(一)Mysql 架构及sql执行流程
1. Mysql 的发展历史
| 时间 | 里程碑 |
|---|---|
| 1996 年 | MySQL 1.0发布。它的历史可以追溯到1979年,作者Monty用BASIC设计的一个报表工具。 |
| 1996年10月 | 3.11.1发布:MySQL没有2.x版本 |
| 2000 年 | ISAM升级成MylSAM引擎。MySQL开源。 |
| 2003 年 | MySQL 4.0发布,集成InnoDB存储引擎。 |
| 2005 年 | MySQL 5 版本发布,提供了视图、存储过程等功能。 |
| 2008 年 | MySQL AB公司被Sun公司收购,进入Sun MySQL时代。 |
| 2009 年 | Oracle收购Sun公司,进入Oracle MySQL时代。 |
| 2010 年 | MySQL 5.5发布,InnoDB成为默认的存储引擎。 |
| 2016 年 | 2016 年 MySQL发布8.0.0版本。为什么没有6、7? 5.6可以当成6.x, 5.7可以当成 7.x |
因为MySQL是开源的(也有商业版本),所以在MySQL稳定版本的基础上也发展出来了很多的分支,就像 Linux—样,有 Ubuntu、RedHat、CentOSs Fedora、Debian
大家最熟悉MySQL分支的应该是MariaDB,因为CentOS 7里面自带了一个MariaDBo。它是怎么来的呢? Oracle收购MySQL之后’MySQL创始人之一Monty担心MySQL数据库发展的未来(开发缓慢,封闭,可能会被闭源),就创建了一个分支MariaDB (2009年),默认使用全新的Maria存储引擎,它是原MylSAM存储引擎的升级版本。
其他流行分支:
Percona Server是MySQL重要的分支之一,它基于InnoDB存储引擎的基础上,提升了性能和易管理性,最后形成了增强版的XtraDB引擎,可以用来更好地发挥服务器硬件上的性能。
国内也有一些MySQL的分支或者自研的存储引擎,比如网易的InnoSQL,极数云舟的ArkDBo
我们操作数据库有各种各样的方式,比如Linux系统中的命令行,比如数据库工具 Navicat,比如程序,例如Java语言的JDBC API或者ORM框架。
大家有没有思考过,当我们的工具或者程序连接到数据库之后,实际上发生了什么事情?它的内部是怎么工作的?
以一条査询语句为例,我们来看下MySQL的工作流程是什么样的。
2. Sql语句的执行流程
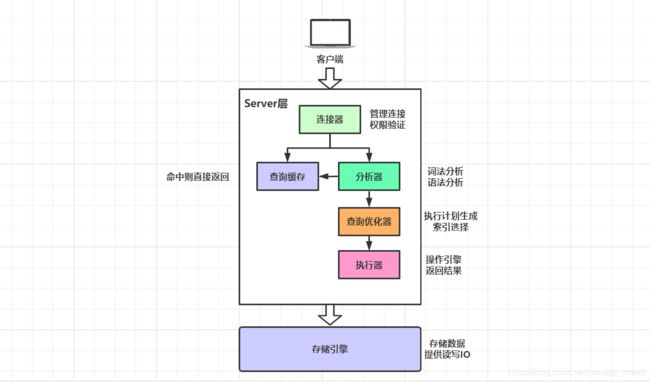
2.1 连接
我们的程序或者工具要操作数据库,第一步要做什么事情?跟数据库建立连接。
MySQL服务监听的端口默认是3306,客户端连接服务端的方式有很多。可以是同步的也可以是异步的,可以是长连接也可以是短连接,可以是TCP也可以是Unix Socket, MySQL有专门处理连接的模块,连接的时候需要验证权限。
我们怎么查看MySQL当前有多少个连接?
可以用show status命令,模糊匹配 Thread:
show global status like 'Thread%';
| 字段 | 含义 |
|---|---|
| Threads cached | 缓存中的线程连接数 |
| Threads connected | 当前打开的连接数 |
| Threads created | 为处理连接创建的线程数 |
| Threads running | 非睡眠状态的连接数,通常指并发连接数 |
问题:为什么连接数是查看线程?客户端的连接和服务端的线程有什么关系?
客户端每产生一个连接或者一个会话,在服务端就会创建一个线程来处理。反过来, 如果要杀死会话,就是Kill线程。
既然是分配线程的话,保持连接肯定会消耗服务端的资源。MySQL会把那些长时间不活动的(SLEEP)连接自动断开。
有两个参数:
show global variables like 'wait timeout'; -- 非交互式超时时间,如 JDBC 程序
show global variables like 'interactive timeout'; -- 交互式超时时间,如数据库工具
默认都是28800秒,8小时。
既然连接消耗资源,MySQL服务允许的最大连接数(也就是并发数)默认是多少呢?
在5.7版本中默认是151个,最大可以设置成10万个
show variables like 'max connections';
参数级别说明:
MySQL中的参数(变量)分为session和global级别,分别是在当前会话中生效和全局生效,但是并不是每个参数都有两个级别,比如max_connections就只有全局级别。
当没有带参数的时候,默认是session级别,包括查询和修改。
比如修改了一个参数以后,在本窗口査询已经生效,但是其他窗口不生效:
show variables like 'autocommit';
set autocommit = on;
所以,如果只是临时修改,建议修改session级别。 如果需要在其他会话中生效,必须显式地加上global参数。
执行一条查询语句,客户端跟服务端建立连接之后呢?下一步要做什么?
2.2 查询缓存
MySQL内部自带了一个缓存模块。
思考一个问题:有一张500万行数据的表,没有索引,如果我两次执行一模一样的SQL语句,第二次会不会变得很快?
答:不会,因为mysql的缓存也是有大小限制的。不可能一次缓存500万的数据。
再问:
select * from user u where u.name = 'xhc';
上面这条sql语句会用到缓存吗?
答案是:缓存没有生效,为什么? MySQL的缓存默认是关闭的。
show variables like 'query_cache%';
默认关闭的意思就是不推荐使用,为什么MySQL不推荐使用它自带的缓存呢? 主要是因为MySQL自带的缓存的应用场景有限,第一个是它要求SQL语句必须一模一样,中间多一个空格,字母大小写不同都被认为是不同的的SQL。
第二个是表里面任何一条数据发生变化的时候,这张表所有缓存都会失效,所以对于有大量数据更新的应用,也不适合。
所以缓存这一块,我们还是交给0RM框架(比如MyBatis默认开启了一级缓存), 或者独立的缓存服务,比如Redis来处理更合适。
MySQL 8.0中,查询缓存已经被移除了。
2.3 语法解析和预处理(Parser & Preprocessor)
这一步主要做的事情是对语句基于SQL语法进行词法分析、语法分析和语义解析。
2.3.1 词法分析
词法分析就是把一个完整的SQL语句打碎成一个个的单词。比如一个简单的SQL语句:
select name from user where id = 1;
它会打碎成8个符号,每个符号是什么类型,从哪里开始到哪里结束。
2.3.2 语法分析
第二步就是语法分析,语法分析会对SQL做一些语法检查,比如单引号有没有闭合, 然后根据MySQL定义的语法规则,根据SQL语句生成一个数据结构。这个数据结构我们把它叫做解析树(select lex)。
词法语法分析是一个非常基础的功能,Java的编译器、百度搜索引擎如果要识别语句,必须也要有词法语法分析功能。
任何数据库的中间件,要解析SQL完成路由功能,也必须要有词法和语法分析功能, 比如Mycat, Sharding-JDBC
问题:如果我写了一个词法和语法都正确的SQL,但是表名或者字段不存在,会在哪里报错?是在数据库的执行器还是解析器?比如:
select * from xhc;
实际上还是在解析的时候报错,解析SQL的环节里面有个预处理器。它会检査生成的解析树,解决解析器无法解析的语义。比如,它会检査表和列名是否存在,检査名字和别名,保证没有歧义。
预处理之后得到一个新的解析树。
2.4 查询优化(Query Optimizer)与查询执行计划
2.4.1 什么是优化器?
得到解析树之后,是不是执行SQL语句了呢?
这里我们有一个问题,一条SQL语句是不是只有一种执行方式?或者说数据库最终执行的SQL是不是就是我们发送的SQL?
这个答案是否定的。一条SQL语句是可以有很多种执行方式的,最终返回相同的结果,他们是等价的。但是如果有这么多种执行方式,这些执行方式怎么得到的?最终选择哪一种去执行?根据什么判断标准去选择?
这个就是MySQL的査询优化器的模块(Optimizer)。
査询优化器的目的就是根据解析树生成不同的执行计划(Execution Plan),然后选择一种最优的执行计划,MySQL里面使用的是基于开销(cost)的优化器,那种执行计划开销最小,就用哪种。
可以使用这个命令査看査询的开销:
show status like 'Last query cost';
2.4.2 优化器可以做什么?
MySQL的优化器能处理哪些优化类型呢?
- 当我们对多张表进行关联查询的时候,以哪个表的数据作为基准表。
- 有多个索弓|可以使用的时候,选择哪个索引。
实际上,对于每一种数据库来说,优化器的模块都是必不可少的,他们通过复杂的算法实现尽可能优化查询效率的目标。
但是优化器也不是万能的,并不是再低效的SQL语句都能自动优化,也不是每次都能选择到最优的执行计划,大家在编写SQL语句的时候还是要注意。
优化完之后,得到一个什么东西呢?优化器最终会把解析树变成一个査询执行计划,查询执行计划是一个数据结构
怎么査看MySQL的执行计划呢?比如多张表关联查询,先査询哪张表?在执行査询的时候可能用到哪些索引,实际上用到了什么索引?
MySQL提供了一个执行计划的工具。我们在SQL语句前面加上EXPLAIN,就可以看到执行计划的信息。
EXPLAIN select name from user where id=1;
如果要得到详细的信息,还可以用FORMAT=JSON 或者开启optimizer traceo
EXPLAIN FORMAT=JSON select name from user where id=1;
2.5 存储引擎
我们知道,mysql 有很多种存储引擎,比如myisam ,memor,innodb等。一个表类型是myisam 的表,和一个表类型是innodb表类型的表,他们到底是如何存储数据的呢?
show variables like 'datadir';
默认情况下,每个数据库有一个自己文件夹,以test数据库为例。任何一个存储引擎都有一个frm文件,这个是表结构定义文件。

不同的存储引擎存放数据的方式不一样,产生的文件也不一样, memory没有,innodb是1个,myisam 是2个。
这里我们有几个问题:
- 表类型是怎么选择的?可以修改吗?
- MySQL为什么支持这么多存储引擎呢?一种还不够用吗?
- 这些不同的存储引擎,到底有什么区别?
2.5.1 存储引擎选择
一张表的存储引擎,是在创建表的时候指定的,使用ENGINE关键字。
CREATE TABLE user_innodb' (
id int(11) NOT NULL AUTOINCREMENT,
name varchar(255) DEFAULT NULL,
gender tinyint(1) DEFAULT NULL,
phone varchar(11) DEFAULT NULL,
PRIMARY KEY ('id'),
KEY 'comidx_name_phone' ( name ,'phone')
)ENGINE=InnoDB AUTO_INCREMENT= 1 DEFAULT CHARSET=utf8mb4;
很多时候我们自己写的建表语句是没有指定存储引擎的。
没有指定的时候,数据库就会使用默认的存储引擎,5.5.5之前,默认的存储引擎是MylSAM, 5.5.5之后,默认的存储引擎是InnoDB。
这么多的存储引擎,区别到底在哪里?
试想一下: 如果我有一张表,需要很高的访问速度,而不需要考虑持久化的问题,是不是要把数据放在内存?
如果一张表,是用来做历史数据存档的,不需要修改,也不需要索引,那它是不是要支持数据的压缩?
如果一张表用在读写并发很多的业务中,是不是要支持读写不干扰,而且要保证比较高的数据一致性呢?
说到这里大家应该明白了,为什么要支持这么多的存储引擎,就是因为我们有不同的业务需求,一种存储引擎不能提供所有的特性。