这是关于为我们将要定义的新语言创建基于浏览器的编辑器的教程。
我们将使用两个组件:
- Monaco :它是一个很棒的基于浏览器的编辑器(或一个Web编辑器:如您所愿)
- ANTLR :这是我们喜欢用来构建各种解析器的解析器生成器
我们将为一种简单的语言构建一个编辑器以执行计算。 结果将是这样的:
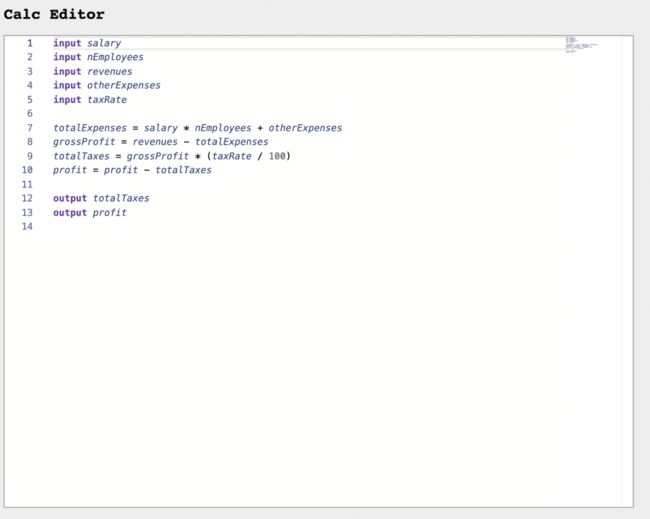
所有代码均可在线获得: calc-monaco-editor 。
前段时间,我们写了一篇文章,关于在浏览器中使用ANTLR构建简单的Web编辑器 。 我们在下一步的基础上继续进行这项工作,使其适应NPM和WebPack的使用,从而使构建应用程序变得更加容易。
为什么要使用摩纳哥?
摩纳哥衍生自Visual Studio Code(VSCode,为其朋友)。 VSCode是一个轻量级的编辑器,正在吸引越来越多的用户。 摩纳哥基本上将VSCode重新打包以在浏览器中运行。 它是一款出色的编辑器,具有许多有趣的功能,维护得当,并根据许可的开源许可证(MIT许可证)发布。
为什么要使用ANTLR?
ANTLR是一种工具,给定语法可以生成多种目标语言的相应解析器。 除其他外,还支持Java,C#,Python和Javascript。 另一个附加价值是ANTLR有几种语法可用。 因此,如果您学习如何将Monaco和ANTLR结合使用,则可以轻松地在Monaco中获得对您可以找到ANTLR语法的任何语言的支持。 我们提供了有关ANTLR的大量资料,从我们的免费ANTLR Mega教程到一个视频课程, 像专业人士一样学习ANTLR 。
我们的样本项目
让我们修改一下如何组织项目:
- 在此项目中,我们将使用NPM下载依赖项,例如ANTLR运行时
- 我们将使用gradle调用ANTLR工具,该工具将从语法定义中为我们的语言生成Javascript解析器
- 我们将使用TypeScript编写代码。 我们的代码会将ANTLR连接到摩纳哥
- 我们将使用WebPack将Javascript打包在一个文件中
- 我们将使用Mocha编写单元测试
- 我们将使用Kotlin和ktor框架编写一个更简单的服务器。 只要有机会,我就可以选择与Kotlin一起使用,这可以由任何服务器代替。
我们简单的计算语言
我们的语言会非常简单。 它只允许执行非常简单的计算。 这是有意的,但是相同的方法可以用于非常复杂的语言。
我们将能够编写如下代码:
input a
b = a * 2
c = (a - b) / 3
output c实际上,我们的语言将允许定义:
- 输入:它们是计算器要接收的值
- 计算:可以计算新值并将其存储在变量中。 可以从输入或其他变量中计算得出
- 输出:我们确定要作为计算结果返回的变量
编写解析器
首先,我们将从定义词法分析器和解析器的语法开始。
我们将创建目录src/main/antlr并在该目录内定义文件CalcLexer.g4和CalcParser.g4 。
我们不会从头开始解释如何编写ANTLR语法。 如果您不熟悉ANTLR,可以从ANTLR Mega Tutorial开始。 但是,我们有一些针对此用例的注释,特别是在词法分析器上。
- 我们不应该跳过空格,而应该将这些标记插入特定的频道,因为所有标记都将与语法突出显示相关。
- 另外,词法分析器应将每个字符都归因于令牌,这就是为什么我们在词法分析器末尾添加特殊规则以捕获任何其他词法分析器规则未捕获的字符的原因。
- 为简单起见,我们应避免标记跨越多行或使用词法模式,因为它们会使与摩纳哥的集成更难于语法突出显示。 这些是我们可以解决的问题(并且可以解决客户的项目),但我们不想在本教程中解决它们,因为它们会使您更加难以理解基础知识
这是我们的词法分析器语法( CalcLexer.g4 ):
lexer grammar CalcLexer;
channels { WS_CHANNEL }
WS: [ \t]+ -> channel(WS_CHANNEL);
NL: ('\r\n' | '\r' | '\n') -> channel(WS_CHANNEL);
INPUT_KW : 'input' ;
OUTPUT_KW : 'output' ;
NUMBER_LIT : ('0'|[1-9][0-9]*)('.'[0-9]+)?;
ID: [a-zA-Z][a-zA-Z0-9_]* ;
LPAREN : '(' ;
RPAREN : ')' ;
EQUAL : '=' ;
MINUS : '-' ;
PLUS : '+' ;
MUL : '*' ;
DIV : '/' ;
UNRECOGNIZED : . ; 这是我们的解析器语法( CalcParser.g4 ):
parser grammar CalcParser;
options { tokenVocab=CalcLexer; }
compilationUnit:
(inputs+=input)*
(calcs+=calc)*
(outputs+=output)*
EOF
;
input:
INPUT_KW ID
;
output:
OUTPUT_KW ID
;
calc:
target=ID EQUAL value=expression
;
expression:
NUMBER_LIT
| ID
| LPAREN expression RPAREN
| expression operator=(MUL|DIV) expression
| expression operator=(MINUS|PLUS) expression
| MINUS expression
;现在我们有了语法,我们需要从中生成Javascript词法分析器。 为此,我们将需要使用ANTLR工具。 对我而言,最简单的方法是使用gradle下载ANTLR及其依赖项,并在gradle中定义任务以调用ANTLR。
我们将通过运行以下命令安装gradle包装器:
gradle wrapper --gradle-version=5.6.1 --distribution-type=bin build.gradle脚本将如下所示:
apply plugin: 'java'
repositories {
jcenter()
}
dependencies {
runtime 'org.antlr:antlr4:4.7.2'
}
task generateLexer(type:JavaExec) {
def lexerName = "CalcLexer"
inputs.file("$ANTLR_SRC/${lexerName}.g4")
outputs.file("$GEN_JS_SRC/${lexerName}.js")
outputs.file("$GEN_JS_SRC/${lexerName}.interp")
outputs.file("$GEN_JS_SRC/${lexerName}.tokens")
main = 'org.antlr.v4.Tool'
classpath = sourceSets.main.runtimeClasspath
args = ['-Dlanguage=JavaScript', "${lexerName}.g4", '-o', '../../main-generated/javascript']
workingDir = ANTLR_SRC
}
task generateParser(type:JavaExec) {
dependsOn generateLexer
def lexerName = "CalcLexer"
def parserName = "CalcParser"
inputs.file("$ANTLR_SRC/${parserName}.g4")
inputs.file("$GEN_JS_SRC/${lexerName}.tokens")
outputs.file("$GEN_JS_SRC/${parserName}.js")
outputs.file("$GEN_JS_SRC/${parserName}.interp")
outputs.file("$GEN_JS_SRC/${parserName}.tokens")
main = 'org.antlr.v4.Tool'
classpath = sourceSets.main.runtimeClasspath
args = ['-Dlanguage=JavaScript', "${parserName}.g4", '-no-listener', '-no-visitor', '-o', '../../main-generated/javascript']
workingDir = ANTLR_SRC
} 它使用gradle.properties文件中定义的一些属性:
ANTLR_SRC = src/main/antlr
GEN_JS_SRC = src/main-generated/javascript 实际上,这将使用src/main/antlr下的语法来生成src/main-generated/javascript下的词法分析器。
我们可以运行ANTLR:
./gradlew generateParser 这也将产生词法分析器,作为任务generateParser任务对任务的依赖性generateLexer 。
运行此命令后,您应该将这些文件放在src/main-generated/javascript :
- CalcLexer.interp
- CalcLexer.js
- CalcLexer.tokens
- CalcParser.interp
- CalcParser.js
- CalcParser.tokens
使用NPM管理依赖项
为了运行我们的词法分析器和解析器,我们需要做两件事:生成的Javascript代码和ANTLR运行时。 为了获得ANTLR运行时,我们将使用NPM。 NPM也将用于下载摩纳哥。 因此,我们不会为项目运行Node.JS,我们只会使用它来获取依赖关系并运行测试。
我们将假定您已经在系统上安装了npm。 如果您不满意,那么就该打谷歌并弄清楚如何安装它。
安装npm后,我们需要通过填充package.json文件来提供项目配置:
{
"name": "calc-monaco-editor",
"version": "0.0.1",
"author": "Strumenta",
"license": "Apache-2.0",
"repository": "https://github.com/Strumenta/calc-monaco-editor",
"dependencies": {
"antlr4": "^4.7.2",
"webpack": "^4.39.2",
"webpack-cli": "^3.3.7"
},
"devDependencies": {
"mocha": "^6.2.0",
"monaco-editor": "^0.17.1"
},
"scripts": {
"test": "mocha"
}
} 至此,我们只需运行npm install就可以安装所需的一切。
现在,你应该已经获得下的ANTLR 4运行node_modules ,与一些其他的东西放在一起。 是的,有很多东西。 是的,您不想手动下载该文件,所以谢谢npm!
编译TypeScript
现在让我们使用生成的词法分析器和解析器编写一些代码。
我们将创建目录src/main/typescript ,并将开始编写一个名为ParserFacade.ts的文件。 在此文件中,我们将编写一些代码来调用并生成词法分析器和解析器,并获取令牌列表。 稍后,我们还将研究获取解析树。
/// 然后,我们需要从Typescript生成Javascript代码。 我们将使用tsc工具在src/main-generated/javascript tsc src/main-generated/javascript下生成它。 要配置它,我们将需要创建tsconfig.json文件。
{
"compilerOptions": {
"module": "CommonJS",
"target": "es5",
"sourceMap": true,
"outDir": "src/main-generated/javascript"
},
"exclude": [
"node_modules"
],
"include" : [
"src/main/typescript"
]
}此时,我们可以简单地运行:
tsc在src / main-generation / javascript下,我们还应该看到以下文件:
- ParserFacade.js
- ParserFacade.js.map
我们如何确保我们的代码有效? 当然,有了单元测试!
编写单元测试
我们将通过创建具有以下内容的test/mocha.opts来配置摩卡:
src/test/javascript
--recursive 现在我们准备编写测试了。 在src/test/javascript我们将创建lexingTest.js :
let assert = require('assert');
let parserFacade = require('../../main-generated/javascript/ParserFacade.js');
let CalcLexer = require('../../main-generated/javascript/CalcLexer.js').CalcLexer;
function checkToken(tokens, index, typeName, column, text) {
it('should have ' + typeName + ' in position ' + index, function () {
assert.equal(tokens[index].type, CalcLexer[typeName]);
assert.equal(tokens[index].column, column);
assert.equal(tokens[index].text, text);
});
}
describe('Basic lexing without spaces', function () {
let tokens = parserFacade.getTokens("a=5");
it('should return 3 tokens', function() {
assert.equal(tokens.length, 3);
});
checkToken(tokens, 0, 'ID', 0, "a");
checkToken(tokens, 1, 'EQUAL', 1, "=");
checkToken(tokens, 2, 'NUMBER_LIT', 2, "5");
});我们可以通过以下方式运行测试:
tsc && npm test
好,我们的项目开始进行到某个地方,我们有办法检查代码的完整性。 生活很好。
现在,我们已经奠定了这些基础,我们可以在ParserFacade编写更多代码。
让我们完成ParserFacade
现在,我们将完成ParserFacade。 特别是,我们将公开一个简单的函数来获取解析树的字符串表示形式。 这对于测试我们的解析器很有用。
/// 现在让我们看看如何测试解析器。 我们在src/test/javascript下创建parsingTest.js :
let assert = require('assert');
let parserFacade = require('../../main-generated/javascript/ParserFacade.js');
function checkToken(tokens, index, typeName, column, text) {
it('should have ' + typeName + ' in position ' + index, function () {
assert.equal(tokens[index].type, CalcLexer[typeName]);
assert.equal(tokens[index].column, column);
assert.equal(tokens[index].text, text);
});
}
describe('Basic parsing of empty file', function () {
assert.equal(parserFacade.parseTreeStr(""), "(compilationUnit )")
});
describe('Basic parsing of single input definition', function () {
assert.equal(parserFacade.parseTreeStr("input a"), "(compilationUnit (input input a) )")
});
describe('Basic parsing of single output definition', function () {
assert.equal(parserFacade.parseTreeStr("output a"), "(compilationUnit (output output a) )")
});
describe('Basic parsing of single calculation', function () {
assert.equal(parserFacade.parseTreeStr("a = b + 1"), "(compilationUnit (calc a = (expression (expression b) + (expression 1))) )")
});
describe('Basic parsing of simple script', function () {
assert.equal(parserFacade.parseTreeStr("input i\no = i + 1\noutput o"), "(compilationUnit (input input i) (calc o = (expression (expression i) + (expression 1))) (output output o) )")
}); 和欢呼! 我们的测试通过了。
好的,我们有一个词法分析器,还有一个解析器。 两者似乎都可以正常工作。
现在的重点是:我们现在如何将这些东西与摩纳哥一起使用? 让我们找出答案。
融入摩纳哥
现在,我们将创建一个简单HTML页面,该页面将托管我们的摩纳哥编辑器:
Calc Editor
Calc Editor
此页面将需要:
- 加载摩纳哥代码
- 加载我们将把ANTLR集成到摩纳哥的代码
现在,我们希望将要编写的代码打包到一个Javascript文件中,以更快,更轻松地将Javascript代码加载到浏览器中。 为此,我们将使用webpack:它将检查一个入口文件,找到所有依赖项并将它们打包到一个文件中。
webpack还希望在名为webpack.config.js的文件中进行自己的配置:
module.exports = {
entry: './src/main/javascript/index.js',
output: {
filename: 'main.js',
},
module: {
rules: [{
test: /\.tsx?$/,
use: 'ts-loader',
exclude: /node_modules/
}]
},
resolve: {
modules: ['node_modules'],
extensions: [ '.tsx', '.ts', '.js' ]
},
mode: 'production',
node: {
fs: 'empty',
global: true,
crypto: 'empty',
tls: 'empty',
net: 'empty',
process: true,
module: false,
clearImmediate: false,
setImmediate: false
}
} 我们还需要定义入口点Javascript文件。 我们将在src/main/javascript/index.js下创建它。 现在,我们将其保留为空。
现在运行webpack,我们可以生成dist/main.js文件,将其加载到HTML页面中。
服务文件:我们用Kotlin编写的简单服务器
此时,我们将使用Kotlin设置一个非常简单的Web服务器。 这部分不是那么重要,您可能希望选择其他方法来存储文件。
我们将使用以下build.gradle文件创建一个名为server的子目录:
buildscript {
ext.kotlin_version = '1.3.41'
repositories { jcenter() }
dependencies {
classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlin_version"
classpath "org.jetbrains.kotlin:kotlin-serialization:$kotlin_version"
}
}
plugins {
id 'org.jetbrains.kotlin.jvm' version '1.3.41'
}
apply plugin: 'kotlin'
apply plugin: 'kotlinx-serialization'
repositories {
mavenCentral()
jcenter()
}
ext.ktor_version = "1.2.3"
dependencies {
implementation "org.jetbrains.kotlin:kotlin-stdlib-jdk8"
compile "io.ktor:ktor-server-core:$ktor_version"
compile "io.ktor:ktor-server-netty:$ktor_version"
implementation "io.ktor:ktor-websockets:$ktor_version"
implementation 'com.google.code.gson:gson:2.8.5'
implementation 'org.jetbrains.kotlin:kotlin-test'
implementation 'org.jetbrains.kotlin:kotlin-test-junit'
compile "org.jetbrains.kotlin:kotlin-stdlib:$kotlin_version"
compile "org.jetbrains.kotlinx:kotlinx-serialization-runtime:0.11.1"
}
compileKotlin {
kotlinOptions {
jvmTarget = "1.8"
}
}
compileTestKotlin {
kotlinOptions {
jvmTarget = "1.8"
}
}
task runServer(type:JavaExec) {
main = 'com.strumenta.simpleserver.MainKt'
classpath = sourceSets.main.runtimeClasspath
args = ['8888']
}该脚本指定依赖项,并添加任务以从命令行运行服务器。
服务器的代码很简单:
package com.strumenta.simpleserver
import io.ktor.application.call
import io.ktor.http.ContentType
import io.ktor.http.content.files
import io.ktor.http.content.static
import io.ktor.response.respondText
import io.ktor.routing.get
import io.ktor.routing.routing
import io.ktor.server.engine.embeddedServer
import io.ktor.server.netty.Netty
import java.io.File
fun main(args: Array
) {
val port = if (args.isEmpty()) 8080 else args[0].toInt()
val server = embeddedServer(Netty, port = port) {
routing {
static("css") {
files("../src/main/css")
}
static("js") {
files("../dist")
}
static("node_modules") {
files("../node_modules")
}
get("/") {
try {
val text = File("../src/main/html/index.html").readText(Charsets.UTF_8)
call.respondText(text, ContentType.Text.Html)
} catch (e: Exception) {
e.printStackTrace()
}
}
}
}
server.start(wait = false)
}
此时,我们可以简单地通过运行以下命令从server目录中运行server :
../gradlew runServer 请注意,gradle包装器安装在根目录下,因此我们使用../gradlew而不是通常的./gradlew来运行它。
现在,如果我们在localhost:8888打开浏览器,我们将看到以下内容:

很基本吧? 让我们看看如何改进它。
语法高亮
我们需要添加的第一件事是语法突出显示,即,我们希望以不同的方式呈现不同的标记,以便可以将关键字与标识符区分开,将文字与运算符区分开,依此类推。 尽管此功能非常基本,但是在键入代码时提供反馈非常有用。 当我们突出显示语法时,我们可以浏览一下代码并更快地理解它。 而且感觉很好。
为了增加对语法突出显示的支持,我们将需要更改一些文件:
- 我们将需要编写必要的TypeScript代码
- 我们将需要在
index.js包含该代码 - 我们将需要在
index.html调用新代码,并与摩纳哥进行必要的连接
让我们开始吧。
在ParserFacade.ts我们只会更改一件事:导出createLexer 。
export function createLexer(input: String) {
...
} 我们还将添加另一个TypeScript文件,名为CalcTokensProvider.ts :
/// 关于index.js我们基本上需要导入内容并以可以从HTML页面访问它的方式公开它。 怎么样? 很简单,我们将必要的元素添加到window对象中(如果存在)(并且仅在从浏览器内部访问代码时才存在)。
const CalcTokensProvider = require('../../main-generated/javascript/CalcTokensProvider.js');
if (typeof window === 'undefined') {
} else {
window.CalcTokensProvider = CalcTokensProvider;
} 此时,剩下要做的就是让Monaco意识到我们新的CalcTokensProvider 。 好了,然后设置一些样式,以便我们实际上可以在编辑器中看到不同类型的令牌:
现在我们准备出发了。 我们只需要运行tsc && webpack ,我们应该看到:

如果我们输入一些ANTLR无法识别的标记,则应将其标记为红色:

在这里,您去了:我们将ANTLR词法分析器与摩纳哥结合了起来! 因此,我们有了我们自己的基于浏览器的编辑器的第一部分,以用于我们的新语言!
我有点兴奋,是吗?
错误报告
另一个关键功能是错误报告:我们想在用户编写代码时指出错误。
现在,有不同类型的可能的错误:
- 词汇错误:当某些文本不能被识别为属于任何类型的标记时
- 语法错误:当代码的结构不正确时
- 语义错误:它们取决于语言的性质。 语义错误的示例是未声明变量的用法或涉及不兼容类型的操作。
在我们的情况下:
- 我们没有词法错误,因为我们的词法分析器捕获各种字符。 为此,我们添加了特殊的令牌定义:
unrecognized。 现在,unrecognized在任何语句中使用unrecognized类型的标记,因此它将始终导致语法错误 - 我们有语法错误,我们将向他们展示
- 我们不会在本教程的上下文中考虑语义错误,因为它们需要对解析树进行一些高级处理。 例如,我们应该执行符号解析,以在使用前验证声明的位置使用的所有值。 无论如何,它们都可以以与显示语法错误相同的方式在摩纳哥中显示,它们的计算方式不同,如何计算它们不在本教程的讨论范围之内。
现在,我们将研究在编辑器中报告语法错误。 我们想要获得这样的东西:

现在,我们基本上必须将ANTLR产生的错误与摩纳哥联系起来。 但是,在此之前,我们想稍微重构一下语法。 为什么? 因为我们要强制不同的语句保持一行。 这样,将在更直观的位置发现语法错误。
考虑以下示例:
a = 1 +
b = 3 当前,ANTLR将在第二行报告错误。 为什么? 因为a = 1 +线本身似乎是正确的,所以它缺少要完成的其他元素。 因此,ANTLR从第二行开始,构建了表达式a = 1 + b ,这是正确的。 在这一点上它符合=令牌,并在报告错误=令牌 。 这对于我们的DSL贫穷,简单的用户可能会造成混淆。 我们希望通过使ANTLR在第1行的末尾报告错误来使事情更直观,这表明该行还没有完成。
因此,为了实现这一点,我们首先需要调整一些语法以使换行符有意义。
在Lexer语法中,我们更改了NL定义,删除了将令牌发送到WS通道的操作:
NL: ('\r\n' | '\r' | '\n'); 现在我们必须在解析器语法中考虑NL :
基本上,我们强制每个语句以NL令牌结尾。
eol:
NL
;
input:
INPUT_KW ID eol
;
output:
OUTPUT_KW ID eol
;
calc:
target=ID EQUAL value=expression eol
; 好。 很好 现在让我们看看如何开始从ANTLR收集错误。 我们将首先创建一个表示错误的类,然后添加ANTLR ErrorListener来获取ANTLR报告的错误,并使用它们来创建Error实例。
export class Error {
startLine: number;
endLine: number;
startCol: number;
endCol: number;
message: string;
constructor(startLine: number, endLine: number, startCol: number, endCol: number, message: string) {
this.startLine = startLine;
this.endLine = endLine;
this.startCol = startCol;
this.endCol = endCol;
this.message = message;
}
}
class CollectorErrorListener extends error.ErrorListener {
private errors : Error[] = []
constructor(errors: Error[]) {
super()
this.errors = errors
}
syntaxError(recognizer, offendingSymbol, line, column, msg, e) {
var endColumn = column + 1;
if (offendingSymbol._text !== null) {
endColumn = column + offendingSymbol._text.length;
}
this.errors.push(new Error(line, line, column, endColumn, msg));
}
} 此时,我们可以添加一个名为validate的新函数。 该函数将尝试解析输入,并记录解析时获得的每个错误,仅用于报告它们。 稍后我们可以在编辑器中显示这些错误。
export function validate(input) : Error[] {
let errors : Error[] = []
const lexer = createLexer(input);
lexer.removeErrorListeners();
lexer.addErrorListener(new ConsoleErrorListener());
const parser = createParserFromLexer(lexer);
parser.removeErrorListeners();
parser.addErrorListener(new CollectorErrorListener(errors));
parser._errHandler = new CalcErrorStrategy();
const tree = parser.compilationUnit();
return errors;
}我们快到了,但是有一个警告。 事实是,ANTLR默认会在发现错误后尝试添加或删除令牌以起诉解析。 一般而言,这可以正常工作,但是在我们的情况下,我们不希望ANTLR尝试删除新行。 让我们看看ANTLR如何解析我们的示例:
a = 1 +
b = 3 ANTLR会认识到第1行存在错误,但它认为问题将是额外的换行符。 因此,它将在第1行的末尾报告换行符为错误,然后它将继续假装不存在的情况下进行解析。 此行为由错误策略控制,也就是说,ANTLR如何响应解析错误。 然后它将识别出赋值a = 1 + b并在第2行的等号上报告错误。我们要避免这种情况,并调整ANTLR如何尝试固定输入以进行解析。 我们通过实施ErrorStrategy做到这一点。
class CalcErrorStrategy extends DefaultErrorStrategy {
reportUnwantedToken(recognizer: Parser) {
return super.reportUnwantedToken(recognizer);
}
singleTokenDeletion(recognizer: Parser) {
var nextTokenType = recognizer.getTokenStream().LA(2);
if (recognizer.getTokenStream().LA(1) == CalcParser.NL) {
return null;
}
var expecting = this.getExpectedTokens(recognizer);
if (expecting.contains(nextTokenType)) {
this.reportUnwantedToken(recognizer);
// print("recoverFromMismatchedToken deleting " \
// + str(recognizer.getTokenStream().LT(1)) \
// + " since " + str(recognizer.getTokenStream().LT(2)) \
// + " is what we want", file=sys.stderr)
recognizer.consume(); // simply delete extra token
// we want to return the token we're actually matching
var matchedSymbol = recognizer.getCurrentToken();
this.reportMatch(recognizer); // we know current token is correct
return matchedSymbol;
} else {
return null;
}
}
getExpectedTokens = function(recognizer) {
return recognizer.getExpectedTokens();
};
reportMatch = function(recognizer) {
this.endErrorCondition(recognizer);
};
}实际上,我们只是在说不要假装不存在换行符。 而已。
在这一点上,我们可以编写一些测试:
function checkError(actualError, expectedError) {
it('should have startLine ' + expectedError.startLine, function () {
assert.equal(actualError.startLine, expectedError.startLine);
});
it('should have endLine ' + expectedError.endLine, function () {
assert.equal(actualError.endLine, expectedError.endLine);
});
it('should have startCol ' + expectedError.startCol, function () {
assert.equal(actualError.startCol, expectedError.startCol);
});
it('should have endCol ' + expectedError.endCol, function () {
assert.equal(actualError.endCol, expectedError.endCol);
});
it('should have message ' + expectedError.message, function () {
assert.equal(actualError.message, expectedError.message);
});
}
function checkErrors(actualErrors, expectedErrors) {
it('should have ' + expectedErrors.length + ' error(s)', function (){
assert.equal(actualErrors.length, expectedErrors.length);
});
var i;
for (i = 0; i < expectedErrors.length; i++) {
checkError(actualErrors[i], expectedErrors[i]);
}
}
function parseAndCheckErrors(input, expectedErrors) {
let errors = parserFacade.validate(input);
checkErrors(errors, expectedErrors);
}
describe('Validation of simple errors on single lines', function () {
describe('should have recognize missing operand', function () {
parseAndCheckErrors("o = i + \n", [
new parserFacade.Error(1, 1, 8, 9, "mismatched input '\\n' expecting {NUMBER_LIT, ID, '(', '-'}")
]);
});
describe('should have recognize extra operator', function () {
parseAndCheckErrors("o = i +* 2 \n", [
new parserFacade.Error(1, 1, 7, 8, "extraneous input '*' expecting {NUMBER_LIT, ID, '(', '-'}")
]);
});
});
describe('Validation of simple errors in small scripts', function () {
describe('should have recognize missing operand', function () {
let input = "input i\no = i + \noutput o\n";
parseAndCheckErrors(input, [
new parserFacade.Error(2, 2, 8, 9, "mismatched input '\\n' expecting {NUMBER_LIT, ID, '(', '-'}")
]);
});
describe('should have recognize extra operator', function () {
let input = "input i\no = i +* 2 \noutput o\n";
parseAndCheckErrors(input, [
new parserFacade.Error(2, 2, 7, 8, "extraneous input '*' expecting {NUMBER_LIT, ID, '(', '-'}")
]);
});
});
describe('Validation of examples being edited', function () {
describe('deleting number from division', function () {
let input = "input a\n" +
"b = a * 2\n" +
"c = (a - b) / \n" +
"output c\n";
parseAndCheckErrors(input, [
new parserFacade.Error(3, 3, 14, 15, "mismatched input '\\n' expecting {NUMBER_LIT, ID, '(', '-'}")
]);
});
describe('deleting number from multiplication', function () {
let input = "input a\n" +
"b = a * \n" +
"c = (a - b) / 3\n" +
"output c\n";
parseAndCheckErrors(input, [
new parserFacade.Error(2, 2, 8, 9, "mismatched input '\\n' expecting {NUMBER_LIT, ID, '(', '-'}")
]);
});
describe('adding plus to expression', function () {
let input = "input a\n" +
"b = a * 2 +\n" +
"c = (a - b) / 3\n" +
"output c\n";
parseAndCheckErrors(input, [
new parserFacade.Error(2, 2, 11, 12, "mismatched input '\\n' expecting {NUMBER_LIT, ID, '(', '-'}")
]);
});
});在生产中,我们可能希望采用更高级的方法,以避免在每次按键操作时都进行昂贵的计算。 但是,此方法适用于小型文档。
就是这样! 我们在ANTLR和摩纳哥之间有一个简单但很好的集成。 我们可以从这里开始,为我们的用户构建一个出色的编辑器。
摘要
越来越多的应用程序正在向Web转移。 尽管使用特定工具的专业人员可能希望安装诸如桌面应用程序之类的工具,但仍有许多临时用户或技术不适合的用户,为此提供Web工具非常有意义。
我们已经看到,我们可以构建域专用语言 (DSL),使领域专家可以编写丰富而重要的应用程序。 通过构建高级语言,我们可以使他们自己编写代码变得更加容易。 但是,他们仍然无法使用具有复杂UI的工具,对于组织而言,在计算机上交付IDE有时仍然是一个问题。 对于此用户,基于浏览器的编辑器可能是一个不错的解决方案。
在本教程中,我们看到了如何为文本语言编写语法并将其集成到摩纳哥中以获取语法突出显示和错误报告。 这些是编写编辑器的坚实基础,但是从那里我们应该研究更多类似的东西:
- 语义验证
- 自动补全
- 提供执行代码的方法
- 支持某种形式的版本控制(取决于用户的类型,我们可能希望其不如git复杂!)
因此,仍有工作要做,但我们认为摩纳哥可能是一个很好的解决方案。
附注:如果您发现任何错误或不清楚的地方,请给我写信 。 另外,我总是很想听听您对摩纳哥,ANTLR或其他工具的看法。 请随时与我联系!
翻译自: https://www.javacodegeeks.com/2019/11/writing-a-browser-based-editor-using-monaco-and-antlr.html