python爬虫实战三:近十年中国电影票房数据爬取与分析
近十年中国电影票房数据爬取与分析
- 前言
- 爬取
- 分析
-
- 十年top10
- 年度top5
- 每年电影数
- 每年总票房
- 二八原则
- 代码与数据
前言
这篇文章主要讲述的是近十年(2010-2019)中国电影票房数据的爬取与简单分析。
之所以想到做这个,是因为我最近在一本书上读到这么一段话
2013年受市场热捧的电影行业其实是个现金流状况很差的行业。中国每年会拍七百多部电影,只有两百多部能够上映,其中票房能够超过五亿的屈指可数。即使赚了五亿的票房“大获成功”的电影,扣除分给院线的一半,再扣除发行费,宣传费,制片方能够拿到手的大概只有2亿多一点。再扣除给编剧、导演、制片和演员的薪酬以及拍摄中的各种成本,最后剩下的净利润可能只有几千万。
这句话让我对中国的电影市场产生了好奇,想了解一下近年来中国电影市场的发展,于是想爬取近十年的中国电影票房。
但是,我在爬取的过程中,遇到了很多困难:
- 数据不公开
没有一个权威、公开、透明的电影数据网站。我搜索了很多网站,没有找到满意的。所谓的中国电影数据信息网,有的是政策法规,工作咨询,没有的是电影数据。 - 设置爬虫障碍
后来我找到一家数据齐全的网站:电影票房网,但是万万没有想到这个网站给爬虫设置了重重障碍:-
查看多页数据需要用户登录

-
奇怪的验证码

-
这个数据居然是图片格式!
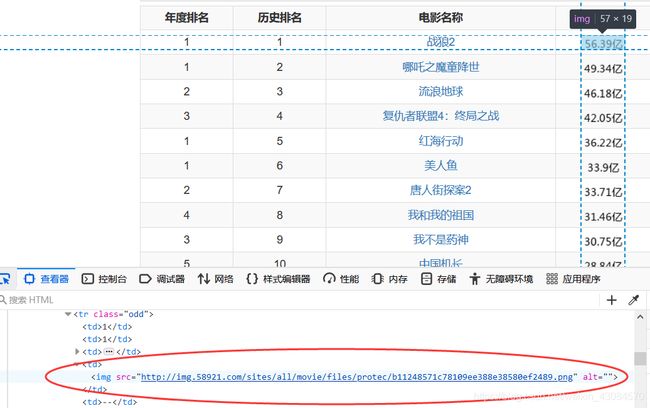
-
这让我这个爬虫小白望而却步,等以后学得更精了,再来爬这个。
后来我在外网上找到一个不错的网站:这是个网站
但是这个数据是非正式的,存在很多漏洞和问题,与真实数据有出入(下面会说明)。这里只是用来作爬取和数据分析用,不代表真实情况!
爬取
与前两个爬虫项目类似,直接上代码:
# 引入库
import re
import pandas as pd
import time
import urllib.request
from lxml.html import fromstring
from bs4 import BeautifulSoup
# 下载链接
def download(url):
print('Downloading:', url)
request = urllib.request.Request(url)
request.add_header('User-agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36') #进行伪装
resp = urllib.request.urlopen(request)
html = resp.read().decode('utf-8')
return html
# 待爬取内容
name = []
year = []
Box_office = []
# 循环爬取每页内容
for k in range(10):
movie_year = 2010+k
url = download('http://www.boxofficecn.com/boxoffice{}'.format(movie_year))
time.sleep(3) #间隔3s,防止被封禁
tree = fromstring(url)
soup = BeautifulSoup(url)
length_string = soup.find('div',{
'class':'entry-content'}).p.get_text()
length = int(re.search('[0-9]{1,3}(?=部)',length_string).group())
for k in range(length):
name.append(soup.find_all('tbody')[0].find_all('td')[4*k+2].get_text())
year.append(movie_year)
Box_office.append(soup.find_all('tbody')[0].find_all('td')[4*k+3].get_text())
# 将list转化为dataframe
name_pd = pd.DataFrame(name)
year_pd = pd.DataFrame(year)
Box_office_pd = pd.DataFrame(Box_office)
# 拼接
movie_Box_office_data = pd.concat([name_pd,year_pd,Box_office_pd],axis=1)
movie_Box_office_data.columns=['电影','年份','票房']
movie_Box_office_data.head()
# 数据预处理
## 提取数字部分
f = lambda x: re.search('[0-9]*(\.[0-9]*)?',x).group()
movie_Box_office_data['票房'] = movie_Box_office_data['票房'].apply(f)
## 缺失值填充为0
empty = movie_Box_office_data['票房'] == ''
movie_Box_office_data.loc[empty,'票房'] = 0
## 转化成浮点数
movie_Box_office_data['票房'] = movie_Box_office_data['票房'].apply(lambda x: float(x))
# 输出
outputpath='c:/Users/zxw/Desktop/修身/与自己/数据分析/数据分析/爬虫/中国电影票房/movie_box_office.csv' ## 路径需要自己改!
movie_Box_office_data.to_csv(outputpath,sep=',',index=False,header=True,encoding='utf_8_sig')
需要注意的一点是,这里使用 beautifulsoup 里面的 find_all 函数来进行定位,应该是最简单的。这是对爬取的所有十个网页均适用的定位方法。其他 xpath 等方法,都不大行得通。
另外需要注意的是爬取的票房数据要进行预处理,因为票房数据中可能含有中文。
分析
前期准备:引入库,导入数据。
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn
import pandas as pd
import numpy as np
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #使得图片可以显示中文
data = pd.read_csv('movie_box_office.csv')
十年top10
先看一下这十年 top10的影片,(票房的单位是万)
data.sort_values(by='票房',ascending=False).head(10)
 这里有一个问题就是,电影芳华的数据明显出错了,没有加小数点。更改之后如下
这里有一个问题就是,电影芳华的数据明显出错了,没有加小数点。更改之后如下
data.iloc[2111,2]=142241.3
data.sort_values(by='票房',ascending=False).head(10).plot.bar(x='电影',y='票房',title='top 10')

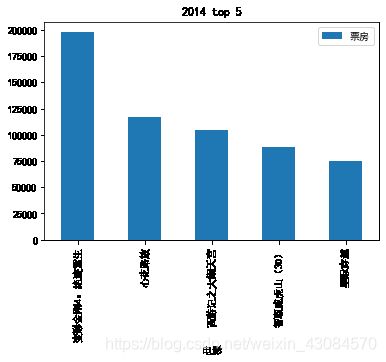
年度top5
data[data['年份']==2010].sort_values(by='票房',ascending=False).head(5).plot.bar(x='电影',y='票房',title='2010 top 5')

类似可以得到其他年份的top5








每年电影数
groupby_year = data.groupby('年份').size()
groupby_year.plot.bar(title = '每年电影数')
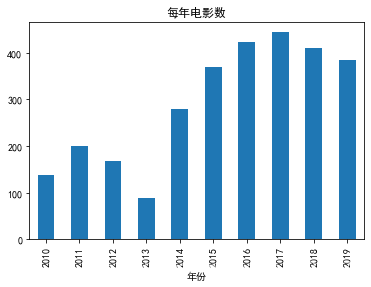 注意到2013年上映电影数明显下降。事实上是因为这份网页在统计2013年电影数据时存在缺失。
注意到2013年上映电影数明显下降。事实上是因为这份网页在统计2013年电影数据时存在缺失。
每年总票房
data.groupby('年份')['票房'].sum().plot.bar(title = '每年总票房')
 同样地,2013年电影票房明显下降。
同样地,2013年电影票房明显下降。
二八原则
二八原则大概指的是,前20%的人,拥有了80%的资源。
电影票房是不是也符合二八原则呢?是不是爆款电影占据了电影市场大部分份额,而绝大多数的电影却成为了不为人知的炮灰呢?事实正是如此。
可以先看一下近两年的票房情况:
data[data['年份']==2019]['票房'].plot.hist()
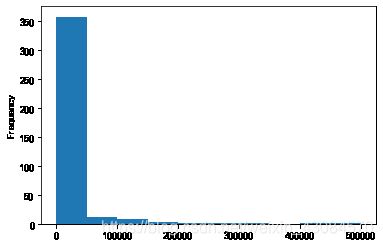
data[data['年份']==2018]['票房'].plot.hist()
 再看一下近十年,每年票房前20%电影所占全年票房总市场的份额:
再看一下近十年,每年票房前20%电影所占全年票房总市场的份额:
percent = []
for k in range(10):
Boxoffice= data[data['年份']==(2010+k)]['票房']
q80 = np.percentile(Boxoffice ,80)
percent.append(Boxoffice[Boxoffice >= q80].sum()/ Boxoffice.sum())
percent
 可以看到,每年票房前20%电影所占全年票房总市场的份额大于70%的,而且是逐年增加的,近四年甚至超过了90%!
可以看到,每年票房前20%电影所占全年票房总市场的份额大于70%的,而且是逐年增加的,近四年甚至超过了90%!
代码与数据
最后附上完整的代码和数据:提取码 v9kh