深入浅出Linux内核中的内存屏障
工程师的圣地—Linux内核, 谈谈内核的架构
5个方面分析内核架构
linux内核,进程调度器的实现,完全公平调度器 CFS
深透剖析Linux内核字符与块设备驱动程序
抽象内存模型
指令重排
每个 CPU 运行一个程序,程序的执行产生内存访问操作。在这个抽象 CPU 中,内存 操作的顺序是松散的,CPU 假定进程间不依靠内存直接通信,在不改变程序执行 结果 的推测下由自己方便的顺序执行内存访问操作。
例如,考虑下面的执行过程:
{ A = 1 b = 2}
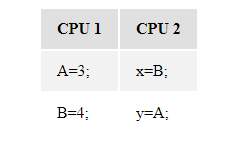
这有 24 中内存访问操作的组合,每种组合都有可能出现:
STORE A=3, STORE B=4, y=LOAD A->3, x=LOAD B->4
STORE A=3, STORE B=4, x=LOAD B->4, y=LOAD A->3
STORE A=3, y=LOAD A->3, STORE B=4, x=LOAD B->4
STORE A=3, y=LOAD A->3, x=LOAD B->2, STORE B=4
STORE A=3, x=LOAD B->2, STORE B=4, y=LOAD A->3
STORE A=3, x=LOAD B->2, y=LOAD A->3, STORE B=4
STORE B=4, STORE A=3, y=LOAD A->3, x=LOAD B->4
STORE B=4, ...
...
从而产生 4 种结果:
x == 2, y == 1
x == 2, y == 3
x == 4, y == 1
x == 4, y == 3
更残酷的是,一个 CPU 已经提交的 store 操作,另一个 CPU 可能不会感知到,从而 load 操作取到旧的值。
比如:
{
A = 1, B = 2, C = 3, P = &A, Q = &C}
CPU 1 CPU 2
B=4; Q=p;
P=&B; D=*Q;
可以产生 4 种结果:
(Q == &A) and (D == 1)
(Q == &B) and (D == 2)
(Q == &B) and (D == 4)
设备操作
一些设备将自己的控制接口映射成一个内存地址,访问这些地址的指令顺序是极重要 的。比如一个拥有一系列内部寄存器的网卡,可以通过一个地址寄存器 (A) 和一个数 据寄存器 (D) 访问它们。如果要访问内部寄存器 5 ,则使用下面的代码:
*A = 5;
x = *D;
但这个代码可能生成以下两种执行顺序:
STORE *A = 5, x = LOAD *D
x = LOAD *D, STORE *A = 5
合并内存访问
CPU 还可能将内存操作合并。比如
X = *A; Y = *(A + 4);
可能会生成下面任何一种执行顺序:
X = LOAD *A; Y = LOAD *(A + 4);
Y = LOAD *(A + 4); X = LOAD *A;
{
X, Y} = LOAD {
*A, *(A + 4) };
而
*A = X; *(A + 4) = Y;
则可能生成下面任何一种执行:
STORE *A = X; STORE *(A + 4) = Y;
STORE *(A + 4) = Y; STORE *A = X;
STORE {
*A, *(A + 4) } = {
X, Y};
最小保证
可以期望 CPU 提供了一些最小保证,不满足最小保证的 CPU 都是假的 CPU。
有依赖关系的内存访问操作是有顺序的。也就是说:
Q = READ_ONCE(P); smp_read_barrier_depends(); D = READ_ONCE(*Q);
总是在 CPU 中以这样的顺序执行:
Q = LOAD P, D = LOAD *Q
smp_read_barrier_depends() 只在 DEC Alpha 中有用,READ_ONCE 的作用在 这里 提到。
在一个 CPU 中的覆盖 load-store 操作是有顺序的。比如
a = READ_ONCE(*X); WRITE_ONCE(*X, b);
总是以这样的顺序执行:
a = LOAD *X, STORE *X = b
而
WRITE_ONCE(*X, c); d = READ_ONCE(*X);
总是以下面的顺序执行:
STORE *X = c, d = LOAD *X
最小保证不适用于位图。假设我们有一个长度为 8 的位图,CPU 1 要将 1 位置 1, CPU 2 要将 2 位 置 1:
{ A = 0 }

可能有三种个结果:
A = 2
A = 4
A = 6
内存屏障
正如之前看到的,内存访问操作的顺序是随机的,这会造成 CPU 间通信或者 I/O 问 题。需要一种介入保证指令的顺序以获得期望结果。内存屏障就是这样一种介入。
4+2种内存屏障
写屏障
写屏障保证任何出现在写屏障之前的 STORE 操作先于出现在写屏障之后的任何 STORE 操作执行。
写屏障一般与读屏障或者数据依赖屏障配合使用。
数据依赖屏障
数据依赖屏障是一个弱的读屏障。用于两个读操作之间,且第二个读操作依赖第一个 读操作(比如第一个读操作获得第二个读操作所用的地址)。读屏障用于保证第二个读 操作的目标已经被第一个读操作获得。
数据依赖屏障只能用于确实存在数据依赖的地方。
读屏障
读屏障保证任何出现在读屏障之前的 LOAD 操作先于出现在读屏障之后的任何 LOAD 操作执行。
读屏障一般和写屏障配合使用。
一般内存屏障
一般内存屏障保证所有出现在屏障之前的内存访问 (LOAD 和 STORE) 先于出现在屏障 之后的内存访问执行。
此外还有两种不常见的内存屏障
ACQUIRE 操作
保证出现在 ACQUIRE 之后的操作确实在 ACQUIRE 之后执行。而出现在 ACQUIRE 之前 的内存操作可能执行于 ACQUIRE 之后。
ACQUIRE 和 RELEASE 配合使用。
RELEASE 操作
保证出现在 RELEASE 之前的操作确实在 RELEASE 之前执行。而出现在 RELEASE 之后 的内存操作可能执行于 RELEASE 之前。
数据依赖屏障
数据依赖屏障需要并不总是那么明显。举个例子。
{ A = 1, B = 2, C = 3, P = &A, Q = &C }
这个例子中,D 要么是 &A, 要么是 &B:
(Q == &A) implies (D == 1)
(Q == &B) implies (D == 4)
但是,CPU 2 察觉到的 P 的更新可能比先于 B 的更新被察觉,这导致下面的结果:
(Q == &B) and (D == 2)
现实世界中有 CPU 是这么表现的,比如 DEC Alpha。要获得想要的结果,需要一个数 据依赖屏障:

数据依赖凭证保证了只会出现两种可预期的结果。
数据依赖屏障也可以序列化依赖前一指令的写操作:
{
A = 1, B = 2, C = 3, P = &A, Q = &C }

数据依赖凭证保证了只会出现一种结果:
(Q == &B) && (B == 4)
【文章福利】小编推荐自己的Linux、C/C++技术交流群:【960994558】整理了一些个人觉得比较好的学习书籍、大厂面试题、有趣的项目和热门技术教学视频资料共享在里面(包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等等.),有需要的可以自行添加哦!~
这里推荐一个大佬的免费课程,这个跟以往所见到的只会空谈理论的有所不同,正在学习的朋友可以体验一下
【免费】C/C++Linux服务器开发/后台架构师
控制依赖
现在的编译器是不能理解控制依赖的,需要人开动脑筋做一些微小的工作。这一小节 可以防止你的代码不被傲慢无知的编译器破坏。
考虑下面的代码:
q = a;
if (q) {
p = b;
}
如果编译器推测 q 总是 非 0, 它会觉得有必要对这段代码进行优化,优化后的结果 为:
q = a;
p = b;
编译器也可能合并 a 的读操作到其它位置,或者合并 p 的写操作。为了阻止这些情 况发生,需要将代码改为:
q = READ_ONCE(a);
if (q) {
p = READ_ONCE(b);
}
即使这样,CPU 也会因为预执行而引起其它 CPU 感知到 b 的 LOAD 先于 a 的 LOAD。 这里需要一个读屏障来防止这样的事情发生:
q = READ_ONCE(a);
if (q) {
<read barrier>
p = READ_ONCE(b);
}
但写操作是不会预执行的,下面的代码所见即所得:
q = READ_ONCE(a);
if (q) {
p = WRITE_ONCE(b);
}
编译器也可能将它觉得重复的操作移出合并,比如:
q = READ_ONCE(a);
if (q) {
barrier();
WRITE_ONCE(b, 1);
do_something();
} else {
barrier();
WRITE_ONCE(b, 1);
do_something_else();
}
被转化为:
q = READ_ONCE(a);
barrier();
WRITE_ONCE(b, 1); /* BUG: No ordering vs. load from a!!! */
if (q) {
/* WRITE_ONCE(b, 1); -- moved up, BUG!!! */
do_something();
} else {
/* WRITE_ONCE(b, 1); -- moved up, BUG!!! */
do_something_else();
}
如果需要严格控制这个过程,可以使用 smp_store_release():
q = READ_ONCE(a);
if (q) {
smp_store_release(&b, 1);
do_something();
} else {
smp_store_release(&b, 1);
do_something_else();
}
或者令两条语句不同从而编译器无法将共同代码提出判断条件:
q = READ_ONCE(a);
if (q) {
WRITE_ONCE(b, 1);
do_something();
} else {
WRITE_ONCE(b, 2);
do_something_else();
}
另外,需要小心编译器的推断,比如:
q = READ_ONCE(a);
if (q % MAX) {
WRITE_ONCE(b, 1);
do_something();
} else {
WRITE_ONCE(b, 2);
do_something_else();
}
如果 MAX 被定义为 1, 那么编译器将推测出 (q % MAC) = 0,那么编译器就会觉得 有必要将判断条件优化掉:
q = READ_ONCE(a);
WRITE_ONCE(b, 1);
do_something_else();
如果优化成这样, CPU 将没有义务保证 LOAD a 和 STORE b 的顺序。如果这个判断 是必要的,那么 MAX 必须保证大于 1:
q = READ_ONCE(a);
BUILD_BUG_ON(MAX <= 1); /* Order load from a with store to b. */
if (q % MAX) {
WRITE_ONCE(b, 1);
do_something();
} else {
WRITE_ONCE(b, 2);
do_something_else();
}
注意两个 LOAD 操作是不同的,否则编译器会将其提出判断条件外。
还必须注意不要太依赖 bool 运算的短路计算,比如:
q = READ_ONCE(a);
if (q || 1 > 0)
WRITE_ONCE(b, 1);
由于第一个条件不会出错,而第二个条件总是 TRUE, 编译器会将其转化成:
q = READ_ONCE(a);
WRITE_ONCE(b, 1);
不要令编译器看透你的代码,否则连 READ_ONCE() 也不能阻止这种情况发生。
另外,控制依赖只能控制 then-clause 和 else-clause 的顺序,并不能保证判断语 句之外的代码:
q = READ_ONCE(a);
if (q) {
WRITE_ONCE(b, 1);
} else {
WRITE_ONCE(b, 2);
}
WRITE_ONCE(c, 1); /* BUG: No ordering against the read from 'a'. */
也许有人会说编译器不能重排 b 的 STORE 因为这是 volatile 的访问,但编译器可 能生成如下代码:
ld r1,a
cmp r1,$0
cmov,ne r4,$1
cmov,eq r4,$2
st r4,b
st $1,c
CPU 没有义务保证 c 的 STORE 必须在 a 的 LOAD 之后。
举例
写屏障规定了 STORE 操作的顺序。

这意味着无序集合 {STORE A, STORE B, STORE C} 中所有指令都出现在无序集合 {STORE D, STORE E} 任何指令之前。
数据依赖屏障保证了 LOAD 依赖的前一个 STORE 操作已经执行。
考虑下面的代码:
{ B = 7; X = 9; Y = 8; C = &Y }
如果没有数据依赖屏障, CPU 2 执行 LOAD C 时感知到了 CPU 1 的 STORE C = &B, 但可能 LOAD *C 时却没有感知到 CPU 1 的 STORE B = 2,而得到结果 LOAD *C = 7。
这里需要一个数据依赖屏障来让 CPU 2 感知 B 的改变。
{ B = 7; X = 9; Y = 8; C = &Y }
这样得到的结果就是 LOAD *C = 2。
读屏障保证 STORE 操作是有顺序的
{ A = 0, B = 9 }

没有读屏障,CPU 2 感知到 CPU 1 的随机顺序,根本不管 CPU 1 上的写屏障。 这里甚至可能出现 A = 0, B = 2 的情况。
所以这里需要一个写屏障:
{ A = 0, B = 9 }

这个写屏障保证了如果 B=2 那么 A=1。
读屏障和预取
很多 CPU 有预取技术,如果 CPU 发现需要用到一个内存中的数据,并且总线空闲, 即使没有执行到真正需要这个值的指令,CPU 也会提前将其取出。如果 CPU 发现并不 需要这个值(在分支条件中可能出现这种情况),它会将其丢弃,或者将其缓存。
考虑下面的代码:
LOAD B
DIVIDE
DIVIDE
LOAD A
DIVIDE 指令需要消耗大量的时间,此时 A 已经被预取,如果在 DIVIDE 执行过程中, 另一个 CPU 修改了 A 的值,CPU 2 是不管的,因为 A 已经预取了。
此时需要一个内存屏障:
LOAD B
DIVIDE
DIVIDE
<read barrier>
LOAD A
在这个屏障的作用下,如果预取之后 A 被修改,CPU 将重新取得 A 的值。
传递性
一般内存屏障提供了传递性。考虑下面的代码:
{ X = 0, Y = 0 }

假设 CPU2 LAOD X = 1, LOAD Y = 0,这表示 CPU2 的 LOAD X 后于 CPU1 的 STORE X = 1,CPU2 的 LOAD Y 先于 CPU3 的 STORE Y = 1。这时候 CPU3 能否出现 LOAD X = 0?
在 Linux 内核中,一般内存屏障提供了传递性,所以这里的 CPU3 中 LOAD X 只能得 到 1。
但是, 读屏障和写屏障不提供传递性,比如下面的代码:
{ X = 0, Y = 0 }

这可能出现 CPU2 LOAD X = 1, CPU2 LOAD Y = 0, CPU3 LOAD X = 0。
CPU2 的读屏障虽然保证了它自己 LOAD 的顺序,但不能保证 CPU1 的 STORE。如果 CPU1 和 CPU2 共享同一个 cache,CPU2 可能更早的感知到 CPU1 的 STORE X = 1。
Linux 内核屏障
Linux 内核拥有三种级别的屏障:
- 编译器屏障
- CPU 内存屏障
- MMIO 写屏障
编译器屏障
Linux 内核提供了编译器屏障函数,它防止编译器将屏障以便的内存操作移动到另一边:
barrier();
这是个一般屏障,READ_ONCE() 和 WRITE_ONCE() 可以认为是 barier() 的弱化版本。
barrier() 有一下两个功能:
(1) 防止编译器将 barrier() 之后的内存访问重排到 barrier() 之前。 (2) 在循环中,迫使编译器在循环里面每次都取条件判断中需要的值,而不是只取一次。
READ_ONCE() 和 WRITE_ONCE() 可以防止编译器的一些优化,这些优化在但线程环境 中是无害的,但在多线程环境中会引发错误。
(1) 编译器有权重排 LOAD 和 STORE 指令以达到优化目的:
a[0] = x;
a[1] = x;
可能会被重排成先赋值 (a[1]), 后赋值 (a[0])。使用 READ_ONCE() 可以防止编译器重排:
a[0] = READ_ONCE(x);
a[1] = READ_ONCE(x);
一句话:READ_ONCE() 和 WRITE_ONCE() 提供了多 CPU 访问一个变量的缓存一致性。
(2) 编译器有权合并 LOAD 操作以达到优化目的,比如:
while (tmp = a)
do_something_with(tmp);
这会被编译器优化成:
if (tmp = a)
for (;;)
do_something_with(tmp);
这一定不是你想要的,使用 RAED_ONCE() 防止编译器这么做:
while (tmp = READ_ONCE(a))
do_something_with(tmp);
(3) 在寄存器紧张的时候,编译器可能会生虫重新取内存中的值的代码:
while (tmp = a)
do_something_with(tmp);
将变成:
while (a)
do_something_with(a);
这在单线程环境中是没有问题的,但在并行环境中会引起错误。同样使用 READ_ONCE() 抑制编译器的自作多情:
while (tmp = READ_ONCE(a))
do_something_with(tmp);
(4) 如果编译器“知道”一个变量的值是什么,它就有权忽略 LOAD 操作。如果编译器 推测 a 总是0,那么
while (tmp = a)
do_something_with(tmp);
会被优化成:
do {
} while (0);
这在单线程环境中是个极大的优化,但多线程环境中是个问题。其它线程可能会修改 a 以改变它为 0 的命运,但生成的代码并不会知道这些。这里应该使用 READ_ONCE() 告诉编译器它不了解情况:
while (tmp = READ_ONCE(a))
do_something_with(tmp);
(5) 如果编译器发现一个变量要赋一个相同的值,那么这个赋值操作将被忽略:
a = 0;
... Code that does not store to variable a ...
a = 0;
百年一起发现 a 已经是 0 了,所以它觉得第二个 a = 0 没有用,就将其忽略。这同 样导致多线程环境中的问题。使用 WRITE_ONCE() 告诉编译器事情比它想象中的复杂:
WRITE_ONCE(a, 0);
... Code that does not store to variable a ...
WRITE_ONCE(a, 0);
(6) 编译器有权重排内存访问的顺序,除非你告诉它不这么做。比如:
void process_level(void)
{
msg = get_message();
flag = true;
}
void interrupt_handler(void)
{
if (flag)
process_message(msg);
}
编译器可能将 process_level() 重排成:
void process_level(void)
{
flag = true;
msg = get_message();
}
如果一个中断在这两条语句中间发生,那么 interrupt_handler 中的 process_message 使用的将是为初始化的 msg。
使用 READ_ONCE() 和 WRITE_ONCE() 告知编译器不要重排:
void process_level(void)
{
WRITE_ONCE(msg, get_message());
WRITE_ONCE(flag, true);
}
void interrupt_handler(void)
{
if (READ_ONCE(flag))
process_message(READ_ONCE(msg));
}
(7) 编译器有权优化一个条件控制语句,比如:
if (a)
b = a;
else
b = 42;
可被优化成:
b = 42;
if (a)
b = a;
这是有道理的,因为省略了一个判断分支。同样地,造成了多线程环境的问题。使用 WRITE_ONCE() 防止编译器这么做:
if (a)
WRITE_ONCE(b, a);
else
WRITE_ONCE(b, 42);
(8) 编译器可能会把没有对齐的内存地址操作转化为两个指令,例如下面的代码:
p = 0x00010002;
可能被转换成两条 16-bit 的指令实现这个 32-bit 操作。使用:
WRITE_ONCE(p, 0x00010002);
可以避免这样的指令分割。这种分割在 attribute__((__packed)) 的 struct 中很常见。
CPU 内存屏障
Linux 内核拥有 8 个基本的内存屏障:
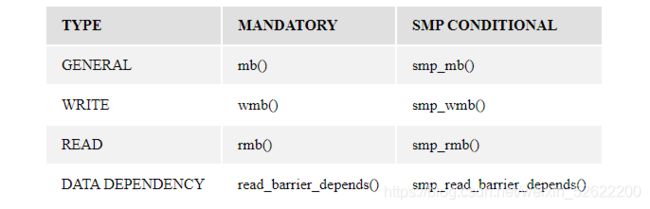
除了数据依赖屏障,其它每个内存屏障都隐含这编译器屏障。数据依赖屏障不影响编 译器的生成的指令顺序。
SMP 内存屏障在单处理器编译系统上的作用跟编译器屏障一样,因为我们假设单 CPU 是不会把事情搞砸的。
在 SMP 系统中,必须使用 SMP 内存屏障来规范共享内存的访问次序,即使使用锁已 经足够了。
除了 8 个基本函数,还有一些高级屏障函数:
(1) smp_store_mb(var, value)
相当于将 var 赋值后插入一个内存屏障。
(2) smp_mb__before_atomic() 和 smp_mb__after_atomic()
这两个函数用于没有返回值的原子操作函数,多用在引用计数中。这两个函数不包含 内存屏障。
比如,考虑下面的代码,它将一个 object 标记为死亡,然后递减 object 的引用计 数:
obj->dead = 1;
smp_mb__before_atomic();
atomic_dec(&obj->ref_count);
这保证了 obj->dead = 1 在引用计数递减之前被感知到。
(3) lockless_dereference()
作用等同于指针解引用和 smp_read_barrier_depends() 数据依赖屏障的结合。
(4) dma_wmb() 和 dma_rmb()
这两个函数保证了一块 DMA 和 CPU 共享的内存的访问指令顺序。
例如下面的代码,它使用 desc->status 区分 desc 属于 CPU 还是设备,当 desc 可 用时就去按门铃:
if (desc->status != DEVICE_OWN) {
/* do not read data until we own descriptor */
dma_rmb();
/* read/modify data */
read_data = desc->data;
desc->data = write_data;
/* flush modifications before status update */
dma_wmb();
/* assign ownership */
desc->status = DEVICE_OWN;
/* force memory to sync before notifying device via MMIO */
wmb();
/* notify device of new descriptors */
writel(DESC_NOTIFY, doorbell);
}
dma_rmb() 保证在读数据之前设备已经释放了它对 desc 的所有权,dma_wmb() 保证 在设备察觉 desc->status = DEVICE_OWN 时数据已经写入。smb() 用于保证缓存一致 的内存写操作在缓存不一致的 MMIO 写之前已经完成。
MMIO 写屏障
Linux 内核有一个专门用于 MMIO 写的屏障:
mmiowb()
隐藏的内存屏障
Linux 内核中一些锁或者调度函数暗含了内存屏障。
锁函数
Linux 内核有很多锁的设计:
- spin locks
- R/W spin locks
- mutexes
- semaphores
- R/W semaphores
这些设计中都包含了 ACQUIRE 操作和 RELEASE 操作,或者它们的变种。这些操作暗 含了内存屏障。
但 ACQUIRE 和 RELEASE 并不实现完全的内存屏障。
中断禁止函数
启动或禁止终端的函数的作用仅仅是作为编译器屏障,所以要使用内存或者 I/O 屏障 的场合,必须用别的函数。
SLEEP 和 WAKE-UP 以及其它调度函数
使用 SLEEP 和 WAKE-UP 函数时要改变 task 的状态标志,这需要使用合适的内存屏 障保证修改的顺序。
多 CPU 间 ACQUIRE 的作用
ACQUIRE 和内存访问
考虑下面的代码,系统有一对自旋锁 M 和 Q ,三个 CPU:

CPU 3 察觉到的修改的顺序不能为以下任何一个:
*B, *C or *D preceding ACQUIRE M
*A, *B or *C following RELEASE M
*F, *G or *H preceding ACQUIRE Q
*E, *F or *G following RELEASE Q
ACQUIRE 和 I/O
在一些结构下,比如 NUMA,两个位于不同 CPU 间的自旋锁区域的 I/O 访问在 PCI 上 可能是交错的,因为 PCI 没有必要考虑缓存一致协议。
比如:
在 PCI 桥中可能出现下面的序列:
STORE *ADDR = 0, STORE *ADDR = 4, STORE *DATA = 1, STORE *DATA = 5
这可能会造成硬件故障。在释放 spin_lock 之前需要一个 mmiowb() :
这保证了 CPI 桥看到的 CPU1 的 STORE 操作出现在 CPU2 之前。
但下面的 store-by-load 操作却不需要 mmiowb(), 因为 load 迫使 store 操作先完 成。
何处使用内存屏障
在下面的 4 中情况下需要用内存屏障保证指令顺序:
- 处理器间交互
- 原子操作
- 访问设备
- 中断
处理器间交互
当系统拥有多个处理器时,超过一个的 CPU 可能会在同一时间操作同一个数据集。这 可能会有同步问题,一般的解决办法是使用锁。但锁是很昂贵的,所以尽可能不用。这 种情况下每个 CPU 的操作指令都需要严格控制。
考虑一个 R/W 的信号量,结构中有一个等待队列,保存指向等待进程的指针:
struct rw_semaphore {
...
spinlock_t lock;
struct list_head waiters;
};
struct rwsem_waiter {
struct list_head list;
struct task_struct *task;
};
为了唤醒一个等待队列中的进程,up_read() 或者 up_write() 函数必须:
(1) 读等待者的 next 指针,以得知下一个等待者的结构在哪里;
(2) 读指向等待者 task struct 的指针;
(3) 清除 task 指针,告知等待者信号量已经给它了;
(4) wake_up_process();
(6) 释放 task struct 中的引用。
换一种语言:
LOAD waiter->list.next;
LOAD waiter->task;
STORE waiter->task;
CALL wakeup
RELEASE task
如果上述顺序不能保证,整个过程在多 CPU 环境中就会有问题。需要在2-3行之间插 入一个 smp_mb()。
原子操作
有些原子操作包含了完整的内存屏障,但一些根本没有。任何操作一个内存并拥有内 存值返回的原子操作都实现了内存屏障(smp_mb()),在操作前后都有,这些函数包括:
xchg();
atomic_xchg(); atomic_long_xchg();
atomic_inc_return(); atomic_long_inc_return();
atomic_dec_return(); atomic_long_dec_return();
atomic_add_return(); atomic_long_add_return();
atomic_sub_return(); atomic_long_sub_return();
atomic_inc_and_test(); atomic_long_inc_and_test();
atomic_dec_and_test(); atomic_long_dec_and_test();
atomic_sub_and_test(); atomic_long_sub_and_test();
atomic_add_negative(); atomic_long_add_negative();
test_and_set_bit();
test_and_clear_bit();
test_and_change_bit();
/* when succeeds */
cmpxchg();
atomic_cmpxchg(); atomic_long_cmpxchg();
atomic_add_unless(); atomic_long_add_unless();
下面的函数是不包含内存屏障的,但它们可能用于实现类似 RELEASE 的东西:
atomic_set();
set_bit();
clear_bit();
change_bit();
使用它们的时候,内存屏障是必要的,应该使用诸如 smp_mb__before_atomic() 之 类的函数。
虽然可能在某些环境中包含内存屏障,但不确保的函数:
atomic_add();
atomic_sub();
atomic_inc();
atomic_dec();
当这些函数用于实现一个锁标志位时,内存屏障是必要的。
访问设备
一些设备可能被映射成内存地址,CPU 访问这些内存地址时需要保证正确的指令顺序。 拥有过于先进的 CPU 和 过于先进的编译器的我们需要用内存屏障类给这个保证。参 看前面 mmiowb() 的例子。
中断
驱动可能被自己的中断服务函数中断,这两部分可能会互相干涉。考虑下面的访问网 卡的代码:
LOCAL IRQ DISABLE
writew(ADDR, 3);
writew(DATA, y);
LOCAL IRQ ENABLE
<interrupt>
writew(ADDR, 4);
q = readw(DATA);
</interrupt>
第一个 STORE DATE 寄存器的操作可能出现在第二个 STORE ADDR 操作之后:
STORE *ADDR = 3, STORE *ADDR = 4, STORE *DATA = y, q = LOAD *DATA
需要一个 I/O 屏障保证这个顺序。mmiowb() 是个不错的选择。
CPU cache
逻辑上讲,内存屏障擢用于内存和 CPU 的分界线上:
<--- CPU ---> : <----------- Memory ----------->
:
+--------+ +--------+ : +--------+ +-----------+
| | | | : | | | | +--------+
| CPU | | Memory | : | CPU | | | | |
| Core |--->| Access |----->| Cache |<-->| | | |
| | | Queue | : | | | |--->| Memory |
| | | | : | | | | | |
+--------+ +--------+ : +--------+ | | | |
: | Cache | +--------+
: | Coherency |
: | Mechanism | +--------+
+--------+ +--------+ : +--------+ | | | |
| | | | : | | | | | |
| CPU | | Memory | : | CPU | | |--->| Device |
| Core |--->| Access |----->| Cache |<-->| | | |
| | | Queue | : | | | | | |
| | | | : | | | | +--------+
+--------+ +--------+ : +--------+ +-----------+
:
:
cache 一致性
某个 CPU 对内存的修改最后都会被所有其它 CPU 感知到,但感知顺序却不能保证。
考虑下面的架构:
:
: +--------+
: +---------+ | |
+--------+ : +--->| Cache A |<------->| |
| | : | +---------+ | |
| CPU 1 |<---+ | |
| | : | +---------+ | |
+--------+ : +--->| Cache B |<------->| |
: +---------+ | |
: | Memory |
: +---------+ | System |
+--------+ : +--->| Cache C |<------->| |
| | : | +---------+ | |
| CPU 2 |<---+ | |
| | : | +---------+ | |
+--------+ : +--->| Cache D |<------->| |
: +---------+ | |
: +--------+
:
这个系统拥有下面的特性:
- 奇数缓存行保存在 A, C 或者内存中;
- 偶数缓存行保存在 B, D 或者内存中;
- 当 CPU 询问一个 cache 时,其它 cache 可能会利用总线访问其它部分,比如置换 脏页,或者预取;
- 每个 cache 都有一个操作队列,用于维护一致性;
- 一致性队列中的对 cache 中已经存在的数据的 load 不会引起队列的刷新。
当一个 CPU 访问内存时,操作顺序如下:

smp_wmb() 保证其它 CPU 感知到的两个改变是有序的。但如果第二个 CPU 想要访问这些值:
q = p;
x = *q;
这会可能会出现 q = &v 但 v = 1 的情况:
CPU2 的两条指令之间需要一个 smp_read_barrier_depends() 防止这一情况。这在 DEC Alpha 处理器中是可能出现的情况。
CACHE 和 DMA
不是所有的系统都会维护 DMA 和 cache 间的一致性。DMA 可能会从内存拿到陈腐的 数据而新的数据还在 cache 中。DMA 写 RAM 的时候 CPU 的 cache 可能会刷新它的 脏行到内存从而引起不一致。
CACHE 和 MMIO
MMIO 不会走 CACHE, 在访问 MMIO 之前保证读取到的数据是一致的即可。