数'])
def process_item(self, item, spider):
item["up_name"] = item["up_name"].strip()
item["likes"] = item["likes"].strip()
item["coins"] = item["coins"].strip()
self.writer.writerow([item["up_name"],item["video_name"],item["release_time"],item["views"],
item["living_comments"],item["likes"],item["coins"],item["collections"]])
return item
def close_spider(self,spider):
self.fp.close()
print('爬虫结束')
settings设置
BOT_NAME = 'spider_bilibili'
SPIDER_MODULES = ['spider_bilibili.spiders']
NEWSPIDER_MODULE = 'spider_bilibili.spiders'
ROBOTSTXT_OBEY = False
LOG_LEVEL='ERROR'
DOWNLOADER_MIDDLEWARES = {
'spider_bilibili.middlewares.SpiderBilibiliDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'spider_bilibili.pipelines.SpiderBilibiliPipeline': 300,
}
最终共爬取13532条数据,如下图所示:
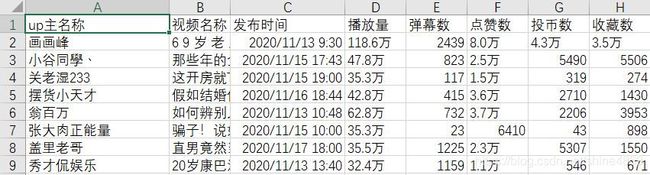
大概只花了2个多小时,简直比selenium快太多了呀!(之前爬CSDN博主信息,用selenium3个小时也只能爬1千多条数据)个人感觉scrapy+selenium组合简直无敌呀!如果没特殊的反爬,基本上可以解决大部分网页爬取了!
以上就是本次分享的全部内容~
