【数据分析-学术前沿趋势分析】 Task1 论文数据统计
task1 论文数据统计
- 1. 任务说明
- 2. 数据集介绍
- 3. 代码实现
-
- 3.1 导入包并读取原始数据
- 3.2 数据预处理
- 3.2数据分析及可视化
Datawhale一月份的组队学习~
关键词:数据分析、爬虫、文本分析
开源地址: https://github.com/datawhalechina/team-learning-data-mining/tree/master/AcademicTrends
1. 任务说明
- 任务主题:论文数量统计,即统计2019年全年计算机各个方向论文数量;
- 任务内容:赛题的理解、使用 Pandas 读取数据并进行统计;
- 任务成果:学习 Pandas 的基础操作;
- 可参考的学习资料:开源组织Datawhale joyful-pandas项目
2. 数据集介绍
- 数据集来源https://www.kaggle.com/Cornell-University/arxiv
- 数据集格式如下,主要包括论文id、论文提交者、作者等
| 名称 | 含义 |
|---|---|
id |
arXiv ID,可用于访问论文 |
submitter |
论文提交者 |
authors |
论文作者 |
title |
论文标题 |
comments |
论文页数和图表等其他信息 |
journal-ref |
论文发表的期刊的信息 |
doi |
数字对象标识符,https://www.doi.org; |
report-no |
报告编号 |
categories |
论文在 arXiv 系统的所属类别或标签 |
license |
文章的许可证 |
abstract |
论文摘要 |
versions |
论文版本 |
authors_parsed |
作者的信息 |
例如:
"root":{
"id":string"0704.0001"
"submitter":string"Pavel Nadolsky"
"authors":string"C. Bal\'azs, E. L. Berger, P. M. Nadolsky, C.-P. Yuan"
"title":string"Calculation of prompt diphoton production cross sections at Tevatron and LHC energies"
"comments":string"37 pages, 15 figures; published version"
"journal-ref":string"Phys.Rev.D76:013009,2007"
"doi":string"10.1103/PhysRevD.76.013009"
"report-no":string"ANL-HEP-PR-07-12"
"categories":string"hep-ph"
"license":NULL
"abstract":string" A fully differential calculation in perturbative quantum chromodynamics is presented for the production of massive photon pairs at hadron colliders. All next-to-leading order perturbative contributions from quark-antiquark, gluon-(anti)quark, and gluon-gluon subprocesses are included, as well as all-orders resummation of initial-state gluon radiation valid at next-to-next-to leading logarithmic accuracy. The region of phase space is specified in which the calculation is most reliable. Good agreement is demonstrated with data from the Fermilab Tevatron, and predictions are made for more detailed tests with CDF and DO data. Predictions are shown for distributions of diphoton pairs produced at the energy of the Large Hadron Collider (LHC). Distributions of the diphoton pairs from the decay of a Higgs boson are contrasted with those produced from QCD processes at the LHC, showing that enhanced sensitivity to the signal can be obtained with judicious selection of events."
"versions":[
0:{
"version":string"v1"
"created":string"Mon, 2 Apr 2007 19:18:42 GMT"
}
1:{
"version":string"v2"
"created":string"Tue, 24 Jul 2007 20:10:27 GMT"
}]
"update_date":string"2008-11-26"
"authors_parsed":[
0:[
0:string"Balázs"
1:string"C."
2:string""]
1:[
0:string"Berger"
1:string"E. L."
2:string""]
2:[
0:string"Nadolsky"
1:string"P. M."
2:string""]
3:[
0:string"Yuan"
1:string"C. -P."
2:string""]]
}
- arxiv论文类别介绍
arxiv论文的类别经查阅共153种
查询网址:
https://arxiv.org/help/api/user-manual
https://arxiv.org/category_taxonomy
部分展示如下
'astro-ph': 'Astrophysics',
'astro-ph.CO': 'Cosmology and Nongalactic Astrophysics',
'astro-ph.EP': 'Earth and Planetary Astrophysics',
'astro-ph.GA': 'Astrophysics of Galaxies',
'cs.AI': 'Artificial Intelligence',
'cs.AR': 'Hardware Architecture',
'cs.CC': 'Computational Complexity',
'cs.CE': 'Computational Engineering, Finance, and Science',
'cs.CV': 'Computer Vision and Pattern Recognition',
'cs.CY': 'Computers and Society',
'cs.DB': 'Databases',
'cs.DC': 'Distributed, Parallel, and Cluster Computing',
'cs.DL': 'Digital Libraries',
'cs.NA': 'Numerical Analysis',
'cs.NE': 'Neural and Evolutionary Computing',
'cs.NI': 'Networking and Internet Architecture',
'cs.OH': 'Other Computer Science',
'cs.OS': 'Operating Systems',
3. 代码实现
3.1 导入包并读取原始数据
【相关资料】
- BeautifulSoup:python bs4 之 BeautifulSoup 爬虫使用
- request:数据爬虫(三):python中requests库使用方法详解
- json:菜鸟教程python:json
import seaborn as sns #用于画图
from bs4 import BeautifulSoup #爬虫,用于爬取arxiv的数据,相关资料见https://blog.csdn.net/guoxinjie17/article/details/80519547
import re #用于正则表达式,匹配字符串的模式
import requests #用于网络连接,发送网络请求,使用域名获取对应的信息
import json #读取数据,此处数据位json格式的
import pandas as pd
import matplotlib.pyplot as plt
import tqdm
#读入数据
data=[]
#使用with语句读入
##使用with语句读入的优势:(1)自动关闭文件句柄(2)自动显示(处理)文件读取异常
###https://blog.csdn.net/qq_38684504/article/details/86547340
with open('./archive/arxiv-metadata-oai-snapshot.json','r') as f:
for idx,line in enumerate(f):
#读取前一百行,如果读取全部数据需要8G内存
if idx>100:
break
data.append(json.loads(line))
#将data转换为pandas格式,方便进行pandas分析
data=pd.DataFrame(data)
print(data.shape)
data.head()

#定义文件读取函数,方便直接进行读取
def readArxivFile(path, columns=['id', 'submitter', 'authors', 'title', 'comments', 'journal-ref', 'doi',
'report-no', 'categories', 'license', 'abstract', 'versions',
'update_date', 'authors_parsed'], count=None):
'''
定义读取文件的函数
path: 文件路径
columns: 需要选择的列
count: 读取行数
'''
data = []
with open(path, 'r') as f:
for idx, line in enumerate(f):
if idx == count:
break
d = json.loads(line)
d = {
col : d[col] for col in columns}
data.append(d)
data = pd.DataFrame(data)
return data
#利用函数实现读取,这里只读取了其中三列
data = readArxivFile('./archive/arxiv-metadata-oai-snapshot.json', ['id', 'categories', 'update_date'])
print(data.shape)
data.head()

#占用内存为41.1M
data.info()

3.2 数据预处理
- 使用
describe:对数据做初步的统计count:一列数据的元素个数;unique:一列数据中元素的种类;top:一列数据中出现频率最高的元素;freq:一列数据中出现频率最高的元素的个数;
data['categories'].describe()

通过结果可以看出共有1338381个数据,有61371个子类(因为可能存在一篇论文对应多个类别的情况),其中最多的种类是astro-ph,即Astrophysics(天体物理学),共出现了86914次
由于部分论文的类别不止一种,下面判断下本数据集中共出现了多少种独立的数据集
#可以看出来具有多个类别的是用空格进行分割
data['categories'].sample(5)

-
使用split 函数将多类别使用 “ ”(空格)分开,组成list,并使用 for 循环将独立出现的类别找出来,并使用 set 类别,将重复项去除得到最终所有的独立paper种类。
-
set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等
#set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等
unique_categories=set([i for l in [x.split(' ') for x in data['categories']]for i in l])
print(len(unique_categories))
unique_categories

从以上结果发现,共有176种论文种类,比直接从 https://arxiv.org/help/api/user-manual 的 5.3 小节的 Subject Classifications 的部分或 https://arxiv.org/category_taxonomy中的到的类别少,这说明存在一些官网上没有的类别,。不过对于我们的计算机方向的论文没有影响,依然是以下的40个类别,我们从原数据中提取的和从官网的到的种类是可以一一对应的。
我们的任务是对2019年以后的paper进行分析,所以要先对时间特征进行处理,以得到2019年以后的论文
#提取年份
data['year']=pd.to_datetime(data['update_date']).dt.year #将update_date转化为datetime格式,并提取年份
del data['update_date'] #删除
data=data[data['year']>=2019] #提取出2019年以后的数据
data.reset_index(drop=True,inplace=True) #进行重新编号
data.head()
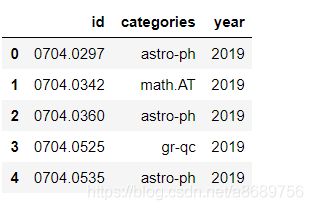
通过上面的步骤已经得到了2019年以后的所有论文,下面从原网页中选出出计算机类的论文
网址中样子,要想提取所有计算机论文小类的名字需要用到爬虫和正则化
正则化介绍 使用re.sub用来替换字符中的匹配项
re.sub(pattern,repl,string,count=0.flags=0)
- pattern:正则中的模式字符串
- repl:替换的字符串,也可以是一个函数
- string:要被查找替换的原始字符串
- count:模式匹配后的最大次数,默认为0,代表替换所有的匹配
- flags:编译时用的匹配模式,数字形式
- 其中pattern、repl、string为必选参数 正则表达式相关用法https://www.runoob.com/python3/python3-reg-expressions.html
正则表达式测试网站https://tool.oschina.net/regex/
#re.sub的例子
phone='2004-959-559 # 这是一个电话号码'
#删除注释
#.匹配任意字符,除了换行符
#$匹配字符串的末尾
#*匹配0个或多个的表达式
num=re.sub(r'#.*$','',phone)#在phone中用空白来替换#后面的东西
print ("电话号码 : ", num)
#移除非数字的内容
num = re.sub(r'\D', "", phone) #\D匹配任意非数字
print ("电话号码 : ", num)

查看下源文件的代码

对于我们的代码来说只要是实现如下功能
#\2匹配第2个分组的内容
re.sub(r"(.*)\((.*)\)",r"\2", " Astrophysics(astro-ph)")
其中
- 正则中的模式字符串 pattern 的格式为 “任意字符” + “(” + “任意字符” + “)”。
- 替换的字符串 repl 为第2个分组的内容。
- 要被查找替换的原始字符串 string 为原始的爬取的数据。
完整的代码为
#爬取所有的类别
website_url = requests.get('https://arxiv.org/category_taxonomy').text #获取网页的文本数据
soup = BeautifulSoup(website_url,'lxml') #爬取数据,这里使用lxml的解析器,加速
root = soup.find('div',{
'id':'category_taxonomy_list'}) #找出 BeautifulSoup 对应的标签入口
tags = root.find_all(["h2","h3","h4","p"], recursive=True) #读取 tags
#初始化str和list变量
level_1_name=''
level_2_name=''
level_2_code=''
level_1_names = []
level_2_codes = []
level_2_names = []
level_3_codes = []
level_3_names = []
level_3_notes = []
#进行
for t in tags:
if t.name == "h2":
level_1_name = t.text
level_2_code = t.text
level_2_name = t.text
elif t.name == "h3":
raw = t.text
level_2_code = re.sub(r"(.*)\((.*)\)",r"\2",raw) #正则表达式:模式字符串:(.*)\((.*)\);被替换字符串"\2";被处理字符串:raw
level_2_name = re.sub(r"(.*)\((.*)\)",r"\1",raw)
elif t.name == "h4":
raw = t.text
level_3_code = re.sub(r"(.*) \((.*)\)",r"\1",raw)
level_3_name = re.sub(r"(.*) \((.*)\)",r"\2",raw)
elif t.name == "p":
notes = t.text
level_1_names.append(level_1_name)
level_2_names.append(level_2_name)
level_2_codes.append(level_2_code)
level_3_names.append(level_3_name)
level_3_codes.append(level_3_code)
level_3_notes.append(notes)
#根据以上信息生成dataframe格式的数据
df_taxonomy = pd.DataFrame({
'group_name' : level_1_names,
'archive_name' : level_2_names,
'archive_id' : level_2_codes,
'category_name' : level_3_names,
'categories' : level_3_codes,
'category_description': level_3_notes
})
df_taxonomy

3.2数据分析及可视化
查看大类中paper的分布,这里使用merge函数,以两个dataframe的共同属性categories进行合并,以group_name作为类别进行统计,统计结果放入’id’中并排序
df_taxonomy.head(1)

data.head(1)

可以看出来共同的列是categories,下面进行合并
#进行合并
_df=data.merge(df_taxonomy,on='categories',how='left')
print(_df.shape)
_df.head(5)
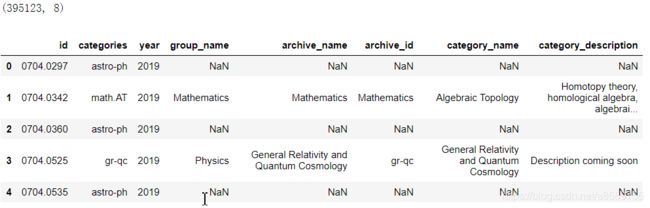
#过滤掉重复的
_df=_df.drop_duplicates(['id','group_name'])
print(_df.shape)
#按照group_name进行类别统计
_df=_df.groupby('group_name').agg({
'id':'count'}).sort_values(by='id',ascending=False).reset_index()
_df

使用饼图进行可视化,相关参数如下
| 参数 | 含义 |
|---|---|
| x | (每一块)的比例,如果sum(x) > 1会使用sum(x)归一化; |
| labels | (每一块)饼图外侧显示的说明文字; |
| explode | (每一块)离开中心距离; |
| startangle | 起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起; |
| shadow | 在饼图下面画一个阴影。默认值:False,即不画阴影; |
| labeldistance | label标记的绘制位置,相对于半径的比例,默认值为1.1, 如<1则绘制在饼图内侧; |
| autopct | 控制饼图内百分比设置,可以使用format字符串或者format function '%1.1f’指小数点前后位数(没有用空格补齐); |
| pctdistance | 类似于labeldistance,指定autopct的位置刻度,默认值为0.6; |
| radius | 控制饼图半径,默认值为1;counterclock :指定指针方向;布尔值,可选参数,默认为:True,即逆时针。将值改为False即可改为顺时针。wedgeprops :字典类型,可选参数,默认值:None。参数字典传递给wedge对象用来画一个饼图。例如:wedgeprops={‘linewidth’:3}设置wedge线宽为3。 |
| textprops | 设置标签(labels)和比例文字的格式;字典类型,可选参数,默认值为:None。传递给text对象的字典参数。 |
| center | 浮点类型的列表,可选参数,默认值:(0,0)。图标中心位置。 |
| frame | 布尔类型,可选参数,默认值:False。如果是true,绘制带有表的轴框架。 |
| rotatelabels | 布尔类型,可选参数,默认为:False。如果为True,旋转每个label到指定的角度。 |
fig=plt.figure(figsize=(15,12))
#设置距离中心的距离,一共有八块,为了方便后面几块显示
explode=(0,0,0,0.2,0.3,0.3,0.2,0.1)
plt.pie(_df["id"], labels=_df["group_name"], autopct='%1.2f%%', startangle=160, explode=explode)
plt.tight_layout() #自动调整函数,tight_layout会自动调整子图参数,使之填充整个图像区域
plt.show()

下面统计在计算机各个子领域2019年后的paper数量,我们同样使用 merge 函数,对于两个dataframe 共同的特征 categories 进行合并并且进行查询。然后我们再对于数据进行统计和排序从而得到以下的结果:
#查询计算机领域的
group_name='Computer Science'
cats=data.merge(df_taxonomy,on='categories').query('group_name==@group_name')
cats.head()
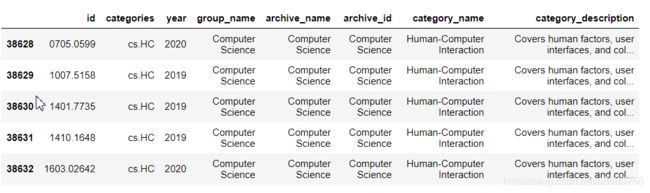
cats.groupby(['year','category_name']).count()
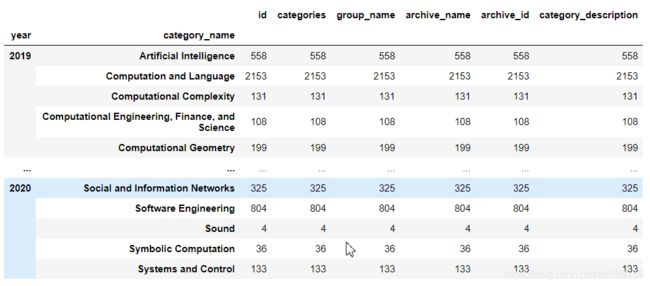
cats.groupby(["year","category_name"]).count().reset_index()

cats.groupby(["year","category_name"]).count().reset_index().pivot(index='category_name',
columns='year',
values='id')

从结果看出
- Computer Vision and Pattern Recognition(计算机视觉与模式识别)类是CS中paper数量最多的子类,遥遥领先于其他的CS子类,并且paper的数量还在逐年增加
- Computation and Language(计算与语言)、Cryptography and Security(密码学与安全)以及 Robotics(机器人学)的2019年paper数量均超过1000或接近1000,也是几大热门方向,符合我们认知