动态爬虫(暴力爬虫/selenium)-爬取bilibili直播弹幕(已更新XHR方法)
文章目录
- 前言
- 一、页面分析
- 二、selenium安装与使用
-
- 1.安装库
- 2.下载驱动
- 3.模拟浏览器发出请求并捕获弹幕
- 三、所有代码
-
- 1.导入库
- 2.创建一个BiliLive类并写上构造方法
- 3.创建两个get方法,分别来获得htnl页面和里面的弹幕
- 4. 把新的弹幕列表更新到总体的列表中
- 5.保存弹幕
- 6.跑起来
- 四、(更新)眼瞎作者找到api了
-
- (更新)附上代码
- 运行结果
- 五、总结
前言
上次咱们爬了bilibili的热门视频,今天整点花活,爬一下弹幕
但是爬视频弹幕有很多人都做过了,所以想整一下爬直播的弹幕
话不多说,走起!
一、页面分析
还是老样子,要想获取弹幕,先要抓包来捕获接口
随便打开个直播,然后按F12进入开发者模式
可以发现有一堆请求,但是箭头指的这两个应该是视频推流,跟弹幕关系不大
为了排除干扰,把直播给暂停了试试
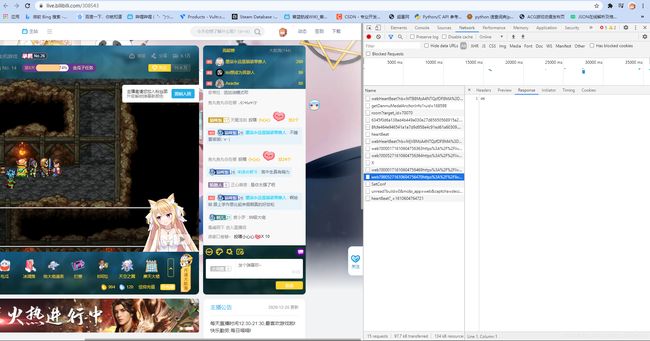
结果是 空空如也
然后我又试了试用Fiddler抓包,也是一样的情况,啥都没有,只能抓到直播的推流
所以我推测,弹幕的交互应该是b站自己写的协议

答案可能藏在这些js里面,看了半天看地头皮发麻
虽然我们没有找到用来请求弹幕的接口,但是我们发现,所有的弹幕都被动态刷新在了前端的html上
如果我们通过网页url拿到前端的html,不就可以拿到弹幕列表了吗?
(ps:你上次不是说网页是动态刷新的,用网页url请求,返回回来的html只是一个框架,里面什么都没有!你这不是打自己脸吗!!)
咳咳,如果我们直接用http请求当然会这样,但是我们不妨换一种思路。
如果我们模拟一个浏览器,让浏览器去执行脚本,刷新页面,我们只需要拿到刷新后的界面就行了!
所以,我使用了selenium库!
二、selenium安装与使用
1.安装库
直接pip就行了:
pip install selenium
2.下载驱动
selenium需要使用浏览器的内核,我用的是chrome的,去这里下载就行
版本选和自己一样的
下载完之后,解压后的exe放到自己的python安装目录
3.模拟浏览器发出请求并捕获弹幕
from selenium import webdriver
import time
import re
url = 'https://live.bilibili.com/308543'
print('正在打开浏览器')
browser = webdriver.Chrome()
browser.get(url)
print('正在读取网页')
# 延时一下
time.sleep(3)
# 得到动态的html
html = browser.page_source
"""
数据模板
"""
pattern = ''
danmus = re.findall(pattern=pattern, string=html)
print(danmus)
成功捕捉到弹幕!!
webdriver.Chrome() 创建了一个浏览器对象 browser ,直接调用 browser 的page_source就能得到当前的html了!
三、所有代码
1.导入库
from selenium import webdriver
import time
import re
import my_tools.my_print as mp
这个my_print是我自己写的小库,可以把列表按行打印,并且可以选择颜色
2.创建一个BiliLive类并写上构造方法
class BiliLive:
"""
用来抓取弹幕的类
"""
def __init__(self, room_num):
"""
构造方法
:param room_num: 要打开的直播房间号码
"""
self.url = 'https://live.bilibili.com/' + str(room_num)
print('正在打开浏览器')
self.browser = webdriver.Chrome()
print('正在打开网页')
self.browser.get(self.url)
print('打开成功')
# 等待浏览器内容加载
time.sleep(2)
# 弹幕列表
self.danmus = []
# 弹幕列表的最后一条弹幕
self.last_danmu = ''
3.创建两个get方法,分别来获得htnl页面和里面的弹幕
def get_html(self):
"""
获得页面
:return: 当前页面的源文件
"""
return self.browser.page_source
def get_new_danmus(self):
"""
解析页面内容,从当前页面获得新的弹幕的列表
:return:
"""
pattern = ''
danmus = re.findall(pattern=pattern, string=self.get_html())
return danmus
4. 把新的弹幕列表更新到总体的列表中
def flush_danmus(self):
"""
刷新弹幕列表,将读取到的新的弹幕添加到弹幕列表
"""
# 获取新的弹幕列表
new_list = self.get_new_danmus()
"""
ps: 你当然可以把列表转换成集合然后直接添加进去,或者使用for
循环遍历,但是这两种的时间复杂度都很高
"""
# 找到弹幕列表最后一条弹幕在新列表中的位置
if self.last_danmu in new_list:
# 找到其索引
flush_index = new_list.index(self.last_danmu) + 1
else:
# 弹幕列表不在新列表中
flush_index = 0
# 更新列表
self.danmus += new_list[flush_index:]
# mp.print_list(self.danmus, 'y')
# 更新最后一条弹幕
if len(self.danmus) > 1:
self.last_danmu = self.danmus[-1]
合并的思想是,使用原本弹幕列表的最后一个元素,在新得到的弹幕列表中找到相同的一项,设它在新列表中的索引为flush_index,那么只需要将从flush_index开始往后的弹幕合并到弹幕别表就行了,这样可以消除重复的弹幕
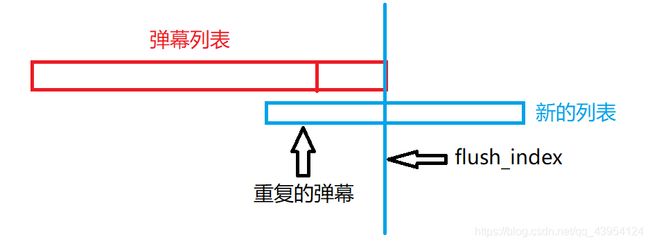
你当然可以将弹幕列表转化为set,然后再向里面添加新的弹幕,或者使用[i for i in new_danmus if …]的方式来合并弹幕,但是两种方法时间复杂度都很高,强迫症受不了
5.保存弹幕
def save_danmus(self):
"""
保存弹幕(懒......)
"""
pass
6.跑起来
def run(self, max_time=65536, flush_time=1):
"""
:param flush_time: 刷新弹幕的时间
:param max_time: 最大运行时间
:return:
"""
time.sleep(3)
start_time = time.time()
now_time = time.time()
while now_time - start_time < max_time:
# 刷新弹幕列表
self.flush_danmus()
# 自己写的打印库,换成print就行
# print(self.danmus)
mp.print_list(self.danmus, 'g')
time.sleep(flush_time)
now_time = time.time()
# 建议每次循环都保存一下,防止关了浏览器之后数据丢失
self.save_danmus()
if __name__ == '__main__':
live = BiliLive('308543')
live.run()

爬取成功!
四、(更新)眼瞎作者找到api了
阿巴阿巴,写完这篇文章之后,又用Fiddler仔细找了一下
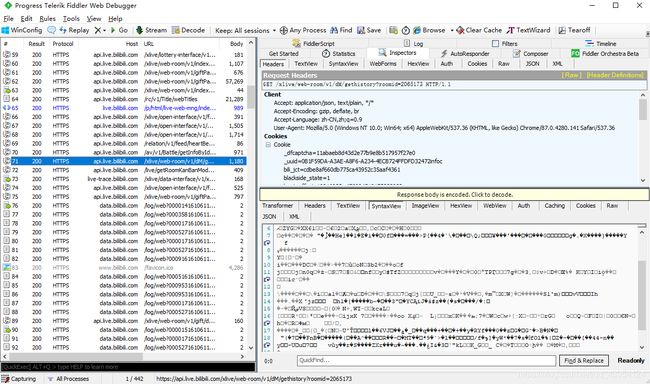
复制到浏览器康了一下
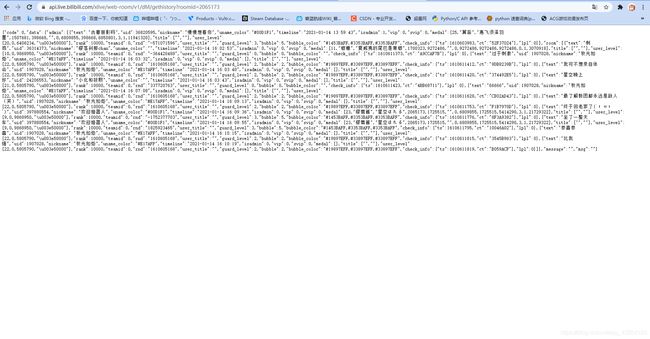
主要是这个接口刷新频率很慢,而且直接抓包得到的都是乱码,当时就给忽略过去了
接口名叫https://api.live.bilibili.com/xlive/web-room/v1/dM/gethistory?roomid=<房间号>
想要爬取的小伙伴直接拿来用吧!!
不说了,配眼镜去了!!
(更新)附上代码
import requests
import my_fake_useragent
import json
import my_tools.my_print as mp
import time
class BiliLive2:
"""
用来爬取直播弹幕的类
"""
def __init__(self, room_num):
self.url = 'https://api.live.bilibili.com/xlive/web-room/v1/dM/gethistory'
self.params = {
'roomid': str(room_num)}
self.danmus = []
self.last_danmu = ''
def get_headers(self):
"""
生成响应头
:return: 生成的响应头
"""
user_agent = my_fake_useragent.UserAgent()
ua = str(user_agent.random())
headers = {
'user-agent': ua
}
return headers
def get_response(self):
"""
得到请求
:return:
"""
response = requests.get(url=self.url, params=self.params, headers=self.get_headers())
return response
def get_new_danmus(self):
"""
访问url得到新的弹幕
:return:
"""
resopnse = self.get_response()
text = resopnse.text
# 转化为字典
info = json.loads(text)
ret_list = []
danmu = {
}
for dm in info['data']['room']:
# 保存文本
danmu['text'] = dm['text']
# 保存uid
danmu['uid'] = dm['uid']
# 保存用户名
danmu['nickname'] = dm['nickname']
# 保存时间
danmu['timeline'] = dm['timeline']
ret_list.append(danmu.copy())
danmu.clear()
return ret_list
def upgrade_danmus(self):
"""
刷新弹幕列表,将读取到的新的弹幕添加到弹幕列表
"""
# 获取新的弹幕列表
new_list = self.get_new_danmus()
"""
ps: 你当然可以把列表转换成集合然后直接添加进去,或者使用for
循环遍历,但是这两种的时间复杂度都很高
"""
# 找到弹幕列表最后一条弹幕在新列表中的位置
if self.last_danmu in new_list:
# 找到其索引
flush_index = new_list.index(self.last_danmu) + 1
else:
# 弹幕列表不在新列表中
flush_index = 0
# 更新列表
self.danmus += new_list[flush_index:]
# 更新最后一条弹幕
if len(self.danmus) > 1:
self.last_danmu = self.danmus[-1]
def save_danmus(self):
"""
保存弹幕(懒......)
"""
pass
def run(self, max_time=65536, flush_time=1):
"""
:param flush_time: 刷新弹幕的时间
:param max_time: 最大运行时间
:return:
"""
# time.sleep(3)
print('开始运行')
start_time = time.time()
now_time = time.time()
while now_time - start_time < max_time:
# 更新弹幕列表
self.upgrade_danmus()
# 打印一下
mp.print_list(self.danmus, 'g')
# 延时
time.sleep(flush_time)
now_time = time.time()
print('结束运行')
self.save_danmus()
if __name__ == '__main__':
live = BiliLive2(12885328)
live.run(max_time=200, flush_time=3)
运行结果

五、总结
虽然刚开始绕了点弯路,但最后好歹还是做出来了。不得不说,暴力爬虫确实爽
还有一点就是返回回来的json里面有两个列表,一个是admin,只显示会员的弹幕,另一个是room,显示直播间里面所有的弹幕
两个类里面的save方法没有完善(懒),有需要的小伙伴可以自己动手写哦!