编程作业四
作业链接:Boggle & Checklist
我的代码:BoggleSolver.java
问题简介
Boggle 是一个文字游戏,有 16 个每面都有字母的骰子,开始随机将它们放在 4 * 4 的板子上,如图:

图片来自:wiki。
游戏双方就在上面找有效的单词,单词越长分数越高,有效的单词具体指:
- 有效单词相邻字符的骰子也相邻,上下左右,对角线也行。
- 有效单词不能重复使用某个骰子。
- 有效单词的长度至少为 3。
- 有效单词要能在字典中找到,专有名词不算。
举例:
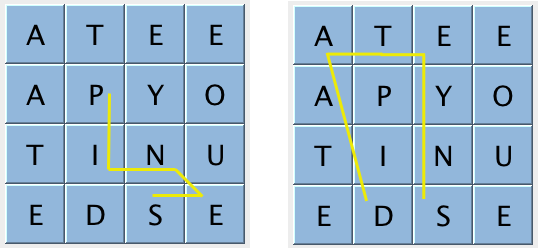
左边的单词 PINES 是有效的,右边的 DATES 是无效的(显然不相邻)。
不同长度的单词计分如下:
| word length | points |
|---|---|
| 0 - 2 | 0 |
| 3 - 4 | 1 |
| 5 | 2 |
| 6 | 3 |
| 7 | 5 |
| 8+ | 11 |
最后,因为英语单词中字母 Q 后面几乎总是会跟着 U,所以直接在骰子上写了 QU,计分的时候按两个字母算。
任务摘要
Your task. Your challenge is to write a Boggle solver that finds all valid words in a given Boggle board, using a given dictionary. Implement an immutable data type BoggleSolver with the following API:
public class BoggleSolver { // Initializes the data structure using the given array of strings as the dictionary. // (You can assume each word in the dictionary contains only the uppercase letters A through Z.) public BoggleSolver(String[] dictionary) // Returns the set of all valid words in the given Boggle board, as an Iterable. public IterablegetAllValidWords(BoggleBoard board) // Returns the score of the given word if it is in the dictionary, zero otherwise. // (You can assume the word contains only the uppercase letters A through Z.) public int scoreOf(String word) }
详细要求参见:Boggle。
问题分析
照着 Checklist 里建议的编程步骤一步步做下来。先熟悉作业为我们提供的数据结构:BoggleBoard.java,这个看下 API 就好,要注意的是板子上的 QU 为方便它直接用 Q 表示,后面我们要自己处理。第二步叫我们选个标准的数据结构来表示输入的字典,像 SET, TreeSet,或是 HashSet,用集合来表示一堆没重复的单词构成的字典,想想也是很合理。但后面觉得是没有必要再特地拿一个集合来表示。
第三步建议我们用 DFS 在 Board 上找出可能的单词组合,这步花了点时间才实现。传统的 DFS 是遍历所有的点,而且只会访问每个点一次。但是这里从不同的路径访问同一个字符显然算两个单词,所以递归返回之前还要把这个位置标记为没有被访问过,允许下次从不同的路再访问它。再者,路径上的字符要连起来才能构成单词,于是递归的 DFS 我还加了个 StringBuilder 类型的参数 pre,每次 new 一下传到下一层再接上这个位置的字符。
第四步是很重要的一步,像第三步那样找出相邻字符所有可能组成的单词,我在四乘四的板子上都跑到堆栈溢出。其实,发现字典里没有以当前组成的 pre 为前缀的单词时,这条 DFS 就不用再递归下去了,有很多 DFS 刚开始就会结束,而且基本不会有跑到底的 DFS。建议我们再实现一个数据结构,用来查询字典中是否有以 pre 为前缀的单词。
那第二步集合只是为了方便判断某个单词是否在字典中吗,那完全可以和第四步合起来吧我觉得,像 TrieSet 里就有这两个方法。但是课程里实现的 TrieSET.java 支持的是拓展 ASCII 的 256-way Trie,这里只会有 A 到 Z 共 26 个单词,感觉会浪费很多空间。于是,一开始调用了课程里有的 TST.java(三向单词查找树实现的符号表),以单词(字符串)为键,值随便。最后让我们解决特殊的 "QU" 情形,问题不大,字符是 Q,给 pre 拼接上 QU 就好。
又一番调试,本地测试通过,先交一波上去评测。拿到了 92 分,似乎开了个头,但实际上前面就做挺久了。。。具体是有四个时间测试没有通过,是参考程序的两百多倍。
Test 2: timing getAllValidWords() for 5.0 seconds using dictionary-yawl.txt
(must be <= 2x reference solution)
- reference solution calls per second: 8870.50
- student solution calls per second: 42.90
- reference / student ratio: 206.79
=> passed student <= 10000x reference
=> FAILED student <= 25x reference
=> FAILED student <= 10x reference
=> FAILED student <= 5x reference
=> FAILED student <= 2x reference那没办法,考虑 Checklist 里建议的可能的优化部分:
Possible Optimizations
You will likely need to optimize some aspects of your program to pass all of the performance points (which are, intentionally, more challenging on this assignment). Here are a few ideas:
Make sure that you have implemented the critical backtracking optimization described above. This is, by far, the most important step—several orders of magnitude!
Think about whether you can implement the dictionary in a more efficient manner. Recall that the alphabet consists of only the 26 letters A through Z.
Exploit that fact that when you perform a prefix query operation, it is usually almost identical to the previous prefix query, except that it is one letter longer.
Consider a nonrecursive implementation of the prefix query operation.
Precompute the Boggle graph, i.e., the set of cubes adjacent to each cube. But don't necessarily use a heavyweight Graph object.
第一点已经实现了,本着有现成就尽量不自己写的精神,再试试调用课程里其它的程序:TrieSET.java 和 TrieST,但本地测试的结果并没有比 TST.java 好,那就只能自己写了。
一开始,还是想着直接用现成的前缀判断方法。先在课程程序的基础上,忙活半天改出了 26-way trie 和 TST with \(R^{2}\) root 这两个版本,但本地测试并没有什么明显的效果,还是一开始的 TST 表现最好,也可能是我改得不好吧。再直接考虑最后一点,预处理一下板子,先算出每个位置的邻居,这样就不用每次 DFS 到了再算一次。效果也一般,而且我一开始用放整数的集合数组(泛型数组)来存,交上去评测编译时会有警告,编译部分还会被扣分。
到了最后的最后,只能自己写单词树了,后来觉得还不如一开始就自己实现好了。然后,当然是参考着课程里的程序来写的,主要目的是优化前缀的查找。因为这边的前缀查找比较特殊,相邻的查找总是只差一个字符,作业就提示我们是否能利用这一现象。在程序里实现单词查找树,前缀的判断就可以融入 DFS。递归传下去的不只是这条路上的 pre,这个 pre 在单词树中的位置节点也可以传下去,只要这个节点一为空,就说明单词树中没有以 pre 为前缀的单词,也就可以跳出这条 DFS。不好说明,可以直接看代码的 DFS 部分:BoggleSolver.java。
大概是这么个思想,最终实现自然是又捣鼓了好久。本地测试通过,交上去,拿了 98 分,还差最后一个测试,只要耗时小于参考程序的两倍就好。于是又盯着代码,各种小优化,像测试用随机的 4 * 4 板子,预计算出邻居不用每次都算,像空间还够,用数组存,下标来加快查找等等,但最终还是差那么 0.03。。。
Test 2: timing getAllValidWords() for 5.0 seconds using dictionary-yawl.txt
(must be <= 2x reference solution)
- reference solution calls per second: 9160.06
- student solution calls per second: 4502.85
- reference / student ratio: 2.03
=> passed student <= 10000x reference
=> passed student <= 25x reference
=> passed student <= 10x reference
=> passed student <= 5x reference
=> FAILED student <= 2x reference
Total: 8/9 tests passed!去作业论坛寻找新的优化思路,有人说他把板子存成一维的,就不用老是访问作业提供的板子对象查这个位置字符是啥。稍加修改,本地测试感觉良好,貌似会快那么一点点,交上去终于 a 掉了所有点!!
Test 2: timing getAllValidWords() for 5.0 seconds using dictionary-yawl.txt
(must be <= 2x reference solution)
- reference solution calls per second: 6842.46
- student solution calls per second: 4873.98
- reference / student ratio: 1.40
=> passed student <= 10000x reference
=> passed student <= 25x reference
=> passed student <= 10x reference
=> passed student <= 5x reference
=> passed student <= 2x reference
Total: 9/9 tests passed!据说(论坛)比参考程序耗时少还会有额外分数,但优化点我都用上了,也不想再优化了,100 分就好啦,哈哈。
测试结果
