Android Binder通信一次拷贝你真的理解了吗?
Android Binder通信一次拷贝你真的理解了吗?
Android Binder框架实现目录:
Android Binder框架实现之Binder的设计思想
Android Binder框架实现之何为匿名/实名Binder
Android Binder框架实现之Binder中的数据结构
Android Binder框架实现之Binder相关的接口和类
Android Binder框架实现之Parcel详解之基本数据的读写
Android Binder框架实现之Parcel read/writeStrongBinder实现
Android Binder框架实现之servicemanager守护进程
Android Binder框架实现之defaultServiceManager()的实现
Android Binder框架实现之Native层addService详解之请求的发送
Android Binder框架实现之Native层addService详解之请求的处理
Android Binder框架实现之Native层addService详解之请求的反馈
Android Binder框架实现之Binder服务的消息循环
Android Binder框架实现之Native层getService详解之请求的发送
Android Binder框架实现之Native层getService详解之请求的处理
Android Binder框架实现之Native层getService详解之请求的反馈
Android Binder框架实现之Binder Native Service的Java调用流程
Android Binder框架实现之Java层Binder整体框架设计
Android Binder框架实现之Framework层Binder服务注册过程源码分析
Android Binder框架实现之Java层Binder服务跨进程调用源码分析
Android Binder框架实现之Java层获取Binder服务源码分析
引言
最近有读者在询问一个关于Binder通信"一次拷贝"的问题,说在学习Binder驱动的实现中看到有多次调用了copy_from_user和copy_to_user来进行数据的跨用户空间和内核空间的拷贝,但是为啥Android官方和绝大部分的博客还是说只进行了一次拷贝呢!这就是本篇博客的由来!
对于从事Android开发的coder来说Binder应该不会陌生了(如果对它概念都没有的话,那估计大概率是个假的开发者了)!按照现在比较流行的段位排序来说,青铜选手(初级开发者)肯定知道Binder是Android提供的可以进行跨进程的IPC通信机制,而白银选手(中级开发者)肯定应该知道Binder跨进程IPC通信原理是通过内存映射实现的,而这也是Binder相对于其他传统进程间通信方式的优点之一(即我们总说的Binder只需要做“一次拷贝”,而其他传统方式需要“两次拷贝”的核心了)!
对于这里的排位没有歧视或者任何其它的意思啊(仅仅是为了文字的描述),闻道有先后术有专攻而已,而已啊!
不对啊,王者排序还没有结束啊!是的,这不我们的Binder的进阶打怪不是也没有结束吗,所以不要着急!,对于想继续进阶的王者段位(高阶开发者来说)肯定会再进一步思考深入,一定会遇到两个绕不开的的关于Binder的问题:
- 这所谓的“一次拷贝”到底是发生在什么地方?
这个问题,对于有研究过Binder驱动源码的读者来说一定会有体会,因为在Binder驱动的源码中有多次copy_from_user和copy_to_user的调用,根本不止"一次拷贝",但是很多的书籍包括Android官方都多宣称只有一次拷贝,这是为什么呢,是它们错了,还是我们理解不到位呢!
- 这"一次拷贝“的到底是什么东西?
而很不幸的是绝大部分介绍Android的Binder的文章会重点强调“一次拷贝”是其优点之一,但对上面的两个问题要么一笔带过,要么就是回答的并不完全正确,从而给读者造成一些理解上的混乱(感觉被欺骗了的感觉)。所以本篇文章会从两个维度来阐述这个问题:
- 第一个维度:对于青铜开发者,将带领读者了解为啥Binder跨进程IPC通信只需要"一次拷贝",而传统的IPC通信为啥需要两次拷贝(当然想深入吗,可以先从我上面的Android Binder框架实现目录开启,不是打广告!)
- 第二个维度:对于想继续进阶的开发者,我将带领大伙解决上面列举的两个疑问点(这个阶段就需要读者对Binder驱动的工作过程和Binder驱动源码有一个大致的了解,如果没有那就只能是解决第一阶段目标了)
注意,本篇博客的源码是基于Android 7来进行的,其中后续分析涉及的源码路径如下:
--- kernel/drivers/staging/android/binder.c
--- kernel/include/linux/list.h
--- kernel/drivers/staging/android/uapi/binder.h
--- external/kernel-headers/original/uapi/linux/android/binder.h
--- framework/native/cmds/servicemanager/binder.c
--- frameworks/native/cmds/servicemanager/service_manager.c
--- frameworks/native/include/binder/Parcel.h
--- frameworks/native/include/binder/IPCThreadState.h
--- frameworks/native/libs/binder/IPCThreadState.cpp
--- frameworks/native/include/binder/ProcessState.h
--- frameworks/native/libs/binder/ProcessState.cpp
一.前期知识准备
注意,注意,注意重要的事情说三篇!
这一大章节主要是针对青铜读者进行入门使用的,如果你已经是白银段位或者王者段位的,这个章节可以跳过,直接进入下一环节!
Android的Binder是一个跨多种技术的集大成者(特别是Linux相关的技术),所以在回答分析今天的博客标题所提出来的问题之前,我们非常有必要了解科普一些相关的知识,特别是Linux中传统的跨进程IPC通信的(注意这里的措辞是科普和了解,因为想要深入这块的知识,不是本篇博客也不是一两篇博客能做到的,而且说实话读者本人也就了解个大概,了解)!
1.1 Linux系统中进程模型
我们知道Linux中的进程是被隔离不能直接进行通信的,而Android的应用程序作为特殊的Linxu进程也遵循了这一原则。所以这里我们要必要先了解一下Linux中的进程模型,然后扩散到涉及的一些基本概念,再然后逐步展开,让大家先行掌握传统LInux进程通信,然后发散到Android的Binder IPC进程通信!
啥也不说了,翠花上酸菜!我们先看下Linux中进程模型图,如下:

上面的图示向我们传递了Linux进程模型中几个非常重要的概念(这个几个概念和后续的Linux跨进程通信息息相关):
- 进程隔离
- 用户空间(User space)
- 内核空间(Kernel space)
- 系统调用(System call)
下面让我们对上述几个概念一一介绍,各个了解,走起约起!
1.2 Linux进程隔离
提到进程隔离让我莫名的想到了种群隔离,扯多了言归正传!我们从如下几个维度来简单说说进程隔离:
- 进程隔离的概念:进程隔离简单的说就是Linux操作系统设计的一种机制使进程之间不能共享数据,保持各自数据的独立性即A进程不能访问B进程数据,同理B进程也不能访问A进程数据
- 进程隔离的实现原理:进程隔离的实现使用到了虚拟内存技术(这个后面简单说下)
- 进程隔离的目的:当然是通过虚拟内存技术,达到Linux进程中数据不能共享,从而保持独立的功能
正是由于上述提到的进程隔离,从而导致Linux进程之间要进行数据交互就得采用特殊的通信机制进程间IPC通信!
1.3 Linux虚拟内存
虚拟内存顾名思义就是一种实际上并不存在的内存,是虚拟出来的。它是Linux操作系统为了进行内存管理而设计的一种内存管理机制。总之就是虚拟内存是被虚拟出来的,是为了实现更好的内存管理而创建出来的最后它会通过一定的机制和物理内存映射起来的,并且这个映射的过程对应用程序来说是透明的!
感觉有点整不下去了,因为这个涉及到操作系统的相关原理了。!读者如果有兴趣的请参阅博客Linux虚拟内存和物理内存的理解和Linux虚拟内存,网上有很多关于这方面的知识,这里我就先撤了。
1.4 Linux进程空间(内核空间和用户空间)
我们前面提到了虚拟内存的概念,而Linux进程空间就是通过虚拟内存来实现的。我们知道现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操心系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核,保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。
针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。每个进程可以通过系统调用进入内核,因此,Linux内核由系统内的所有进程共享。于是,从具体进程的角度来看,每个进程可以拥有4G字节的虚拟空间。
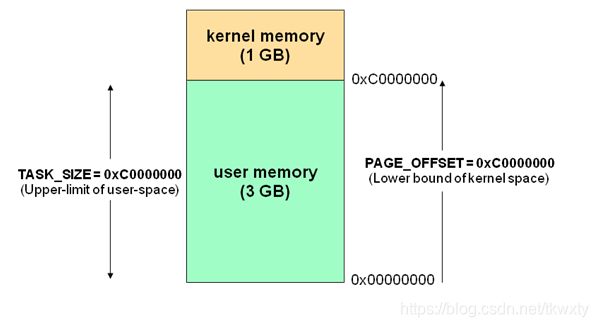
关于进程空间有如下几个点需要注意:
1.内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。不管是内核空间还是用户空间,它们都处于虚拟内存中的(当然肯定会在实际使用中映射到实际的物理内存上面去的)。
2.为了保证系统的安全,用户空间和内核空间是天然隔离的
3.内核空间是被所有的进程所共享的,这个从最上面的进程模型也可以看出来
4.为啥要将进程空间划分为用户空间和内核空间呢,且之间有隔离,用户空间不能随意操作内核空间呢,这个最最主要的原因是为了安全方面考虑的,因为内核拥有对底层设备的所有访问权限,为了安全用户进程是不能直接访问内核进程的
1.5 Linux进程空间系统调用
虽然操作系统从逻辑上进行了用户空间和内核空间的划分,但不可避免的用户空间需要访问内核资源,比如文件操作、访问网络等等。为了突破隔离限制,就需要借助系统调用来实现。系统调用是用户空间访问内核空间的唯一方式,保证了所有的资源访问都是在内核的控制下进行的,避免了用户程序对系统资源的越权访问,提升了系统安全性和稳定性。
而在实际的操作中所有的系统资源管理都是在内核空间中完成的。比如读写磁盘文件,分配回收内存,从网络接口读写数据等等。我们的应用程序是无法直接进行这样的操作的。但是我们可以通过内核提供的接口来完成这样的任务这就是所谓的系统调用了。比如应用程序要读取磁盘上的一个文件,它可以向内核发起一个 “系统调用” 告诉内核:“我要读取磁盘上的某某文件”。其实就是通过一个特殊的指令让进程从用户态进入到内核态(到了内核空间),在内核空间中,CPU 可以执行任何的指令,当然也包括从磁盘上读取数据。具体过程是先把数据读取到内核空间中,然后再把数据拷贝到用户空间并从内核态切换到用户态。此时应用程序已经从系统调用中返回并且拿到了想要的数据,可以开开心心的往下执行了。其切换的示意图如下:
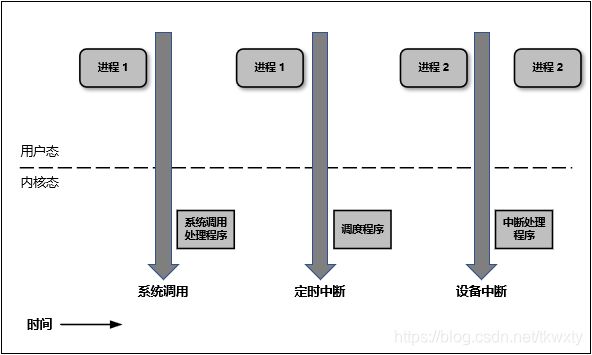
这里简单说下什么是内核态与用户态:
(1)当一个任务(进程)执行系统调用而陷入内核代码中执行时,称进程处于内核运行态(内核态)。此时处理器处于特权级最高的(0级)内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。每个进程都有自己的内核栈。
(2)当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。此时处理器在特权级最低的(3级)用户代码中运行。当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈。
并且Linux使用两级保护机制:0级供系统内核使用,3级供用户程序使用
1.6 Linux进程空间跨进程通信常用的系统调用函数
到这里不容易啊,概念性的东西就是这么枯燥且乏味(当然深入了,那就是另外一说了啊)!而我们今天的博客重点两字就是"通信",这里我们先重点看下Linux进程空间是重点通过那几个函数实现用户空间和内核空间的数据交互的。
1.6.1 用户空间向内核空间传递数据常用函数
这里主要用到了两个函数,分别是copy_from_user()和get_user(),它们拷贝的数据流向如下:
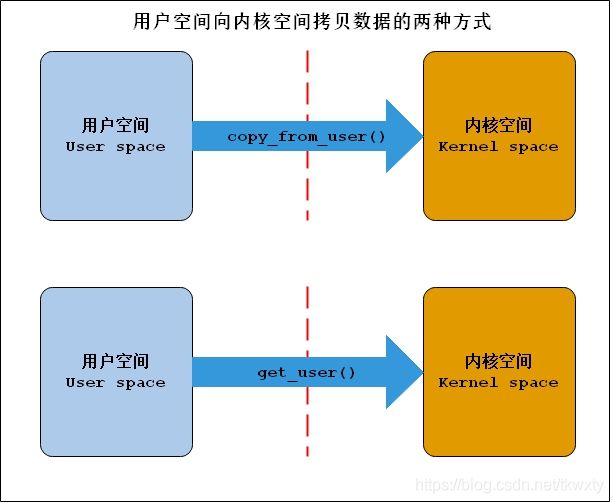
1.6.2 用户空间向内核空间传递数据常用函数
这里主要用到了两个函数,分别是copy_to_user()和put_user(),它们拷贝的数据流向如下:

这里关于上述四个函数(宏)就不一一列举出来了啊,可以详见博客copy_to_user 、copy_from_user函数实现内核空间数据与用户空间数据的相互访问。
1.7 Linux内存映射概念
前面一口气介绍了这么多的Linux相关概念,这还没有完,还有一个非常重要重要的知识点没有介绍完毕,那就是Linux的内存映射概念。这里读者可以先缓缓,先理解理解前面的概念,心里有个谱,然后继续征战!
内存映射是系统调用函数mmap()的中文翻译,其本质是一种进程虚拟内存的映射方法,它可以将一个文件、一段物理内存或者其它对象(也包括内核空间)映射到进程的虚拟内存地址空间。实现这样的映射关系后,进程就可以采用指针的方式来读写操作这一段内存,进而完成对文件(或者其它被映射的对象)的操作,而不必再调用 read/write 等系统调用函数了。所以正是因为有如上的特点内存映射能减少数据拷贝次数,实现用户空间和内核空间的高效互动。当映射成功以后,两个空间各自的修改能直接反映在映射的内存区域,从而被对方空间及时感知。也正因为如此,内存映射能够提供对进程间通信的支持。其模型如下所示:
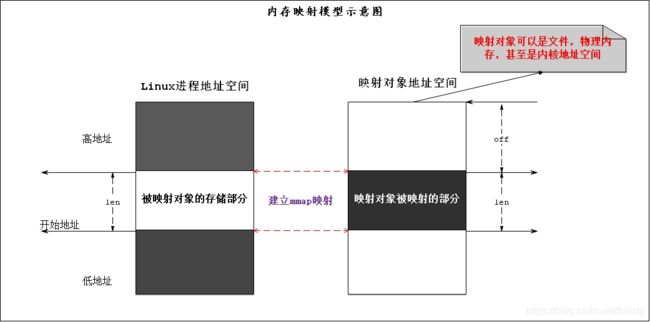
看到上述的描述可以减少拷贝次数,估计读者眼前一亮了!难不成Binder通信只拷贝依次的秘密武器就是它,是的Binder通信少拷贝一次的秘密武器就是它。这里我们先不带入Binder通信的概念,只重点了解一下内存映射的原理!
关于这一块的具体底层原理读者可以想见博客Android-内存映射mmap和Linux操作系统原理—内存—mmap进程虚拟内存映射这两篇博客。
1.8 Linux动态内核加载模块技术与Binder驱动简介
1.8.1 Linux动态内核加载模块技术
通过前面的理论知识的补充,我们知道了Linux进程空间中的用户空间和内核空间在绝大部分情况下是隔离的,它们之间的通信是可以通过系统调用来实现的。而传统的进程IPC通信模式都是如下接着内核来实现的譬如如管道,socket,消息队列等,而它们都已经作为Linux的内核一部分了,所以Linux是天然支持如上几种IPC通信模式的。
但是我们的Android中引入的Binder通信概念中的Binder驱动并不是Linux系统标准内核的一部分,那怎么实现加载和使用呢?这就得益于Linux的动态内核可加载模块(Loadable Kernel Module,LKM)的机制;模块是具有独立功能的程序,它可以被单独编译,但是不能独立运行。它在运行时被链接到内核作为内核的一部分运行。这样,Android系统就可以通过动态添加一个内核模块运行在内核空间,用户进程之间通过这个内核模块作为桥梁来实现通信。
1.8.2 Binder驱动简介
在介绍Binder驱动之前我们先了解一下驱动的基本概念,驱动是一种使用实现对硬件进行相关操作,并屏蔽硬件特性的一种软件技术!并且Linux将驱动分为三大类:字符设备驱动,块设备驱动以及网络设备驱动。
这里对于驱动的概念就不做过多的介绍了,关于驱动的详细介绍可以参见博客Linux驱动简介及分类。
好了上面我们对驱动有了一定的了解了,这里我们简单介绍一下Binder驱动,Binder驱动是一种虚拟的字符设备(重点它是虚拟出来的,实际上Binder驱动并没有操作相关的硬件),注册在/dev/binder中,如下所示:
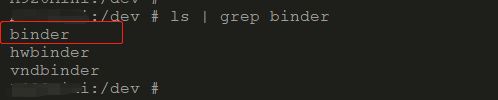
其定义了一套Binder通信协议,负责建立进程间的Binder通信,提供了数据包在进程之间传递的一系列底层支持。当然Binder驱动是Android特有的,所以它不是Linux标准内核携带的必须通过动态内核加载进行加载的。既然Binder驱动属于内核层所以应用层对于它访问也是通过系统调用实现的。
二.Linux传统IPC通信原理和Binder通信原理
这个章节主要是从理论层面解释Linux传统IPC通信原理和Binder通信原理关于拷贝次数差异的原因所在,让读者从可以瞬间从青铜进阶成白银(如果这关读者已经打通,可以直接跳过进入下一章节了)。至于想变成最后的王者呗,那必须是待最后的分析了!
有了前面知识的铺垫,是时候来点真家伙了!让我们一起来揭开Binder IPC通信所谓"一次拷贝"和其它IPC通信“两次拷贝“的真实面纱!
2.1 Linux传统跨进程IPC通信原理
Linux传统进程IPC通信由于Linux进程设计的原因,通常需要如下的步骤进行跨进程IPC通信(共享内存除外):
-
对于消息的发送端进程:
- 通常传统的IPC通信(Socket,管道,消息队列)首先将消息发送方将要发送的数据存放在内存缓存区中
- 然后通过前面所说系统调用进入内核态。然后操作系统为Linux发送方进程在内核空间分配内存,开辟一块内核缓存区,调用 copy_from_user()函数将数据从用户空间的内存缓存区拷贝到内核空间的内核缓存区中
-
对于消息的接收端进程:
- 首先在进行接收数据时在自己的用户空间开辟一块内存缓存区
- 然后操作系统为Linux接收方进程在内核空间中调用 copy_to_user() 函数将数据从内核缓存区拷贝到接收进程的内存缓存区。这样数据发送方进程和数据接收方进程就完成了一次数据传输,我们称完成了一次进程间通信
Linux传统跨进程IPC通信的模型可以使用如下的示意图来完整表示,如下:
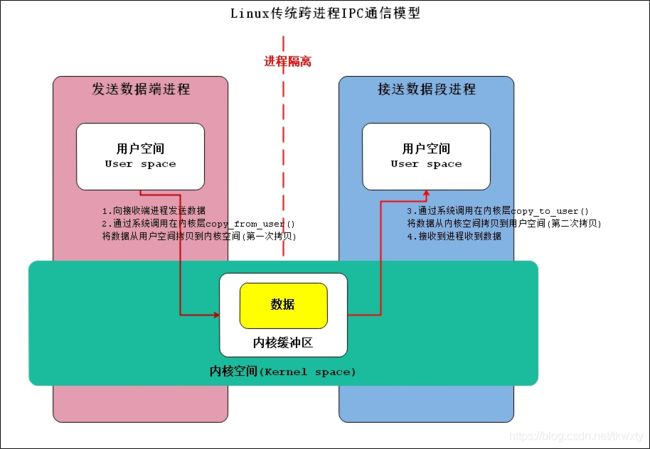
好吗,说到这里不说下Linux传统跨进程IPC通信模型的缺点好像过意不去,必须吐槽一下(注意,此处仅仅就IPC通信数据传输效率,以及资源占用角度出发):
1.传统IPC通信模型传输效率比较低,拷贝次数过多需要两次(这个仅是对于Binder和匿名共享内存而言),第一次是从发送方用户空间拷贝到内核缓存区,第二次是从内核缓存区拷贝到接收方用户空间。
2.接收数据的缓存区由数据接收进程提供,但是接收进程并不知道需要多大的空间来存放将要传递过来的数据,因此只能开辟尽可能大的内存空间或者先调用API接收消息头来获取消息体的大小,这两种做法不是浪费空间就是浪费时间。
2.2 Binder跨进程IPC通信原理
传统Linux进程的跨进程IPC通信原理介绍完毕,是时候来介绍Binder跨进程IPC通信原理了!前面我们知道了传统的IPC通信采用的是发送端Linux进程用户空间内存-区–>内核空间—>接收端Linux进程用户空间内存区的"两次拷贝"方式,那么Binder跨进程IPC通信是怎么做到了节约一次内存拷贝只需要一次的呢?
细心的的读者肯定想到了博主在前面知识储备章节说到的内存映射mmap方式了,并且博主在介绍mmap的时候有强调了一个关键点就是内存映射不仅可以将文件映射到进程的用户空间(从而减少数据的拷贝次数,用内存读写取代I/O读写,提高文件读取效率),而且也可以将内核空间的一块区域映射到进程的用户空间。而我们这里的Binder跨进程IPC通信正是借助了内存映射的方法,在内核空间和接收方用户空间的数据缓存区之间做了一层内存映射。这样一来,从发送方用户空间拷贝到内核空间缓存区的数据,就相当于直接拷贝到了接收方用户空间的数据缓存区,从而减少了一次数据拷贝(在这里不得不说声设计的真的巧妙啊)。
一次完整的 Binder IPC 通信过程通常如下所示:
- 对于Binder服务端进程而言:
- Binder服务端(Service)在启动之后,通过系统调用Binde驱动在内核空间创建一个数据接收缓存区(调用binder_oepn方法执行相关的操作)
- 接着Binder服务端进程空间的内核接收到系统调用的指令,进而调用binder_mmap函数进行对应的处理。首先申请一块物理内存,然后建立Binder服务端(Service端)的用户空间和内核空间一块区域的映射关系(这样上述两块区域就映射在一起了)
- 对于请求端(Client)进程而言:
- Client向服务端发送通信发送请求,这个请求数据打包完毕之后通过系统调用先到驱动中,然后在驱动中通过copy_from_user()将数据从用户空间拷贝到内核空间的缓存区中(注意这块内核空间和Binder服务端的用户空间存在映射关系)
- 由于内核缓存区和接收进程的用户空间存在内存映射,因此也就相当于把数据发送到了接收进程的用户空间(只需要进行一定的偏移操作即可),这样便完成了一次进程间的通信,从而达到了省去一次拷贝的操作
Binder跨进程IPC通信(数据传输)的模型可以使用如下的示意图来完整表示,如下:

这里Binder就数据传入效率和资源包占用角度来说,相关传统的IPC通信有如下的优点:
1.减少了数据的拷贝次数,用内存读写取代 I/O 读写,提高了文件读取效率
2.作为Binder服务端开辟的数据接收区大小是固定的(对于普通的BInder服务端和servicemanager端有一定的区别,都是都没有大于1M的空间)
三.Binder通信"一次拷贝"源码大揭秘
通过前面的不懈努力,为我们的源码事业贡献无数青春和汗水的情况下(有点夸张啊)终于我们将Linux传统跨进程IPC通信原理和Binder跨进程IPC通信原理给弄清楚了,可喜可贺啊!但是如果想要真的掌握好了Binder通信"一次拷贝"的真正精髓,那还得深入研究一番,而这个章节的博客的目的正是如此带领读者从白银选手走向终极王者巅峰!在这大章节中我们将要重点掌握的是如下两个的关键知识点:
- 内核中服务端内存映射的建立
- 在Binder驱动源码中有多次调用了copy_from_user()和copy_to_user()这两个函数(注意这里强调的是多次调用),这里我们将要带领读者搞清楚每次调用都是在拷贝些什么东西,拷贝到哪里去了
- 既然上面存在了多次拷贝,那为啥Binder通信又铺天盖地的说只进行了“一次拷贝”呢,这个是不是有问题呢,或者是我们的理解有问题呢?
- 发送端数据通过一次拷贝到内核,怎么和接收服务端的映射空间建立连接
在后续源码的分析中,我们会主要集中火力在和Binder实现的内存操作相关的源码分析中,Binder其它的相关逻辑就忽略带过了。并且这一章节对读者的Binder知识有一定高度的要求,如果读者没有相关方面的知识储备可以从本篇博客最开始的Binder框架目录中的文章开始!
3.1 Binder预备知识准备
前途是光明的,道路是曲折的!所以如果想要深入探究Binder通信"一次拷贝"的真正原理,在开始相关的源码分析前还是有必要梳理梳理一下将要涉及的相关Binder知识,来点储备。走起,梳理起:
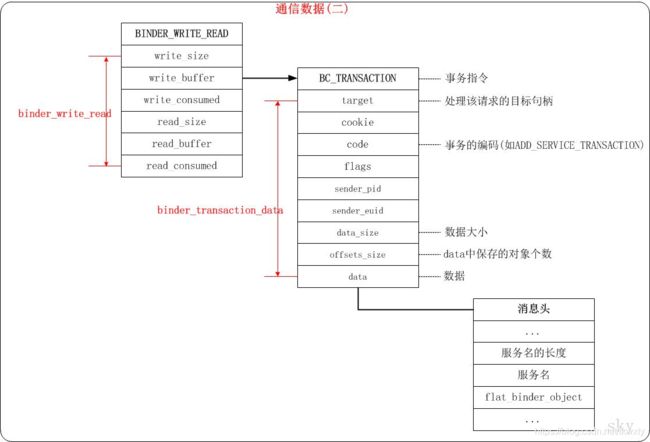
- 由于在后续的博客分析中会牵涉到Binder通信中数据的封装和打包,这里我们有必要了解一下Binder传入数据协议的的封装逻辑,具体的可以参见博客Android Binder框架实现之Binder中的数据结构和Android Binder框架实现之Native层addService详解之请求的发送这两篇博客,其Binder传入数据的打包封装基本模型如下所示:

- 参与Binder通讯的进程,无论是请求端还是服务器端,他们都会通过调用ProcessState::self()函数来建立自己的初步映射(这也是为什么说Android进程是天生就支持Binder通信的所在),而我们本章节博客重点也是从此处开始
对于上述流程还有不是很清楚的读者请参见如下博客:
Android Binder框架实现之servicemanager守护进程
Android Binder框架实现之defaultServiceManager()的实现
Android Binder框架实现之Native层addService详解之请求的发送
3.2 服务端(接收)进程Binder建立内存映射
其实这个标题,应该是Binder进程建立内存映射,但是这里为了形成一个整体的链路所以特意写的是服务端(接收)进程。
前面我们知道了Binder内存映射建立是从ProcessState::self()函数开始,该函数使用典型的单列模式:如已创建该实例则直接返回,如果没有创建,则创建返回这个实例,这里需要锁来防止创建两个同类型的实例,该函数还是static类型的,所以可以在系统的任何地方调用。先上源码,一起燥起来!
//[ProcessState.cpp]
sp<ProcessState> ProcessState::self()
{
Mutex::Autolock _l(gProcessMutex);
if (gProcess != NULL) {
return gProcess;
}
gProcess = new ProcessState;
return gProcess;
}
上述源码逻辑没有啥好说的(主要就是判断是否已经初始化过了gProcess而已),我们接着看ProcessState的构造方法,如下:
//[ProcessState.cpp]
#define BINDER_VM_SIZE ((1*1024*1024) - (4096 *2))
ProcessState::ProcessState()
: mDriverFD(open_driver())
, mVMStart(MAP_FAILED)
, mThreadCountLock(PTHREAD_MUTEX_INITIALIZER)
, mThreadCountDecrement(PTHREAD_COND_INITIALIZER)
, mExecutingThreadsCount(0)
, mMaxThreads(DEFAULT_MAX_BINDER_THREADS)
, mStarvationStartTimeMs(0)
, mManagesContexts(false)
, mBinderContextCheckFunc(NULL)
, mBinderContextUserData(NULL)
, mThreadPoolStarted(false)
, mThreadPoolSeq(1)
{
if (mDriverFD >= 0) {
//mmap()函数原型
//void *mmap(void *addr, size_t length int " prot ", int " flags , int fd, off_t offset);
// mmap the binder, providing a chunk of virtual address space to receive transactions.
mVMStart = mmap(0, BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0);
if (mVMStart == MAP_FAILED) {
// *sigh*
ALOGE("Using /dev/binder failed: unable to mmap transaction memory.\n");
close(mDriverFD);
mDriverFD = -1;
}
}
LOG_ALWAYS_FATAL_IF(mDriverFD < 0, "Binder driver could not be opened. Terminating.");
}
可以看到在ProcessState的构造函数中,它有进行一系列的初始化(这种初始化的方式在C++中运用的比较普遍)。其中比较重要的有如下两步:
-
通过open_driver()打开"/open/binder",并将文件句柄赋值给mDriverFD(关于这部分不是本篇博客的重点,就不花费过多的时间分析了,如果还有不清楚的可以详见博客Android Binder框架实现之defaultServiceManager()的实现的2.2.2 open_driver()章节)
-
通过调用mmap()映射内存,最后会通过系统调用调用内核空间驱动的binder_mmap()函数。这里我们先mmap()的入参分析一下(如果对于mmap()有不清楚的,请参见章节1.7 Linux内存映射概念中关于mmap()函数的说明):
- 第一个参数是映射内存的起始地址,0代表让系统自动选定地址
- mapsize表示映射空间的大小,这里的取值1M-8K的
- PROT_READ表示映射区域是可读的
- MAP_PRIVATE表示建立一个写入时拷贝的私有映射(即,当进程中对该内存区域进行写入时,是写入到映射的拷贝中)
- mDriverFD是"/dev/binder"句柄
- 而0表示偏移
这里有几点我要重点强调说明一下:
1.重点注意mmap上方的注释,已经说的很清楚了,这块内存映射只是作为接收transactions来使用的,也就是说往驱动写数据的时候是与内存映射无关的。记住这一点
2.mmap()函数是怎么通过系统调用到binder_mmap()来的,这个说来话长了(如果读者是从事驱动开发的应该就很容易理解了),可以详见博客Android binder中的mmap到binder_mmap调用流程和博客Android Binder框架实现之servicemanager守护进程的章节3.3以及mmap系统调用(内核空间到用户空间的映射就OK了。
分析到这里,我来给读者提一个问题是不是所有的Binder进程映射的内存空间大小都是固定的呢?譬如这里的1M-8K大小!我想对于Binder框架熟悉的读者肯定能很快的回答出来,不是的!因为有一个特例就是 servicemanager进程,它的Binder映射空间大小只有128K,这个要怎么来确定呢,我们可以通过如下的简单命令来验证一下:

xxx:/ # ps | grep servicemanager
system 419 1 4912 1400 binder_thr ac9d562c S /system/bin/servicemanager
xxx:/ # cat /proc/419/maps | grep binder
ac840000-ac860000 r--p 00000000 00:0b 8600 /dev/binder
xxx:/ #
可以看到很明显,这里的计算结果表明servicemanager进程的Binder映射空间大小只有128K(计算方法这里就不需要强调了吗,0xac840000-0xac860000虚拟地址长度)。

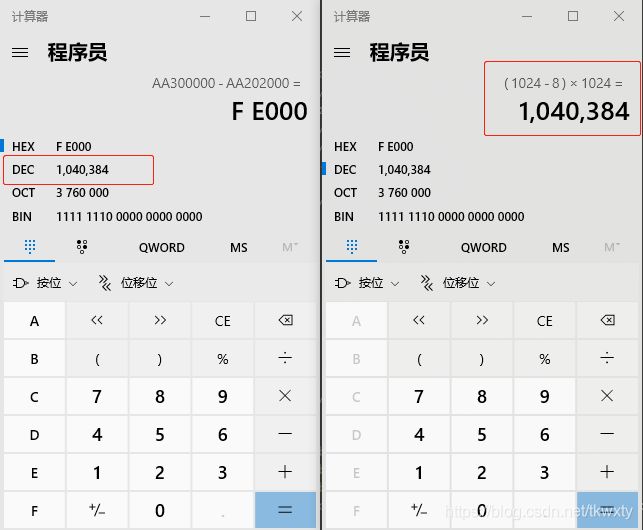
我们接下来看下普通进程的Binder地址长度,这里我们以mediaserver为例说明,如下:

xxx:/ # ps | grep mediaserver
media 571 1 43028 6964 binder_thr aa45362c S /system/bin/mediaserver
xxx:/ # cat /proc/571/maps | grep binder
aa202000-aa300000 r--p 00000000 00:0b 9864 /dev/binder
aabb7000-aac07000 r-xp 00000000 b3:15 1485 /system/lib/libbinder.so
aac08000-aac11000 r--p 00050000 b3:15 1485 /system/lib/libbinder.so
aac11000-aac12000 rw-p 00059000 b3:15 1485 /system/lib/libbinder.so
xxx:/ #
老规矩,我们来计算一下被映射的Binder地址空间大小是不是1M-8K,见证奇迹的时候到了,如下:
3.2.1 内核空间对Binder映射的处理
通过前面我们知道进程空间的用户空间mmap操作最后会通过系统调用到内核空间的binder_mmap()中去,所以让我们深入内核层看看binder_mmap()的处理逻辑是什么。我们先看下binder_mmap()函数的定义,如下:
static int binder_mmap(struct file *filp, struct vm_area_struct *vma);
我们先看下该函数的参数的定义,其中struct vm_area_struct *vma就是内核为我们找到的用户空间的进程虚拟内存区域,这就是我驱动程序需要映射到设备内存的地址。而该参数的vma->vm_start和vma->vm_end即为此次映射内核为我们分配的开始地址和结束地址,他们差值就是系统调用mmap中的length的值。而vma->vm_start的则是系统调用mmap调用的返回值。需要注意的是vma->vm_start和vma->vm_end都是调用进程的用户空间的虚拟地址,他们地址范围可以通过如下命令:cat /proc/pid/maps | grep "/dev/binder"看到,如上图所示mediaserver进程对应的vma->vm_start和vma->vm_end的值分别为:aa202000和aa300000。
该了解的不该了解的都已经了解了,我们直接来看binder_mmap()的源码实现。
//[kernel/drivers/staging/android/binder.c]
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
//内核进入这个函数时,就已经预先为此次映射分配好了调用进程在用户空间的虚拟地址范围
//(vma->vm_start,vma->vm_end)
struct binder_buffer *buffer;
// 有效性检查:映射的内存不能大于4M
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
...
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
mutex_lock(&binder_mmap_lock);
//为进程所在的内核空间申请与用户空间同样长度的虚拟地址空间,这段空间用于内核来访问和管理binder内存区域
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
...
// 将内核空间地址赋值给proc->buffer,即保存到进程上下文中,对应内核虚拟地址的开始,即为binder内存的开始地址
proc->buffer = area->addr;
// 计算 "内核空间地址" 和 "进程虚拟地址" 的偏移
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
// 为proc->pages分配内存,用于存放内核分配的物理页的页描述指针:struct page,每个物理页对应这样一个struct page结构
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
...
// 内核空间的内存大小 = 进程虚拟地址区域(用户空间)的内存大小
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
// 将 proc(进程上下文信息) 赋值给vma私有数据
vma->vm_private_data = proc;
// 通过调用binder_update_page_range()来分配物理页面。
// 即,将物理内存映射到内核空间 以及 用户空间
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
goto err_alloc_small_buf_failed;
}
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
// 将物理内存添加到proc->buffers链表中进行管理。
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
// 把分配好内存插入到对应的表中(空闲内存表)
binder_insert_free_buffer(proc, buffer);
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(proc->tsk);
// 将用户空间地址信息保存到proc中
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
return 0;
...
}
这里可以看到binder_mmap的作用是进行内存映射。当应用调用到内存的binder_mmap()映射内存到进程虚拟地址时,该函数会进行两个操作
- 第一,将指定大小的"物理内存" 映射到 “用户空间”(即,进程的虚拟地址中)
- 第二,将该"物理内存" 也映射到 “内核空间(即,内核的虚拟地址中)”。简单来说,就是"将进程虚拟地址空间和内核虚拟地址空间映射同一个物理页面"
这样在Binder通信机制中,binder_mmap()会将Server进程的虚拟地址和内核虚拟地址映射到同一个物理页面。那么当Client进程向Server进程发送请求时,只需要将Client的数据拷贝到内核空间即可!由于Server进程的地址和内核空间映射到同一个物理页面,因此,Client中的数据拷贝到内核空间时,也就相当于拷贝到了Server进程中。因此,Binder通信机制中,数据传输时,只需要1次内存拷贝!这就是Binder通信原理的精髓所在!
上面binder_update_page_range函数就是为进程的内核空间和进程的用户空间针对同一块物理内存建立映射,这样进程的用户空间和内核空间就可以共享该物理内存了。对于它我就不展开了,感兴趣的可以参见博客Android binder中的mmap到binder_mmap调用流程和博客Android Binder框架实现之servicemanager守护进程的章节3.3以及mmap系统调用(内核空间到用户空间的映射就OK了。
3.3 请求端进程数据传输过程
本大章节的主题是Binder通信"一次拷贝"源码大揭秘,而其中我们需要要解决的是Binder通信传输的一次拷贝的本质,所以我们这里对Binder的其它枝节不予关系,只重点关注其中内存和数据的处理。而一次完整的Binder传输需要涉及到发送端和接收端进程(Binder也可以同一个进程通信,这种模式不在我们这里讨论范围之内),所以这里我们先从请求端进程开始分析起!
并且这里的分析,我们只关注数据的处理部分,发送端进程是怎么从业务逻辑调用到传输逻辑我们就不赘述了,有不清楚的详见博客Android Binder框架实现之请求数据的发送,里面有关于Binder通信数据传入的完整流程!
3.3.1 请求端用户空间对传输数据的处理
在进程的用户空间,我们知道BInder数据最后都会统一通过IPCThreadState::writeTransactionData对传入的数据进行处理,我们看下它对传入数据的处理逻辑,如下:
IPCThreadState::writeTransactionData
//[IPCThreadState.cpp]
//对于Binder实现有一定掌握的读者,这里的代码一定看着很亲切吗
status_t IPCThreadState::writeTransactionData(int32_t cmd, uint32_t binderFlags,
int32_t handle, uint32_t code, const Parcel& data, status_t* statusBuffer)
{
binder_transaction_data tr;
tr.target.ptr = 0; /* Don't pass uninitialized stack data to a remote process */
tr.target.handle = handle;
tr.code = code;
tr.flags = binderFlags;
tr.cookie = 0;
tr.sender_pid = 0;
tr.sender_euid = 0;
const status_t err = data.errorCheck();
..
tr.data_size = data.ipcDataSize(); //数据大小(对应mDataSize)
tr.data.ptr.buffer = data.ipcData(); //数据的起始地址(对应mData)
tr.offsets_size = data.ipcObjectsCount()*sizeof(binder_size_t); // data中保存的对象个数(对应mObjectsSize)
tr.data.ptr.offsets = data.ipcObjects(); // data中保存的对象的偏移地址数组(对应mObjects)
...
// 将tr写入mOut。
mOut.writeInt32(cmd);
mOut.write(&tr, sizeof(tr));
return NO_ERROR;
}
这里的binder_transaction_data数据结构存储的是相关Binder传入的数据和一些相关的控制指令,然后被 统一打包到了Parcel实例对象mOut中去了,关于Binder传入涉及的数据结构binder_transaction_data其数据模型可以参见章节3.1的介绍!Binder要传输的数据打包完毕后,发送端进程会调用IPCThreadState::talkWithDriver函数继续处理数据,我们接着往下看!
IPCThreadState::talkWithDriver
status_t IPCThreadState::talkWithDriver(bool doReceive)
{
binder_write_read bwr;
...
bwr.write_size = outAvail;
bwr.write_buffer = (uintptr_t)mOut.data();
// 这里我们先暂且忽略发送端读取数据涉及的数据交互
if (doReceive && needRead) {
bwr.read_size = mIn.dataCapacity();
bwr.read_buffer = (uintptr_t)mIn.data();
} else {
...
}
....
bwr.write_consumed = 0;
bwr.read_consumed = 0;
status_t err;
. ...
//调用ioctl,然后通过系统调用到binder_ioctl
if (ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr) >= 0)
return err;
}
这里的处理逻辑也比较简单,就是对前面的封装的binder_transaction_data的数据又进行了一次的封装,这里使用的是binder_write_read数据结构实例对象bwr。其中bwr.write_buffer保存了指向mOut.data()的指针,通过前面章节我们也知道了指向了前面的binder_transaction_data对象实例tr。
此处的数据封装,一定要搞清楚,对于前面的数据模型一定要清楚。
3.3.2 请求端用户空间对传输数据的处理
最终ioctl对通过系统调用到内核层的binder_ioctl进行下一步的处理,我们接着往下看(第一次拷贝要出现了)。
//[kernel/drivers/staging/android/binder.c]
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
...
void __user *ubuf = (void __user *)arg;
....
switch (cmd) {
case BINDER_WRITE_READ: {
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto err;
}
/*
第一次拷贝,将ubuf的数据从用户空间拷贝到内核空间bwr中
注意此时的ubuf表示的是binder_write_read数据结构,即把它从“用户空间”拷贝到“内核空间”
*/
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto err;
}
if (bwr.write_size > 0) {
//继续
ret = binder_thread_write(proc, thread, bwr.write_buffer, bwr.write_size, &bwr.write_consumed);
...
}
...
}
这里我们遇到了第一个copy_from_user()调用,通过这个调用会把用户空间的bwr指向的数据给拷贝到内核空间中。通过前面章节1.6我们知道copy_from_user()的第一个入参是拷贝的目标地址,这里给的是&bwr,bwr是binder_write_read 的实例对象,是对Binder传输数据的最外层封装 ,所以此时还是没有和服务端被映射的内存扯上关系。
难道我们这么快就找到了Binder框架实现中被重点强调的"一次拷贝"吗?大家不要高兴的这么早吗,不然我这篇博客不就要和读者说再见了吗。
此处的从用户空间拷贝到内核空间的数据bwr是前面我们在用户空间封装的协议的最外层,并不是发送端进程真正要传递的数据,它封装的是一些传入协议,如果真的要说bwr中携带了要传递的数据那也就是存储了指向binder_transaction_data的指针信息(这里或者换另外一种说法,就是对于Binder传递的数据内核中是分段多次拷贝的所以给人造成一种感觉是有执行了多次拷贝,有点像我们实际生活中多多餐少食和一餐多食其实吃的食量是一样的!)。
上述读者一定要悟透,搞懂。不然会有一种越学越糊涂的感觉,尼玛内核中不止一次拷贝啊!
接下来就进入binder_thread_write。其中涉及到数据传入的参数bwr.write_buffer,这里我们需要重点关心的是write_buffer数据的指向,它指向的是那里,指向的是用户空间的binder_transaction_data实例对象tr。
binder_thread_write
//[kernel/drivers/staging/android/binder.c]
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error == BR_OK) {
//从用户空间获取write_buffer指向的内存数据
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
...
switch (cmd) {
...
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
//这里又来了一次拷贝
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
binder_transaction(proc, thread, &tr, cmd == BC_REPLY);
break;
}
...
}
}
}
内核层怎么对传入数据的解析这里我们就不分析了,在上述源码中我们遇到了第二个copy_from_user(),通过这次拷贝会把用户空间的那个tr,也就是IPCThreadState.mOut,给拷贝到内核中来(注意此时binder_transaction_data并没有真正的存储要传输“”实际数据“”,它也是对Binder数据的一层封装而已,它的data指针指向了真正的数据),所以此时还是没有和服务端被映射的内存扯上关系,我们继续往下分析binder_transaction()函数,看看它的处理流程。
binder_transaction函数
//[kernel/drivers/staging/android/binder.c]
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply)
{
//Binder事物
struct binder_transaction *t;
...
t->sender_euid = proc->tsk->cred->euid;
t->to_proc = target_proc;//事物的目标进程
t->to_thread = target_thread;//事物的目标线程
t->code = tr->code;//事物代码
t->flags = tr->flags;
t->priority = task_nice(current);//线程的优先级的迁移
trace_binder_transaction(reply, t, target_node);
t->buffer = binder_alloc_buf(target_proc, tr->data_size,//从target进程的binder内存空间分配所需的内存大小(tr->data_size+tr->offsets_size),并且分配好的空间是已经被映射好的
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
if (t->buffer == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_alloc_buf_failed;
}
t->buffer->allow_user_free = 0;
t->buffer->debug_id = t->debug_id;
t->buffer->transaction = t;//该binder_buffer对应的事务
t->buffer->target_node = target_node;//该事物对应的目标binder实体
offp = (binder_size_t *)(t->buffer->data +
ALIGN(tr->data_size, sizeof(void *)));
if (copy_from_user(t->buffer->data, (const void __user *)(uintptr_t)
tr->data.ptr.buffer, tr->data_size)) {
...
}
if (copy_from_user(offp, (const void __user *)(uintptr_t)
tr->data.ptr.offsets, tr->offsets_size)) {
...
}
off_end = (void *)offp + tr->offsets_size;
...
}
这里牵涉到Binder事物传递流程,我们知道在进行Binder事物的传递时,如果一个Binder事物(用struct binder_transaction结构体表示需要使用到内存,就会调用binder_alloc_buf函数分配此次Binder事物需要的内存空间(并且这里我们需要注意它的第一个参数target_proc,此时binder_alloc_buf会从前面服务端进程的内存映射好的空间中划分出一块分配好的内存出来,然后t->buffer就指向这块有映射的内存,此处是关键所在这块牵涉的逻辑比较多,我们不纠结于此,感兴趣的可以参见博客Android Binder 分析——内存管理)。
接下来可以看到这里调用了两次的copy_from_user()函数:
- 其中一次是copy parcel的data数据操作,此次就是把发起方用户空间的数据直接拷贝到了接收方内核的内存映射中,这就是所谓“一次拷贝”的关键点(而这也是我认为Android所宣传的一次拷贝的核心点)
- 另外一次copy parcel里flat_binder_object的偏移地址的数据(这次拷贝的数据体量上来讲与前面一次拷贝数据的体量相比不是主要矛盾),所以这里我们就将就认为"一次拷贝"就指代这里吧。这里就把发送端进程从用户空间传递过来的数据(parcel 打包)copy到内核空间了。而且这个内核空间的内存是接收服务端端提供的,更加重要的是这个块内核空间还和接收端进程的 的用户空间共同映射到了同一块物理内存上了,这样接收端就不需要再进行一次拷贝将数据从内核空间拷贝到用户空间了
上述流程处理完毕之后,Binder驱动内核空间会将该次事物放到接收端线程所在的todo列表中,然后唤醒接收端目标线程对传输的数据进行下一步处理。我们也接着继续跟进下看看服务端进程是怎么对发送端发过来的数据处理。
3.4 服务(接收)端进程数据传输过程
我们知道Binder服务端进程在添加Binder服务到servicemanager进程以后,会开启loop循环然后阻塞在binder_thread_read函数中的thread->wait等待队列上的目标线程,由于此时有事物的到来会被被唤醒,唤醒后从自己的thread->todo双向列表中取出在binder_transaction()函数放入到该队列的事务(struct binder_transaction),并用这个结构体来初始化struct binder_transaction_data结构体(关于此处不清楚的可以参见博客 Android Binder框架实现之Binder服务的消息循环)。
3.4.1 服务(接收端)内核空间对传输数据的处理
如果说前面发送的流程是从用户空间通过系统调用到内核空间,那么接收端则是相反的是先从内核空间开始处理的,这里我们来看下接收端进程内核中的处理流程,即调用binder_thread_read读取数据。
binder_thread_read
//[kernel/drivers/staging/android/binder.c]
static int binder_thread_read(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed, int non_block)
{
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
...
tr.data_size = t->buffer->data_size;//事物对应的数据的大小
tr.offsets_size = t->buffer->offsets_size;
//得到事物对应的内核数据在用户空间的访问地址
tr.data.ptr.buffer = (binder_uintptr_t)(
(uintptr_t)t->buffer->data +
proc->user_buffer_offset);
//得到事务对应的数据在用户空间的访问地址
tr.data.ptr.offsets = tr.data.ptr.buffer +
ALIGN(t->buffer->data_size,
sizeof(void *));
if (put_user(cmd, (uint32_t __user *)ptr))//拷贝返回命令
return -EFAULT;
ptr += sizeof(uint32_t);
//注意:只是拷贝了命令对应的固定大小的tr参数,并没有拷贝tr.data.ptr.buffer指向的内容
if (copy_to_user(ptr, &tr, sizeof(tr)))
return -EFAULT;
...
}
这里我们遇到了第一个copy_to_user()调用,这里是把前面发送端进程传递过来的事物binder_transaction_data实例对象tr给拷贝到接收方的用户空间的binder_write_read.read_buffer中(在此之前把内核映射的数据地址指针转换为用户空间的指针赋值给tr.data.ptr.buffer),所以此时我们的接收端进程的用户空间可以直接使用tr.data.ptr.buffer的值就可以访问到远端传递过来的数据,而不需要继续做拷贝动作将内核的数据通过copy_to_user来拷贝到用户空间,同样的道理用户空间直接使用tr.data.ptr.offsets的值就可以直接访问binder对象的偏移数组。
此处接收端进程可以和前面发送端进程拷贝进行对比!
对于发送端进程需要从用户空间向内核空间拷贝如下四个数据:
1. binder_write_read
2. binder_transaction_data
3. copy parcel的data数据操作
4. copy parcel里flat_binder_object的偏移地址的数据
而对于接收端进程而言,只要进行前面两次拷贝就OK了,后面两个通过内存映射的方式省去了
接着接收端进程从binder_thread_read函数中返回,调用binder_ioctl方法继续下一步的处理,我们接着往下看。
binder_ioctl
//[kernel/drivers/staging/android/binder.c]
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
...
void __user *ubuf = (void __user *)arg;
....
switch (cmd) {
case BINDER_WRITE_READ: {
if (bwr.read_size > 0) {
//接收端进程调用binder_thread_read
ret = binder_thread_read(proc, thread, bwr.read_buffer, bwr.read_size, &bwr.read_consumed, filp->f_flags & O_NONBLOCK);
...
}
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto err;
}
...
}
在这里我们看到了第二个copy_to_user(),它的功能主要是将把内核空间的bwr拷贝回用户空间的ubuf中(注意此时bwr内包含指向tr的指针,也就是bwr.read_buffer是指向这个tr,或者说IPCThreadState.mIn)。如上流程执行完毕以后就会回到接收端的用户空间接着调用IPCThreadState::executeCommand执行下一步的处理逻辑。
3.4.1 服务(接收端)用户空间对传输数据的处理
这里没有啥好说的了,直接上源码看看IPCThreadState::executeCommand的处理逻辑,如下:
IPCThreadState::executeCommand
//[IPCThreadState.cpp]
status_t IPCThreadState::executeCommand(int32_t cmd)
{
...
case BR_TRANSACTION:
{
binder_transaction_data tr;
result = mIn.read(&tr, sizeof(tr));
...
Parcel buffer;
buffer.ipcSetDataReference(
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), freeBuffer, this);
...
error = reinterpret_cast<BBinder*>(tr.cookie)->transact(tr.code, buffer, &reply, tr.flags);
}
...
}
这里首先把binder_transaction_data从mIn里面读出来。然后就直接就把内存映射过来的指针tr.data.ptr.buffer也就是那“一次拷贝”过来的地址赋值给给buffer这个Parcel。这样后续的实体Binder就可以调用transact来处理发起方传过来的数据了。至此Android Binder通信的"一次拷贝"的原理到这里就结束了。